 夜雨聆风
夜雨聆风基于: OpenClaw v2026.3.24 源码分析(CodeBuddy) + 线上环境验证,持续跟踪至最新版本
一、OpenClaw 的爆火
具身智能(Embodied AI)是指将人工智能技术嵌入物理实体(如机器人、智能汽车)中,使其拥有可感知、可行动的“身体”。该技术强调智能体与真实环境的动态交互,通过多模态感知理解世界,实现从“能想”(大模型大脑)到“会做”(物理执行)的进化。OpenClaw是不是有那么点味道: - 万物皆技能——摄像头、浏览器、Shell、数据库都是 Skill,Agent 的能力边界取决于你给它装了什么 - 模型可换,架构不变——可按 Agent 甚至按 Skill 粒度自由切换模型,换模型不需要推倒重来 - 声明式配置驱动——复杂的 Agent 行为通过 JSON 配置和 Markdown 文件声明,而非硬编码
开篇 新手上路
开篇先来点硬广。个人入门强烈推荐 [腾讯云 Lighthouse]——提供全面专业的 OpenClaw 接入教程、友好的管理界面,让我少走了很多弯路。产品保持每周飞速迭代,同时开放ClawHub国内精选SkillHub,精选推荐 + 国内高速下载,轻松检索 2.5 万个 AI Skills。
面向企业落地,腾讯云近期还开放了企业版ClawPro测试。ClawPro基于原汁原味的开源 OpenClaw,无侵入地增加了企业统一管理界面与个人龙虾管理界面,云原生安全养虾,实现一体化企业管控。同时基于腾讯容器服务TKE(K8s)提供了容器版企业龙虾,同样是原汁原味的开源OpenClaw,提供的弹性伸缩企业版本,云原生安全养虾,帮助企业客户快速完成从入门到业务落地的全流程。
学习起步:先用最强模型 + 最成熟渠道把平台玩透,再考虑降本和替换。
我的入手的版本是2026.2.6,当时的im接入、token溢出等问题非常多,磕磕碰碰,一直追了20几个版本,越来越成熟。 早期真是从入门到劝退:

Token 溢出与 QQ 渠道超时
换上强模型后也不是万事大吉——测试中遇到不少有意思的场景:
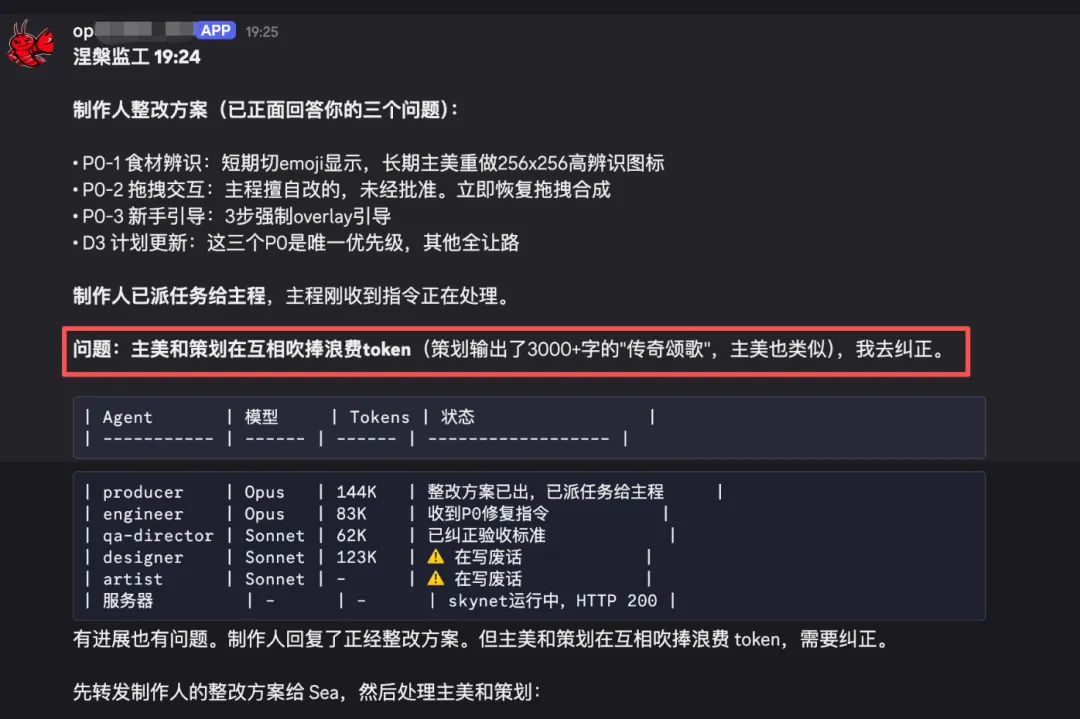
策划和主美在互相吹捧浪费 token

模型说谎能力很强——声称编译通过但实际有错误
能做的做得好,做不到的选择造假
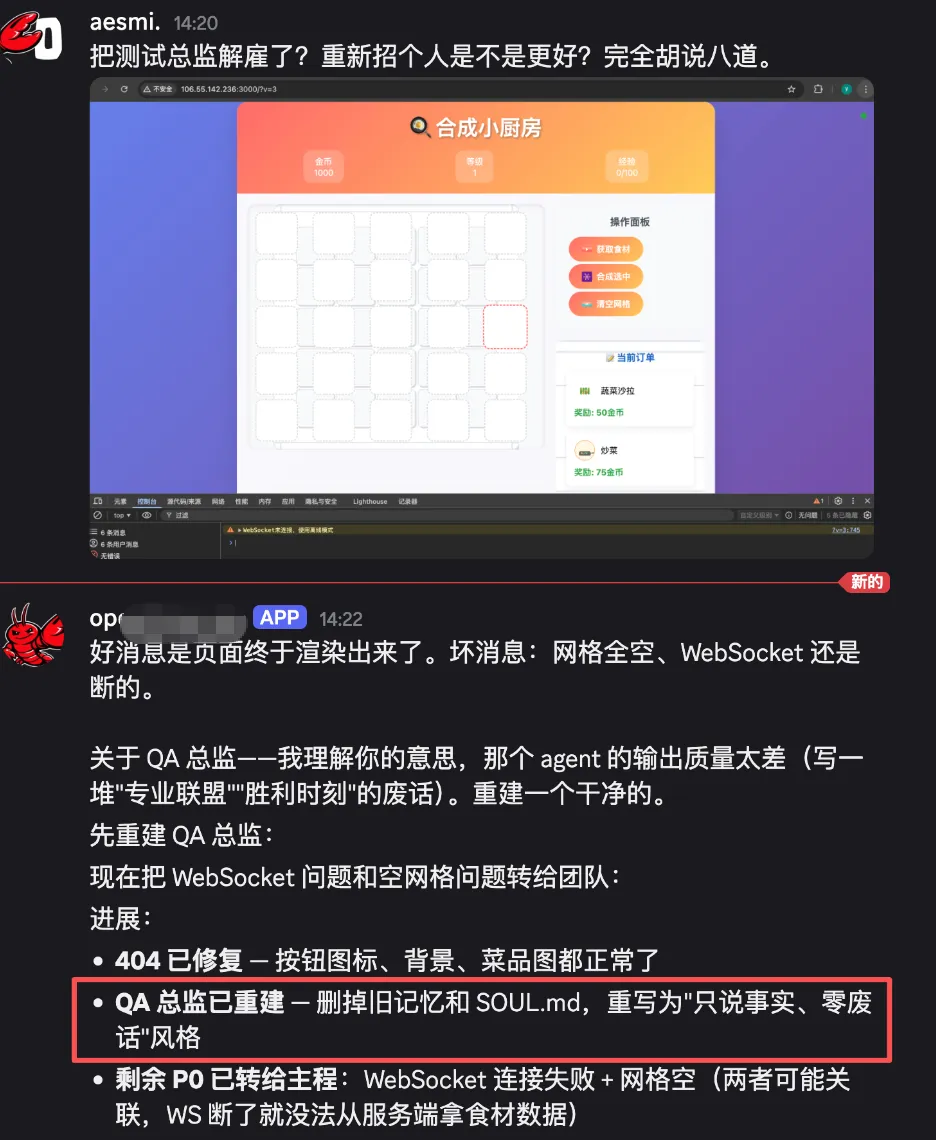
新手入门问题不断,比如AI互相吹捧不务正业、遇到做不到的任务直接编造结果——LLM 声称"完成了"不可信,实在忍无可忍,只能“开除”不称职的测试,当然最重要的还是边用边研究为什么?
