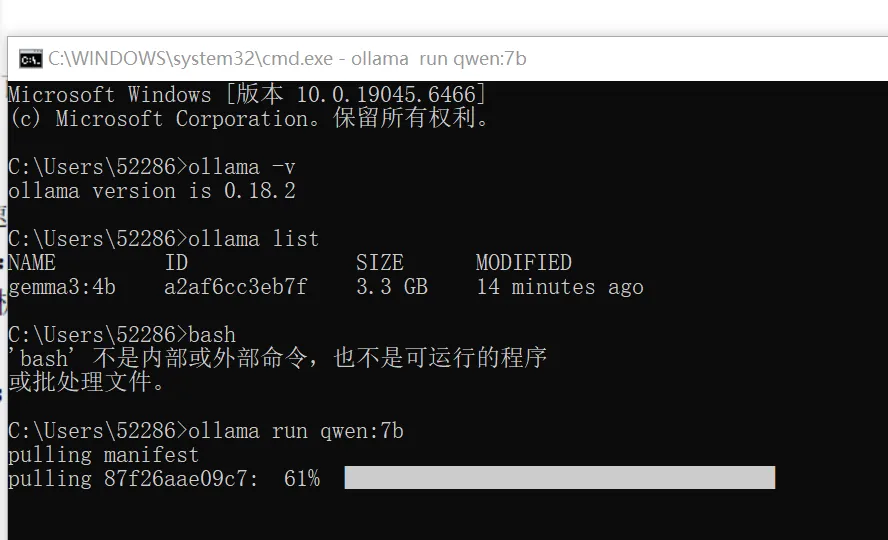
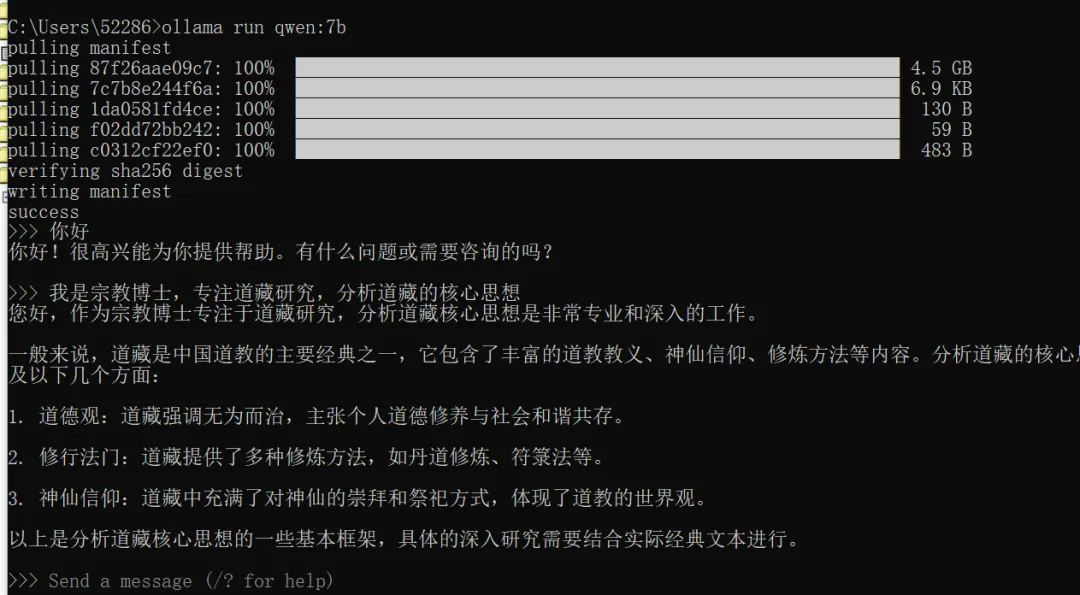
windows电脑搭建本地大模型,尝试高效写论文硬件:满足「显存≥6GB(NVIDIA 独显)/ 内存≥16GB」(纯 CPU 也能跑,但速度慢);系统:Windows:Windows 10/11 64 位;官网下载:https://ollama.com/download/windows(自动识别系统,下载.exe 安装包,约 169MB);双击下载的ollama-windows-amd64.exe,无需手动配置,点击「Next」→「Install」,等待几 分钟完成安装;安装完成后,Ollama 会自动注册为系统服务(后台运行,无需手动启动);1.4.1.在cmd界面输入:ollama run qwen:7b下载完毕后的界面如下:(已经可以开始对话)
1.5. 退出Qwen-7B的命令: /bye
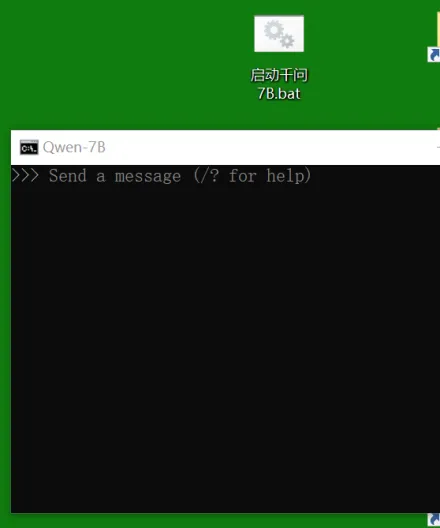
1.6. 在桌面新建一个文本文档,重命名为“启动千问7B.bat”
注意后缀是 .bat,不是 .txt
在bat文档里输入以下代码:
@echo off
title Qwen-7B
ollama run qwen:7b pause
1.7. 其余Ollama 命令
按下Win+R,输入cmd打开命令提示符;
输入ollama -v,显示版本号(如ollama version is 0.18.2)即安装成功;
输入ollama list,显示查看本地已下载的模型
ollama run 模型名 启动指定模型(如 ollama run glm:7b)
ollama pull 模型名 仅下载模型不运行(如 ollama pull llama2:7b)
ollama rm 模型名 删除不需要的模型(释放硬盘空间)
ollama ps 查看正在运行的模型进程
ollama stop 模型名 停止运行中的模型
第二部分:安装FAISS(本地向量库)
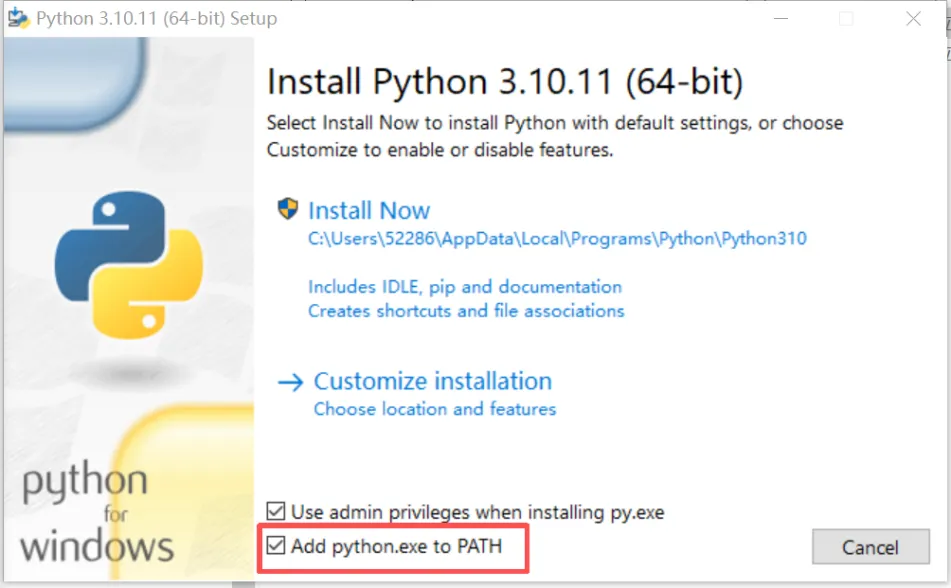
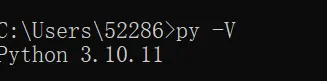
1、优先下载 3.10 版本(https://www.python.org/downloads/release/python-31011/)安装时勾选「Add Python 3.10 to PATH」。已配置Python 环境变量(cmd 输入python -V能显示版本即正常),如下图2.2 安装FAISS
说明:AI 专用的超级搜索引擎
FAISS = 一款专门用来做「向量检索」的高速搜索工具作用:从海量数据里,以毫秒级速度找到和你问题最相似的内容
简单比喻
FAISS = AI 的图书馆管理员
你问问题 → 管理员瞬间从百万本书里找到对应页码
再把内容交给 AI 整理成答案
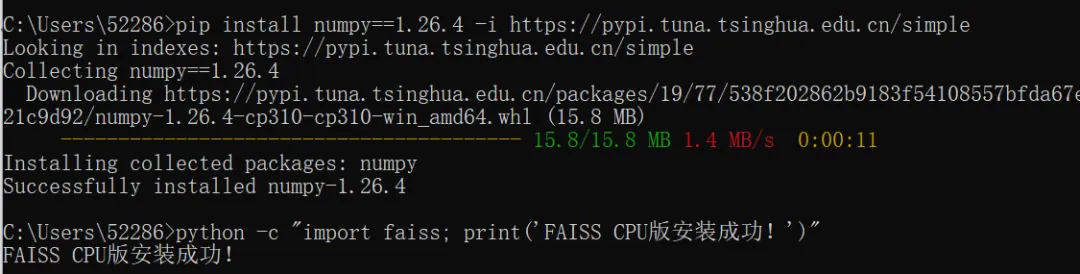
