 夜雨聆风
夜雨聆风
👆点击蓝字关注【理想连山】

最近一段时间,OpenClaw是AI圈里最热的词。
2个月,21万GitHub Stars,创始人最终被OpenAI招至麾下。深圳出了“龙虾十条”,最高1000万股权支持;线下活动千人排队,就为让工程师帮装一个开源软件。这个热度,我们也一直在观察。
但我们更想聊的,不是OpenClaw有多火,而是它对企业来说意味着什么——以及为什么企业落地和个人使用,是两套完全不同的逻辑。
01
AI有了“手”,企业先想到的是什么。
OpenClaw的能力并不复杂:一个运行在本地的AI助手,接入飞书、企业微信这类你天天在用的IM工具,然后用自然语言指挥它干活——整理文件、执行任务、操控电脑、写入表格。
个人用,体验很好。
但企业用,第一个问题不是“它能做什么”,而是“它能碰什么”。
OpenClaw在运行时,AI拥有本机完整的文件系统访问权限,并且可以执行命令。这意味着,如果部署在生产环境的同一台机器上,ERP数据、客户信息、工艺参数、历史报价——AI理论上都摸得到,也写得进去。
Gartner对此的评级,是“不可接受的网络安全风险”。
这个评级出来之后,社区里关于恶意Skills、凭据窃取的讨论多了起来。对制造企业来说,生产系统的任何一条数据被意外改动,都可能带来难以预估的连锁反应。
02
连山AI-Brain:安心养“虾”。
面对这个问题,我们的选择不是绕开它,也不是去说服客户“其实没那么危险”。我们把OpenClaw部署在AI-Brain里,模型部署和推理全在本地完成,数据不出设备,不经公有云,不走第三方服务器。