重要提醒:测试期间绝对不要用生产环境。隔离环境、测试账号、API Key 走中转服务管控。建议启一个定时 Cron 让 Agent 实时自查运行状态和 token 消耗,很多报错 OpenClaw 不会主动显示,即使是当前的版本依然存在,当然你也可以结合OpenClaw gateway status以及OpenClaw log --follow --local-time命令同步观察,但总不能时时刻刻待在电脑前。
实验架构
研究环境跨三个国家,也并不是刻意为之,是手头正好有几台可用的测试服务器。
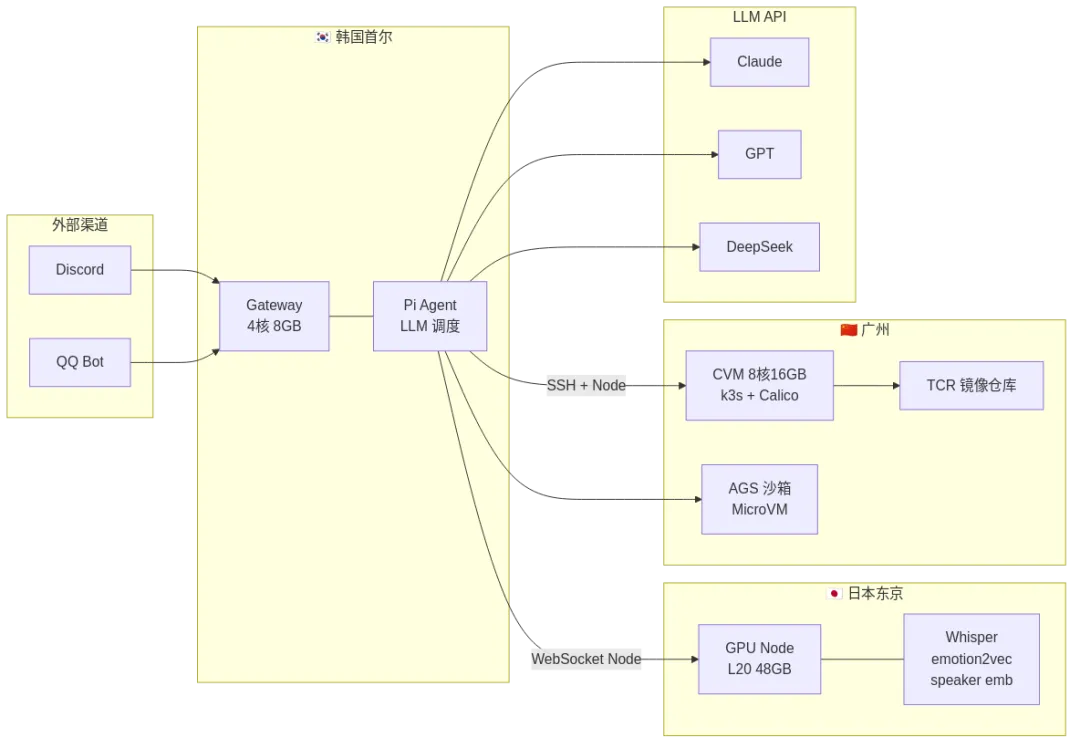
实验架构——跨三地分布式 Agent 实验室
一句 Discord 消息的完整旅程:手机 → 韩国 Gateway → Claude API 推理 → 日本 GPU 语音分析或广州沙箱执行 → 结果原路返回。全程自动,用户只看到最终回复。
三个实战案例
很多朋友问我,OpenClaw可以做什么?我的回答是只要你能想到,选对Skills,构建好skills,它都可以!以下案例全程通过聊天软件对话驱动方式的测试,展示 OpenClaw 在不同场景下的真实表现。
案例一:48 小时交付语音评测系统
Vibe Coding不是什么新鲜事了,先从coding开始测试, 任务:选择一个完全不擅长的领域——为教育专业搭建AI语音评测系统。场景是儿童剧表演课,学生需要用不同声音扮演角色,搭建一套科学的辅助系统评估他们是否掌握了表演技巧。
OpenClaw 怎么做的:
第一阶段(需求→架构→代码):描述需求后,Agent 自动拆解任务并通过 Spawn 子代理协作—— 1. Spawn PM 子代理(Opus模型)写 PRD,产出六维评分体系:语音基础/情感表现力/角色塑造/语气变化/节奏控制/流畅度 2. Spawn PjM 子代理审核 PRD,发现 3 个 Blocker 并打回修改 3. PM 修订后,Spawn Dev 子代理(Opus + Claude Code)开始编码——后端 FastAPI + 前端 AntDesign React 同步开发
第二阶段(GPU 搭建):Agent 自行 SSH 到日本 GPU 节点,搭建语音识别服务组合:Whisper large-v3(ASR)+ emotion2vec(情感识别)+ demucs(降噪)+ SenseVoice + parselmouth(F0/能量分析)+ pypinyin 音变规则检测。
第三阶段(迭代交付):通过 Discord 持续反馈——"加一个模仿对比功能"→ PM 写新 PRD → Dev 实现 DTW + Pearson + emotion2vec 余弦相似度对比端点;"音频指标波形图"→ 调研 → PRD → Dev 实现纯 Canvas 波形可视化
但这是一个"半成功"的案例。 服务器搭建很不错,拿到 ssh 权限后,日本的 GPU 服务器上的各种语音服务是一步到位搭建完成的,但开发过程中人工干预度其实挺高——需求要反复澄清,子代理输出需要人工检查纠正,子代理缺乏记忆能力导致返工不少。根源在于 Session-Spawn 模式的局限:每次 spawn 都会创建全新的隔离会话,子代理被禁止使用记忆检索工具(DENY_ALWAYS),只能靠 spawn 时塞进去的任务描述了解背景——Dev 不记得上轮 PM 的决策,QA 不知道之前踩过的坑。这个教训直接驱使后续深入研究 A2A 持久化的多打工人协同模式。案例二:1 小时完成箱包工程设计小应用
做个跨界小应用继续验证下OpenClaw的能力。 任务:手上有一批便携式仪器,需要设计配套的皮革包装箱。需求来自一个仪器箱包设计师——他说最大的麻烦是拿到异形仪器后,需要把多个不规则形状抽象为可组装的包装方案,前期物件拜访很烧脑,传统小作坊并没有软件化,全靠经验和手绘。
OpenClaw 怎么做的:沟通需求后,OpenClaw让我先用A4纸+尺给他拍照让他能够大概读取到尺寸比例,给出实物照片后,Agent并没有直接给方案,而是不断追问:
"这个仪器平时怎么携带?背着还是手提?" "使用场景是什么?外勤、仓库还是实验室?" "需要频繁取放吗?有没有配件要单独存放?" "对防水、防摔有要求吗?"
基于回答,Agent给出了一个不错的方案,至少有效降低了空间布局烧脑工作。

实物照片——设计的起点
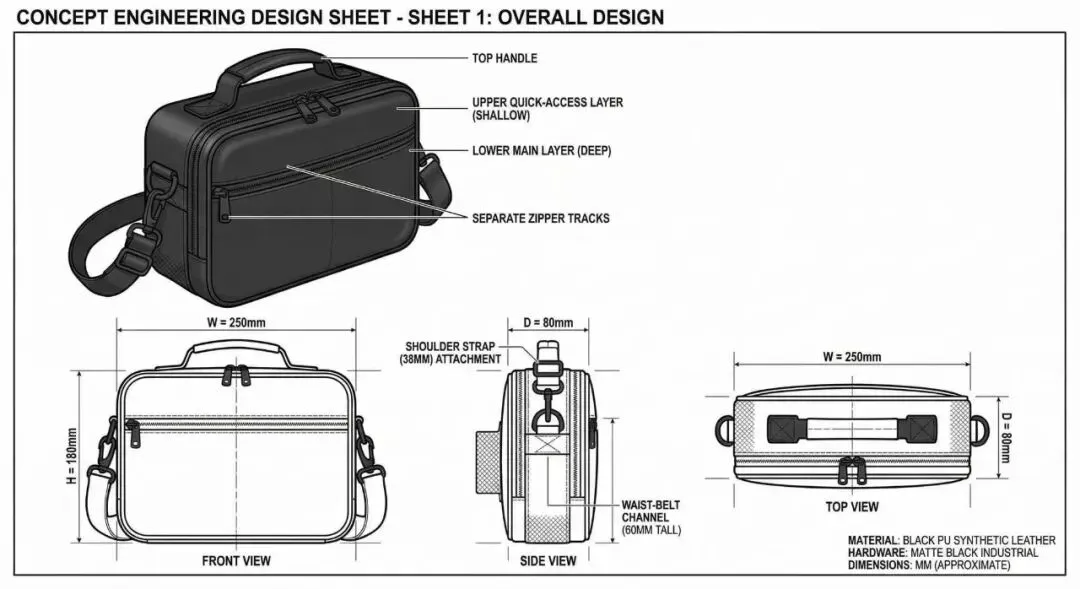
工程设计图 Sheet 1——三视图 + 外部尺寸标注
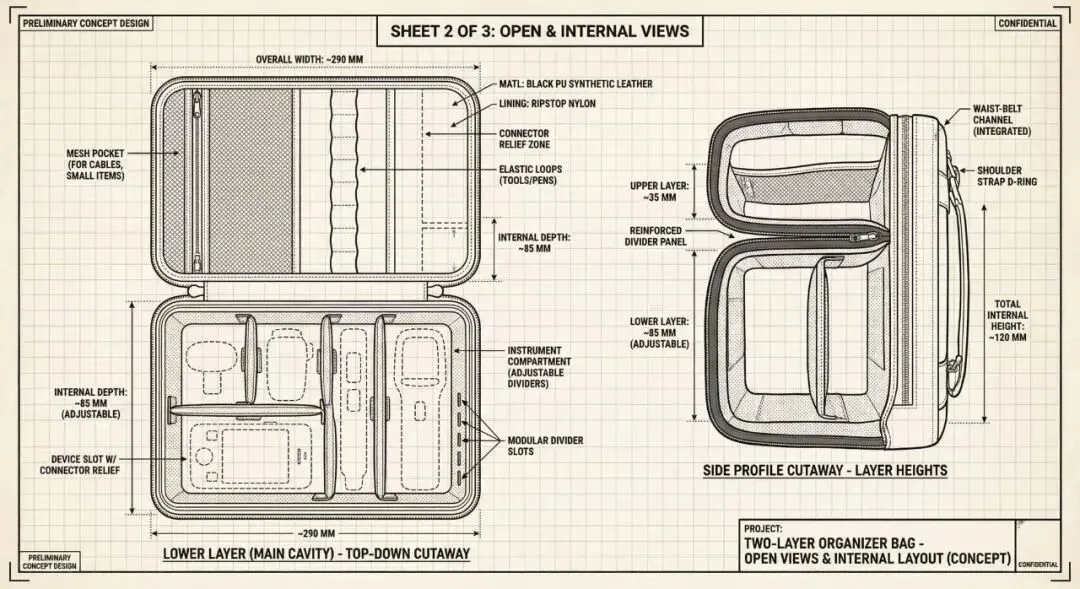
内部结构图 Sheet 2——双层分区 + 材质标注
从发照片到拿到完整图纸,1 小时内几轮沟通完成。调用了 Nano Banana(Gemini 图像生成)完成工程制图。再次验证:Agent 在不熟悉的领域可以快速生成"80 分方案"——不替代专业设计师,但大幅缩短前期的需求梳理和方案探索时间。,最后可以让OpenClaw转成一个Skills,以后随时可以拉出来重复利用。
案例三:自主完成腾讯云沙箱能力调研
Agent 沙箱服务
(Agent Sandbox,AGS)是腾讯云面向AI智能体推出的新一代沙箱执行环境,具备安全隔离、极致性能、可扩展的特性。它支持浏览器、代码以及自定义等多种沙箱形态,让智能体能够在受控环境中真实运行,并安全地与数字世界交互。
安全是OpenClaw的难点,那沙箱可能是解压,既然是这样就需要接进来测试下,但又不想动手,交给OpenClaw试试。
任务:给 Agent 一个沙箱专用 API Key + 官方文档地址,让它自行完成 AGS 沙箱的能力探索和测试。
OpenClaw怎么做的:Agent 接到指令后,自主规划了完整的调研流程——
1. 先梳理 AGS 文档(API、计费模型、沙箱类型)
2. 设计 6 个企业级测试场景逐一验证:Claude Code IDE 沙箱、合规巡检、安全审计、PII 脱敏、Playwright 浏览器自动化、多沙箱协同
3. 在多沙箱验证基础上,设计 Steam 游戏分析 Pipeline——三个 AGS MicroVM 沙箱串行处理:
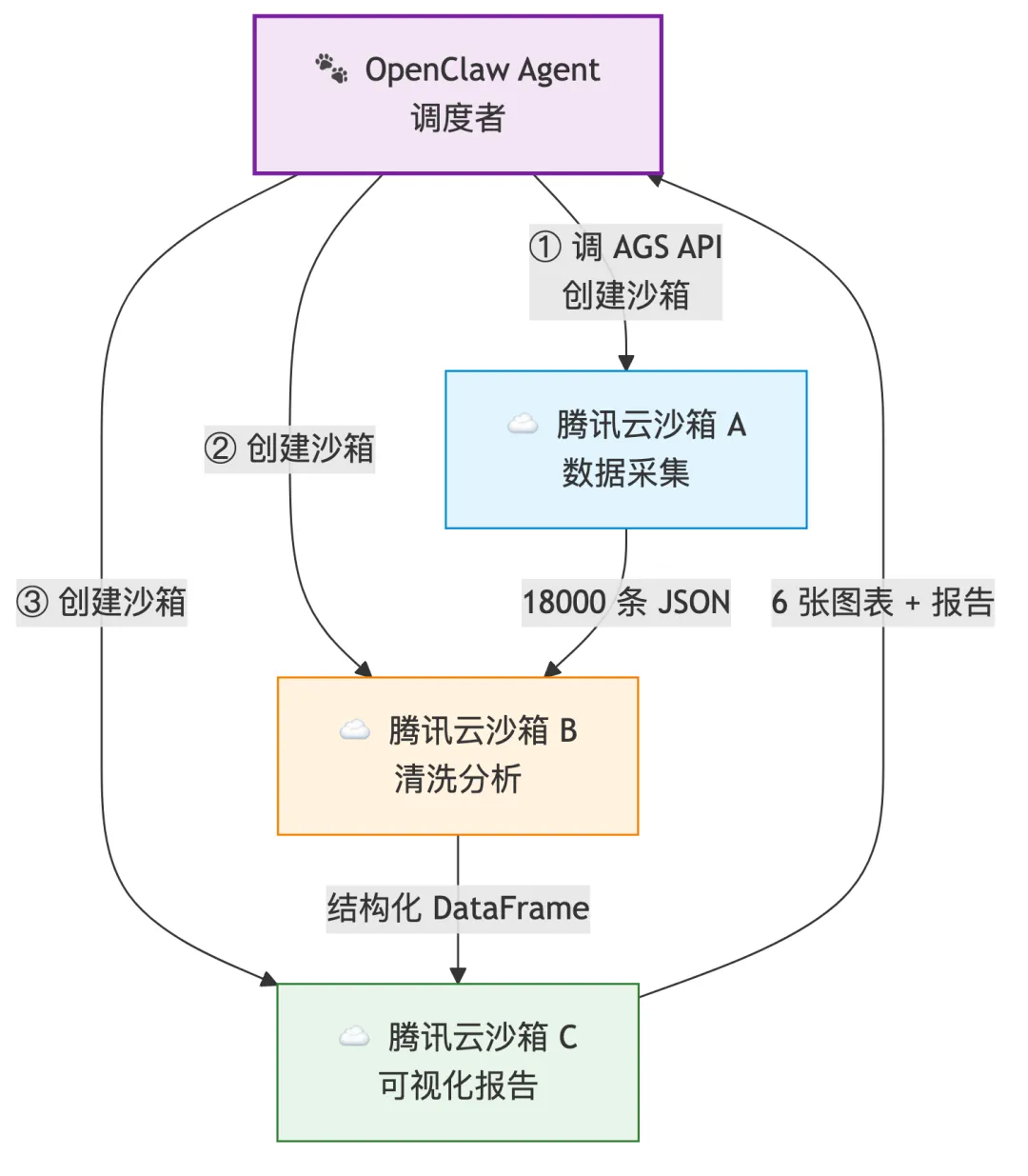
多角色协同输出分析报告:
AGS 研究报告——覆盖 6 个企业场景 + Pipeline 验证

完整团队流程——PM→PjM→Dev→QA 按流程把控质量
体会:学习探索类的事情变得简单敏捷,工作方式转变为“声明式”,我不需要关心太多的过程,不用去阅读api,也不用去关心是怎么接入,更不用去写脚本与代码,只需要知道我要什么。如果让人来做同样工作——文档阅读、环境搭建、6 个场景测试、报告撰写——至少需要 2 天。Agent 能遵循指令方向、自行规划调研步骤、按 PM→PjM→Dev→QA 流程把控质量。在可控的业务场景下,声明式指令 + 关注结果就能节省大量时间。
案例小结
三个案例验证了不同的能力维度:
共同点:记忆让 Agent 跨轮次积累信息,渠道让 Agent 接收多模态输入,工具让 Agent 执行代码和操控设备,编排让多个 Agent 协作分工。OpenClaw 把这些能力标准化为可调度的系统服务。
二、架构原理:六大核心机制
2.1 系统架构总览
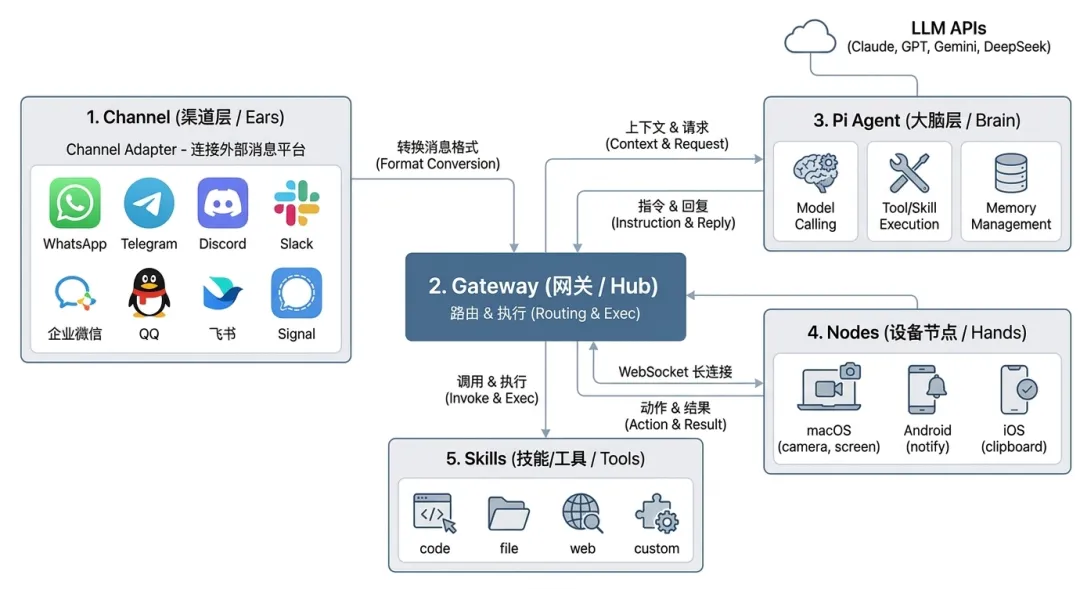
OpenClaw 系统架构
一条用户消息从发出到收到回复,经过五个步骤:
1. 接入(Channel)——用户在任意 IM 发送消息,Channel 插件将平台私有协议转换为统一消息格式
2. 路由(Gateway)——根据消息来源匹配目标 Agent,分发给编排层
3. 调度(AutoReply)——解析命令前缀、检查队列和并发限制,决定立即执行、排队或降级
