 夜雨聆风
夜雨聆风深入解析OpenClaw龙虾的记忆方案与底层架构,教你如何为AI智能体构建持久且精准的记忆。

1 记忆存储
1.1 三类核心文件
在OpenClaw的设计哲学中,模型本身并不存在凭空的记忆,所有被记住的内容必须真实写入磁盘。
智能体工作空间中的纯Markdown文件(以及系统底层的JSONL运行记录)就是系统唯一的事实来源。在同一段对话中,OpenClaw通常将内容分为三类,分别服务于不同目标:

长期记忆:这个文件通常位于工作区的根目录。它非常精简,只保留最重要的事实和偏好。系统在启动时会优先加载它,确保 Agent 在任何时候都不会违背这些核心设定。
文件示例:workspace/MEMORY.md

日常记忆:日常记忆以日期命名,采用Append-only(仅追加)模式。当用户要求 Agent 记一下某事时,Agent会优先调用写入工具记录在这里。它避免了琐碎信息污染长期记忆,同时为未来的 RAG 检索提供了带有时间戳的依据。
文件示例:
workspace/memory/2026-03-27.md

会话运行记录:这是系统最底层的数据流,完整保留了 Agent 的思考过程(CoT)、工具调用(ToolCalls)、API耗时以及系统元数据。使用 JSONL 格式不仅方便流式写入,也地简化了断点续传和会话重放。
文件示例:
agents/main/sessions/f4fc3f5.jsonl
1.2 记忆写入时机
✅记忆写入的时机与谁在写
这三类文件的写入时机截然不同,核心区别在于谁在写:
