 夜雨聆风
夜雨聆风前言:
前文简单介绍了Slash的几个节省Token的命令比如compress/compact,以及/new/stop和/restart。 本文从架构的角度来解释原因。
1 OpenClaw的核心架构
openClaw的核心架构包含3个部分,分别为Gateway,Agent Loop和Tools。
⁘ 1.1 Gateway
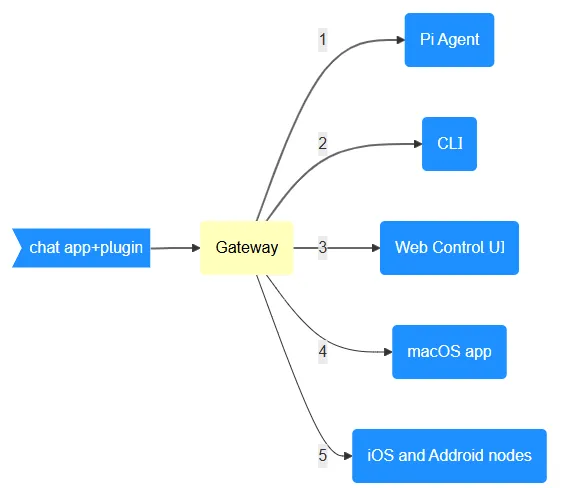
Gateway 网关是会话、路由和渠道连接的唯一事实来源。 OpenClaw 通过单个Gateway网关进程将聊天应用连接到 Pi 等编程智能体。
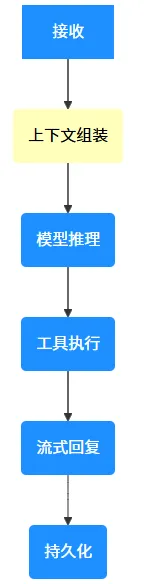
⁘ 1.2 Agent Loop
Agent Loop就是 ReAct(Reasoning + Acting)模式:
⁘ 1.3 Tools
工具嵌入到上面的Agent Loop里面,根据需求调用,同时为了安全设置了Sandbox和Tools policy的设置,可以参考前面的描述。
2 Slash命令如何节省Token
⁘ 2.1 Slash命令为什么能够节省成本?
我们在聊天对话框的Slash命令在Gateway中执行,命令的执行不需要经过大模型的调用,所以不产生成本。
⁘ 2.2 new和stop命令为什么能够节省TOken?
在Agent Loop阶段的上下文组装阶段,我们组装了哪些内容?
系统提示词(OpenClaw 构建):规则、工具、Skills 列表、时间/运行时,以及注入的工作区文件。 对话历史:你的消息 + 助手在此会话中的消息。 工具调用/结果 + 附件:命令输出、文件读取、图片/音频等。
比如我们问了一个关于狗狗的问题,那么我们的上下文内容全部是关于该话题的内容,我们希望问一个数学的问题,那么前面关于狗狗的问题会作为对话历史重新进行下一轮组装,那么我们使用/new命令就会将上下文的历史清空,重新问新的问题的话就会以第一次问的作为历史会话进行组装,无形中就节省了Token。
⁘ 2.3 comporess和compact原理又是什么呢?
依然是Agent Loop的上下文组装阶段,如果我的上下文过长会导致污染以及传递给LLM推理的数据越来越长,那么我压缩一下传递给LLM推理的数据就少了,从而达到节省Token的目的。
后记:
本文无法从根本上解决Token消耗过大的问题,但是使用最简单的方式节省Token消耗,当前还有一些memory的插件等也能够降低Token的消耗,后续我们在介绍Memory章节会介绍。
