 夜雨聆风
夜雨聆风第一章 全局视角——OpenClaw 的设计蓝图
OpenClaw 是一个自托管的多渠道 AI 网关,用 TypeScript(ESM)编写,运行在 Node.js 22+ 之上。它的核心命题很简单:让一个 AI Agent 同时活跃在 WhatsApp、Telegram、Slack、Discord、Signal 等二十余个通讯平台上,通过统一的运行时管理对话、记忆、工具调用和安全策略。
从架构角度看,OpenClaw 更像一个面向 AI Agent 的操作系统。Gateway 扮演内核角色,插件系统提供驱动程序式的可扩展性,渠道适配层负责 I/O 抽象,Agent 运行时则是核心进程。
这种分层设计让每一层都能独立演进。新增一个通讯渠道只需实现一个 Channel Plugin,切换 LLM 提供商只需更换一个 Provider Plugin,Agent 的核心执行逻辑对这些变化完全无感。
下面的分层架构图展示了各子系统之间的层次关系和数据流向。后续章节将沿着这张图从内到外逐层展开。
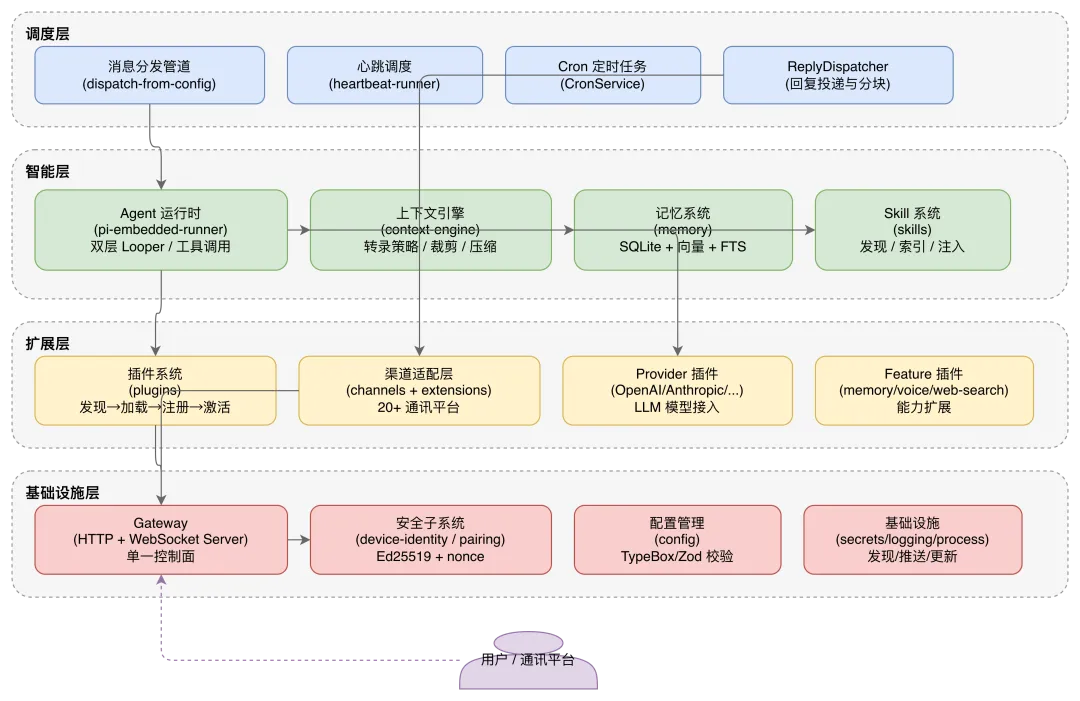
这四层之间构成了一条清晰的数据生命线:用户消息从通讯平台进入渠道适配层,经 Gateway 路由到消息分发管道,分发管道交给 Agent 运行时处理,Agent 在上下文引擎和记忆系统的支撑下完成推理,最终通过 ReplyDispatcher 将回复投递回用户。
心跳和定时任务则在这条主线之外,以独立的调度循环驱动 Agent 执行周期性工作。接下来的章节将从基础设施到上层调度逐层展开。
第二章 Gateway——系统的中枢神经
如果把 OpenClaw 比作一台计算机,Gateway 就是它的内核。所有客户端——CLI、WebChat、macOS 桌面应用、远程移动节点——都通过 WebSocket 连接到这个唯一的服务端进程。Gateway 不直接处理 AI 推理,但掌控着系统的一切生命周期:插件加载、渠道启停、会话管理、定时调度、配置热重载。
这种"单一控制面"的设计是深思熟虑的架构决策。在自托管场景下,单进程模型的优势非常明显:部署简单、状态一致性有保证、调试链路清晰。并发控制通过 Lane 队列机制解决——每个会话一条 session lane,全局一条 global lane,避免多个 Agent 对同一会话产生竞态。
启动序列
Gateway 的启动流程体现了"分阶段初始化"模式。startGatewayServer 是整个系统的入口,将启动过程拆为若干有序阶段,每阶段完成后才进入下一个,确保依赖关系得到满足。
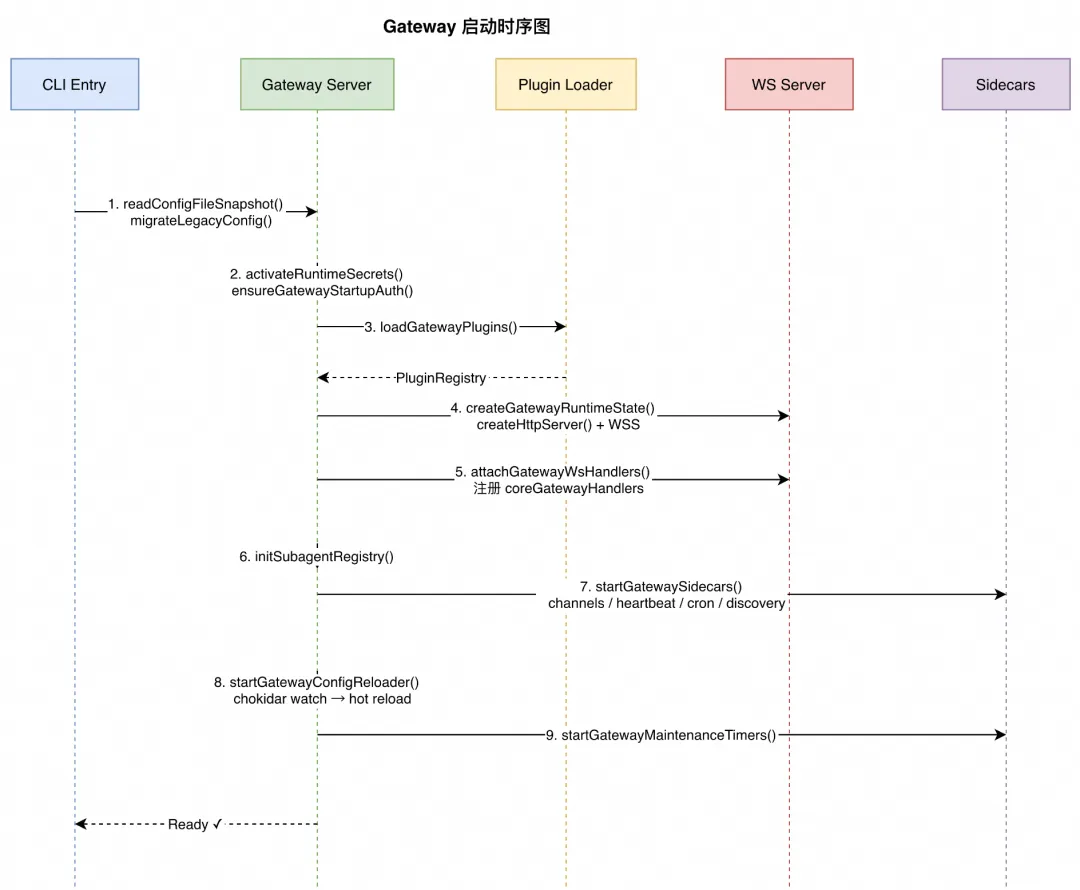
启动序列中值得注意的是第 3 步和第 5 步的关系。插件加载必须在 WebSocket handler 注册之前完成,因为 loadGatewayPlugins 返回的 PluginRegistry 包含了插件注册的 gateway method handler,这些会被合并到 coreGatewayHandlers 中。如果顺序颠倒,插件注册的 RPC 方法将无法被客户端调用。
WebSocket 请求分发
Gateway 建立 WebSocket 连接后,首先进行身份认证而非处理业务请求。每个新连接收到一个 connect.challenge 事件(携带服务端 nonce),客户端必须在规定时间内完成认证握手,否则连接被强制关闭。这个流程在第十章详细展开。
通过认证后,消息分发采用经典的命令分发模式(Command Dispatcher Pattern):客户端发送的每条消息包含一个 method 字段(类似 JSON-RPC),服务端从预注册的 handler map 中查找处理函数。
