 夜雨聆风
夜雨聆风标题:OpenClaw-RL:Train Any Agent Simply by Talking
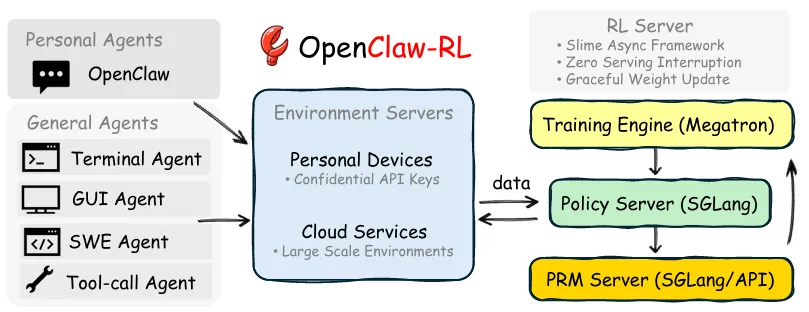
OpenClaw-RL 这篇工作最打动我的地方,就是它构建了一个真正意义上的在线强化学习飞轮(Online RL Flywheel)。它不挑场景,无论是个人对话助手,还是终端、GUI、SWE(软件工程)智能体,都能通过“收集下一状态信号”实现边用边学。
https://zhuanlan.zhihu.com/p/2016838379036221636
代码地址:https://github.com/Gen-Verse/OpenClaw-RL发表日期:2026-03-10
摘要:每一次智能体交互都会产生一个“下一状态”信号,即在每个动作之后出现的用户回复、工具输出、终端状态变化或 GUI 状态变化;然而,现有的智能体强化学习系统都没有把这种信号作为一种实时、在线的学习来源来利用。OpenClaw-RL的核心思想很简单:下一状态信号具有普适性,策略可以同时从所有这类信号中学习。个人对话、终端执行、GUI 交互、SWE(软件工程)任务以及工具调用轨迹,并不是彼此独立的训练问题,它们本质上都是交互过程,都可以在同一个训练循环中用于训练同一个策略。
下一状态信号包含两类信息:一类是评估性信号,用于指示动作完成得如何,并通过 PRM(过程奖励模型)评审器提取为标量奖励;另一类是指令性信号,用于说明动作本该如何改进,并通过后验引导的在策略蒸馏(Hindsight-Guided On-Policy Distillation, OPD)恢复出来。OpenClaw-RL从下一状态中提取文本提示,构建增强的上下文,并提供 词元级的方向性优势监督,这种监督比单一标量奖励更丰富。由于采用异步设计,模型可以持续服务线上请求,PRM 可以同时评审进行中的交互,而训练器也能同步更新策略,三者之间几乎没有协调开销。
将OpenClaw-RL 这一框架应用于个人智能体时,智能体能够通过“被使用”而不断改进,从用户的再次提问、纠正和显式反馈中恢复会话信号。将其应用于通用智能体时,同样的基础设施支持在终端、GUI、SWE 和工具调用等场景下进行可扩展的强化学习;此外,论文还展示了过程奖励在这些场景中的作用。
论文地址:https://arxiv.org/html/2603.10165v1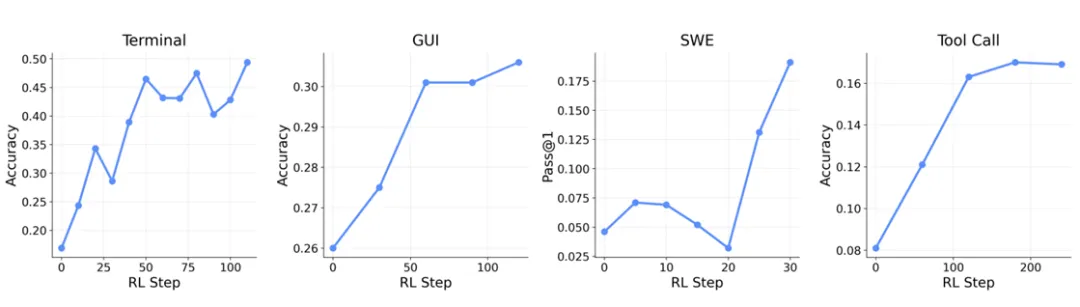
===========================================
星球号主要针对公众号提供增值服务,内容包括但不限于
| 博士团队提供公众号论文二次讨论,论文下载,算法代码指导 | |
专著作者面对面交流,《图深度学习从理论到实践》,《快速部署大模型 LLM策略与实践》作者面对面交流书内容跟着书籍零基础入门。 | |
IT就业指导,大厂面试指导,避坑指导, 《剑指大模型offer》真实面经,提升面试准备效率 | |
| 海内外大厂大模型/研究员信息聚合(twitter,facebook,youtube) | |
| RAG咨询 ,GraphRAG咨询,大模型咨询 | |
Graph 算法咨询,图挖掘,图推荐 图数据库咨询,neo4j, nebula |
话题相关文章:
