 夜雨聆风
夜雨聆风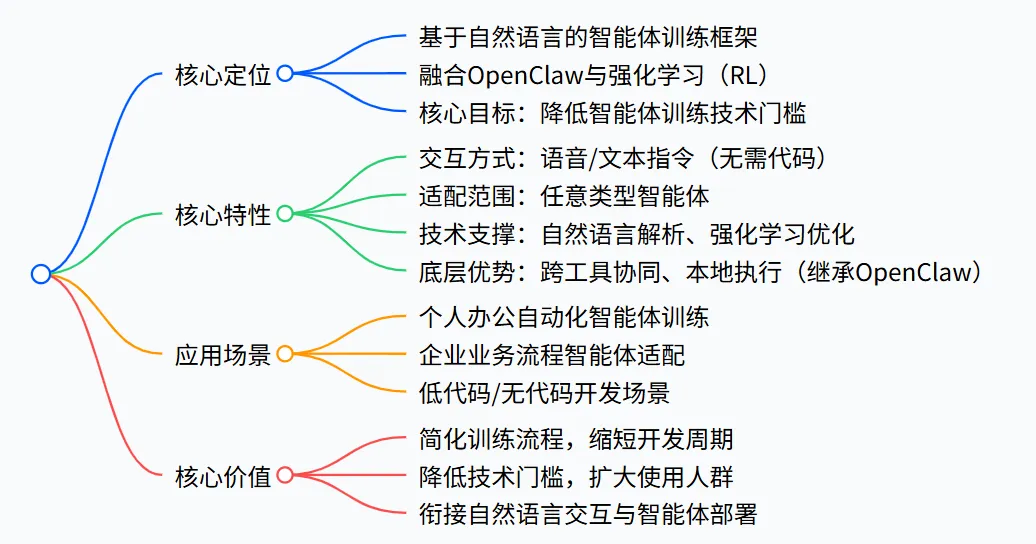
一、框架核心定位
- 1.名称与本质:OpenClaw-RL 是 OpenClaw 生态的延伸框架,核心是将
- 2.核心目标:解决传统智能体训练 “依赖专业代码、流程复杂、门槛高” 的痛点,让非技术用户也能通过自然语言指令完成智能体的定制训练。
- 3.底层基础:继承 OpenClaw 原生的 “本地优先、跨工具协同、模块化架构” 特性,新增强化学习模块用于智能体行为优化。
二、核心功能与特性
三、应用场景与价值
- 目标用户:
非技术从业者(如职场白领、企业运营):需定制办公自动化智能体; 中小企业:无专业算法团队,需快速部署业务流程智能体; 开发者:需简化智能体训练流程,缩短迭代周期。 - 典型场景:
办公场景:训练智能体自动处理邮件、生成报表、同步日程; 业务场景:训练智能体完成客户咨询应答、订单跟踪、数据统计; 工具场景:训练智能体联动本地软件(如 Excel、PPT)执行批量操作。 - 核心价值:
效率提升:将智能体训练周期从 “数天 / 数周” 缩短至 “小时级 / 分钟级”; 门槛降低:无需掌握强化学习算法、编程技能即可完成定制; 生态协同:丰富 OpenClaw 生态的 “训练 - 部署 - 执行” 闭环,增强生态竞争力。
4. 关键问题
问题 1:OpenClaw-RL 与原生 OpenClaw 的核心区别是什么?
答案:核心区别在于 “功能定位” 与 “技术模块”:原生 OpenClaw 聚焦 “智能体执行”(通过自然语言指令操控工具完成任务),而 OpenClaw-RL 聚焦 “智能体训练”(通过自然语言指令定制、优化智能体行为);技术上新增 强化学习(RL)模块 和 自然语言 - 训练目标解析模块,实现 “对话驱动训练”,而原生 OpenClaw 无训练相关功能。
问题 2:OpenClaw-RL 如何实现 “无需代码即可训练智能体”?
