 夜雨聆风
夜雨聆风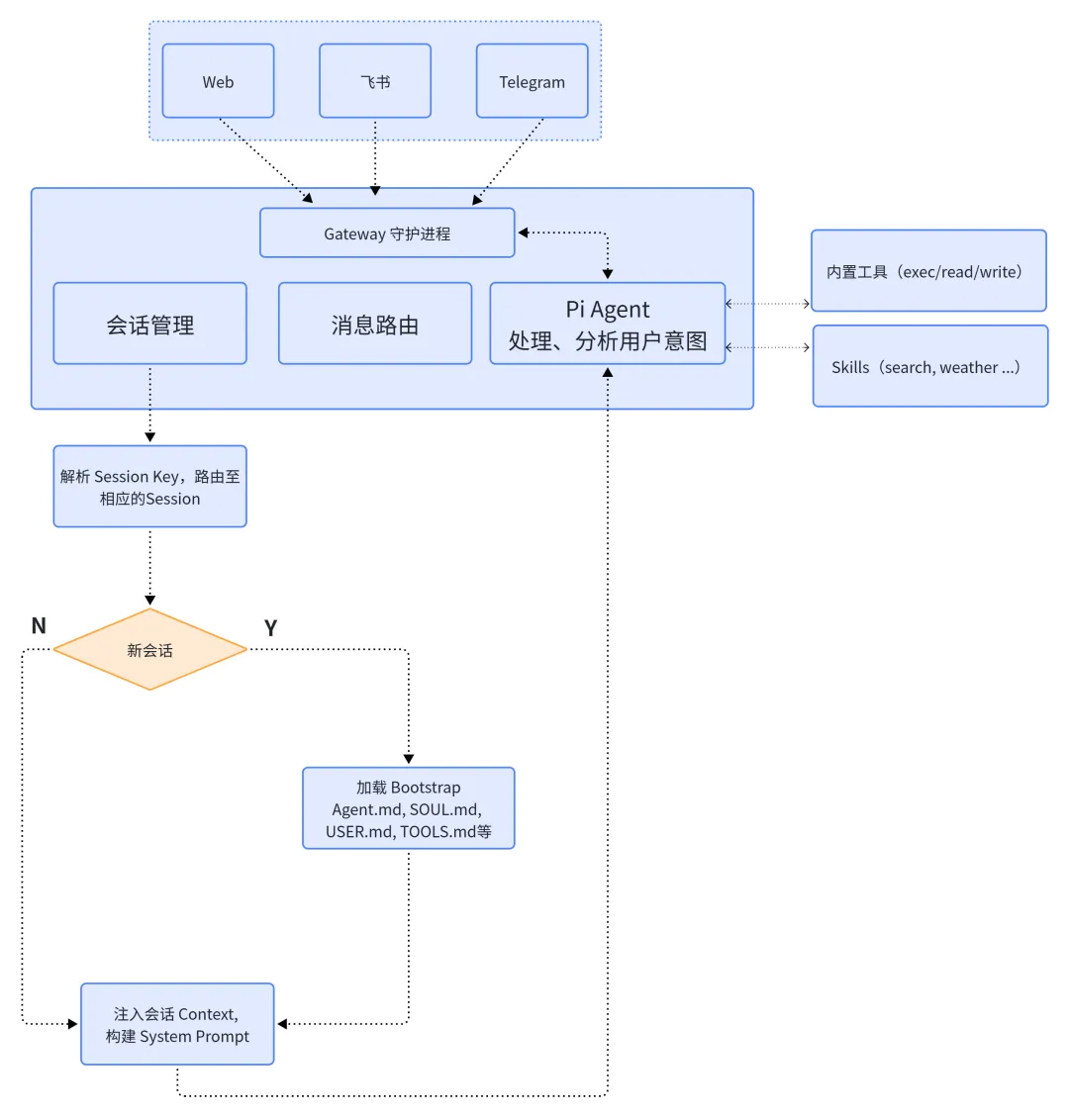
以上是依据个人理解画的一个OpenClaw消息流图,
引言:为什么需要理解完整会话流程?
用户消息如何从飞书/Web 渠道传递到智能体?
不同用户的会话如何隔离?上下文如何保持?
SOUL.md、USER.md 等配置文件何时加载?如何影响智能体行为?
工具调用(Skills/Exec/Memory)是如何触发和执行的?