CPU 版无需独立显卡,适配所有 Windows 电脑,满足文献 RAG 检索需求在cmd界面输入下面三行代码,最终显示FAISS CPU版安装成功!pip install faiss-cpu==1.7.4pip install numpy==1.26.4 -i https://pypi.tuna.tsinghua.edu.cn/simplepython -c "import faiss; print('FAISS CPU版安装成功!')"Retrieval-Augmented GenerationRetrieval 检索:先在你的文档、知识库、PDF 里搜索相关内容。Augmented 增强:把搜到的资料喂给 AI,给它补充知识。Generation 生成:AI 结合资料,再给你生成准确、不胡说的回答。· RAG AI:先翻你的课本 / 笔记 → 找到对应段落 → 再整理答案→ 更准、更专业、不会乱编核心是:把道佛文献变成本地可检索的向量库,提问时先从向量库中找相关内容,再让模型基于这些内容写论文,精准且无幻觉。简单说:先检索本地文献,再生成内容,彻底解决模型编造假引文的问题。3.1 在电脑F盘上新建一个文件夹“daofo_literature”将道佛文献(《道藏》、专著、核心期刊论文等整理为纯文本/ TXT/PDF(扫描件用 OCR 转文字)。(Windows + Python 3.10 + FAISS 1.7.4)pip uninstall -y numpy faiss-cpu langchain pypdf chromadb sentence-transformers3.2.2 再安装 RAG 全套依赖
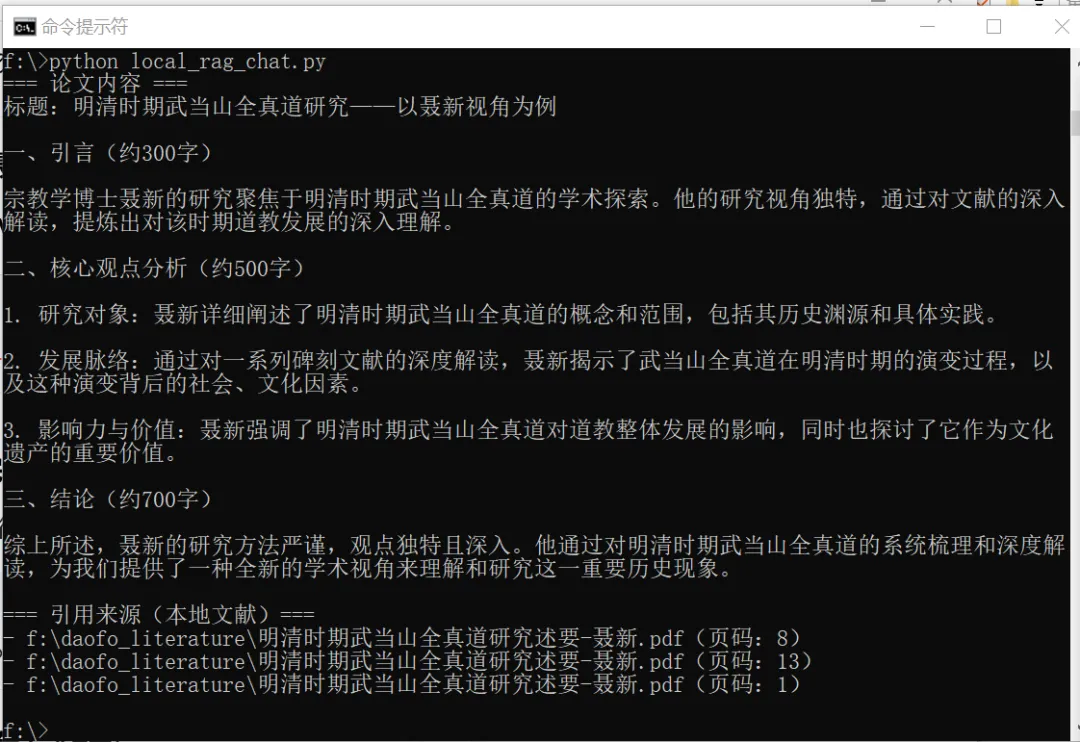
pip install langchain==0.1.10 pypdf==4.1.0 sentence-transformers==2.7.0 python-dotenv==1.0.1 -i https://pypi.tuna.tsinghua.edu.cn/simple验证安装:python -c "import langchain, faiss, sentence_transformers; print('依赖安装成功')"4.1.1 新建local_rag_chat.py文件# ====================== 修复 1:替换 langchain 导入 ======================from langchain_community.document_loaders import PyPDFLoader, TextLoaderfrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom sentence_transformers import SentenceTransformer# ====================== 1. 配置参数(你只需要改这里!)======================LITERATURE_PATH = "f:\\daofo_literature" # 你的知网下载论文存放的文件夹VECTOR_DB_PATH = "f:\\daofo_rag_db\\faiss_index.bin" # 向量库保存路径EMBEDDING_MODEL = "all-MiniLM-L6-v2"# ====================== 2. 