答案:核心依赖两层技术支撑:① 自然语言解析技术:将用户的自然语言指令(如 “训练一个每天自动整理邮件并分类的智能体”)转化为明确的训练目标、奖励函数(如 “成功分类 1 封邮件得 1 分”)和约束条件;② 自动化强化学习流程:框架内置标准化训练 pipeline,自动完成智能体初始化、行为迭代、策略优化,无需用户手动配置算法参数或编写训练脚本。
问题 3:OpenClaw-RL 的适用边界是什么?是否能训练复杂场景的智能体?
答案:适用边界集中在 “结构化 / 半结构化任务”(如数据处理、流程执行、规则明确的交互任务);对于高复杂度场景(如需要复杂逻辑推理、多智能体协同、动态环境适配的任务),推测其训练效果可能受限 —— 需依赖用户提供更细致的指令的或结合少量参数配置。其设计初衷是满足 “中低复杂度智能体” 的快速训练需求,而非替代专业强化学习平台处理高难度研发任务。
===========================================
******------------------------华丽的分割线----------------------******
===========================================
以下是文章正文部分详细内容介绍:
每一次智能体交互都会产生一个下一状态信号,即每个动作之后的用户回复、工具输出、终端或图形用户界面(GUI)状态变化 —— 然而,现有智能体强化学习(agentic RL)系统均未将其作为实时、在线的学习来源。本文提出 OpenClaw-RL 框架,其核心基于一个简单观察:下一状态信号具有通用性,单一策略可同时从所有信号中学习。个人对话、终端执行、图形用户界面(GUI)交互、软件工程(SWE)任务和工具调用轨迹并非独立的训练问题,而是可在同一循环中用于训练同一策略的交互场景。
下一状态信号包含两类信息:
- 评估型信号:指示动作执行效果,通过过程奖励模型(PRM)评判器提取为标量奖励;
- 指导型信号:指示动作应如何改进,通过事后引导在线策略蒸馏(OPD)恢复。
我们从下一状态中提取文本提示,构建增强型教师上下文,提供比任何标量奖励更丰富的令牌级方向性优势监督。得益于异步设计,模型可响应实时请求、PRM 评判器可评估正在进行的交互、训练器可同步更新策略,三者之间无需协调开销。
将 OpenClaw-RL 应用于个人智能体时,智能体仅需通过实际使用即可实现性能提升,从用户的重复查询、修正意见和明确反馈中提取对话信号;应用于通用智能体时,同一基础设施可支持终端、图形用户界面(GUI)、软件工程(SWE)和工具调用场景的规模化强化学习,我们在此进一步验证了过程奖励的实用价值。
1 引言
每一个已部署的人工智能(AI)智能体都在持续收集提升自身所需的数据,却又将其丢弃。在执行每个动作at后,智能体都会收到一个下一状态信号st+1:可能是用户回复、工具执行结果、图形用户界面(GUI)状态转换或测试结论。现有系统仅将其视为下一个动作的上下文(Fu 等人,2025; Mei 等人,2025; Sheng 等人,2025; Wang 等人,2025b; Zhu 等人,2025)。我们认为,下一状态信号蕴含着更具价值的信息:对动作at的隐含评估,包括动作的执行效果,以及通常情况下应如何改进。关键在于,这种信号在所有交互类型中均可自然获取,涵盖个人对话、终端环境、图形用户界面(GUI)环境、软件工程(SWE)任务和工具调用环境 —— 然而,现有智能体强化学习(agentic RL)系统均未将其作为实时、在线的学习来源。我们发现了两种可回收利用的 “信息浪费” 形式:
浪费 1—— 评估型信号
下一状态信号会隐含地为前序动作打分:用户重复查询意味着不满,测试通过代表成功,错误轨迹则表明失败。这构成了天然的过程奖励,无需额外的标注流水线。但过程奖励模型(PRM)的研究几乎仅限于具备可验证真实标签的数学推理任务(Cui 等人,2025b; Lightman 等人,2023; Wang 等人,2024)。在个人智能体中,它逐轮捕捉用户满意度;在通用智能体中,它为长程任务提供所需的密集型逐步骤信用分配(Wang 等人,2026)。现有系统要么忽略这一信号,要么仅以离线、预收集的形式利用它,依赖固定数据集或终端结果奖励。
浪费 2—— 指导型信号
除打分外,下一状态信号通常还包含指导信息:用户反馈 “应先检查文件” 时,不仅表明响应错误,还明确了令牌级别的改进方向;同样,详细的软件工程(SWE)错误轨迹往往隐含具体的修正路径。当前的强化学习与验证(RLVR)方法采用标量奖励,无法将此类信息转化为方向性策略梯度(Guo 等人,2025; Hu 等人,2025; Shao 等人,2024; Yu 等人,2025a);而蒸馏方法(Hübotter 等人,2026; Shenfeld 等人,2026)依赖预整理的反馈 - 响应对,而非实时信号。事后重新标记(Hübotter 等人,2026; Zhang 等人,2023)和上下文增强蒸馏(Yang 等人,2024b, 2025c)的研究表明,向上下文添加结构化修正信息可显著改善输出,但这些方法均基于固定数据集。在并行研究中,Buening 等人(2026)通过直接用下一状态信息提示来优化在线策略,但修正提示仍处于隐含状态。
OpenClaw-RL 框架
本文提出 OpenClaw-RL,这是一款统一框架,可回收个人智能体和通用智能体在多种场景下的两类下一状态信号浪费,包括 OpenClaw 支持的个人对话(OpenClaw, 2026)、终端、图形用户界面(GUI)、软件工程(SWE)和工具调用环境。OpenClaw-RL 基于 slime 框架(Zhu 等人,2025)构建,采用完全解耦的异步架构,其中策略服务、轨迹生成收集、过程奖励模型(PRM)评判和策略训练作为四个独立循环运行,无阻塞依赖。在个人智能体场景中,模型可通过日常使用自动优化 —— 这扩展了现有强化学习基础设施的能力,后者通常假设批量数据收集,而非从实时部署中持续学习。
我们提供两种优化方案:第一,二元强化学习(binary RL)利用过程奖励模型(PRM)将对话转化为标量过程奖励;第二,事后引导在线策略蒸馏(OPD)从下一状态中提取文本提示,构建增强型教师上下文,将令牌级方向性监督蒸馏回学生模型,提供仅靠标量奖励无法获得的训练信号。仿真实验表明,通过加权损失函数结合两种方法,可实现显著性能提升。
该框架还可扩展至通用智能体的强化学习训练,涵盖终端、图形用户界面(GUI)、软件工程(SWE)和工具调用场景。我们将过程奖励模型(PRM)评判与可验证结果相结合,提供密集且可靠的监督(Wang 等人,2026; Zou 等人,2025);通过支持在云服务上大规模部署环境,进一步提升了框架的可扩展性。
使用 OpenClaw 完成作业的学生,不希望被发现使用人工智能。
使用 OpenClaw 批改作业的教师,希望评语具体且友好。
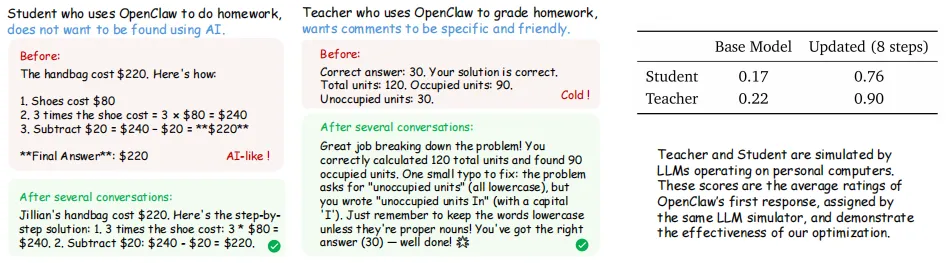
