 夜雨聆风
夜雨聆风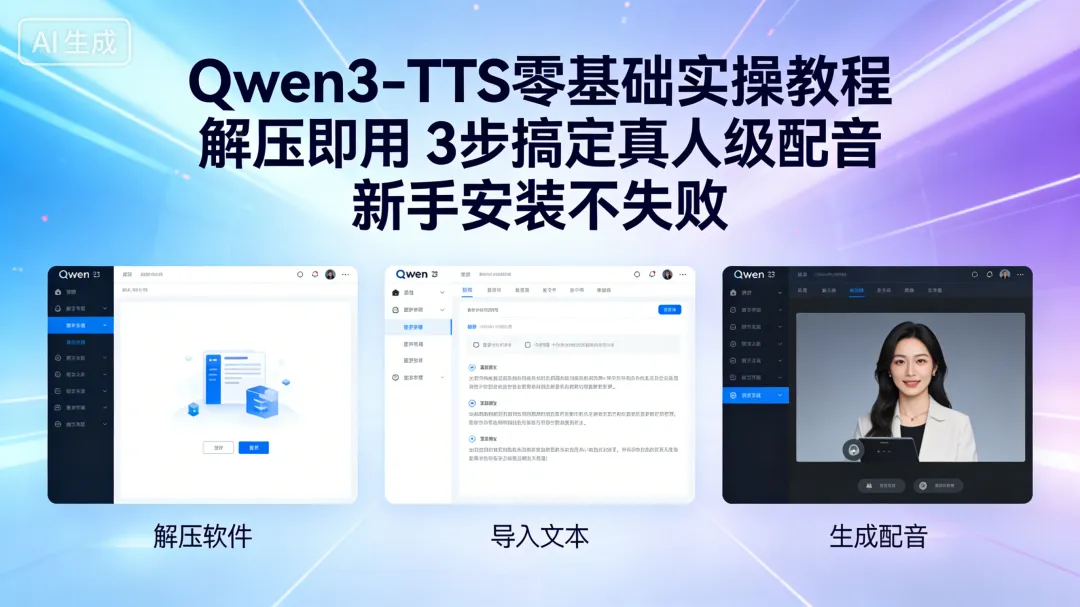
之前给大家深挖了Qwen3-TTS这款开源语音合成神器的核心亮点,作为当前开源TTS天花板级工具,它最圈粉的就是摆脱了复杂的AI模型部署流程,专门适配普通用户的懒人包版本,真正做到解压即用、零代码操作。很多小伙伴后台留言想要完整的实操步骤,今天这篇就带来纯干货零基础教程,从文件准备到最终导出高清音频,全程一步步拆解,没有任何技术门槛,电脑小白也能轻松学会,赶紧收藏跟着操作~
📥 前期准备:基础要求
首先跟大家明确,咱们用的是整合好的一键懒人包,不用单独下载模型、不用安装Python、不用配置环境变量,彻底省去繁琐步骤。
✅ 运行要求(低配也能冲)
系统:Windows 10/11 64位系统
显卡要求和对应版本:非独立显卡,不建议安装,GTX10、20推荐安装0.6B模型(基本上能满足95%以上的日常配音需求),GTX30及以上安装1.7B模型(追求极致的专业用户且电脑配置高的,选择这个)
实测:我测试的电脑配置是GTX1660,生成300字音频文件用了大概2分钟,显卡越好速度越快,音色域越准确。0.6B能绝对能胜任95%的要求。我现在宣传片配音,都是用的这个版本,跟真人老师配音无异,客户满意度跟之前一样,每年节约的配音费可以买个GTX5060Ti了,是不是很nice~
存储空间:解压后占用空间约5G,提前预留好磁盘空间
注意:电脑内存推荐8GB以上,CPU最起码i5,要不然用起来 ,会卡顿;不要修改安装包里面的设置,本地离线运行,不用担心内容泄露和使用限制
✅ 文件解压第一步(避坑重点)建议放在D根盘下
拿到懒人包压缩包后,千万不要直接在桌面压缩包内打开,一定要先右键选择“解压到当前文件夹”,或者解压到非中文路径的磁盘内(比如D:\Qwen3-TTS),避免因为中文路径导致模型加载失败、启动报错,这是新手最容易踩的坑,一定要记牢。
解压完成后,找到文件夹内的一键启动_语音克隆,双击即可运行,等待10-20秒,会自动弹出操作界面,全程自动加载模型,不用手动设置任何参数。
🎙️ 核心操作3步法:从零到导出音频
Step 1:界面基础设置,选对参数不返工
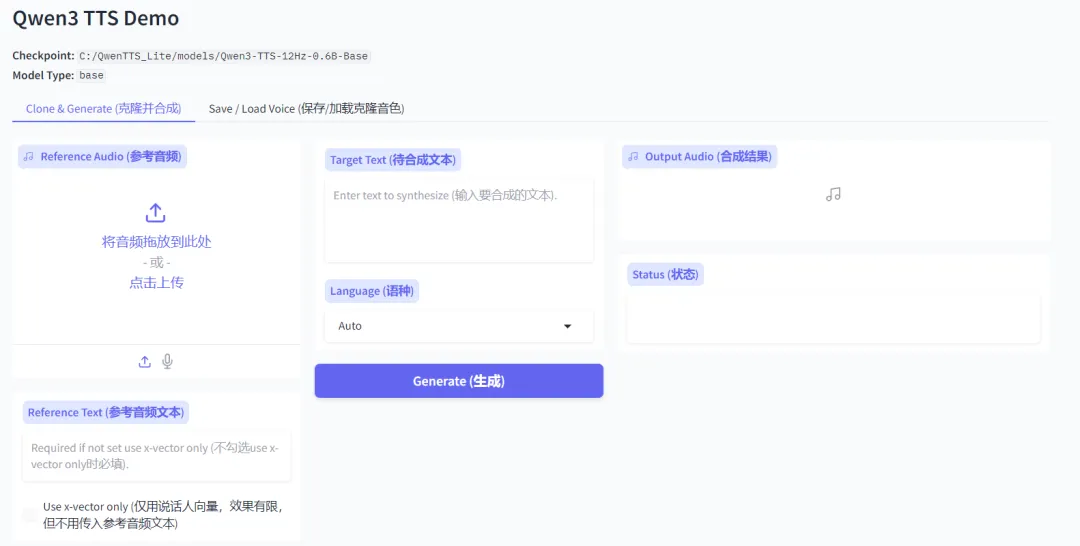
打开界面后,布局非常简洁,没有冗余按钮,新手先搞定基础设置,后续直接生成即可。