这套边端架构决定了整条链路的安全边界:AI助手的运行范围被限定在AI-Brain内部,它能访问的,只有你主动授权挂载进来的内容;企业其他系统的数据,不在它的触达范围之内。
具体来说,这解决了三件事:
AI不会越权触碰业务数据:AI的操作范围被明确限定在授权区域内。读、写、执行,每一层的权限都需要显式配置,没有默认开放。
数据与模型推理本地化:很多OpenClaw部署方案仍然依赖云端模型API,每次调用都要把内容发给外部服务器。连山通过本地设备和本地大模型运行OpenClaw,风险更可控。客户信息、订单记录、财务数据等,全部留在自己的硬件里。
操作可追溯、可回滚:OpenClaw的底层用文件系统加Git做版本控制。AI改了什么,一目了然;改错了,随时回滚。没有黑箱。

03
一个真实的场景。
说安全,是为了让AI能真正被用起来。所以同样重要的问题是:它实际能做什么?
我们在一家企业做了一个场景验证:邮件订单自动录入。
原来的流程:收到供应商发来的采购订单PDF,员工对照邮件内容,逐行核对物料编号、零件号、数量、交期,然后在飞书表格里手动更新或新增记录。每封邮件,几十行数据,容易出错,也耗时间。
将OpenClaw接入AI-Brain之后,在飞书里发一句话:
“帮我整理一下邮件里的最新订单。”
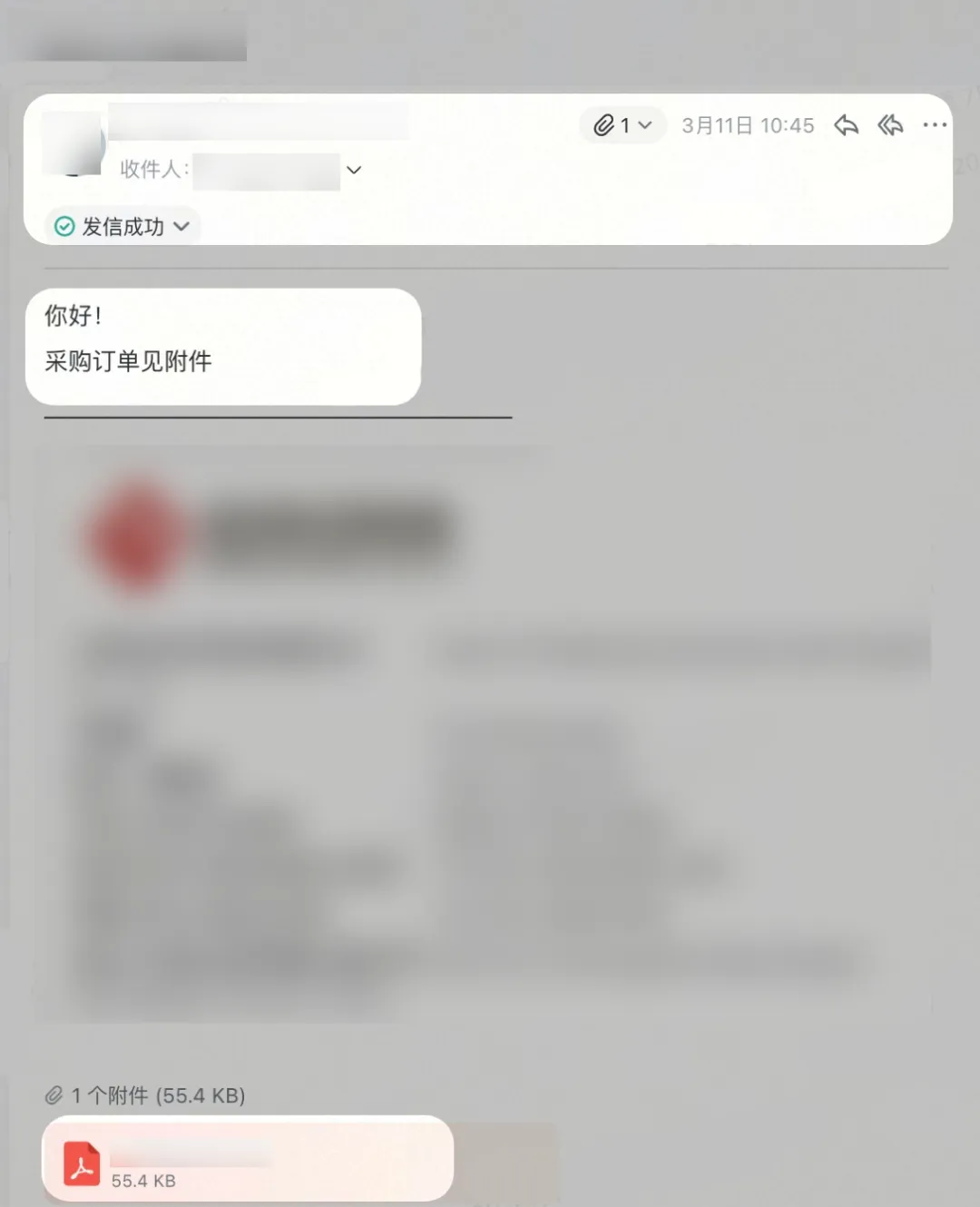
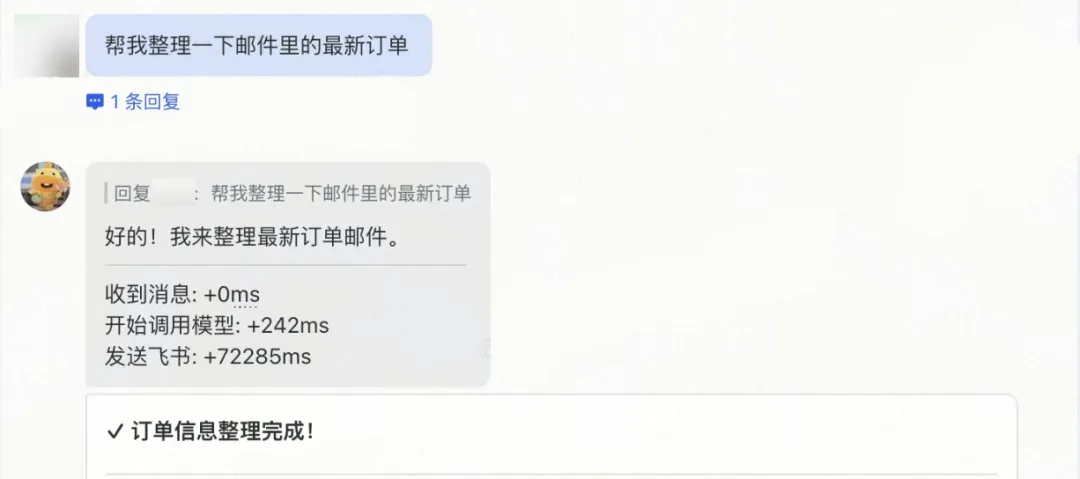