图 2 | 仅需使用即可优化你的 OpenClaw:此处展示仿真结果。
主要贡献
- 将下一状态信号作为实时在线学习来源:我们发现,无论是用户回复、执行结果、测试结论还是图形用户界面(GUI)转换,下一状态信号均包含对前序动作的评估型和指导型信息。我们将这些信号作为实时在线训练来源,适配异构交互类型。
- OpenClaw-RL 基础设施:首个统一多种并行交互数据流的系统,涵盖个人对话、终端、图形用户界面(GUI)、软件工程(SWE)和工具调用智能体场景。设计目标为 “服务无中断”,支持会话感知多轮跟踪、平滑权重更新、灵活的过程奖励模型(PRM)适配和大规模环境并行化。
- 两种互补的下一状态信号回收方法:基于过程奖励模型(PRM)的二元强化学习将评估型下一状态信号转化为密集标量过程奖励;而事后引导在线策略蒸馏(OPD)通过从下一状态提取文本提示、构建增强型教师上下文,将指导型信号转化为令牌级优势监督 —— 丰富的文本反馈为改进提供方向性指导。
- 个人与通用智能体的实证验证:在个人智能体个性化任务,以及终端、图形用户界面(GUI)、软件工程(SWE)和工具调用场景的智能体强化学习任务中,验证了 OpenClaw-RL 的有效性。实验表明,二元强化学习与事后引导在线策略蒸馏(OPD)具有互补性,两者结合可为个人智能体带来显著性能提升;同时验证了在通用智能体强化学习场景中,整合过程奖励与结果奖励的有效性。
2 问题定义
OpenClaw-RL 基于策略πθ运行,该策略可同时接收多条交互数据流,并将其与推理流水线解耦,因此具备足够灵活性,适用于多种智能体场景,包括个人智能体对话、终端执行、图形用户界面(GUI)交互、软件工程(SWE)任务和工具调用轨迹。我们将每条交互数据流形式化为马尔可夫决策过程(MDP)(S,A,T,r):
状态st∈S:截至第t轮的完整对话或环境上下文; 动作at∈A:智能体的响应,即由πθ生成的token序列; 转移函数T(st+1∣st,at):由环境决定(确定性);st+1是动作at之后的用户回复、执行结果或工具输出; 奖励r(at,st+1):通过过程奖励模型(PRM)评判器从下一状态信号中推断得出。
在标准强化学习与验证(RLVR)中,结果o作为整个轨迹的奖励。然而,依赖于下一状态st+1的过程奖励r(at,st+1)包含更丰富的信号。特别是当下一状态包含关于 “动作应如何改进” 的明确指导信息时,在线策略蒸馏可通过将此类方向性下一状态信号转化为令牌级教师监督,实现方向性优化(Agarwal 等人,2024; Hübotter 等人,2026)。
3 OpenClaw-RL 基础设施:面向个人与通用智能体的统一系统
我们在单一框架中实现了个人 OpenClaw 智能体的自动优化,以及面向通用智能体(包括终端、图形用户界面(GUI)、软件工程(SWE)和工具调用场景)的大规模智能体强化学习。
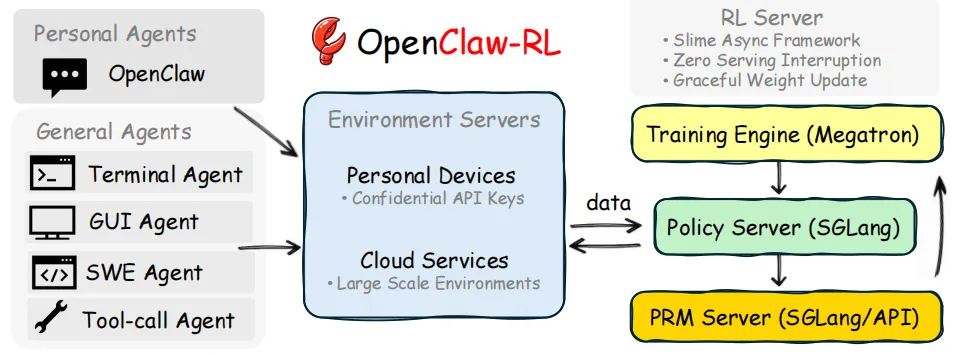
3.1 含四个解耦组件的异步流水线
OpenClaw-RL 的核心架构原则是完全解耦:策略服务、环境托管、过程奖励模型(PRM)评判和策略训练作为四个完全独立的异步循环运行,组件间无阻塞依赖(图 1)。
策略服务 → 环境 → 奖励评判 → 策略训练
(SGLang 框架)→(HTTP/API 协议)→(SGLang 框架 / API 接口)→(Megatron 框架)