一、消息接入与标准化
1.1、用户在不同渠道(Web 聊天窗口、飞书机器人、Telegram、Discord)发送消息后,OpenClaw 的第一道关卡是 Gateway 接收层,gateway 接收到不同的消息后,将它们标准化为统一的 message 对象
# 支持的消息渠道channels:- web: WebSocket/HTTP REST API- feishu: 飞书开放平台 webhook- telegram: Telegram Bot API- discord: Discord Gateway- whatsapp: WhatsApp Business API
二、Session Key 路由识别
消息标准化后,Gateway 面临一个关键问题:这条消息属于哪个会话?OpenClaw 通过 session Key 实现细粒度的会话隔离。
场景 | 消息特征 | 生成的 Session Key | 说明 |
|---|---|---|---|
用户在 Web 直接提问 |
|
| 所有 Web 直接聊天共享一个会话 |
飞书群@机器人 |
|
| 每个群独立会话 |
会话隔离的意义
上下文隔离:群A的对话历史不会泄露到群B
配置隔离:不同会话可加载不同的 USER.md(用户偏好)
并发安全:避免多线程写入同一会话状态
如果是一个新的会话,则通过 bootstrap 加载系统默认的 SOUL.md、USER.md 等建立会话。
三、工作区和上下文Context加载
一旦确定了 sessionKey,Gateway 需要为这个会话加载上下文配置文件。这些文件位于**工作区(Workspace)**目录中。
~/.openclaw/workspaces/
├── SOUL.md # 智能体人格定义
├── USER.md # 用户档案与偏好
├── AGENTS.md # 操作指令与记忆
├── TOOLS.md # 工具使用说明
├── IDENTITY.md # 智能体身份标识
└── memory/ # 向量知识库索引
对于新创建的Session, 有 bootstrap 负责加载至上下文中
async def load_workspace_context(session_key: str, workspace_path: Path) -> dict:"""加载工作区上下文文件"""context_files = {"SOUL": workspace_path / "SOUL.md","USER": workspace_path / "USER.md","AGENTS": workspace_path / "AGENTS.md","TOOLS": workspace_path / "TOOLS.md","IDENTITY": workspace_path / "IDENTITY.md"}
四、系统提示词创建
加载完上下文文件后,Gateway 需要将它们组装成系统提示词(System Prompt),这是影响智能体行为的最关键因素,因为不同场景,Session 下加载的内容不一,这也是为什么OpenClaw吃token(新说法叫词元)太多的原因之一。
4.1、动态提示词生成:
这里举一个例子,动态提示词加载
# Identity - 来源于Identified.md
你是 OpenClaw 助手,由 OpenClaw 团队开发。
# Personality & Behavior - 来源于SOUL.md
你是一个专业的 DevOps 工程师助手,擅长 Kubernetes、CI/CD 流水线设计。
# User Profile - 来源于 USER.md
姓名:小学生
技术栈:Python, FastAPI, Kubernetes
最终合成的Prompt长度就是:SOUL.md → USER.md → AGENTS.md → TOOLS.md → 渠道规则 → 最终拼接成完整的 System Prompt。最终可能形成一个几百K Token的上下文,未开始正式工作,“token 已如流水东去也”。
五、Pi Agent 推理引擎
系统提示词构建完成后,Gateway 通过 createAgentSession() 直接实例化 Pi Agent(同进程,非 RPC)
5.1、推理拆解过程
用户消息: "帮我部署一个 FastAPI 服务到 Kubernetes"
↓
┌─────────────────────────────────────┐
│ 1. 理解意图 │
│ - 识别任务类型:代码生成 + 部署 │
│ - 提取关键信息:FastAPI, K8s │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ 2. 检索上下文 │
│ - 查看 USER.md:用户技术栈确认 │
│ - 查看 SOUL.md:DevOps 专家角色 │
│ - 搜索记忆:是否有历史部署经验? │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ 3. 规划执行步骤 │
│ Step 1: 生成 FastAPI 代码框架 │
│ Step 2: 编写 Dockerfile │
│ Step 3: 生成 K8s Deployment YAML │
│ Step 4: 提供 kubectl 部署命令 │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ 4. 工具调用决策 │
│ - 需要读取模板文件?→ 调用 exec │
│ - 需要搜索最佳实践?→ memory_search│
│ - 需要生成代码?→ 直接推理 │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ 5. 生成响应 │
│ - 流式输出代码块 │
│ - 添加解释说明 │
│ - 提供下一步建议 │
└─────────────────────────────────────┘
六、工具调用与技能执行
Pi Agent 根据自己的推理思考,调用相应的工具或Skills, 缺乏什么样的Skill会去市场下载。
七、结果回流与响应
Pi Agent 的推理结果是流式输出的(token by token),Gateway 需要实时推送给用户
以下借助一个生成的图进行整个过程的说明
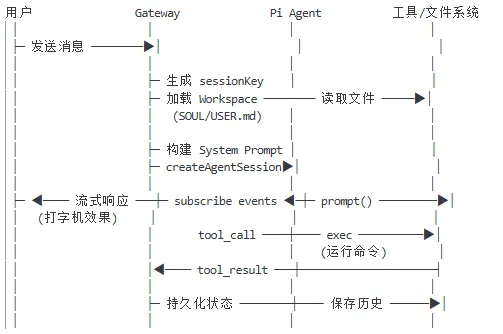
以上就是个人理解的一次完整的OpenClaw会话过程,OpenClaw 的强大,不在于单个组件,而在于这些组件如何无缝协作
参考文档:https://docs.openclaw.ai/
知识点扫盲:https://chat.qwen.ai/ - Qwen3.5 AI Model
注:一家之言仅供参考,如有问题还请各位朋友们交流讨论。