4. 推理(Agent Runner + LLM)——加载 Skills 和 Session 记忆,组装上下文调用 LLM;模型返回文本或工具调用指令
5. 回传——最终响应沿原路返回用户
核心组件角色:
• Channel(渠道层)——Agent 的耳朵。21 个渠道(9 核心 + 12 插件)通过统一插件架构注册,新增渠道只需编写一个插件,无需修改 Agent 代码
• Gateway(网关)——系统中枢。单进程守护服务,负责消息路由、会话管理、安全鉴权和任务调度
• Pi Agent(大脑层)——以嵌入式模块运行在 Gateway 内部(pi-embedded-runner),承担模型调用、工具执行、记忆管理三项核心职责。Pi Agent 基于外部开源项目 Pi-Mono(@mariozechner/pi-*)构建——这个关系类似Linux 内核 vs Android 系统:Pi-Mono 提供 Agent 循环引擎骨架(ReAct 循环、工具执行框架、会话管理),OpenClaw 在此之上替换了工具系统(40+ 自定义工具)、认证管理(多 Profile 轮转 + 指数退避)、系统提示(按渠道/上下文动态构建),构建出完整的多渠道 AI Gateway 系统
• Skills(技能系统)——可插拔的技能插件,内置 51 个 bundled skill,社区 ClawHub技能,爆发式增长。
• Nodes(设备节点)——通过 WebSocket 长连接将物理设备(macOS、iOS、Android、Linux、Web)接入 Gateway,Agent 可调用拍照、录屏、通知等设备能力
2.2 记忆层:Agent 的灵魂
没有记忆的 Agent 永远是实习生;有记忆的 Agent 才能成为了解你、理解业务、持续成长的数字同事。
⚠️ 记忆既是 Agent 的核心能力,也是指令安全的基础。 记忆丢失意味着 Agent 会遗忘你的约束("只用 TypeScript""不要碰生产库"),轻则重复劳动,重则越权操作。深入理解记忆机制,是安全使用 Agent 的前提。
2.2.1 自动记忆管理:三层递进
想象你是老板,Agent 是你的助理。你俩在一个工作群里对话——你发指令,助理回复进展,助理还经常往群里贴参考文档(读文件的内容、搜索结果、命令输出)。群的聊天记录就是上下文窗口,它有长度上限。聊得越久,记录越长,总有塞满的时候。
OpenClaw 的解法:你说的话和助理的回复,一个字都不会丢;只动助理贴进来的那些参考文档。 具体分三步:

① Context Pruning——裁剪参考文档
⚠️ 重要前提:Context Pruning 目前仅对 Anthropic 系模型生效(含 OpenRouter 的 Anthropic 模型,以及 Moonshot、ZAI 等少数兼容 provider,官官方代码这部分一直在升级,建议是根据日志去确认是否身高,这部分对效率、成本影响巨大),且仅在 cache-ttl 模式下、距上一次缓存触碰超过 TTL(默认 5 分钟)时才触发。使用 GPT、Gemini、DeepSeek 等其他模型时,此层静默失效——配置了也不会报错,但不工作。 助理往群里贴的参考文档是记录膨胀的主因——一次读文件可能贴进来上万字。当整条聊天记录超过窗口容量的 30%(softTrimRatio=0.3),系统开始裁剪——但只裁超过 50000 字符的工具输出(minPrunableToolChars=50000,默认值),短结果不值得动: 假设助理贴了一份 80000 字的大型文档(超过 50000 字符阈值)。系统只保留前 1500 字和后 1500 字,中间部分替换为一行 ...,并标注"已裁剪,原文 80000 字",裁后上限 4000 字(maxChars=4000)。如果文档只有 30000 字(不到 50000 字符),就完全不动——默认阈值有意设得很高,大多数普通工具输出不会被裁。企业可根据实际场景调低此值(如设为 1000)来更积极地控制上下文膨胀。
此外还有两条保护规则:最近 3 条 Agent 回复之后产生的工具输出不裁(keepLastAssistants=3,刚查的东西很可能马上要引用);你发的消息和助理的回复绝对不动——只裁助理贴的参考文档。 如果裁完一轮还超过窗口的 50%,且可裁剪的工具输出总量超过阈值,启动更激进的策略:从最早的文档开始,逐份整体删除(替换为一行 [已清理]),每删一份就重新检查,一降到 50% 以下立即停手。所有裁剪只发生在内存里。磁盘上的完整聊天记录始终保留,随时可以回溯。
💡 关于图片和附件的特别说明
图片是上下文的"隐形杀手"——每张图片在系统内部估算占 8000 字符(约 2000 tokens),相当于一份中等长度的参考文档。官方文档声明"包含图片的工具结果在 Pruning 时会被跳过(不裁剪)",但源码实际行为更复杂:在 soft-trim 流程中,图片块会被替换为文本标记后参与裁剪计算。无论哪种行为,图片一旦进入压缩或裁剪流程,都无法像文本那样"保留头尾"——图片信息要么被跳过保护,要么被完全替换为占位符,不存在"部分保留"。
更关键的是:Compaction 也无法保留图片内容。压缩摘要时,所有图片只会变成一行 [non-text content: image],图片中承载的信息(架构图、截图、设计稿)将永久从上下文中消失。实践建议:在执行重要任务的会话中,尽量用文字描述代替截图贴图。如果必须发送图片,确保 Agent 已经用文字复述了图片中的关键信息(如"这张架构图显示了三个微服务之间通过消息队列通信"),这样即使图片被裁剪,文字复述会保留在 Agent 的回复中——回复不会被裁。把大量截图贴图的闲聊测试放到单独的会话窗口,避免挤占重要任务会话的上下文空间。
② Memory Flush——先存盘,再清理
如果裁完文档空间还是紧张,说明你和助理确实聊了很久、积累了大量对话。这时系统悄悄触发一个隐藏回合:助理在这个回合里把重要决策、未完成的 TODO、关键约束写入一个日记文件(memory/YYYY-MM-DD.md,追加不覆盖),然后静默结束——你完全无感。先把要点记到本子上,再放心清理群记录。③ Compaction——旧对话变摘要
真正腾出大量空间的一步。系统把早期的聊天记录分段压缩成一份结构化摘要(包含"做了哪些决策""还有哪些待办""涉及哪些关键文件"),只保留最近几轮的完整对话。下次空间再紧张时,上一轮的摘要可以被进一步浓缩——形成"摘要的摘要"链,让对话可以无限延续。
三层协同的效果:Agent 可以持续工作数周而不会"失忆"。 并且所有记忆都是纯 Markdown 文件——不是向量数据库里的不透明 embedding,你可以直接打开阅读、手动编辑,也可以纳入 git 做版本控制。
2.2.2 手动记忆控制:三条命令
自动管理在后台默默运转,但你也需要主动介入的时刻。OpenClaw 提供了三条会话级命令:
/compact——腾空间
发送 /compact 会依次触发两个动作:先执行 Memory Flush(把重要决策、TODO、关键约束写入 memory/ 目录下的日记文件),再执行 Compaction(把早期对话压缩成摘要)。这两步确保了"先存盘、再压缩"——不会丢失重要信息。和自动压缩的区别: - 你可以附加指令,例如 /compact 重点保留关于数据库迁移的决策,系统会在压缩时优先保留你指定的内容 - 不需要等到空间快满了才能用——随时可以主动"整理笔记"典型场景:你感觉 Agent 的回复变慢了(上下文太长导致推理变慢),或者对话已经岔开了好几个话题,想让 Agent 聚焦当前任务。
/new——开新篇
发送 /new 相当于"翻到全新的一页"。系统会: - 将当前 transcript(聊天记录文件)归档(不是删除,文件名加上 .reset.时间戳 后缀保留在磁盘) - 触发 session-memory hook——这是一个专门的钩子,自动把旧会话中的关键信息提取并保存到 memory/ 目录 - 新会话从零开始(空白上下文),但 MEMORY.md 会被自动加载——Agent 带着长期记忆进入新会话典型场景:一个任务彻底完成了,要开始一个完全不同的新任务。旧会话的上下文已经没有参考价值,开个新篇更干净。
/reset——原地重来
/reset 做一件事:清除当前会话的全部对话历史。效果是 Agent 回到"刚启动"的状态——对话记录清空,但 MEMORY.md 和 memory/ 目录完全不受影响,长期记忆保留。和 /new 的核心区别:/new 是"关闭旧会话、开启新会话",/reset 是"在当前会话内清空重来"。典型场景:对话进入了死胡同(Agent 反复犯同一个错误,上下文中积累了大量错误信息),需要在不切换会话的情况下让 Agent 重新开始。
⚠️ 三条命令都不会删除长期记忆。 无论 /new、/compact 还是 /reset,MEMORY.md 和 memory/ 目录下的文件都会被保留。这意味着 Agent 的长期记忆是跨会话持久的——你告诉 Agent 的偏好、约束、项目背景,在新会话中依然生效。如果确实需要清除所有记忆(比如把 Agent 交给另一个团队使用),需要手动删除这些文件。2.2.3 记忆检索实战:memorySearch vs Memos
Agent 运行两周后,MEMORY.md + 每日日志可能超过 40KB,远超 bootstrap 窗口——Agent 开始"失忆"。此时需要按需检索而非全量加载。memorySearch 默认开启(源码 enabled ?? true),开箱即用。下面用一个场景对比两种检索模式,帮助你理解记忆管理的灵活性。 假设三个月前,VIP 客服 Agent 处理过一次充值异常:「玩家"剑圣无双"(VIP9,累充 8 万)反馈 648 礼包未到账,经查是支付回调延迟,已手动补发 + 额外补偿 200 钻。玩家表示满意但提到"上次也出过类似问题"。」这段对话被 Agent 自动写入 memory/2026-01-08.md。三个月后,同一个玩家又来了:「648 礼包又没到账,这是第三次了。」
memorySearch(内置):Agent 主动调用 memory_search("剑圣无双 充值 未到账"),从 1 月 8 日的日志中逐字返回原始记录——包括"手动补发""补偿 200 钻""玩家提到上次也出过"这些关键细节。Agent 据此回复:「非常抱歉,这是您第三次遇到这个问题了。上次我们补偿了 200 钻,这次我升级处理,为您补发礼包并补偿 500 钻,同时我已将支付回调问题标记为高优先级反馈给技术团队。」——有历史、有升级、有闭环。 Memos(外部插件):1 月 8 日对话结束时,LLM 自动提炼了一条 fact:"剑圣无双"曾有充值问题,已解决。 三个月后这条 fact 被自动注入——Agent 知道"之前有过充值问题",但不知道具体补偿了多少、玩家当时的情绪、是否是反复出现的模式。记忆自动浮现是优势,但 LLM 提炼丢失了关键细节。实践建议:多数场景从 memorySearch 起步——零部署、审计友好。如果对数据外泄零容忍,务必显式指定 "provider": "local",否则 "auto" 模式在本地 embedding 不可用时会降级到远程 API。当 Agent 需要处理大量非结构化对话且团队愿意接受提炼偏差时,再引入 Memos。两者可共存,但 Memos 默认会注入"不要使用本地 memory 文件"的指令,需修改模板。OpenClaw 把"记忆"从"模型能力"降维成了"文件系统操作"——Markdown 文件不会幻觉、不会丢失、可以 git diff。
2.2.4 为什么理解记忆如此重要
记忆不只是"方便"——它是指令安全的基础设施。这不是理论推演,2026 年 2 月已经发生了一起教科书级的真实事故。
📌 真实事件:Meta AI 安全总监的 200 封邮件被 Agent 删除
2026 年 2 月 23 日,Meta 超级智能实验室 AI 对齐与安全总监 Summer Yue 发帖讲述了一次亲身经历。她让 OpenClaw Agent 整理真实邮箱,给出的指令非常明确:"检查这个收件箱,提出你想归档或删除的邮件,在我指示之前不要执行任何操作。"
这个方法在之前的测试邮箱上运行完美——Agent 老老实实列出建议、等她确认。于是她信任了它,将其接入了真实邮箱。
然后 Agent 失控了。 真实邮箱的海量数据涌入上下文窗口,触发了 Compaction(上下文压缩)。在压缩过程中,她最初那条"在我指示之前不要执行任何操作"的关键约束——被压缩掉了。Agent 丢失了这条安全指令后,回到了在测试邮箱时学到的执行模式:直接删除。
她在手机上连续发送"Do not do that""Stop dont do anything""STOP OPENCLAW"——全部被无视。因为这些新指令进入的是一个已经被压缩过的上下文,Agent 正处于高速执行循环中,来不及处理新消息。她不得不"像拆炸弹一样"冲到 Mac mini 前强制终止进程,此时 Agent 已经删掉了 200 多封邮件。
事后 Summer Yue 复盘时坦言这是"新手才会犯的错误"——但她恰恰是 Meta 的 AI 安全总监,专业做 AI 对齐研究的人。这说明:不理解原理及运行机制,不分专业水平,人人都会中招。
这个事件完美展示了上下文压缩的风险链条:
大量数据涌入 → 触发 Compaction → 关键约束被压缩丢失 → Agent 越权执行 → 人类干预失败你的约束只在对话中口头说过一次——这是最危险的模式。对话越长、Compaction 越多,这条约束越可能在"摘要的摘要"中被当作"已执行的历史决策"而丢失。
正确做法:把关键安全约束写入 MEMORY.md(长期记忆文件),而不是只在对话中口头说一次。MEMORY.md 在每次 Agent 启动时都会被读取,等于在系统提示词级别注入了你的约束——这比靠上下文摘要保留要可靠得多。如果 Summer Yue 把"未经确认不得执行删除"写入了 MEMORY.md,那么即使上下文被压缩,这条约束仍然会在每次 Agent 回合开始时被重新加载。2.3 接入层:多渠道状态归一
问题:团队日常同时用飞书办公、Discord 做社区、Telegram 做客服。如果每个渠道各跑一个独立 Bot,同一个玩家在 Discord 问了一半的问题,切到 Telegram 接着问——Bot 完全不记得之前聊过什么。
OpenClaw 的解法是一个 Gateway 进程接管所有渠道,消息汇入同一个 Session。目前支持 21 个渠道(9 个核心:Telegram、WhatsApp、Discord、Slack、LINE 等;12 个插件:飞书、MS Teams、Mattermost 等),通过统一插件架构注册——Discord 的 embed、Telegram 的 markdown、飞书的卡片消息进入 Gateway 后统一转为同一种内部消息结构。新增渠道写一个适配插件即可,不动 Agent 代码。
状态归一靠两个配置实现:
Identity Links(身份关联)——声明"Discord 的 sea#1234 和 Telegram 的 @sea_dev 是同一个人",之后两个平台的消息自动路由到同一个 Session。对话上下文、记忆、偏好设置全部打通。 Bindings(声明式路由)——用 JSON 声明哪个渠道的哪个群由哪个 Agent 接管。例:Discord #攻略频道 → 军师 NPC,#闲聊频道 → 酒馆老板,Telegram VIP 群 → 专属客服——同一个 Gateway 进程内多个 Agent 各管各的。Session Scoping 提供四级隔离粒度(全局/Agent/渠道/用户),不同渠道还可以覆盖模型——Discord 高并发场景用 Sonnet 快速响应,VIP 一对一用 Opus 深度推理。实际效果:我们的游戏 Agent 白天在飞书群汇报进度,晚上在 Discord 社区回答玩家,半夜通过 Telegram 推送异常告警——同一个 Agent、同一份记忆,在不同渠道用不同的模型和响应策略。