// coreGatewayHandlers 的组装方式
exportconst coreGatewayHandlers: GatewayRequestHandlers = {
...connectHandlers,
...chatHandlers,
...sessionsHandlers,
...cronHandlers,
...configHandlers,
...agentHandlers,
...browserHandlers,
// ... 共 25+ handler 组
};
这种设计的好处在于高度可扩展:核心 handler 和插件 handler 使用完全相同的注册与分发机制。插件通过 api.registerGatewayMethod(method, handler) 注册自己的 RPC 方法,这些方法与核心方法享有同等地位,调用者无法区分核心功能和插件功能。
在分发之前,handleGatewayRequest 会执行两道前置检查。authorizeGatewayMethod 验证角色和权限是否匹配;高危写操作(如 config.apply)还会施加速率限制。整个分发被 withPluginRuntimeGatewayRequestScope 包裹,确保插件运行时作用域正确绑定,避免跨插件的状态污染。
运行时状态
createGatewayRuntimeState 创建的运行时状态对象是 Gateway 的"内存数据库"。它持有所有活跃连接(clients Set)、会话运行状态跟踪(chatRunState)、去重表(dedupe)、全局序列号(agentRunSeq)和中断控制器(chatAbortControllers)。
这些状态都不做持久化——这是有意为之的。Gateway 被设计为可随时安全重启,会话的持久化由独立的 session 文件机制保证。重启后,子 Agent 注册表通过 restoreSubagentRunsFromDisk 从磁盘恢复,确保正在执行的子 Agent 任务不会丢失。
第三章 插件系统——可插拔的扩展骨架
OpenClaw 的插件系统是整个架构中最能体现"开闭原则"的部分。核心运行时只定义契约和生命周期,所有具体能力——接入 GPT-4 或 Claude、连接 Telegram 或 Discord、添加记忆检索或语音合成——都以插件形式存在于 extensions/ 目录下。目前已有超过 80 个插件。
插件系统遵循一条完整的流水线:发现(Discovery)→ 加载(Loading)→ 注册(Registration)→ 激活(Activation)。每个阶段职责明确,失败可精确定位,且都内置了安全检查。
发现:扫描与安全校验
插件发现由 discoverOpenClawPlugins 负责,按三个层级扫描:
stock(内置,extensions/目录)global(用户全局安装,~/.openclaw/extensions/)、workspace(项目级,<workspace>/.openclaw/extensions/),还支持额外的loadPaths。
发现过程并非简单的目录遍历。对每个候选插件,系统执行安全检查:checkSourceEscapesRoot 通过 realpathSync 检测符号链接逃逸;checkPathStatAndPermissions 拦截权限过宽(world-writable)或所有权可疑的文件。对内置目录,发现权限过宽时还会主动 chmod 收紧。
发现结果会被短时缓存(默认 1 秒),避免频繁文件系统扫描。成功的候选项被封装为 PluginCandidate,携带 idHint、source、origin 等元数据进入下一阶段。
加载:jiti 与惰性初始化