加载并拆分文献 ======================def load_and_split_docs():pdf_loader = PyPDFLoader(f"{LITERATURE_PATH}\\明清時期全真道在河西走廊的傳播-程思尹.pdf")docs.extend(pdf_loader.load())text_splitter = RecursiveCharacterTextSplitter(separators=["\n\n", "\n", "。", ","]split_docs = text_splitter.split_documents(docs)# ====================== 3. 构建向量库 ======================# ====================== 修复 2:本地模型 + 禁止联网 ======================os.environ["TRANSFORMERS_OFFLINE"] = "1" # 强制本地模式os.environ["HF_HUB_OFFLINE"] = "1"embed_model = SentenceTransformer(EMBEDDING_MODEL)split_docs = load_and_split_docs()doc_texts = [doc.page_content for doc in split_docs]doc_embeddings = embed_model.encode(doc_texts, convert_to_numpy=True).astype('float32')dim = doc_embeddings.shape[1]index = faiss.IndexFlatL2(dim)index.add(doc_embeddings)faiss.write_index(index, VECTOR_DB_PATH)metadata = [{"text": doc.page_content, "source": doc.metadata["source"], "page": doc.metadata.get("page", 0)} for doc in split_docs]np.save(f"{LITERATURE_PATH}\\doc_metadata.npy", metadata)if __name__ == "__main__":1、修改代码中LITERATURE_PATH为你的文献实际路径;4、运行结束后会生成faiss_index.bin(向量库)和doc_metadata.npy(文献元数据)。执行:python build_local_rag_db.py5.1 新建local_rag_chat.py文件,复制以下代码: from sentence_transformers import SentenceTransformer# from langchain.llms import Ollamafrom langchain_ollama import OllamaLLM# ====================== 1. 配置参数(改这里!)