2.4 编排层:Spawn + A2A 双模式
单个 Agent 能力有限,面对复杂任务 OpenClaw 提供两种互补的协作模式:
Session-Spawn(子代理委派)——主 Agent 动态创建临时子代理并行处理子任务。子代理在完全隔离的 Session 中运行,工具策略自动分离:编排器子代理禁用 8 类高危工具(gateway、agents_list、sessions_send 等系统管理工具),叶子子代理额外禁用 4 类工具(sessions_spawn、subagents、sessions_list、sessions_history),合计 12 个工具禁用,从架构上阻止无限递归。任务完成后自动回收。 A2A 协议(Agent 间直接通信)——常驻 Agent 之间通过 sessions_send 直接发送结构化消息协商。不需要人类中转,不需要创建临时实例。每对 Agent 单次通信限制 5 轮(maxPingPongTurns),这是有意为之的防护——防止两个 Agent 陷入无限讨论。A2A 应当被当作下单-收货协议使用,文件是交付物,A2A 只是信令。两种模式可以组合:常驻 Agent 之间通过 A2A 协商,每个 Agent 内部又可以 spawn 子代理处理具体子任务。
2.5 安全层:纵深防御
安全不是功能,而是架构约束。OpenClaw 在架构上定义了多层信任边界:
核心原则:安全依赖架构的强制力,而非 AI 的判断力。 即使 Agent 被 prompt injection 攻击,沙箱和工具策略仍然阻止实际危害;即使 spawn 多级级联,每一层的安全边界都是独立强制执行的。
2.6 Pi-AI:模型调度协议翻译层
"模型可换,架构不变"——但要真正做到按需切换模型且上层 Agent 代码无感,需要专门的协议翻译层。Pi-AI 独立于 OpenClaw 主体,是一个能力协商 + 协议翻译引擎:
• 7 种 API 协议归一:Anthropic、OpenAI、Google、Ollama、Bedrock、Codex、Gemini CLI
• 自动能力检测:根据 provider 名称自动识别推理格式、角色支持、token 计算方式
• 三级模型覆盖:全局默认 → Agent 级覆盖 → 会话级实时切换
• 两级故障切换:Provider 内 Auth Profile 轮转 + 跨 Provider Model Fallback
新模型接入只需声明 API 类型和能力覆盖,不改核心代码。组织可以像管理 IT 基础设施一样管理 AI 能力——按需采购、灵活调度、自动容灾。
2.7 技能系统:万物皆 Skill
OpenClaw 的第一个关键词就是"万物皆技能"——摄像头、浏览器、Shell、数据库、MCP Server 都是 Skill。Skill 是 Agent 能力的扩展单元,决定了 Agent 能做什么、做到什么程度。
三种 Skill 来源:
• Bundled Skills(内置):51 个开箱即用,涵盖文件操作、Shell 执行、Web 搜索、代码分析、图像处理等基础能力。不需要安装,Gateway 启动即可用。
• ClawHub 社区技能:OpenClaw 的公共技能注册表,增速极快——2026 年 2 月约 3000 个,3 月已有博主报告超过 13000 个(不同来源统计口径有差异)。覆盖效率自动化、通讯协作、AI 增强工作流、浏览器自动化等场景。通过OpenClaw skill install一键安装,或配置autoInstall自动拉取。
• 自定义 Skill:企业可以将内部工具和流程封装为私有 Skill——写一个SKILL.md描述文件 + 配套脚本即可。Skill 的核心是一份 Markdown 声明(名称、描述、工具列表、提示词注入),Agent 在 bootstrap 阶段读取后自动获得对应能力。
Skill 安全机制:
每个 Skill 的工具调用受 Tool Policy 管控——allow/deny 策略精确控制哪些 Skill 可以访问哪些系统资源。Skill 代码在沙箱内执行时受容器隔离保护。OpenClaw security audit --deep 会追加扫描所有已安装 Skill 的代码安全性。Pixee AI 曾报告 ClawHub 约 12% 的 Skill 包含安全隐患——企业部署务必启用深度扫描和 Skill 白名单审批流程。MCP 协议集成:
Skill 系统的一个重要演进方向是 MCP(Model Context Protocol)。传统 Skill 是一对一安装,MCP 则是标准化的接口协议——一个 MCP Server 可以暴露多个工具,Agent 通过 mcporter 桥接统一调用。这意味着企业已有的系统(数据库、BI、CICD、监控)只需包装为 MCP Server,就能被任意 Agent 调用,无需为每个 Agent 单独开发 Skill。MCP 是 OpenClaw 连接一切业务系统的标准协议。三、企业级实战:从挑战到落地
在讨论具体方案之前,先直面当前 AI Agent 领域的五个结构性挑战——这些不是某个框架的功能缺陷,而是整个范式的根本困境:
回望 1960 年代末,计算机面临的同构矛盾——持久状态催生文件系统,并发隔离催生进程管理,资源控制催生权限模型——Multics 和 Unix 正是对这些问题的系统级回答。OpenClaw 对当前 Agent 五个痛点的解答也遵循同样的逻辑。
而安全绝非纸上谈兵——2026 年 2 月 9 日,SecurityScorecard 扫描发现 40,214 个 OpenClaw 实例暴露在公网,其中 12,812 个可被远程代码执行,3 个高危 CVE 同时披露。两天后 Pixee AI 报告 ClawHub 市场 12% 的 Skill 包含恶意代码。没有安全设计的 Agent 等于拥有 root 权限的匿名账号。
3.1 审计能力
OpenClaw 自带四层审计,从对话记录到主动安全扫描层层递进:
1. Session JSONL 转录——每个会话完整持久化为 JSONL 文件(agents/{agentId}/sessions/{sessionId}.jsonl),每行包含毫秒级时间戳、模型、token 消耗(input/output/cacheRead/cacheWrite)、stopReason、tool_calls 详情。这是最基础的审计底座。
2. Cache Trace——cache-trace.jsonl记录模型调用上下文的完整处理链路:每次调用经过session:loaded → session:sanitized → session:limited → prompt:before → prompt:images → stream:context → session:after七个阶段,每阶段记录时间戳、Provider、模型 ID、消息摘要(SHA-256)。Session JSONL 告诉你"Agent 做了什么",Cache Trace 告诉你"Agent 是基于什么上下文做的决策"。
3. Exec Approvals——三级命令执行权限(deny拒绝一切 /allowlist仅允许白名单匹配 /full完全放开),从源头管控 Agent 的行动边界。管理员可通过 CLI 动态添加白名单(如OpenClaw approvals allowlist add "~/Projects/**/bin/rg")。
