 夜雨聆风
夜雨聆风
4月22日,中科大副研究员程明月,Nanobot团队负责人黄超,HiClaw项目发起人、阿里云智能高级解决方案架构师付宇轩等5位嘉宾将在OpenClaw技术研讨会带来主题报告。
智猩猩AI整理
AI Agent 正在从“会聊天”加速跃迁到“真能干活”。2026 年初,OpenClaw 以惊人速度突破 33 万 GitHub Star,成为开源历史上增长最迅猛的个人 AI 助手平台。它让普通人拥有了一个本地优先、跨平台、能自主调用工具完成复杂任务的“数字分身”。
但这些 Agent 上线后,能力就基本定型了。用户越多、场景越杂,它们暴露出的短板就越明显——工具调用不稳、长序列规划崩盘、面对新任务反应迟钝。
传统强化学习要么局限于实验室的模拟沙盒,要么需要侵入式修改模型内部,生产环境里几乎无法落地。结果就是,Agent “聪明一时”,却难以“聪明一世”。
为此,今天要给大家介绍中国科大认知智能全国重点实验室团队的开源项目 Claw-R1,正是针对上述问题提出的一种全新的强化学习训练框架。它将前沿的Agent Runtime(比如OpenClaw) 与强化学习训练框架深度结合,为 Agentic AI 提供一个新的训练基础设施。

项目链接:
https://github.com/AgentR1/Claw-R1
01
Agent 迈入落地期,
两条主线交汇暴露核心问题
当前两条技术路线正在同时走向成熟。
一条是 Agentic RL——用强化学习训练 LLM Agent。从 DeepSeek-R1 证明 RL 可以显著提升模型的推理能力,到 Agent-R1 将 RL 扩展到多轮 Agent 交互场景,再到 VERL、Agent Lightning、Forge 等框架不断完善训练基础设施,Agentic RL 已经从早期探索走向主流实践。让模型与环境交互产生轨迹、以环境反馈作为奖励信号进行策略优化——这一训练范式已在代码生成、数学推理、工具调用等多个场景中被验证有效。
另一条是 General Agent——能力远超简单 ReAct 循环的完整智能体系统。OpenClaw、Claude Code、Cursor 等产品正在重新定义 Agent 的能力边界。以 OpenClaw 为例,它支持 22+ 消息渠道接入、复杂的工具编排与上下文管理,能够 7×24 小时持续运行——这已经不是实验室里的原型系统,而是被真实用户日常使用的生产级 Agent 平台。Claude Code 和 Cursor 同样展现了类似的趋势:Agent 系统正在变得越来越复杂、越来越强大。
这两条路线各自蓬勃发展,但它们的交汇点上却暴露出两个关键缺口。
Gap 1:General Agent for Agentic RL
现有的 Agentic RL 框架——无论是 Agent-R1、rLLM 还是其他方案——几乎都围绕简单的 ReAct Agent 设计。它们将 Agent 视为白盒函数,要求 Agent 逻辑使用框架自身的 API 编写,训练系统直接管理 Agent 的每一步执行、自行处理 token 拼接和 mask 设计。
但 General Agent 的世界远非如此。OpenClaw 有自己的消息路由和记忆系统,Claude Code 有自己的工具链和上下文管理,LangChain、AutoGen、CrewAI 等生态更是百花齐放、各有各的架构。要把这些系统接入现有 RL 框架,意味着在框架内重写整套 Agent 逻辑——正如 Agent Lightning 论文所指出的,"将 Agent 迁移到现有 RL 框架中需要手动适配执行逻辑,这不仅费时费力,而且容易出错,难以规模化"。
现有 RL 训练基础设施并未为 General Agent 做好准备。
Gap 2:Agentic RL for General Agent