首先在左侧选择【点击上传】上传你参考的音频文件,然后在【参考音频文本】里面输入你这段音频的文字内容(参考音频建议使用20-30秒,这样更准确)
Step 2:文本输入和语种(长文本无压力)
在中间的【待合成文本】里面输入你要配音的文字内容,下面的语种可以选择你想要的,一般不动就可以了;支持长文本一次性粘贴,上万字的有声书文本、课件文案都能稳定合成,不会出现卡顿或中断,当然文字阅读,生成速度越慢。
这里给大家一个小技巧:文本内可以用标点符号控制停顿,逗号、句号、顿号会自动匹配正常说话停顿,想要长停顿可以直接加换行,不用额外标注停顿符号,合成出来的语调会更自然。另外尽量避免生僻字、特殊符号和乱码,防止发音不准确,遇到专业术语可以提前标注拼音,发音会更标准。
Step 3:一键生成与音频导出
文本输入完成后,直接点击下面的【生成】按钮,等待几秒到几分钟(时长根据文本长度决定,配置高的电脑1000字文本约1分钟生成)不要关闭窗口和使用浏览器做其他事情,满满等就可以了。
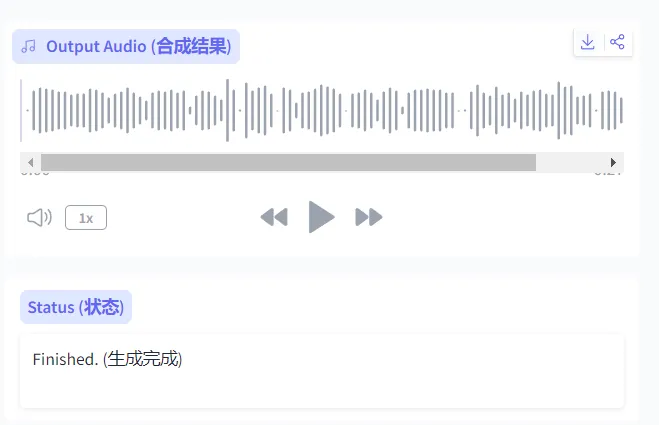
完成后,点击▲可以先听一遍整体效果,确认音色、语速、发音没有问题后,点击右上角下载即可;默认选择保存路径为(C:/Users/Administrator/AppData/Local/Temp/gradio/)导出的音频无水印、无背景噪音,音质高清,兼容性强,手机、电脑、剪辑软件都能直接导入使用。
🎭 进阶技巧:情感微调,更具人性化配音
不用复杂参数,直接在文本前加简单描述,比如“用温柔的语气朗读”“语速慢一点,带点伤感”,模型会自动识别调整,比普通配音工具的生硬情感调节自然太多,真正做到真人级的情感语言表达。
⚠️ 新手常见问题与避坑指南
常见问题解决:1. 启动失败:大概率是中文路径问题,重新解压到英文路径即可;2. 发音卡顿:关闭电脑其他占用内存的软件,重新生成;3. 音色失真:不要把语速调太快,保持0.9-1.1倍区间最合适。
这款懒人包全程无收费、无捆绑软件、无使用次数限制,本地离线运行,隐私性拉满,不管是短视频配音、有声书录制、课件制作、职场汇报,还是日常文案播报,都能完美适配,彻底解决配音难、配音贵的问题。
导演视角|专注AI技术实操、工具拆解、干货教程
后续会持续更新Qwen3-TTS的进阶玩法、其他AI工具实操教程,以及各类懒人包优化版,不想错过干货的小伙伴,记得星标关注,下期教大家如何从音频视频中提取文字,高效提升创作效率~