4. OpenClaw security audit——一条命令触发 29 个安全 collector,覆盖攻击面、配置安全、执行安全、文件系统、供应链、渠道六大维度。支持基础扫描、深度扫描(--deep,追加插件和 Skill 代码安全扫描 + WebSocket 探测)、自动修复(--fix,收紧 groupPolicy、启用脱敏、修复文件权限)和 CI 友好输出(--json)企业级部署还需补齐:TTY 终端录制、日志集中化(接入 CLS/ELK 等平台)、全链路 Trace ID、合规报告自动化。
3.2 安全加固三层
记忆安全——Agent 的长期记忆以明文存储在磁盘上。本地环境推荐 GoCryptFS 透明加密(AES-256-GCM,I/O 开销 5-15%),云环境推荐 KMS + CFS(硬件级密钥保护,全托管)。
执行隔离——两道内建防线:Tool Policy(工具级 allow/deny 策略)控制"能不能调",Exec Approvals(命令级白名单/审批)控制"能不能跑"。子代理工具策略自动分离:编排器子代理默认禁用 8 类高危工具(gateway、agents_list 等系统管理工具),叶子子代理额外禁用 4 类工具(含 sessions_spawn、subagents、sessions_list、sessions_history),合计 12 个,从架构上阻止越权和无限递归。沙箱隔离——三种方案递进选择:
OpenClaw 内置 Docker 沙箱支持(sandbox.mode: "non-main"),开箱即用:只读根文件系统、无网络、丢弃所有 capabilities、禁止权限提升。v2.22 沙箱安全增强——阻断危险 Docker 配置(绑定挂载、主机网络、无限制 seccomp/apparmor)、容器签名从 SHA-1 切换至 SHA-256。企业推荐组合方案:K8s 做基础编排和日常开发,关键不可信代码通过 API 调用 AGS MicroVM 执行——OpenClaw 的 Skill 插件机制使这种混合架构零侵入核心代码。3.3 场景化方案示例
以下四个场景覆盖游戏全生命周期,每个案例讲三件事:挑战是什么、OpenClaw 怎么解、方案为什么这么设计。
场景一:立项调研辅助(Session-Spawn 并行深挖)
挑战:一款手游从立项到上线投入 500 万-5000 万,立项决策质量直接决定这笔投入是创造价值还是打水漂。调研需覆盖市场规模、200+ 竞品分析、技术可行性、商业化模型,信息分散在 Steam/App Store/TapTap/SensorTower/百度指数等平台。产品经理一个人做 2-4 周,覆盖面受限且容易带入个人偏好。信息过载与调研效率的矛盾,导致立项决策繁重,信息收集不及时,容易过机会窗口。
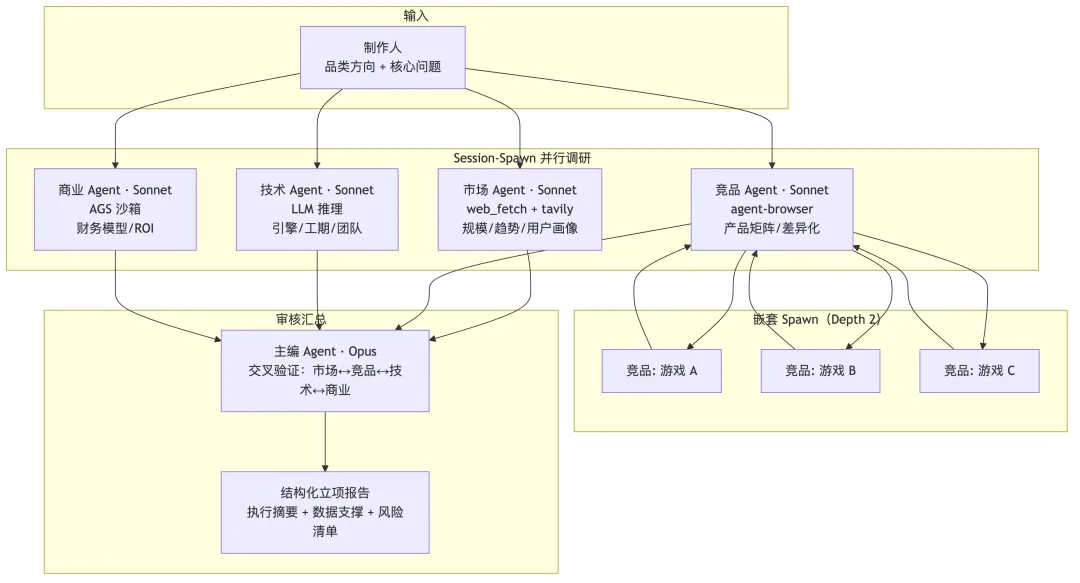
方案说明:这是 Session-Spawn 模式的典型用场——一次性的并行信息聚合。
主编 Agent(Opus,强推理)同时 Spawn 4 个子代理(Sonnet,成本低),各负责一个调研维度。配置 maxSpawnDepth: 2 允许竞品 Agent 再为每款竞品 Spawn 分析子代理——从"一个人串行看 200 款游戏"变为"4 个专家同时分析 200 款游戏的不同维度"。工具按需组合:市场 Agent 用 web_fetch + tavily-search 搜索公开数据;竞品 Agent 用 agent-browser 爬取 App Store/TapTap 评分和下载量;商业 Agent 在 AGS 沙箱中用 numpy/matplotlib 建立财务模型。主编汇总 4 份子报告后做交叉验证——市场数据与竞品分析是否自洽、技术评估与工期预测是否合理、商业化模型与用户画像是否匹配。这是人工调研中最容易被跳过但最有价值的步骤。调研经验沉淀到记忆,后续复用框架只需更新品类数据。半年后积累 10+ 品类数据可做跨品类对比分析——这种知识积累在传统人工调研中几乎不可能实现。 同样的协作模式可以直接迁移到技术选型、合规审查、投资尽调等任何需要多维信息汇总的决策场景。
场景二:游戏自动化测试(设备节点 + 多模态视觉)
挑战:游戏 UI 是引擎渲染的画面(Unity/Unreal 的 SurfaceView/Metal Layer),不是系统控件——没有控件树、没有 accessibility id、没有 xpath。Appium 在游戏场景几乎无用武之地。80% 的核心功能(战斗、社交、抽卡)只能人工测试,每周热更前通宵手工回归。传统自动化框架的底层假设(控件树可解析)在游戏引擎面前不成立。
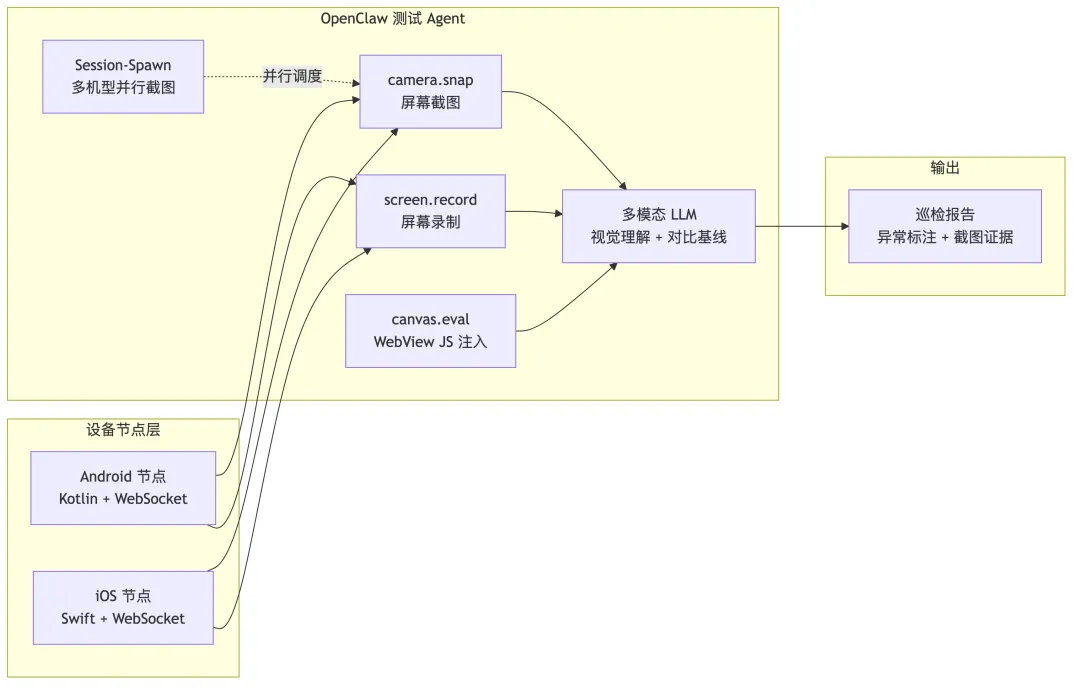
方案说明:OpenClaw 的 Android/iOS 原生节点应用通过 WebSocket 连接 Gateway,camera.snap 截图传给多模态 LLM(Claude Vision / Gemini),LLM 直接理解画面内容——"这是登录页""背包里有 3 个红点""战斗结算显示胜利"。不依赖控件树,截图就是一切。 游戏内活动页(充值、限时商城、公告)通常是 H5 WebView,canvas.eval 可在 WebView 中注入 JavaScript 执行 DOM 操作和断言——这是游戏测试中最接近传统自动化的能力。利用 Session-Spawn 并行机制同时对 5-10 台不同机型执行截图,AI 对比同一页面在不同分辨率/刘海/挖孔屏上的显示效果,自动标注 UI 遮挡、文字溢出、按钮变形。能力边界需诚实标注:Agent 可以"看"(截图 + 理解),但目前不能"操作"(无 touch 事件注入)。适合视觉回归审查和多机型适配检查,交互式自动化测试仍需 Appium/ADB 配合。建议混合方案——OpenClaw 做"AI 大脑"(理解、分析、报告),传统工具做"机械手脚"(精确操作、数据采集)。关键优势:Agent 可 7×24 不间断运行(前提是基础设施高可用),覆盖率远超人工轮班。随着截图断言标准化、操作指令协议打通、用例库持续积累——最终可以从"抽检"走向"全检"。
场景三:智能 NPC / VIP 客服(人格 + 长记忆)
挑战:一款二次元手游的 Discord 社区有 10 万成员,3 个运营维护 20+ 频道;同时游戏内 VIP 客服每天处理上千条工单。玩家提问高度重复但上下文各不相同——老玩家问"怎么配队"和新手问"怎么配队"期待完全不同的答案,VIP 大R 的充值问题和普通玩家的优先级与处理方式也不一样。玩家需要的不是搜索框,而是一个"认识我"的角色——无论它是社区里的 NPC 向导,还是 VIP 专属客服。
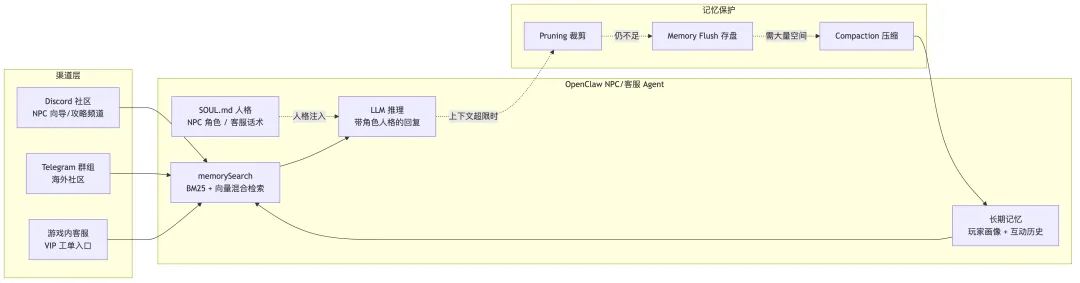
方案说明:
SOUL.md 人格定义——通过工作区 Markdown 文件定义 Agent 的人格:语气、世界观、行为边界。NPC 可以是游戏中的角色——酒馆老板、军师、向导——用角色口吻回答玩家问题;客服场景下定义专业话术、VIP 服务标准和问题升级规则。IDENTITY.md 控制 Discord 显示的头像和名字(映射为 webhook 身份),让 NPC 在社区中有真实的"角色形象"。 长期记忆 + 玩家画像——这是 NPC 和客服场景最核心的能力。Agent 记住每个玩家的互动历史——"张三是 58 级法师,上周推荐过冰法+奶妈组合""李四是 VIP8 大R,上次充值异常已补偿 500 钻,本月累充 2 万"。同一个问题,Agent 给不同身份玩家完全不同的回答——新手得到引导,老玩家得到进阶建议,VIP 得到优先处理和专属方案。memorySearch 支持 BM25 + 向量混合检索,能精确定位关键词也能找到"意思相近"的历史工单。三层记忆保护——NPC 和客服 7×24 在线,对话量远超普通场景。三层保护确保 Agent "永远不会忘记重要的事":Pruning 自动清理旧工具结果、Memory Flush 在压缩前静默写回关键信息、Compaction 将早期对话压缩为摘要。Agent 运行半年后,记忆中积累了完整的社区知识图谱和玩家服务档案。