loadOpenClawPlugins 是加载阶段的编排者。它根据工作区路径、插件根目录和安装配置构建复合缓存 key,检查 LRU 缓存(上限 128 条)是否命中。命中时直接返回,重复加载几乎零成本。
缓存未命中时,加载器使用 jiti(Just-In-Time Import)作为动态模块加载器。jiti 能在运行时直接加载 .ts、.mts 等文件而无需预编译。OpenClaw 通过 buildPluginLoaderAliasMap 为 jiti 配置了 SDK 路径别名,确保插件中的 import ... from "openclaw/plugin-sdk/..." 能正确解析。
加载完成后,resolvePluginModuleExport 提取 register 函数或 OpenClawPluginDefinition 对象。插件既可以导出函数式注册器,也可以导出声明式定义对象,加载器统一处理。
注册:PluginRegistry 的内部构造
注册阶段的核心是 createPluginRegistry。它创建可变的注册表对象,同时返回 createApi 工厂方法。每个插件获得专属的 OpenClawPluginApi 实例,系统调用其 register(api) 函数完成注册。
OpenClawPluginApi 的每个注册方法都有严格的边界控制。registerTool 将工具包装在带 pluginId 的 factory 中,确保工具与来源插件关联;registerHook 检查钩子名称唯一性,重复注册触发诊断告警而非静默覆盖。
// PluginRegistry 的核心结构
type PluginRegistry = {
plugins: PluginRecord[]; // 所有已加载插件的元数据
tools: PluginToolRegistration[]; // Agent 可用工具
hooks: PluginHookRegistration[]; // 生命周期钩子
channels: PluginChannelRegistration[]; // 渠道插件
providers: PluginProviderRegistration[]; // LLM 提供商
gatewayHandlers: GatewayRequestHandlers; // 网关 RPC 方法
httpRoutes: PluginHttpRouteRegistration[];// HTTP 路由
services: PluginServiceRegistration[]; // 后台服务
// ...以及 speechProviders, webSearchProviders 等
};
注册表的全局运行时状态使用 Symbol.for("openclaw.pluginRegistryState") 在 globalThis 上维护。这种 Symbol-keyed 全局单例模式在 OpenClaw 中反复出现,它的优势在于模块被热重载时仍能通过相同的 Symbol key 访问同一状态对象,避免 ESM 热重载时引用丢失。
激活与加载模式
加载器支持两种模式:"full" 模式激活所有注册项;"setup-only" 模式只记录渠道的配置和 setup 信息。后者用于启动前的准备阶段——有些渠道需要先完成配置向导才能建立连接,此时不应激活完整的运行时。
严格的模块边界
OpenClaw 对插件的模块边界有严格约束:所有插件只能通过 openclaw/plugin-sdk/* 子路径引用核心功能,不允许直接 import src/ 下的内部模块,也不允许跨插件 import。这通过 jiti 的别名系统在加载时强制执行。