模型在响应下一个用户请求的同时,过程奖励模型(PRM)评判前一个响应,训练器执行梯度更新 —— 三者互不等待。这一设计使从实时异构交互数据流中持续训练成为可能:无需为适配其他组件的调度而暂停或批量处理任一数据流。
对于个人智能体,模型通过保密 API 连接,实现隐私安全部署,无需修改个人智能体框架,且可在不中断推理的情况下平滑更新;对于通用智能体的大规模训练,该异步设计允许各组件独立运行、无阻塞,从而缓解长程轨迹生成时长导致的长尾问题。
3.2 面向个人智能体的会话感知环境服务器
个人智能体的运行环境为用户设备,设备通过保密 API 与强化学习服务器连接。每个 API 请求被分为两类:
主线轮次(Main-line turn):智能体的核心响应和工具执行结果,可构成训练样本; 辅助轮次(Side turn):辅助查询、记忆整理和环境转换,仅转发数据,不生成训练样本。
这种分类使强化学习框架能精准识别各轮次所属的会话,实现靶向训练。目前,我们仅基于主线轮次进行训练。每个新主线请求的消息中包含对上一轮次的反馈(无论是用户回复还是环境执行结果),该反馈将作为上一轮次奖励计算的下一状态信号st+1。
3.3 可扩展性:从单用户个性化到大规模智能体部署
OpenClaw-RL 设计初衷是覆盖从单用户个人智能体到大规模多环境通用智能体部署的全场景。对于个人智能体,其运行环境为单个用户设备,交互数据流稀疏、基于会话且高度个性化;基于 slime 框架(Zhu 等人,2025)构建的 OpenClaw-RL,继承了适用于通用智能体的可扩展训练基础设施,并进一步支持跨多种智能体场景的云托管环境(3.4 节)。云服务上托管的数百个并行环境可生成密集的结构化执行信号,为规模化强化学习训练提供支撑。
3.4 支持多种真实场景
在开源实现中,OpenClaw-RL 支持多种通用智能体场景,覆盖最常见的真实部署环境(表 1):
终端智能体:计算机使用系统的核心组件,高效、扩展成本低,且天然适配大语言模型(LLM)的文本交互界面(Anthropic, 2026; OpenAI, 2026; Shen 等人,2026); 图形用户界面(GUI)智能体:覆盖终端智能体无法直接访问的功能(如可视化界面、指针交互),是更通用计算机使用任务的必要选择(Qin 等人,2025; Wang 等人,2025a,c; Xue 等人,2026); 软件工程(SWE)智能体:一类尤为重要的编程智能体,环境可通过测试、代码差异(diff)和静态分析提供丰富的可执行反馈(Cao 等人,2026); 工具调用智能体:同样至关重要,外部工具可同时提升推理能力和事实准确性(Feng 等人,2025a)。
表 1 | 支持的智能体场景及其环境特征
3.5 非阻塞记录与可观测性
所有交互和奖励评估均实时记录为 JSONL 格式文件,包含完整消息历史、提示词 / 响应文本、工具调用记录、下一状态内容、过程奖励模型(PRM)逐票评分、选定提示(OPD)及接收 / 拒绝决策。记录过程为非阻塞模式:写入操作通过后台线程 “发送后即遗忘”(fire-and-forget),不会为服务或过程奖励模型(PRM)路径增加延迟。记录文件在每次权重更新边界被清理,确保日志始终与单一策略版本对应。
4 从下一状态信号中学习:跨交互类型的统一强化学习
我们将来自异构交互数据流(包括个人对话、终端交互、图形用户界面(GUI)交互、软件工程(SWE)任务和工具调用轨迹)的下一状态信号,转化为策略梯度。
4.1 面向个人智能体的二元强化学习
将评估型下一状态信号转化为标量过程奖励。