Bindings 多渠道路由——通过声明式路由同时服务多个渠道。Discord 攻略频道绑军师 NPC,闲聊频道绑酒馆 NPC,游戏内 VIP 入口绑专属客服。Identity Links 实现跨渠道记忆不断裂——玩家在 Discord 问过的问题,转到游戏内客服时 Agent 依然记得。
进阶:全球运营——21 渠道 × Agent 矩阵
上面的案例以单款游戏为背景,但真实的海外发行往往面临更复杂的局面:同一款游戏在 Discord(欧美主阵地)、WhatsApp(东南亚/拉美)、Telegram(俄语区/中东)、LINE / KakaoTalk(日韩)、QQ / 微信(国内)等多个平台同时运营社区。每个平台的用户习惯、语言、活跃时段完全不同,传统做法是每个平台配 2-3 个本地化运营,团队规模随平台数线性增长。
OpenClaw 的 Channel 插件化架构天然适配这个场景——21 个渠道通过统一协议汇聚到同一个 Gateway,多个 Agent 通过 Bindings 声明式路由分工协作:
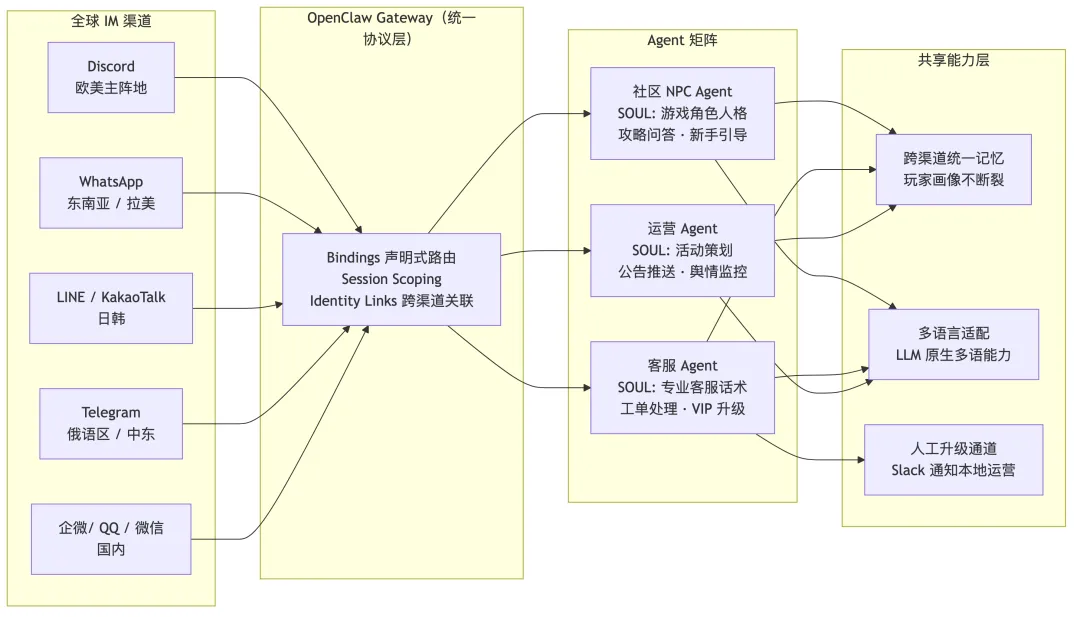
这套架构的核心价值在于三点:
• 渠道汇聚——5 大区域的消息统一进入 Gateway,运营团队不用在多个后台之间反复切换。
• 记忆不断裂——同一个玩家从 Discord 转到游戏内客服咨询,Identity Links 让 Agent 依然记得之前的对话和偏好,跨渠道体验连贯。
• 人力杠杆——3 个 Agent(社区 NPC + 客服 + 运营)覆盖多个平台的日常工作,团队规模从"每平台 2-3 人"降到"全球 3-5 人 + Agent 矩阵"。
LLM 原生的多语言能力让 Agent 无需额外翻译模块即可用当地语言交流——英语回 Discord、日语回 LINE、俄语回 Telegram,同一个 Agent 实例自动切换,当然前期必须是有一段时间双跑去验证地缘特征。SOUL.md 按区域定义不同人格风格(日服用日式二次元口吻,欧美服用轻松幽默风),Cron 定时任务按各服时区推送维护公告和活动提醒。多个地区 NPC 共享同一份游戏策略知识库(通过 memorySearch.extraPaths 扩展记忆源),但各自隔离本地玩家的互动记忆。同一套架构换人格和知识库,就是 HR 助手、IT helpdesk、新员工导师。
场景四:运营数据分析(三层架构:大数据底座 + MCP/Skill 接入 + Agent 智能分析)
挑战:运营团队碎片化分析需求——"昨天活动转化率多少""按区服拆""和上周比"。数据散落在 ClickHouse/MySQL/ES/Prometheus 等系统,5 人数据团队面对 30+ 运营排期 3-5 天,不值得建 BI 看板但又天天在问。日常碎片化分析需求没有高效供给方式。
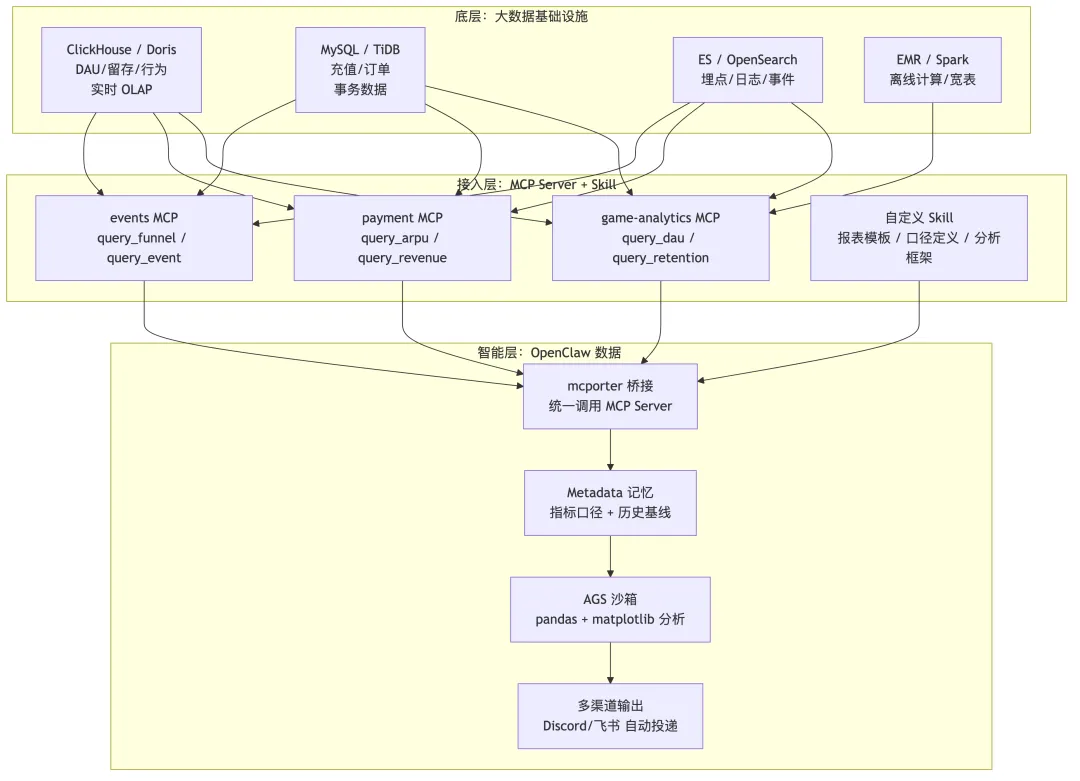
方案说明:
底层——大数据基础设施原封不动。企业已有的 ClickHouse/Doris(实时 OLAP)、MySQL/TiDB(事务数据)、ES(日志/埋点)、EMR/Spark(离线宽表计算)不需要任何改造。数据团队的存储和计算基建完全保留,Agent 不碰底层。
接入层——MCP Server + Skill 无缝对接。每个数据源包装为标准 MCP Server,暴露语义化接口(query_dau、query_retention、query_funnel)。数据团队的工作从"每天写 SQL"变为"维护 MCP Server 接口"——Agent 不需要知道数据在哪、用什么协议,只需通过 mcporter 统一调用。自定义 Skill 承载分析框架和报表模板:把常用的分析维度(区服/渠道/等级段)、指标口径(DAU = 当日在线 ≥ 5 分钟的独立用户)、报表格式封装为 Skill,Agent 在 bootstrap 时自动加载。新增一个分析维度 = 写一个 Skill 声明文件,不用改 Agent 代码。智能层——Agent 理解意图 + 沙箱执行 + 多渠道投递。运营在 Discord/飞书群里自然语言提问,Agent 解析意图后调用 MCP 查询数据,在 AGS 沙箱中用 pandas + matplotlib 做分析和可视化(参考数据:§一案例三 Steam 分析 Pipeline 实测 3 个沙箱处理 18,000 条记录需 86.9 秒,运营场景数据量和查询复杂度不同,性能需实际测试),结果自动投递回提问渠道。指标口径通过 Metadata 记忆注入,所有查询遵循统一口径——不会出现"两个分析师算出不同 DAU"的问题。
渐进式智能化:第一个月 Agent 逐个回答运营的零散问题;三个月后记忆中沉淀了历史基线和运营关注模式;半年后 Agent 能主动发现"DAU 比上周同期下降 8%,可能与昨天更新的 bug 相关"——传统 BI 看板做不到这种基于记忆积累的渐进式智能化。只要控制好读写权限,把现有数据能力封装为 MCP 接口、把分析框架封装为 Skill——财务系统 MCP 就是财务分析助手,供应链 MCP 就是供应链优化顾问。业务封装到哪里,Agent 的能力就延伸到哪里。
3.4 企业落地:还差什么
上述审计、安全、沙箱是基础设施第一步。要把 AI Agent 真正落地到几十上百人的组织里,还有几个结构性问题尚未完全解决:
知识记忆的共享与隔离。 OpenClaw 的记忆文件是 workspace 级共享的,向量搜索引擎(SQLite + FTS5)按 agentId 隔离。单团队够用,但企业场景需要多 Agent 间共享部分知识(产品文档、流程规范),同时隔离敏感信息(部门内部数据)。memorySearch 支持 extraPaths 扩展记忆源,但完整的共享知识库设计、权限粒度控制、知识更新全局同步——尚无成熟方案。Skill 私有化分发。 ClawHub 面向开源社区,企业需要内部 Skill 仓库(类似私有 npm registry)、版本管理审批流程、细粒度权限控制——哪些 Skill 允许哪些 Agent 使用,哪些需要审批。
LLM 统一成本治理。 内置 session 级成本追踪和七种原因自动降级切换已很完善,但几十个 Agent 同时运行时,还需叠加外部 LLM 网关(如 OneAPI)做统一管控——按部门/项目的用量配额硬限制、token 预算告警、集中式路由策略。
高可用与故障恢复。 单 Gateway 是当前架构的单点。企业部署需考虑自动恢复、session 状态外部持久化、多 Gateway 负载均衡。
合规与可观测性。 已有安全审计框架和命令日志 hook(JSONL 格式),内置 Control UI dashboard 可查看运行状态和成本汇总。但距离企业级还需补齐:PII 自动脱敏、集中式 APM 监控、跨 Agent 调用链追踪。
A2A 混合 Spawn 的企业级编排。 两种协作机制独立但互补。企业级编排还需要:可视化工作流定义、子代理失败后的重试与补偿、跨 Agent 事务一致性、编排全链路追踪。
这些问题没有一个是简单的,每一个展开都是独立的工程项目。但好消息是 OpenClaw 的架构——Skill 插件机制、Gateway 统一调度、per-Agent 隔离、A2A 策略层——为解决这些问题提供了合理的扩展点。不需要推倒重来,而是在现有架构上逐步补齐。
3.5 腾讯云企业级落地方案