Plugin SDK(src/plugin-sdk/)提供了两个入口函数:definePluginEntry(非渠道插件)和 defineChannelPluginEntry(渠道插件)。以 Discord 为例:
// extensions/discord/index.ts
exportdefault defineChannelPluginEntry({
id: "discord",
plugin: discordPlugin,
setRuntime: setDiscordRuntime,
registerFull: registerDiscordSubagentHooks,
});
这种"声明式入口 + 运行时注入"的模式让插件开发者不需要关心加载、缓存等基础设施细节,只需按契约定义自己的能力。核心系统的重构也不会波及插件代码,只要 SDK 契约保持稳定。
第四章 渠道与消息路由——从用户到 Agent 的桥梁
上一章我们看到 Channel 插件如何注册到插件系统中。这一章深入渠道层内部,看一条用户消息如何从 Discord、Telegram 或 WhatsApp 的原生 API 流经标准化管道,最终被路由到正确的 Agent 会话。
ChannelPlugin:适配器的组合体
每个渠道插件的核心是 ChannelPlugin 接口。它的设计采用组合优于继承的思路——由大约 20 个可选适配器(Adapter)组合而成,每个适配器负责一个独立的能力维度:
type ChannelPlugin<ResolvedAccount> = {
id: ChannelId;
meta: ChannelMeta; // 显示名称、文档链接
capabilities: ChannelCapabilities; // 能力声明(支持图片?支持线程?)
config: ChannelConfigAdapter; // 账号配置管理
outbound?: ChannelOutboundAdapter; // 出站消息发送
security?: ChannelSecurityAdapter; // 安全策略(白名单)
gateway?: ChannelGatewayAdapter; // 生命周期(启动/停止)
threading?: ChannelThreadingAdapter; // 线程/话题支持
messaging?: ChannelMessagingAdapter; // 消息能力
heartbeat?: ChannelHeartbeatAdapter; // 心跳适配
agentTools?: ChannelAgentToolFactory;// 渠道专属工具
// ... 还有 pairing, groups, mentions, actions 等
};
这种设计让每个渠道可以按需"装配"能力。Telegram 支持线程和内联按钮,实现了 threading 和 actions;SMS 只支持纯文本,可能只实现 outbound 和 config;Slack 则几乎实现了所有适配器。
核心系统调用渠道能力时,总是先检查对应适配器是否存在,不存在则优雅降级。这种"可选接口"模式比抽象类继承灵活得多——能力组合是自由的,而非线性的层级结构。
入站消息流
当用户在某个通讯平台发送消息时,对应渠道插件的监听器捕获事件。以 Discord 为例,monitor.ts 监听 messageCreate 事件,将原始消息转换为标准化的 MsgContext:
Discord messageCreate → MsgContext {
Provider: "discord",
SessionKey: "...",
Body: "帮我分析这个项目",
From: { id, name },
To: { id, name },
...