奖励计算公式:结果奖励 + 过程奖励均值(prm)
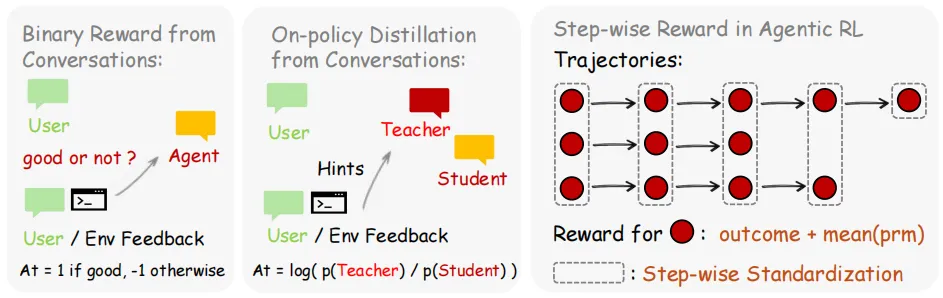
图 3 | 方法概述:针对个人智能体,我们支持二元奖励优化和在线策略蒸馏两种训练方式。实验表明,两者结合可带来显著性能提升。对于通用智能体强化学习,除标准强化学习与验证(RLVR)外,我们还提供集成式分步奖励及一种简洁高效的标准化方法(Wang 等人,2026)。
4.1.1 基于多数投票的 PRM 评判器构建
给定响应at和下一状态st+1,评判器模型评估at的质量:PRM(at,st+1)→r∈{+1,−1,0}
具体而言,PRM 评判器根据用户的下一轮响应或工具调用结果对每个动作进行评分:工具调用结果通常能给出明确结论;用户的下一轮响应可能包含满意或不满意的信号;若用户未给出明确反馈,模型会结合场景进行估算(同时鼓励用户提供更明确的反馈)。对于通用智能体,评判器会判断环境反馈是否表明任务向目标推进。我们执行m次独立查询并采用多数投票机制,最终奖励为rfinal=MajorityVote(r1,...,rm)。
4.1.2 强化学习训练目标
直接采用优势函数At=rfinal,训练目标为带非对称边界的标准 PPO 风格裁剪代理目标(Schulman 等人,2017):
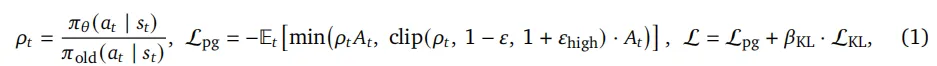
其中ϵ=0.2,ϵhigh=0.28,βKL=0.02。需注意,本方法适用于实时对话场景,因此无法像 GRPO(Shao 等人,2024)那样通过分组结构实现标准化。
4.2 面向个人智能体的事后引导在线策略蒸馏(OPD)
将方向性的下一状态信号转化为token级教师监督信号。
4.2.1 为何需要基于下一状态信号的令牌级监督?
二元强化学习将st+1的全部信息压缩为单一标量r∈{+1,−1,0}。但用户若反馈 “编辑前应先检查文件”,所传递的信息远不止 “响应错误”—— 还包括哪些token需要修改、如何修改。这种指导性信息在标量奖励中会完全丢失。
OPD 通过将下一状态信号转化为token级训练信号,恢复了这类信息。核心洞察是:若在原始提示中加入从st+1提取的文本提示,同一模型会生成不同的token分布 —— 该分布 “知晓” 应有的正确响应。这种提示增强分布与学生模型分布之间的逐令牌差异,提供了方向性优势:模型应强化的令牌对应正优势,应弱化的令牌对应负优势。这与以下方法存在本质区别:RLHF(Christiano 等人,2017; Ziegler 等人,2019)使用标量偏好信号,DPO(Rafailov 等人,2023)需要成对偏好数据,而标准蒸馏需要独立的更强教师模型。
4.2.2 token级 OPD 流程
步骤 1:事后提示提取
评判器执行:Judge(at,st+1)→{score∈{+1,−1},hint∈T∗}
若评分score=+1,评判器在[HINT_START]...[HINT_END]标签内生成简洁提示。我们并行执行m次评判器调用,核心设计为:不直接将st+1作为提示 —— 原始下一状态信号通常存在噪声、冗长或包含无关信息(如用户回复可能同时包含修正意见和无关新问题)。评判器模型将st+1提炼为简洁可执行的指令,聚焦响应需改进的方向,通常为 1-3 句话。
步骤 2:提示筛选与质量过滤