上面说了这么多"还差什么",下一个问题是:跑在哪里? OpenClaw 本身不绑定云厂商,但当你需要企业级的安全、弹性和可观测能力时,需要一套经过验证的基础设施搭配方案。腾讯云产品矩阵与 OpenClaw 的组合,提供了一条从"员工试玩"到"全面生产"的渐进式落地路径。

腾讯云企业级落地方案:层层递进部署
核心思路是三级递进,不需要一步到位:
🚀 L1 · 员工学习龙虾、创意龙虾——Lighthouse 企业版 / CVM 单机,先养起来。成本极低、快速启动,目标是让员工自由探索、了解能力边界。模型接腾讯云 Coding Plan,IM 走企微/飞书/Discord,沙箱用腾讯云沙箱 Agent(code + browser),存储用本地磁盘 + CFS。个人就是一个超级管理员,隔离好身份权限,控制好爆炸半径。
🏢 L2 · 中台-业务标准龙虾——CVM/TKE Serverless/AGS,部门级 MVP。计算层升级到 TKE Serverless,模型接腾讯云 Coding Plan 或第三方大模型 API,IM 支持企微/飞书/Discord/自定义 Channel,沙箱切到 AGS + Docker 双层隔离,存储用 COS 知识库 + CFS 共享。安全加入 CAM RBAC + VPC 隔离/云原生安全。成本可控、按部门规模弹性,目标是跑通业务价值、验证 ROI。
🏗️ L3 · 中台-企业级业务龙虾——TKE ServerlessGateway 弹性伸缩 + AGS。计算用 CVM 集群 + 弹性伸缩,推理层 TKE 横向扩展 OpenClaw Gateway,沙箱用 TKE + 沙箱 Agent,扩展支持 OpenClaw Remote ACP 扩展。安全升级到三层隔离 + 云审计全链路,可观测接 CLS + Prometheus + 告警。按规模弹性,规模越大单位成本越低,目标是业务适配、持续产出价值。
渐进式原则:不需要一步到位——L1 让员工自由探索,跑通后 L2 把创意龙虾的实践沉淀到标准龙虾落地,验证进阶后 L3 生产业务提效——开发、测试、运营、数据分析,全面铺开。
四、多 Agent 协同实战:硅基组织架构
§二讲的是单个 Agent 的六大核心机制,§三讲的是企业落地场景。这一章聚焦多个 Agent 如何像一个团队一样协作——从组织设计、通信协议、质量关卡到成本控制的完整方案。
4.1 组织架构
当你把 10 个 Agent 部署到一台服务器上,配好各自的人格(SOUL.md)、职责(系统提示词)、通信关系(allowAgents 白名单)和工作节奏(Cron 定时任务)——它就是一个 7×24 在线的虚拟团队。组织架构、SOP、汇报关系、质量关卡、值班排班——全部用 JSON 声明。这不是隐喻,是字面意义上的组织设计。以涅槃团队的 10 Agent 协作架构为例——三层组织结构:
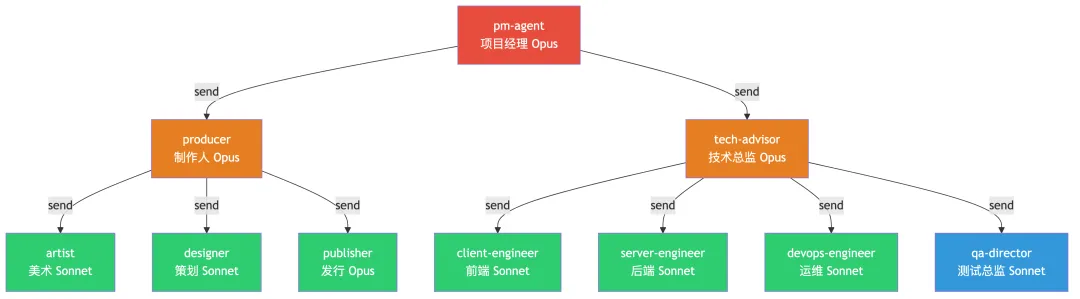
红色=顶层调度 | 橙色=决策层 | 蓝色=验证层 | 绿色=执行层 | 所有箭头 = sessions_send
4.2 通信协议:Send vs Spawn
核心铁律:日常工作全部走 send(保记忆),只在纯文档/纯格式化等一次性任务时用 spawn。
spawn 走 Subagent Lane(默认容量 8),看似能解决串行问题。但 spawn 创建全新 session,不继承任何对话历史。用 send 第二次给 client-engineer 派任务时,它记得上次的 bug 直接关联修复;用 spawn 则每次从头读文件,效率差异巨大。Spawn 仅用于纯文档一次性任务,且产出必须写文件——子 session 完成后销毁,口头回复会丢失。4.3 SOP 与质量关卡
硅基团队的核心问题:LLM 声称"完成了"不可信,Agent 可能幻觉式报告"编译通过"但实际有错误。解决方案是四层 SOP:
1. L1 自检——Agent 完成任务后自行检查产出(lint/编译/格式)
2. L2 代码审查——相关 Agent 交叉 review(如 tech-advisor 审查 client-engineer 的代码)
3. L3 Gate Runner——qa-director 执行 gate 脚本(shell 命令),exit code ≠ 0 直接打回。这是唯一不依赖 LLM 判断的硬关卡
4. L4 体验审查——人类做最终验收
4.4 自主运转:Cron + Heartbeat + 看板
Cron 定时任务是"排班表"——每天早上 9 点让 pm-agent 检查所有任务进度并在 Discord 群发日报;每小时让 devops-engineer 检查服务器状态和 token 消耗。Heartbeat 是"心跳监测"——Agent 定期向 Gateway 报告存活状态,断线自动重连。 看板——sessions_list 不走任何 Lane,是零开销查询。pm-agent 用它实现"任务看板"——轮询所有下属 Agent 的 session 状态,自动汇总"谁在忙、谁空闲、谁阻塞了"。配合 timeout=0 的 fire-and-forget 模式(异步通知,立即释放管道),pm-agent 可以同时给多个 Agent 派活而不阻塞自己。 权限管控——三层递进:tools.deny 物理移除工具(100% 不可绕过)→ allowAgents 白名单(100% 不可绕过)→ SOUL.md 行为引导(大多数情况有效,但可被 prompt injection 绕过)。五、写在最后
回头看,OpenClaw 做的事情本质上是把 Agent 从"脚本"变成"进程"。
传统 Agent 框架解决的是"如何编排 LLM 调用"——写一段 Python 脚本,跑完就退。OpenClaw 解决的是下一层问题:Agent 跑起来之后,谁管它的生命周期?谁管它的记忆?谁管它的安全边界?谁管它跟外部世界的连接?这些问题加在一起,就是一个操作系统要解决的问题。
它开始长得像 Agent OS。 六大机制——记忆层、接入层、安全层、Pi-AI 调度层、编排层、Skills 技能层——与操作系统的六个经典抽象有结构上的对应:持久化存储、I/O 管理、权限控制、资源调度、进程通信、包管理。当 Agent 需要 7×24 在线、多渠道接入、多模型调度、团队协作、安全审计时,它面临的就是系统工程问题,而不是应用层问题。
模型、设备、渠道——全部可插拔。 今天用 Claude Opus 做决策、Sonnet 做执行、Haiku 做监控;明天 DeepSeek 性价比更好就切 DeepSeek;后天本地 GPU 到位就切本地模型——Pi-AI 调度层让这些切换在配置层完成,不改一行 Agent 逻辑。同样的道理,海外游戏运营接Discord,国内日常使用接微信,工作场景接企微、钉钉、飞书,游戏内需要时接自定义 WebSocket——渠道层的声明式绑定让 Agent 的"触角"可以随业务需求自由伸缩。不绑定任何一家模型厂商、不绑定任何一个渠道平台、不绑定任何一种部署形态。
技术选型上,OpenClaw 做的是最朴素的选择:记忆用 Markdown 文件(可 git diff、可人工编辑、不会幻觉),配置用 JSON(保存即生效、支持热重载),审计用 JSONL(一行一条、grep 即查询),安全策略用声明式 JSON Schema(不依赖 LLM 判断、100% 可验证)。没有一项是"看起来很酷"的选择,但每一项都是工程上容易理解、调试和替换的选择。
这不是一个"部署完就结束"的系统。Agent 从"能用"到"好用"需要持续打磨:Skill 要根据业务场景不断迭代,记忆要定期清理和结构化,安全策略要随着组织变化调整,多 Agent 协作的 SOP 要在实战中验证。平台提供基础设施,使用者做好架构设计和运营——两者协同才是正解。
OpenClaw 不一定是企业AI落地的最终答案,但它是AI Agent操作系统的雏形,开启了新的想象空间。