“龙虾”自动读取邮件附件,提取订单信息,与现有表格做智能匹配——已有的物料行更新数量,新增的物料行自动追加——处理结果和完整说明同步回到飞书表格。
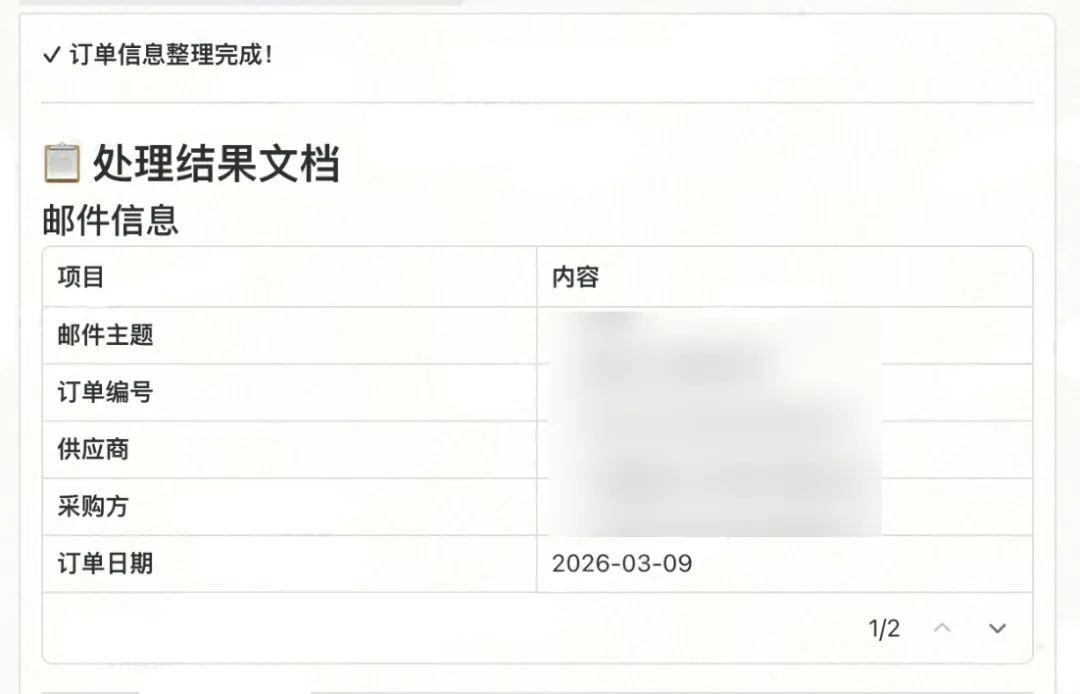
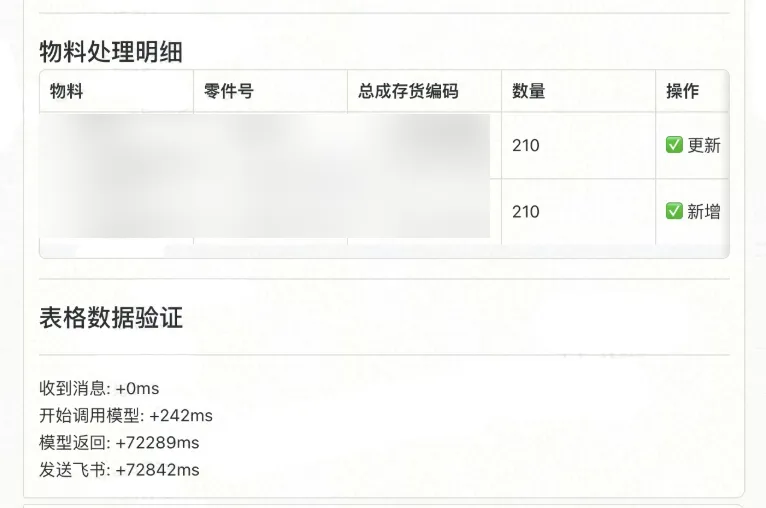

全程在飞书里完成,不需要切换其他系统,不需要人工逐行核对。
这个案例验证的,不只是“省了几分钟”,手工录入的真实成本从来不只是时间——人工比对的每一次操作,都可能因一次出错引发损失;一个物料编号填错,代价往往要到生产环节才能算清楚。将OpenClaw装进AI-Brain,它能够理解业务上下文,完成“读取信息→智能比对→更新记录”这类有判断逻辑的任务,而这类任务,在企业日常运营里每天都在重复发生。
04
工具在变,问题不变。
邮件里的订单是一个场景。同样的逻辑,可以走进审批流、报价单、异常预警,走进任何需要“感知、决策、执行”的业务节点。
AI-Brain承载的不只是让OpenClaw跑起来的硬件,而是一个以记忆、Skills和执行力为核心的本地AI基座。其中,连山工程师针对工业场景预装了精选的Skills,将专家经验沉淀为记忆,业务逻辑封装为可执行的能力——你拿到的不是一只等待配置的“龙虾”,而是一只养好的、开箱能干活的。
今天是OpenClaw,明天可以是更好的工具,但连山在做的事不会变:让AI在企业里产出可以被预期、可以被复制的执行结果。数据怎么集成进来、专家经验怎么沉淀进去、流程怎么在真实环境里稳定运行,才是真正有用的企业AI能力。
END

👇 阅读原文申请试用
↓↓↓点赞 分享 推荐
