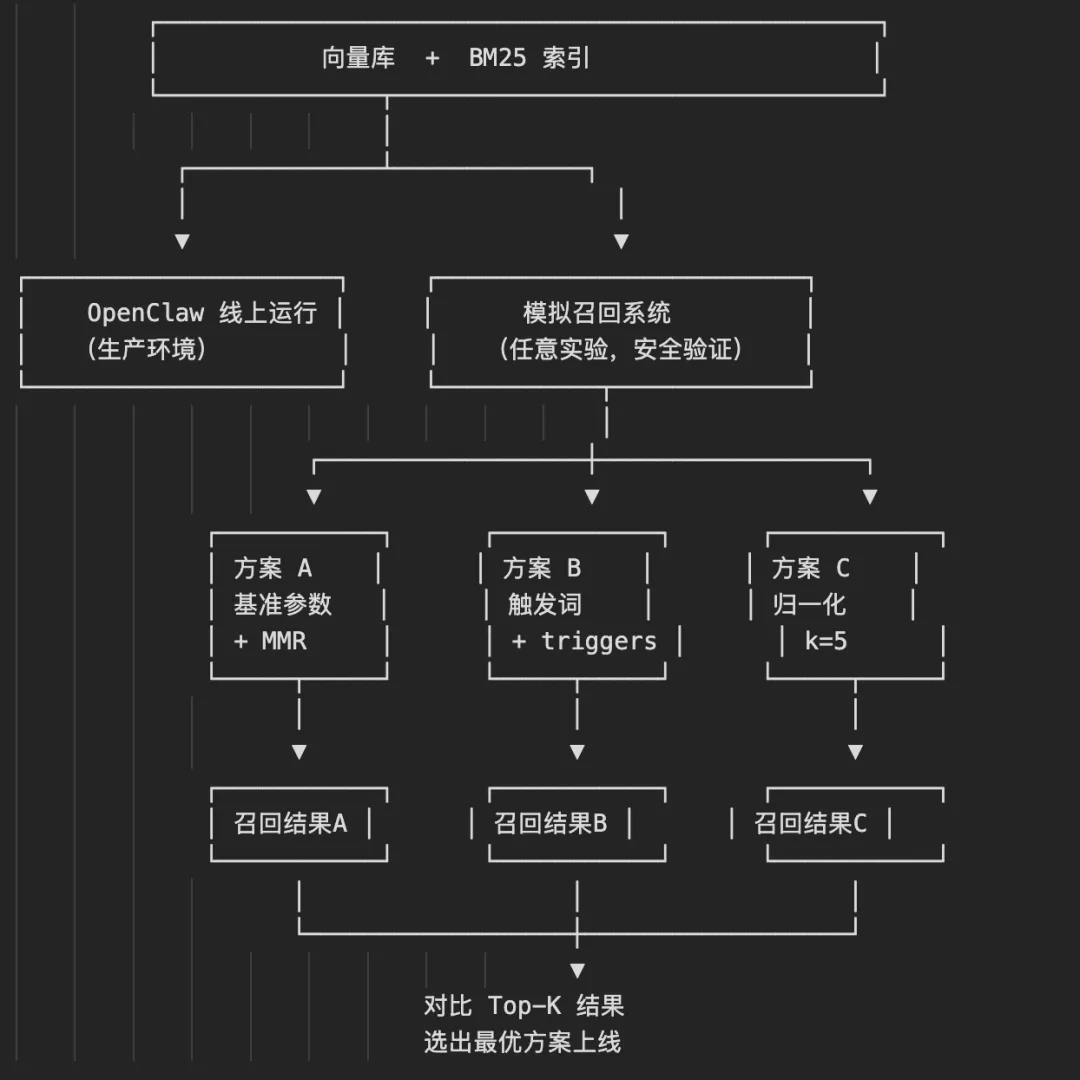
不知道大家在使用OpenClaw、Claude Code或是CodeBuddy这类工具时,是否常常遇到这样的困扰。明明之前已经交代过的事项,转眼就遗忘,哪怕相关信息记录在OpenClaw的Daily文件里,也无法被自动调取。 又或是即便已经反复优化过某Skill的触发词,Agent依旧无法按照预期执行调用,每次都需要手动额外说明“请使用xx Skill”,才能完成对应操作。 这其实不是模型本身的“智力问题”,而是上下文信息的结构性问题,即要么上下文缺失,要么上下文太多噪音。 接下来我分享一下在记忆方面的探索和思考,来解决更精准填入上下文信息的问题,希望就此抛砖引玉。 起步阶段:依托OpenClaw官方插件搭建基础 memory-core:支持向量检索 + BM25,但没有 auto-recall,依赖模型主动调用,模型没调用,这段记忆就不会进入上下文; memory-lancedb:有 auto-recall,但只有纯向量检索,没有关键词精确匹配。 两者没法同时用。所以我以 memory-lancedb 为基础,加上 BM25 + MMR,重写了一套同时具备"自动召回"和"关键词精确匹配"的记忆系统。 其实社区里已经有成熟的开源方案,比如memory-lancedb-pro,早已实现了向量检索+BM25+自动召回的完整组合,甚至还有Mem0、Hindsight这类可直接用于生产环境的成熟记忆解决方案。 但我还是抱着学习的态度去自研,顺便理解向量检索、BM25、召回排序、遗忘策略是什么。自己写的代码,哪里有问题、哪里可以优化,完全透明,也“更具可玩性”。 检索方案优化与分层记忆架构搭建 官方这套向量 + BM25 双路互补,向量检索找"语义相似",BM25 找"关键词匹配",看似很美好。 但随着对话增 长, 噪音也在 累积 。BM25 可能把几个月前已经不重要的记忆捞出来,向量库被低质量内容稀释,好的记忆被稀释掉。 所以减少噪音还涉及 遗忘,记忆被调用的次数越多就越稳固,长久闲置的则会自然衰减,人类的大脑也是这样工作的,于是有了分层的架构。 短期记忆永久保留,但召回时有权重衰减,越新的记忆权重越高,越久远的历史权重越低,长期不用的记忆在召回时逐渐被稀释。只有被反复召回命中过(hitCount ≥ 2)的记忆才值得作为精华沉淀长期保留。 架构搭好了,召回反而更差了 分层架构带来了新的参数:什么时候沉淀?命中多少次才晋升?有效重要性低于多少该删除? 这些参数没有任何经验值。结果是:短期记忆既没有被正确遗忘,也没有被合理晋升。整个系统该记住的没记住,不该记住的占满向量库。 1)不断调参:今天把 hitCount 从 2 改成 3,明天把阈值从 0.1 改成 0.2。治标不治本。 2)建立评测体系:收集 bad case → 聚类分析 → 多方案尝试 → 模拟召回系统离线验证。 相比于不断调参的长尾做法,我选择了搭建模拟召回系统,让同一批 query 可以同时跑不同的召回方案,对比效果后再决定是否上线: 自进化:让记忆系统自己发现问题 AI 评测的幻觉问题 一开始让 AI 自动收集bad case,让它对每个 query 和召回结果打分,它只看到"召回了什么",看不到"应该召回什么",结果打分的结果全是bad case。(因为个人记忆内容少,大部分对话肯定是没有相关记忆的) 正确做法:bad case 必须有"对照组"。 如果 AI 认为某个召回分数低,必须同时在记忆库里找到一条更高分的候选,否则不能简单判断为"不相关"。这样 bad case 才真正被准确积累。 有了准确的 bad case,再让 AI 分析共性、生成修复方案。 1)真实案例:Query Rewrite 用户在实际使用中,输入往往不是单一的、语义完整的句子。比如