}
标准化是渠道层最关键的职责。Telegram 用 chat.id 标识会话,Discord 用 channelId,WhatsApp 用 JID——经过适配器转换后,它们都变成统一的 MsgContext,后续处理逻辑对消息来源完全无感。
进入核心分发管道前,渠道层还执行若干前置检查。安全适配器通过白名单过滤未授权的发送者;群组消息需通过 mention gating 检查;入站去抖动合并用户短时间内的连续消息,避免多次 Agent 调用。
路由决策
标准化后的消息需要被路由到正确的 Agent 会话。OpenClaw 支持多 Agent 部署,不同渠道、不同账号可映射到不同的 Agent 工作区。路由层解析发送者 ID,根据配置确定目标 Agent ID 和 Session Key。
Session Key 是会话隔离的核心标识,格式通常为 agent:<agentId>:session:<sessionKey>,子 Agent 则是 agent:<agentId>:subagent:<uuid>。同一 Session Key 下的消息共享对话历史和上下文。
出站消息流
Agent 处理完消息后,回复需要被投递回用户所在的通讯平台。出站管道(src/infra/outbound/)同样是一条精心设计的流水线。

分块处理值得特别说明。不同渠道的消息长度限制不同(Telegram 4096 字符,Discord 2000 字符),Agent 的回复可能远超限制。ChannelHandler 根据渠道的 textChunkLimit 智能分块——优先在段落边界断开,避免在代码块或列表中间截断。
跨渠道路由
一个有趣的场景是跨渠道路由。当一条消息的来源渠道(OriginatingChannel)与当前处理渠道不同时——例如用户通过 WebChat 发起请求,但配置中指定回复应发送到 Telegram——dispatchReplyFromConfig 中的路由逻辑会检测这种情况:
const shouldRouteToOriginating = Boolean(
!isInternalWebchatTurn &&
routeReplyRuntime.isRoutableChannel(originatingChannel) &&
originatingTo &&
originatingChannel !== currentSurface,
);
当 shouldRouteToOriginating 为 true 时,回复会被转发到消息的原始来源渠道,而非当前正在处理的渠道。这种设计使得 OpenClaw 可以作为一个真正的"多入口、多出口"消息路由器运行。
第五章 消息分发管道——从 chat.send 到 Agent 响应
前两章分别介绍了 Gateway 的请求分发和渠道的消息标准化。这一章将把这两端串联起来,深入消息从进入系统到 Agent 产出回复的完整管道。
管道入口
无论消息来自哪个渠道,它们最终都汇入同一个入口:dispatchInboundMessage。这个函数做的事情很简单——对原始的 MsgContext 调用 finalizeInboundContext 进行最终的上下文标准化,然后委托给 dispatchReplyFromConfig。真正复杂的逻辑都在后者中。
