 夜雨聆风
夜雨聆风What's up, 大家!这是我的第 16 篇原创文章。
先说结论。
如果今天还有人把 OpenClaw 的普及理解成“再多装几个 Skill、再多堆几个案例、再多上几个榜单”,那大概率还是没抓到重点。真正决定它能不能走出极客圈的,不是功能越来越花,而是三件更底层的事有没有补齐:模型选择、安全层、入口设计。
因为普通用户并不会先问你“这个 Agent 能做多少事”,他们更先问的是三件事。
第一,应该选哪个模型才不容易翻车。
第二,会不会把我的环境和账号一起带崩。
第三,我到底从哪里开始用,能不能别先配半天环境。
这三件事不补,OpenClaw 再强也还是少数人的玩具。补齐了,它才有机会变成多数人的工具。
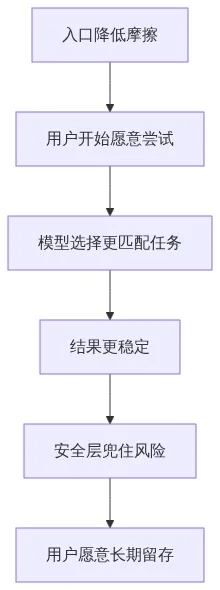
为什么很多人用了几天就劝退
不是因为 Agent 没前途,而是第一体验太容易把人劝走。
有的人一上来就被模型选型绕晕,榜单一堆、参数一堆、价格一堆,最后还是不知道自己该选什么。有的人则是刚装上几个 Skill,就开始担心端口、脚本、密码、主力机是不是全暴露了。还有一批人压根没走到这一步,卡在入口上,环境、API、依赖、接入顺序一多,第一天热情就没了。
这类问题很容易复现:当用户第一次接触 OpenClaw,就同时面对模型、权限、环境和入口四组选择题,任何一组没有清晰答案,试用就会迅速卡住。
| 缺口 | 用户真实感受 | 长期后果 |
| 模型选择没指引 | “我不知道该选谁,换来换去都像赌运气” | 成本高,稳定性低 |
| 安全层没前置 | “我怕它把主力环境搞坏” | 不敢长期用,不敢给权限 |
| 入口太重 | “我还没开始就先配置半天” | 试用转化率很低 |
所以 OpenClaw 真正的普及战,不是“证明它能做事”,而是“让第一次上手就能安全地做成事”。
最终可落地的方案:先定场景,再补模型、安全和入口
真正实用的做法,不是追最强,而是先把使用路径拆清楚。
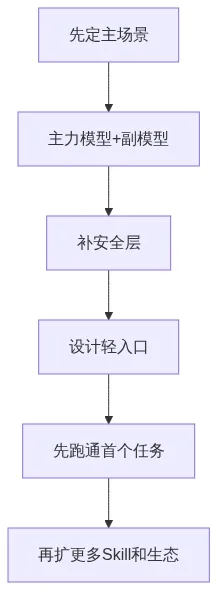
详细步骤:
| # | 操作 | 说明 |
| 1 | 先定主场景 | 先判断这次要解决的是编码、自动化还是内容协作,避免模型和入口乱选 |
| 2 | 再定模型组合 | 用主力模型扛复杂任务,用副模型处理扫描、分类和轻量整理 |
| 3 | 补安全层 | 把审查、隔离、权限和审计放到正式放权之前 |
| 4 | 设计入口 | 先让用户以最低摩擦跑通第一轮任务,再逐步暴露更复杂能力 |
第一件事,模型选择必须从“最强”改成“最合适”
很多人还在用选大模型的老思路,谁榜单高选谁,谁热度高选谁。但 Agent 场景和普通聊天不一样,它更看重持续性、任务贴合度和成本可承受性。
真正实用的选型,不是追最强,而是先分任务。
| 任务类型 | 更该优先看什么 | 常见误区 |
| 代码改造与多文件理解 | 长上下文、指令稳定性、工具调用一致性 | 只看跑分,不看长任务表现 |
| 自动化操作与工具编排 | 调用可靠性、错误恢复能力 | 只看生成质量,不看可执行性 |
| 内容整理与轻任务协作 | 成本、速度、容错 | 上来就用最贵配置 |
这也是为什么模型榜单有价值,但不能直接当答案。榜单告诉你一个大概趋势,却不会替你判断具体任务应该怎么配。
更稳的做法,是先把场景拆成两层。
一层是主力模型,负责难任务、跨文件任务和关键决策。
一层是副模型,负责便宜的扫描、分类和轻度整理。
当你这样配的时候,成本和稳定性才会同时变好。否则很多团队会陷进一个循环:为了稳定不断升级模型,为了省钱又不断降级模型,最后谁都不满意。
第二件事,安全层必须前置,而不是出事后补救
OpenClaw 的风险不是抽象的。