在长度超过 10 个字符的正向投票提示中,选择最长(信息最丰富)的提示;若不存在有效提示,则直接丢弃该样本 —— 此设计为刻意为之。OPD 以样本数量换取信号质量:仅当下一状态信号包含明确可提取的修正方向时,才将该轮交互纳入训练。这种严格过滤与二元强化学习形成互补:二元强化学习接受所有带评分的轮次,提供覆盖广泛的粗粒度信号;OPD 则针对少量样本提供靶向性、高分辨率的监督。
步骤 3:增强型教师模型构建
将提示附加到最后一条用户消息后,格式为[用户提示/指令]\n{hint},生成增强提示 senhanced=st⊕hint—— 该提示模拟了 “用户提前提供修正意见” 时模型的输入场景。
步骤 4:令牌级优势函数计算
在增强提示senhanced下查询策略模型,强制输入原始响应at,计算每个响应令牌的对数概率。在线策略蒸馏中的令牌级优势函数为:

- At<0:教师模型认为该令牌与提示不符 —— 学生模型应弱化该令牌。
与推动所有令牌向同一方向调整的标量优势函数不同,该函数提供逐令牌的方向性指导:在单个响应中,部分令牌可能被强化,而其他令牌被抑制。训练仍采用公式(1)的裁剪代理目标,但此时每个样本的优势函数包含更丰富的信息。
4.3 二元奖励与 OPD 方法的结合
充分发挥两种方法的优势,互补其劣势。
表 2 | 不同学习方法对比
二元奖励与 OPD 方法互为补充而非竞争关系:二元强化学习接受所有带评分的轮次,无需提取提示,可适配任意下一状态信号(包括简洁的隐含反馈如用户重复提问,或结构化环境输出如退出码、测试结论);当交互流可能包含丰富指导信息时(如用户给出明确修正意见 “不要使用该库”“先检查文件”,或环境输出详细错误轨迹如软件工程差异、编译器诊断信息),可额外启用 OPD。实际应用中,建议同时运行两种方法:二元强化学习为所有轮次提供广泛的梯度覆盖,OPD 则针对含指导信号的轮次提供高分辨率的逐令牌修正。
因此,我们提出采用加权损失函数结合这两种互补方法。由于两者共享相同的 PPO 损失,仅优势函数计算不同,可直接使用以下优势函数:
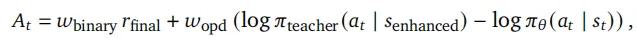
默认设置wbinary=wopd=1。实验表明,该方法可实现显著的性能提升。
4.4 面向通用智能体强化学习的分步奖励
如何结合结果奖励与过程奖励?
4.4.1 过程奖励对智能体任务的重要性
在长程智能体任务中,仅依赖结果奖励的强化学习仅在终端步骤提供梯度信号,导致绝大多数轮次处于无监督状态。PRM 根据下一状态信号为每个轮次分配奖励,实现轨迹全程的密集信用分配。近期研究提供了强有力的实证支持:RLAnything(Wang 等人,2026)表明,在图形用户界面(GUI)智能体、文本游戏智能体和编程任务中,整合分步 PRM 信号与结果奖励的训练效果,持续优于仅依赖结果奖励的训练。OpenClaw-RL 直接基于这一洞察:PRM 评判器以实时下一状态信号为依据评估每个轮次,实证结果(§5.4)表明,这种密集信号对长程强化学习场景具有重要价值。
4.4.2 结果奖励与过程奖励的整合
可验证结果是 RLVR 场景中的标准监督信号。遵循 RLAnything(Wang 等人,2026),我们通过简单相加整合结果奖励与过程奖励,步骤t的奖励为
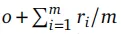
,其中ri为 PRM(at,st+1)独立分配的奖励。与 GRPO 不同,分步奖励的存在使优势函数计算更复杂:Feng 等人(2025b)对相似状态分组并在组内标准化,但在终端智能体等真实场景中,状态难以有效聚类。因此,我们直接对相同步骤索引的动作进行分组,实证表明该方法效果显著。