dispatchReplyFromConfig:十二步管道
dispatchReplyFromConfig 是整个消息处理管道中最复杂的单一函数,接近 800 行代码。但它的结构是清晰的——一条由十二个步骤组成的线性管道,每个步骤都有明确的"继续/终止"语义:
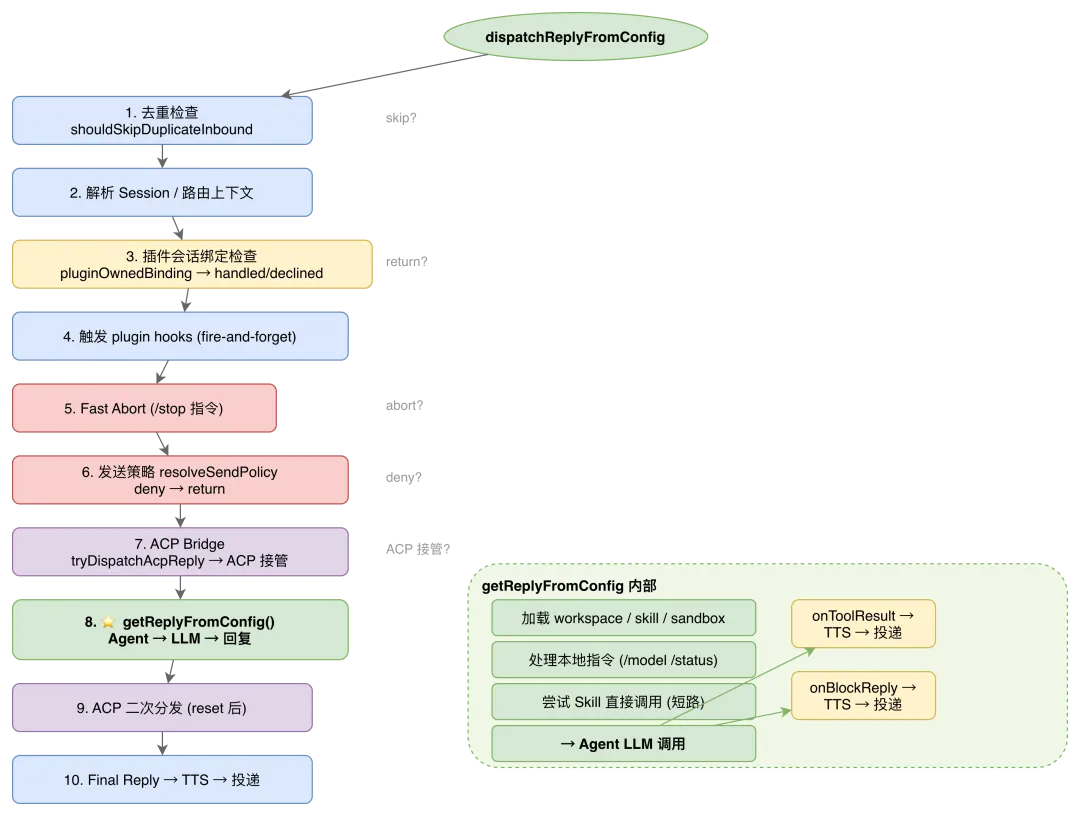
管道的前 7 步都是"守卫"角色:去重防止重复处理;插件会话绑定允许插件接管整个会话;Fast Abort 处理 /stop 指令中断 Agent 运行;发送策略决定是否允许回复;ACP Bridge 尝试将消息分发给外部 Agent 进程。
只有当所有守卫放行后,消息才到达第 8 步——真正的 Agent 调用。
getReplyFromConfig:从消息到 Agent
第 8 步是管道的核心。getReplyFromConfig 并不直接调用 LLM,而是先处理一系列前置工作:检查 workspace 和 skill 可用性,处理模型选择,解析本地指令(/model、/status 等不需要 AI 的命令直接返回结果)。
一个有趣的优化是 Skill 短路执行:如果用户消息匹配了 Skill 的触发条件且 Skill 配置了 command-dispatch: tool,系统可以直接调用工具而不经过 LLM,在意图明确的场景下(如 /commit)显著降低延迟和成本。
当前置步骤都未能直接处理消息时,请求被传给 Agent 运行时。此时 getReplyFromConfig 注册两个回调:onToolResult 将工具执行的中间结果实时投递给用户;onBlockReply 在 Agent 产出流式文本块时逐块投递。这种回调驱动的流式机制让用户无需等 Agent 完成所有推理就能看到回复。
惰性模块加载
管道中大量使用了惰性动态导入:loadRouteReplyRuntime()、loadGetReplyFromConfigRuntime() 等 runtime 模块只在首次使用时加载。消息分发的大部分代码路径在一次请求中只走其中一条,提前全部引入是浪费。这种模式在 OpenClaw 中很普遍,体现了对冷启动延迟的重视。
第六章 Agent 运行时——智能的核心引擎
消息终于来到了 OpenClaw 的心脏地带——Agent 运行时。这是代码量最大、逻辑最复杂的子系统,仅 run.ts(500+ 行)和 attempt.ts(2000+ 行)就承载了 Agent 单次执行的全部生命周期。
Agent 运行时基于 Pi Agent 框架,OpenClaw 在其上构建了重试、故障转移、上下文管理和多 Agent 协作机制。理解这个子系统需要把握三个核心概念:Run(完整的 Agent 执行)、Attempt(一次 LLM API 调用尝试)、Looper(工具调用与 follow-up 的循环模型)。
6.1 Agent Looper 模型