只要它开始接触脚本、文件、端口、浏览器登录态和本地环境,安全就不再是“以后再说”的话题。很多人以前把安全理解成“别乱点链接”,现在不够了。Agent 真正的风险,在于它可能会以很高效率执行你本来就没仔细审过的动作。
| 安全层动作 | 解决的问题 | 不做会怎样 |
| 安装前审查 Skill | 防止把危险能力直接接入 | 越装越多,风险面越大 |
| 权限分层 | 不让 Agent 直接摸最敏感资产 | 一次误操作就可能扩大损失 |
| 环境隔离 | 主力机与实验环境分开 | 出问题时没有缓冲带 |
| 操作审计 | 知道它到底做了什么 | 事后很难追责和复盘 |
很多人直到看到真实受害案例,才意识到安全层不是可选项,而是产品层能力。你不能要求普通用户先成为半个安全工程师,再来体验 Agent。
所以真正能让 OpenClaw 走向大众的,不只是更强的模型,也包括更像“安全管家”的外围能力。只有把审查、隔离、权限边界这些动作前置,普通人才会从“觉得厉害”走到“真的敢用”。
openclaw_policy:
install_guard:
- 新Skill先审查
- 来源不明先隔离
runtime_guard:
- 高风险操作二次确认
- 敏感目录默认拒绝
environment_guard:
- 主力机与实验机分离
- 密码与令牌不明文暴露第三件事,入口要足够轻,才能让普及真正发生
再强的 Agent,如果入口还是“先配环境、再配模型、再配密钥、再调依赖”,那它的传播边界天然就窄。
普通用户不是不想试,而是不想在第一天把全部耐心花在准备动作上。云端 App、预打包形态、免 API Key 的体验、手机端或聊天端入口,价值都在这里。它们不一定是最终形态,但它们会明显降低第一次成功的门槛。
| 入口形态 | 优点 | 适合谁 |
| 本地完整安装 | 控制力强,可定制深 | 有工程基础的人 |
| 云端预置方案 | 上手快,试错成本低 | 想先验证价值的人 |
| 聊天式轻入口 | 任务交付最自然 | 轻任务和日常协作 |
入口的作用,不是把技术复杂度彻底消灭,而是把复杂度挪到用户真正感兴趣之后再出现。先让人跑通,再让人升级,这比一上来要求全都懂有效得多。
真想把 OpenClaw 做成大众工具,建议按这四步落地
操作步骤表
| 步骤 | 先做什么 | 核心判断 | 目标 |
| 1 | 先定主场景 | 是编码、自动化还是内容协作 | 避免模型和入口乱选 |
| 2 | 再定模型组合 | 主力模型+便宜副模型分层 | 压住成本,提升稳定性 |
| 3 | 补安全层 | 审查、隔离、权限、审计 | 先兜风险,再放权限 |
| 4 | 设计入口 | 先让用户轻松开始,再逐步进阶 | 提高首轮留存 |
这四步的顺序不能乱。
很多团队的问题恰恰在于,先追求功能覆盖,再补安全;先讲完整能力,再讲入口;先喊生态繁荣,再回头补选型方法。结果产品看起来越来越大,用户真正用起来却越来越累。
最后一句,普及从来不是“更强”自动带来的
OpenClaw 的下一阶段,已经不是证明 Agent 这件事有没有用,而是证明它能不能用更低摩擦、更低风险、更清晰的方式被更多人接住。
模型选择决定它好不好用。
安全层决定它敢不敢长期用。
入口决定它愿不愿意先试一次。
这三件事,任何一件缺了,普及都会停在半路。
所以真正值得盯的,不是又多了多少新 Skill,而是有没有人把模型选择讲明白,把安全层做进系统,把入口做得足够轻。谁先把这三个缺口补齐,谁才更接近把 OpenClaw 从极客工具推成大众工具。
历史文章,请看这里:
2026-03-18:Windows×Linux×Mac三端协同:OpenClaw多节点同步实战
2026-03-15:让3个顶级模型协作写代码:OpenClaw多Agent编排实战
2026-03-05:手把手教同事用AI:让AI直接操作,问答模式早该扔了