反过来看,当前的基座模型也没有为 General Agent 架构做过针对性的强化学习训练。模型在标准 benchmark 上表现优异,但放进 General Agent 复杂的运行时环境后,往往无法充分发挥能力。这些 General Agent 系统涉及多轮工具调用、异步执行、长上下文管理等复杂交互模式——模型从未在这样的系统中学习过如何高效行动。
如果不能在 General Agent 的真实运行环境中做 RL 训练,模型就始终无法真正适配这些系统的需求。
General Agent 需要为自己量身定制的 RL 训练方案。
Claw-R1正是为了同时填补这两个缺口而设计的 Agentic RL 训练框架。它的目标是双向的:一方面让 General Agent 能够轻松接入 RL 训练流水线;另一方面让模型在 General Agent 的真实环境中持续学习和进化。
02
为什么从 OpenClaw 开始
在众多 General Agent 中,OpenClaw 是 Claw-R1 首先对接的目标系统。OpenClaw 是一款开源的个人 AI Agent 操作系统,采用 MIT 协议发布,支持 22+ 主流消息平台接入,能够 7×24 小时持续运行。它在发布后迅速获得大量社区关注,成为开源 General Agent 领域最具代表性的项目之一。
选择 OpenClaw 作为首个集成对象,是因为它完整体现了 General Agent 的典型特征:多通道消息路由、复杂的工具编排、持续运行的任务执行、以及完善的上下文记忆管理。
如果 Claw-R1 的训练框架能够无缝适配 OpenClaw 这样复杂度的系统,那么它对其他 General Agent 的通用性也就自然可以得到验证。
当然,Claw-R1 的设计并不局限于 OpenClaw。通过 Gateway 的零侵入接入机制(后文会详述),任何基于 OpenAI 兼容接口的 Agent 系统都可以接入 Claw-R1 的训练体系。
03
核心思路:Deploy = Training
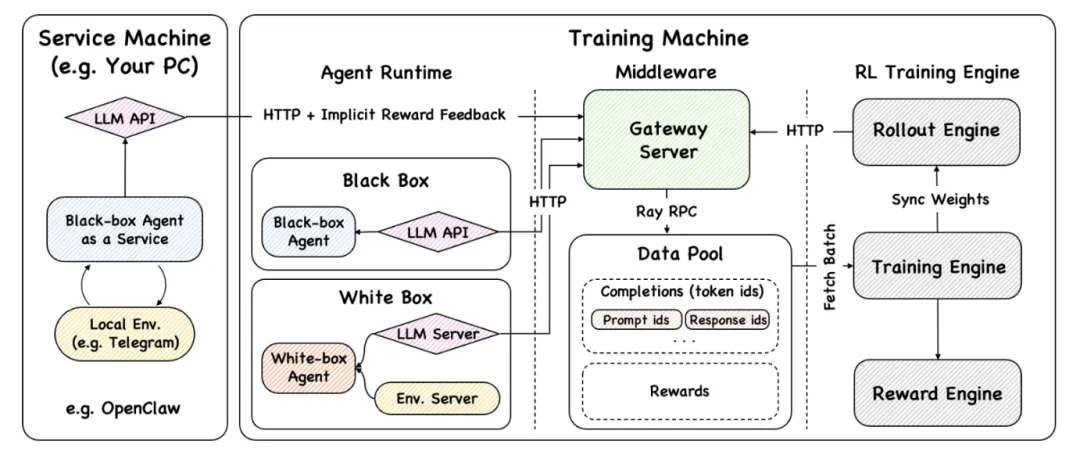
Claw-R1 的全部技术设计围绕一个核心理念展开:Deploy = Training(部署即训练)。
传统的 Agent 开发流程中,训练和部署是两个割裂的阶段。团队先在离线环境中用预设数据训练模型,再将训练好的固定模型部署到生产环境中服务用户。这种流程存在几个难以回避的问题:训练时使用的数据分布与真实用户的使用习惯并不一致,导致分布偏移;面对新场景时模型缺乏冷启动能力;一旦部署上线,模型就停止了学习,无法跟随环境变化而改进。
Claw-R1 打破了训练与部署之间的边界。
在 Claw-R1 的架构下,Agent 在为用户提供服务的同时,其每一次交互——每一轮对话、每一次工具调用、每一个任务执行结果——都被自动采集为强化学习的训练轨迹。训练引擎在后台持续消费这些轨迹并更新模型权重,更新后的模型又立即投入服务。服务产生数据,数据驱动训练,训练改善服务——一个持续运转的进化闭环。
要让这个闭环在生产环境中可靠运转,需要解决三个关键的工程问题:
如何零侵入地接入任意 General Agent? — 不能要求每个 Agent 系统为训练重写代码。
如何在服务与训练之间异步传递数据? — 数据采集不能影响 Agent 的正常响应。
如何让训练与服务互不干扰?— 模型更新不能导致服务中断。
Claw-R1 通过三个关键组件分别回答了这些问题:Gateway、DataPool 和异步双引擎。
(1)Gateway:零侵入的智能代理层
Deploy = Training 的第一个前提是:任何 General Agent 系统都能接入训练体系,且无需修改自身代码。
这正是 Gateway 的设计目标。Gateway 是一个位于 Agent 和推理引擎之间的 HTTP 代理层。它对外暴露标准的 OpenAI 兼容接口——任何 Agent 只需将大模型调用地址指向 Gateway,即可透明接入 Claw-R1 的训练体系。
