 夜雨聆风
夜雨聆风↑↑↑ 点击关注,分享Agent 架构师涉及
今天分享一个很适合运维团队的小玩法:不用再盯着一堆 Dashboard,直接让 OpenClaw 定时巡检 Kubernetes 集群。
思路不复杂。给它装一个 k8s skill,喂一个只读 kubeconfig,再补一份 namespace -> 负责人手机号 的映射表。然后设个 cron,让它自己查。查到异常,就自动走短信 skill 去找对应负责人。
讲真的,这套东西最香的地方不是“AI 多聪明”,而是你终于把巡检这件反复横跳的脏活,塞给了 Agent。
我这次不是从零造一个监控系统,而是把 OpenClaw 现成的 Skill、权限、定时任务、短信通知四块积木拼起来。前提是你已经有一台跑着 OpenClaw 的机器。
先看一下效果。
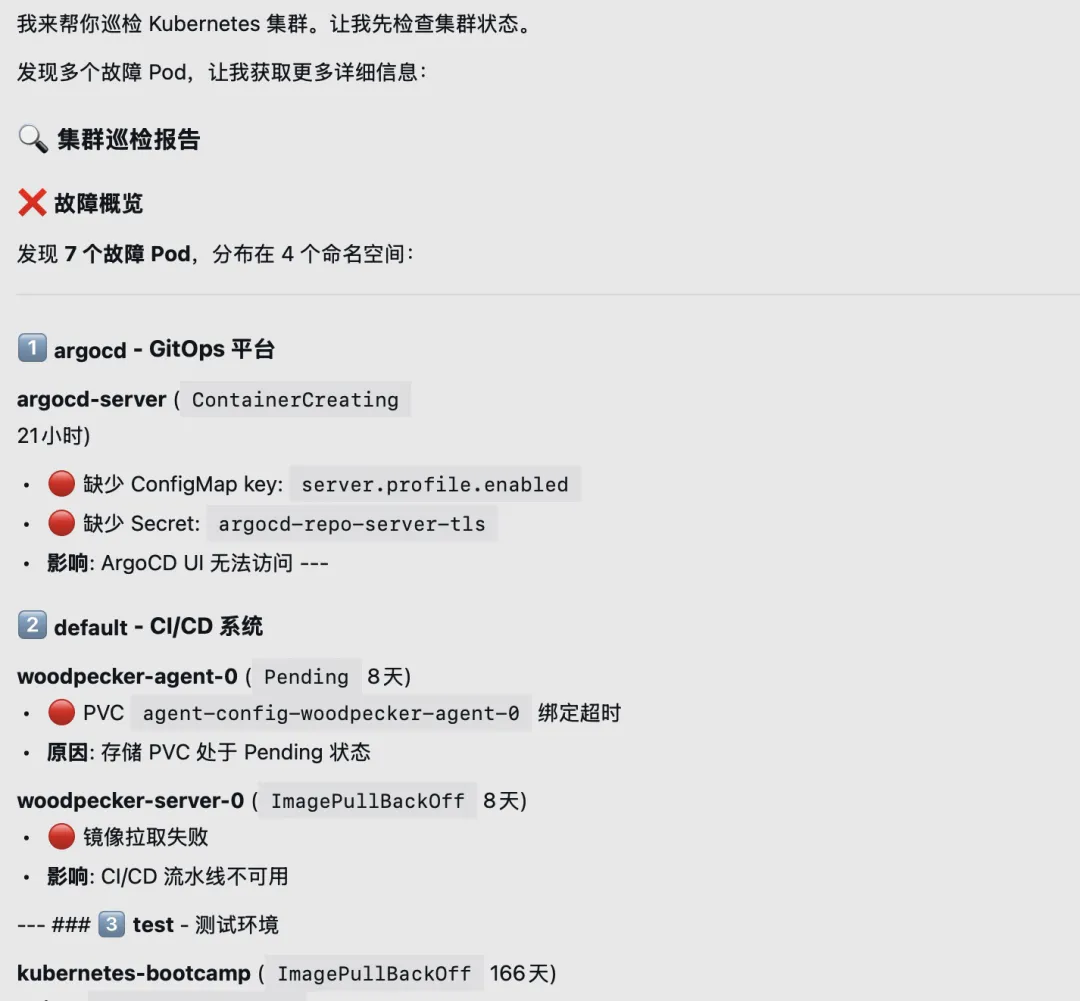
上面这张图里,OpenClaw 已经能把故障 Pod、所在 namespace、异常原因、影响范围都整理出来。
再往前走一步,把通知动作也接上,就变成下面这样。

一句大白话:“帮我巡检下集群,有故障的短信通知业务负责人。”
这就够了。
一. 先给 OpenClaw 装一个 k8s skill
Skill 这东西你可以把它理解成 SOP,不是黑魔法。
它本质上就是告诉 OpenClaw:碰到 K8s 巡检问题时,优先看哪些资源,先查 Pod,再看 Event,再判断是不是 PVC、镜像拉取、ConfigMap、调度这些问题。
最简单的装法,就是把 skill 目录丢进 OpenClaw 的 skills 路径里:
mkdir -p ~/.openclaw/workspace/skills
cp -r ./k8s ~/.openclaw/workspace/skills/
目录名你自己定就行,重点是里面要有一个清楚的 SKILL.md。
我会建议这个 skill 至少覆盖这些能力:
列出异常 Pod 查看 Pod 描述和 Events 识别常见状态,比如 CrashLoopBackOff、ImagePullBackOff、Pending、ContainerCreating按 namespace 汇总异常 输出“现象 + 原因 + 影响”
别一上来就让它做修复。先把“看明白”这件事做好,已经能省很多时间了。
二. 给它一个只读 kubeconfig
这里别贪方便,千万别直接把管理员权限塞给 OpenClaw。
巡检场景最合理的做法,就是专门给它建一个只读账号,只允许 get/list/watch。它的职责是看,不是改。
一个很常见的只读 RBAC,大概长这样:
apiVersion:v1
kind:ServiceAccount
metadata:
name:openclaw-inspector
namespace:ops
---
apiVersion:rbac.authorization.k8s.io/v1
kind:ClusterRole
metadata:
name:openclaw-readonly
rules:
-apiGroups:[""]
resources:["pods","pods/log","events","namespaces","nodes","services","persistentvolumeclaims"]
verbs:["get","list","watch"]
-apiGroups:["apps"]
resources:["deployments","statefulsets","daemonsets","replicasets"]
verbs:["get","list","watch"]
-apiGroups:["batch"]
resources:["jobs","cronjobs"]
verbs:["get","list","watch"]
然后把生成出来的 kubeconfig 单独放到 OpenClaw 能访问的位置,比如:
~/.openclaw/kubeconfigs/prod-readonly.yaml
这样做有两个好处。
一个是安全。就算 Prompt 翻车了,它也最多只能看,动不了你的集群。
另一个是边界清楚。你后面真要做“自动修复”,再单独做一个高权限 skill,不要跟巡检混在一起。