•高频运行时写入(会话记录):*.jsonl由运行时实时维护。对话进行中,系统持续将用户消息、模型回复、工具调用及结果追加落盘。此路径不依赖模型调用工具,而是内部会话管理直接写入,频率最高。
•工具调用写入(长期/日常记忆):.md文件由 Agent 在某个回合中通过调用文件工具(如 write, edit, apply_patch)主动写入。当用户明确要求记住某个偏好或模型主动整理信息时,更新长期记忆。
✅静默刷新
当会话上下文接近自动压缩阈值时,OpenClaw会触发一个优雅的静默回合(pre-compaction memory flush)。系统会自动提醒模型在上下文被压缩丢失前,将重要信息写入持久化记忆文件。此时,模型默认更倾向于将内容追加写入日常记忆(memory/YYYY-MM-DD.md),而不是直接覆盖长期记忆文件。由于默认提示词已指明模型可以直接返回NO_REPLY,这一过程对用户完全透明,实现了无缝的记忆留存。
✅灵活的外部路径挂载
默认情况下,系统只索引内部的工作空间文件(长期与日常记忆)。但如果拥有共享的文档库或外部项目文档,只需在配置文件中通过 agents.defaults.memorySearch.extraPaths 声明绝对路径或相对路径,系统就会递归扫描其中的.md文件并纳入记忆检索范围。
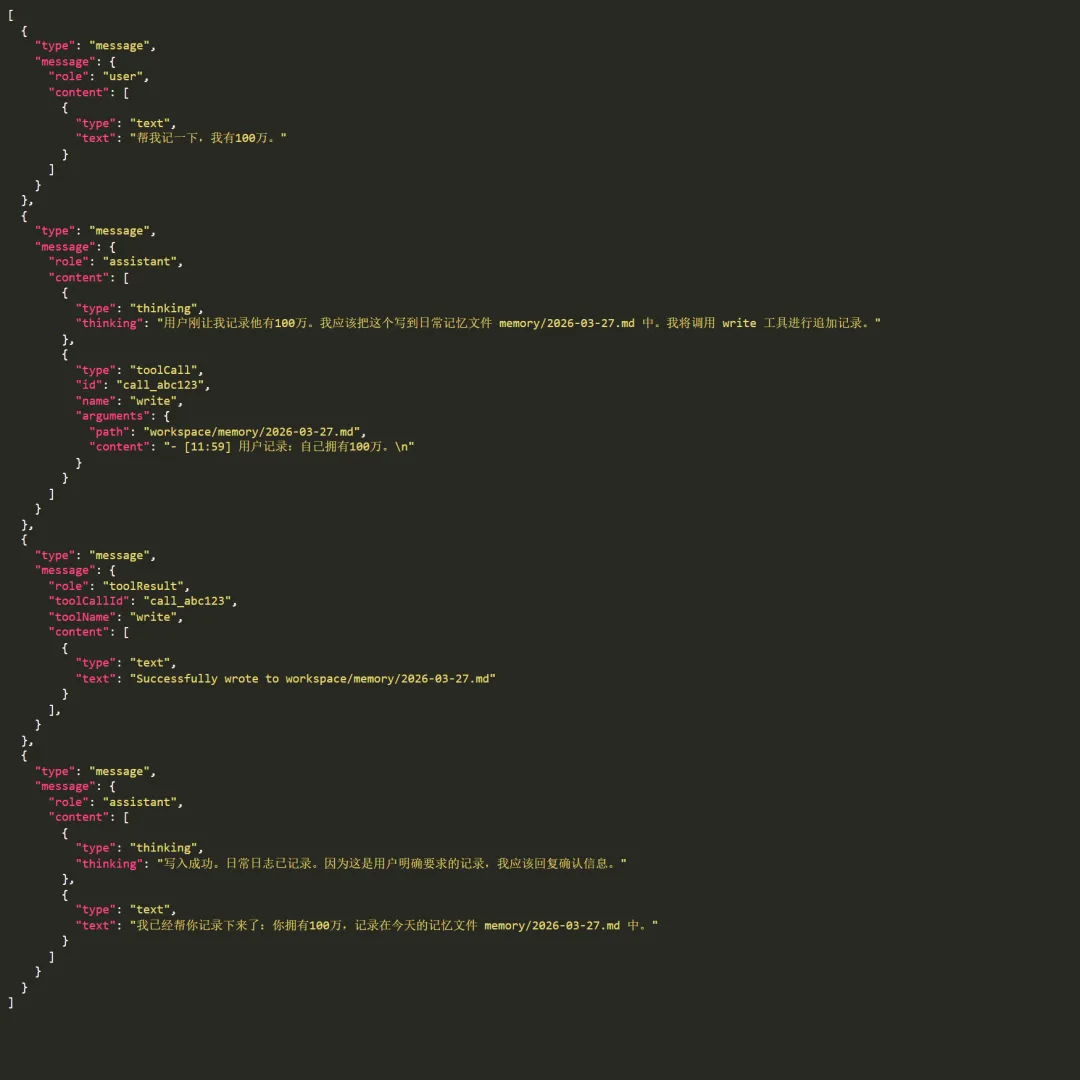
1.3 要求记录信息
当用户要求记录长期偏好或事实信息时,模型会经过思考,定位到对应的 Markdown 记忆文件,并调用文件编辑工具进行精准的文本替换或插入。写入记忆的JSON日志:

1.4 结构化文件夹
作为最容易上手且被严重低估的记忆方案,可以在项目根目录或智能体工作区建立专门的文件夹树,并在系统提示词中指令代理在每次会话结束时更新相关Markdown文件。
这种方法最大的优势在于绝对透明(无黑箱)、兼容所有主流大语言模型,并且赋予你100%的结构掌控权。

2 记忆索引
✅索引构建与写入向量库的时机
OpenClaw会为每个智能体在 ~/.openclaw/memory/.sqlite 建立独立的SQLite索引库。在默认配置下,参与记忆索引的真源是工作区中的长期记忆和日常记忆(会话运行记录默认不进入索引)。
向量库的写入绝不是每次写记忆文件就立刻同步,而是由 MemoryIndexManager 通过复杂的监听与调度机制在 sync() 流程中完成。以下时机会触发同步并可能写入向量库:
• 1.会话开始:系统尝试发起一次异步写库动作,确保首次检索时延不被拉高,且索引新鲜度不完全依赖后续的定时任务。
• 2.检索前发现索引为脏:模型调用 memory_search 时系统先自检。若之前文件有变动被标记为脏,系统会在检索开始前强制安排后台同步,让索引追上最新内容。
• 3.工作区记忆文件变更后(防抖机制):持续监听工作区.md文件(增/删/改)。检测到变动后不立刻同步,而是标记为脏并启动防抖等待(如1.5秒去抖动)。此举既能避免读取写入到一半的残缺文件,又能合并短时间内的一批变更,减少重复索引和消耗。
• 4.定时同步(兜底机制):按配置的时间周期性触发检查。若无变化则迅速结束;若监听器漏掉变更或系统重启需校正状态,则执行实际更新。
• 5.手动触发:通过 CLI 执行 memory index 等显式命令强制重建。
✅触发重新索引的条件
为了保证检索的绝对准确,系统记录了详细的指纹信息。当嵌入提供商/模型发生改变、端点指纹变动,或分块参数被修改时,OpenClaw的内置监视器会自动感知,重置并重新索引整个存储库,确保向量数据与当前模型配置完美匹配。
3 记忆检索
3.1 向量语义搜索与渐进式披露
内置的记忆搜索功能(MemorySearch)允许智能体通过自然语言查询过去的对话与上下文。它使用的是向量检索技术而非简单的Ctrl+F关键词匹配。这意味着系统是将信息转化为数学向量存储,即使你今天查询的措辞与三周前完全不同,只要语义一致,智能体依然能精准提取相关记忆。
✅渐进式披露设计
OpenClaw突破了传统的无脑全文灌入,通过两个底层工具链(memory_search和memory_get)向大模型暴露记忆能力,完美实现了渐进式披露的信息架构模式(即逐步展现复杂性以节省Token并提高准度):
•第一层(索引 / Layer 1):
模型调用memory_search,系统返回轻量级元数据(如文件路径、标题、相关度分数等)。
•第二层(详情 / Layer 2):
memory_search同时返回包含行范围的内容片段(Snippet,约700字符),不暴露全文。
•第三层(深潜 / Layer 3):
当片段信息不足以确认细节时,模型再主动调用memory_get,按路径与确切的行范围读取原始 Markdown 的完整源内容。
查询会议记录的JSON日志演示了这一过程:

许多用户发现记忆功能失效,核心原因在于向量搜索依赖外部的嵌入模型(EmbeddingModel)。即使你使用Anthropic的Claude作为主对话模型,你也必须在设置中提供OpenAI、Gemini或Voyage的API密钥以支持底层嵌入运算。一旦配置成功,每次嵌入调用的成本不到几分钱,却能换来极其流畅的检索体验。本地模式下,也可通过node-llama-cpp实现支持。
3.2 混合检索架构
✅向量与全文搜索的融合
向量搜索虽然擅长语义匹配(如识别MacStudio网关主机等同于运行网关的机器),但在处理特定ID、代码符号或错误堆栈等高频精确Token时表现疲软。为此,OpenClaw引入了强大的混合搜索架构,将向量相似度与BM25关键词相关性结合,提供兼顾自然语言查询与大海捞针的全能检索能力。
✅结果合并机制
混合搜索在底层分别从双方检索候选池中获取数据。向量端按余弦相似度提取,而全文端按FTS5BM25排名提取。系统随后将BM25排名通过公式 textScore = 1 / (1 + max(0, bm25Rank)) 转化为标准化分数,最后结合权重计算最终的finalScore,将最匹配的内容呈现给智能体。
4 第三方记忆插件
下面这段可以直接替换你博客里的原文:
4 第三方记忆插件
如果希望 OpenClaw 的长期记忆不再主要依赖默认的本地 Markdown / memory-core,而是交给外部系统自动完成提取—存储—召回,当前比较有代表性的第三方方案可以看Mem0、MemOS、OpenViking。
需要注意的是,OpenClaw的 memory slot 是独占的;其中Mem0走的是 memory plugin 路线,MemOS当前官方 OpenClaw 集成是 lifecycle plugin,而OpenViking当前主线接入是 context-engine plugin
可以,改成更轻量的版本,适合博客直接贴:
4 第三方记忆插件
如果你不想手动维护 OpenClaw 记忆,也可以接入第三方记忆方案。当前比较典型的有Mem0、MemOS、OpenViking。三者都能实现自动保存 + 自动召回,但侧重点不同。(docs.mem0.ai)

5 原生数据库记忆
✅突破文本瓶颈的SQLite
当面对密集的结构化数据(如包含上百个API端点、财务数据或客户记录)时,传统的Markdown文件和向量搜索会彻底崩溃。OpenClaw提供了令人惊叹的方法:原生支持SQLite数据库的读写。无需额外插件或API密钥,智能体可以直接创建表结构并填充数据。
✅精准查询与自然语言转SQL
对于需要精确条件筛选的场景(例如:列出所有需要认证且与用户管理相关的API),智能体能够理解自然语言指令,将其转化为标准SQL语句执行查询,并直接向你汇报结果。由于数据库就是一个独立的.db文件,它具备极强的便携性,甚至支持版本控制。