这一机制的基础是几乎所有 OpenAI 兼容 SDK 都支持的特性:自定义 base_url。无论 Agent 使用 Python、JavaScript 还是其他语言,无论底层框架是 LangChain、AutoGen 还是完全自研的系统,只需将 base_url 从原来的大模型服务地址改为 Gateway 地址,就完成了全部接入工作。Claw-R1 将训练所需的元信息(如轨迹标识和任务标识)编码在 URL 路径中,Agent 侧完全无感知——它只是在调用一个"看起来一模一样的大模型 API"。
在数据采集层面,Gateway 实现了一套轻量的握手协议来管理对话轨迹的生命周期:初始化轨迹 → 注册元信息 → 多轮对话交互 → 标记轨迹完成。整个过程中,Agent 像调用普通大模型 API 一样发送请求,Gateway 在代理层透明地完成请求转发、响应拦截和轨迹数据的拼装与提交。
Gateway 被设计为独立进程,而非训练系统的内部组件。这意味着即使训练引擎正在进行权重同步或重启,Gateway 的 HTTP 服务也不会中断。Gateway 同时内置负载均衡能力,可将请求分发到多个推理实例,支持水平扩展。
(2)DataPool:异步数据缓冲层
Deploy = Training 面临的另一个现实问题是:数据产生的节奏和训练消费的节奏天然不同步。Agent 服务用户时产生轨迹数据的速率取决于用户请求的频率和任务复杂度,而训练引擎需要等待足够的数据组装成完整批次才能启动一轮更新。
DataPool 作为中间缓冲层解决了这一问题。Gateway 采集到的每一条交互轨迹都会异步提交到 DataPool,这个过程不阻塞 Agent 的正常服务。训练引擎则从 DataPool 中按需拉取就绪的数据批次进行学习。
DataPool 的一个关键设计是组完成判定:同一个任务可能产生多条轨迹(例如同一 prompt 的多次 rollout),只有当该任务的所有轨迹都收到终止标记后,这组数据才会被标记为就绪。这确保了训练引擎消费的始终是完整、一致的数据。同时,DataPool 内置容量管理机制,在长时间持续运行中自动控制内存占用,防止数据无限堆积。
(3)异步双引擎:服务与训练彻底解耦
Deploy = Training 的最后一个关键约束是:训练过程绝不能影响 Agent 的在线服务质量。
Claw-R1 将系统拆分为两个物理隔离的引擎来满足这一约束。生成引擎运行推理服务,负责响应 Agent 的实时请求;训练引擎在后台独立运行,消费 DataPool 中的轨迹数据并更新模型权重。两个引擎运行在各自的计算资源上,独立循环,互不等待、互不阻塞。
这种异步架构对 General Agent 场景尤为关键。General Agent 执行的任务复杂度差异极大——一个简单的信息查询可能秒级完成,一个涉及多轮工具协作的复杂任务则可能持续数分钟。如果采用同步模式,生成和训练交替执行,最慢的任务会拖住整个系统的节奏。异步设计让两个引擎各按自身的速率运转,从根本上消除了这种瓶颈。
两个引擎之间的权重同步由专门的同步组件负责协调。训练引擎每完成若干步更新后,会将最新的模型权重广播到生成引擎的推理实例。由于 Gateway 是独立进程,权重同步期间 Agent 侧的请求转发和数据采集不受任何影响,服务连续性得到充分保障。
04
使用方法
环境要求:CUDA(11.8+)、Python(3.10+)、Conda / Mamba、Git。
(1)创建环境
conda create -n clawr1 python=3.10 -yconda activate clawr1
(2)安装 veRL
git clone https://github.com/volcengine/verl && cd verlpip install --no-deps -e .cd ..