三. 再喂一份 namespace 和负责人手机号的映射表
这一步很关键。
很多团队的问题不是“看不到故障”,而是看到了也不知道该戳谁。最后全堆到平台组,平台组再去群里一个个问,烦得要死。
所以我建议直接维护一份轻量映射表。不要按 Pod 名,不要按 Deployment 名,就按 namespace 来。
因为业务归属这件事,namespace 最稳。
比如你可以放一个 owners.yaml:
argocd:
owner:张三
mobile:13800138000
biz:GitOps平台
default:
owner:李四
mobile:13900139000
biz:CI/CD系统
test:
owner:王五
mobile:13700137000
biz:测试环境
OpenClaw 巡检完之后,只要拿异常 namespace 去查这个表,就知道短信该发给谁。
说白了,这一步是在给 Agent 补“组织结构”。
不然它再能看,也只是个会报错的实习生。
四. 让 OpenClaw 定时巡检
接下来就是把它从“你问一下它才查”变成“它自己按点上班”。
OpenClaw 本身就适合接 cron。你只需要在定时任务里塞一段明确的巡检指令。
我比较推荐直接写成这种风格:
请使用 k8s skill 巡检生产集群:
1. 检查所有 namespace 中异常 Pod
2. 汇总 Pod 状态、持续时长、可能原因
3. 标出业务影响
4. 结合 owners.yaml 找到对应负责人
5. 如果没有异常,只回复“本轮巡检正常”
6. 如果有异常,生成简洁报告并准备调用短信 skill
频率上别太激进。
如果你只是想补一层“智能巡检”,15 分钟一次或者 30 分钟一次就够了。真要秒级告警,那还是 Prometheus + Alertmanager 更靠谱,OpenClaw 适合吃“需要归纳和解释”的那部分。
还有个小细节我很建议你加上:同一个定时任务不要并发跑。
不然上一次巡检还没看完,下一次又来了,最后短信乱飞,业务负责人会先来找你。
五. 有异常就走短信 skill
这一步接上之后,整个链路就闭环了。
OpenClaw 先巡检,定位异常 namespace,再查 owners.yaml,最后把异常摘要丢给短信 skill。短信内容别写成长文,够短、够狠、够能让人看懂就行。
像下面这种就够用了:
[K8s巡检告警]
集群: prod
命名空间: argocd
异常: argocd-server ContainerCreating 持续 21 小时
原因: 缺少 ConfigMap key / Secret
影响: ArgoCD UI 无法访问
处理人: 张三 13800138000
我个人建议短信只做两件事:告诉谁出问题了,告诉他先看哪。
别在短信里塞一大坨技术细节。真要细看,让负责人回到 OpenClaw 的完整巡检报告里再看。
我觉得这套方案最值钱的地方
不是省了一个 kubectl get pods -A。
而是你把“发现问题 -> 判断归属 -> 通知到人”这一串本来很碎的动作,串成了一条链。
以前巡检像什么呢?
一个运维同学早上打开电脑,先看监控,再看 Pod,再看 Events,再去翻 namespace 对应的业务群,最后手动发消息。
现在变成了:OpenClaw 自己看,自己整理,自己找人。
人只在最后接住异常。
这就是 Agent 放在运维场景里最舒服的一种用法。它不替你拍板,不替你瞎修,但它能把那些又琐碎又重复的流程先吞掉。
最后提醒三个坑
第一,权限一定只读。狗命要紧。
第二,负责人映射一定按 namespace 维护,不要跟资源名绑死,不然后面改一次发布名,你的通知链就歇菜了。
第三,先跑通知,再考虑自动修复。很多团队一上来就想让 Agent 重启 Pod、扩容、回滚。讲真的,这步太快了,先把告警链路跑顺再说。
如果你最近正好在折腾 OpenClaw,又有 K8s 巡检这种重复活,这个玩法真的可以试试。5 分钟接起来,后面每天都能省一点命。
OpenClaw 官方站点:https://openclaw.ai/
GitHub 仓库:https://github.com/openclaw/openclaw
好啦,感谢阅读,感兴趣的可以自己接一遍,有问题评论区聊。