这句话里其实包含了两个独立的意图:
如果不做任何处理,直接把这句话拿去检索,召回系统可能会把"广州天气"和"飞书"当成一个整体去匹配,导致匹配不到合适的结果,两边都召回得很差。
Query Rewrite 的作用,就是把用户的复合 query 拆解成多个子查询, 让每条意图都能独立地去召回相关记忆,最后再把结果合并。
我:"这个不要存向量,直接写到 memory.md 作为长期记忆" Rewrite 后:"memory.md 长期记忆写入" 丢失了"不要存向量" 这个否定意图 系统把所有和向量相关的记忆都排在前面,完全没理解用户是想"不要存向量"。 解决: rewrite prompt 加上"否定词原样保留"的规则。 2)真实案例:偏好记忆文本太抽象,向量距离太远 我:"写到我的知识库 todo 里面" 期望召回:Obsidian vault 规范(todo 文件放在 Obsidian/todo/) 实际召回:完全没有召回到这条记忆 根因: Obsidian 规范文本很规整,但我说的是口语化的"知识库 todo",两者语义相关但向量距离很远。 解决: 在记忆沉淀时,让 LLM 自动生成这条记忆的"检索触发词"(如"todo""待办""知识库""写到"),拼入 embedding 文本,拉近向量距离。 为什么在存储端做,而不是在查询端做? 业界主流的 RAG 系统通常在 query 侧做查询扩写,即每次用户搜索时,把 query 扩写成更完整的表述,再去匹配。这是考虑到生产环境的记忆量巨大,在存储侧维护的成本太高。 但个人 Agent 的记忆量少得多,在存储时一次性做好扩写,每次查询就不用再重复计算。对个人开发者而言,在存储端做触发词生成的成本更低、效果更稳定。 3)真实案例:丢失了上文语境 我:帮我配置一下 WebMCP,我要让它能和我本地的 MCP 服务器通信 Shadow:好的,WebMCP 的配置需要... 我:我都配置好了,你试试能否握手成功 Rewrite后:握手测试 丢失了上文“WebMCP”这个关键语境 根因: rewrite 模型只能看到当前 query,看不到上文对话。 解决: 把N轮的对话历史注入 rewrite prompt。 结语:流程比技术堆砌更重要,场景适配才是核心 多路检索、评分归一、MMR 重排序,这些技术本身并不难。 重要的不是用了多少技术,而是一套日常发现问题、分析问题、用真实数据验证的整体流程。 技术会迭代,但流程是核心。 从技术形态看,个人 Agent 的记忆系统和通用 RAG 知识库长得很像,但 使用场景完全不同。 通用 RAG 面对:不同用户 + 海量文档/代码库 + 每次查询需求差异巨大。Claude Code 为此直接放弃了 RAG,转向 bash + grep。 个人 Agent 的场景简单很多:信息量少,语义输入只有使用者一个人。针对性优化是可行的。也就是说可以用更简单的架构持续迭代,专注于自己的使用习惯。 优化后,很多事项只需说明一次就能精准记住并执行,让个人 Agent 真正实现了“懂你所需、记你所托”。(本文板式由公众号网页端“一键排版”功能完成)
 夜雨聆风
夜雨聆风