======================VECTOR_DB_PATH = "f:\\daofo_rag_db\\faiss_index.bin" # 向量库路径METADATA_PATH = "f:\daofo_literature\doc_metadata.npy" # 元数据路径EMBEDDING_MODEL = "all-MiniLM-L6-v2"OLLAMA_MODEL = "qwen:7b" # 本地Ollama模型(也可填daofo-paper)# ====================== 2. 加载本地资源 ======================index = faiss.read_index(VECTOR_DB_PATH)metadata = np.load(METADATA_PATH, allow_pickle=True).tolist()embed_model = SentenceTransformer(EMBEDDING_MODEL)# llm = Ollama(model=OLLAMA_MODEL, base_url="http://localhost:11434")llm = OllamaLLM(model=OLLAMA_MODEL, base_url="http://localhost:11434")# ====================== 3. 本地检索 + 模型生成 ======================query_embedding = embed_model.encode([question], convert_to_numpy=True).astype('float32')distance, idx = index.search(query_embedding, k)if distance[0][i] < 1.0: # 过滤相似度太低的结果(阈值可调整)doc_meta = metadata[idx[0][i]]context += f"\n【文献片段】:{doc_meta['text']}\n【来源】:{doc_meta['source']} 页码:{doc_meta['page']}\n"sources.append(f"- {doc_meta['source']}(页码:{doc_meta['page']})")print("未检索到相关文献,直接生成(慎用)")prompt = f"""你是宗教学博士,专注道教/佛教研究,仅依据以下检索到的本地文献作答:2. 所有观点必须引用上述文献,标注「作者-来源-页码」;response = llm.invoke(prompt)print("\n=== 引用来源(本地文献)===")# ====================== 4. 运行示例 ======================if __name__ == "__main__":paper_question = "分析明清时期武当山全真道,聂新的相关观点,写1500字论述"pip install -U langchain-communitypip install -U langchain-ollama1、确保 Ollama 已启动(ollama run qwen:7b可先测试模型);2、 CMD 中执行:python local_rag_chat.py
3、等待生成(1500 字约 1-2 分钟),输出「论文内容 + 引用来源」。
2、 CMD
 夜雨聆风
夜雨聆风