(3)安装 Claw-R1
git clone https://github.com/AgentR1/Claw-R1 && cd Claw-R1pip install -e .
pip install "ray[default]" fastapi uvicorn(5)验证安装
执行以下检查命令,确保所有组件均已正确安装:
# Check veRLpython -c "import verl; print('veRL:', verl.__version__)"# Check Raypython -c "import ray; print('Ray:', ray.__version__)"# Check Claw-R1 gatewaypython -m claw_r1.gateway.gateway --help
Black-box 模式(推荐入门)
黑盒模式下,Agent 使用标准 OpenAI API 与 Gateway 交互,无需修改 Agent 代码。以 GSM8K 数学题为例:
① 准备数据
# 下载 GSM8K 数据集(parquet 格式)# 确保 train.parquet 和 test.parquet 在 ~/data/gsm8k/ 下
export CUDA_VISIBLE_DEVICES=0,1,2sh example/test_async_blackbox.sh
该脚本会:
启动 Ray 集群 创建 DataPool(Ray Actor) 在 GPU 0-1 上部署 Actor + Critic(训练) 在 GPU 2 上部署 vLLM(推理) 启动 Gateway(端口 8100) 运行 BlackBoxGSM8KAgentFlow:为每个样本调用 init_trajectory获取base_url创建 GSM8KAgent,使用base_url作为 OpenAI API 的 endpointAgent 通过多轮 tool calling 解题 Gateway 自动收集每轮对话为 Step 并提交到 DataPool AsyncTrainer 从 DataPool 拉取批处理进行 PPO 训练 定期同步权重到 vLLM
# GPU 分配trainer.n_gpus_per_node=2 # 训练用 2 张 GPUrollout.n_gpus_per_node=1 # 推理用 1 张 GPU# Agent Flowactor_rollout_ref.rollout.agent.default_agent_flow=blackbox_gsm8k_agentactor_rollout_ref.rollout.agent.agent_flow_config_path=claw_r1/blackbox_agent/agent_flow_config.yaml# 异步训练async_training.trigger_parameter_sync_step=1 # 每步同步权重actor_rollout_ref.rollout.n=5 # 每个 prompt 生成 5 条 trajectory
完整步骤请参考:
https://agentr1.github.io/Claw-R1/getting-started/quickstart/
05
总结
Agentic RL 和 General Agent 是当前 AI 领域最具活力的两个方向,但二者之间存在明显的技术断层——RL 框架还停留在简单 Agent 的范式中,而 General Agent 也缺少为自身量身定制的 RL 训练方案。
Claw-R1 在这个断层之上架起了一座桥梁:
面对 General Agent for Agentic RL 的挑战,Gateway 的
base_url零侵入机制和握手协议让任何 General Agent 系统无需改代码即可接入 RL 训练。面对 Agentic RL for General Agent 的挑战,Deploy = Training 的闭环架构让模型在真实 General Agent 环境中持续学习和进化。
DataPool 在服务与训练之间提供可靠的异步数据缓冲。
异步双引擎 确保训练过程不影响生产环境的服务质量。
这些设计共同构成了一套面向 General Agent 场景的 Agentic RL 训练基础设施。
END
✦
✦
大会推荐
✦
4月21-22日,智猩猩主办的2026中国生成式AI大会将举行,设有开幕式,AI算力基础设施、大模型、AI智能体3大专题论坛,以及OpenClaw、LLM强化学习、大模型记忆等6场技术研讨会。其中,OpenClaw最强轻量平替nanobot团队负责人黄超、Claw-R1项目负责人程明月等学者专家将带来报告分享。

✦
✦
入群申请
✦

智猩猩矩阵号各专所长,点击名片关注