Agent 并非简单地"接收消息 → 调用 LLM → 返回回复"。现实中,一次用户请求可能需要多轮 LLM 交互:先调工具获取信息,根据结果决定是否调另一个工具,最后综合所有信息回复。OpenClaw 用双层循环模型来支撑这种交互。
外层循环处理 follow-up:Agent 完成一次 LLM 调用后,如果有追加消息需要注入(如 steering 消息或子 Agent 结果),触发新一轮 LLM 调用。内层循环处理 tool call:LLM 返回工具调用请求时,运行时执行工具、追加结果到上下文,再次请求 LLM。
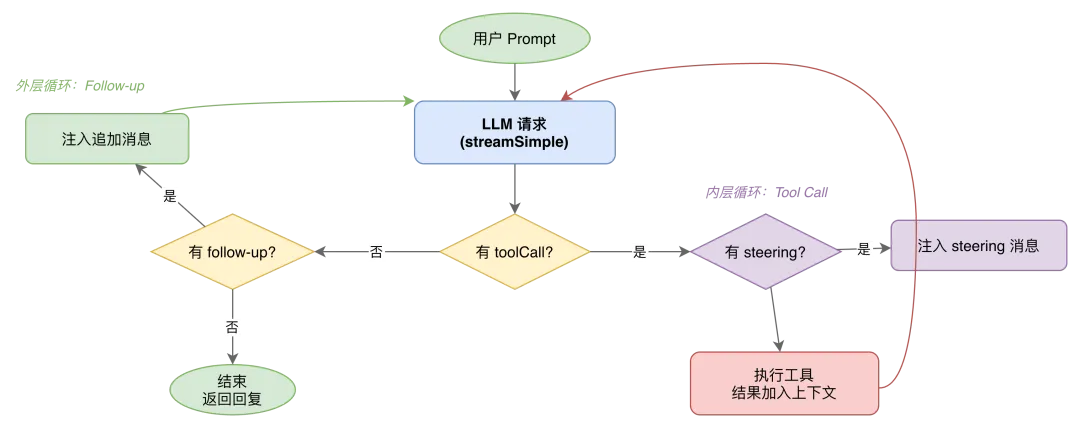
双层循环在 attempt.ts 中实现。内层循环中有一个 steering 注入点——当 Agent 返回 tool call 时,外部系统可在工具执行前注入指令消息来引导行为方向,实现对运行中 Agent 的外部干预。
6.2 Run 的重试与故障转移
runEmbeddedPiAgent 是 Agent 执行的最外层入口,其重试机制不是简单的"失败就重来",而是一套精细的故障转移策略。
首先是 Lane 队列机制。每次运行会被排入 session lane(会话级,串行执行)和 global lane(全局级,并发度控制)两个队列,平衡会话一致性和系统吞吐量。
然后是 Auth Profile 轮换。OpenClaw 允许为同一 LLM 提供商配置多个 API Key。当某个 Key 遭遇认证错误或速率限制时,自动切换到下一个。重试上限由配置的 profile 数量动态计算,钳制在 32 到 160 之间。
// 重试预算计算
const maxRetries = Math.min(
MAX_RUN_RETRY_ITERATIONS, // 160
Math.max(
MIN_RUN_RETRY_ITERATIONS, // 32
BASE_RUN_RETRY_ITERATIONS + // 24
profileCandidates.length * RUN_RETRY_ITERATIONS_PER_PROFILE // 8/profile
)
);
重试循环还处理多种特定错误:上下文溢出触发上下文压缩后重试;过载错误使用指数退避(初始 250ms,最大 1500ms);速率限制等待 Retry-After 时间;故障转移到备用 profile 时 thinking level 可能被降级。这种多层弹性设计使 Agent 在面对 LLM API 的各种不稳定因素时表现健壮。
6.3 系统提示词组装
系统提示词不是静态文本,而是由多达 25 个可选段落条件化拼装而成的动态文档,构建逻辑位于 system-prompt.ts 的 buildAgentSystemPrompt 中。
prompt 结构像一份"Agent 操作手册",从身份声明逐步递进到工具规范、安全约束、工作区信息、技能索引,最后以运行时元信息收尾。
身份声明是第一行——"You are a personal assistant running inside OpenClaw."——锚定 Agent 的角色认知。Tooling 段落列出所有可用工具,按预定义的 toolOrder 排序。Safety 段落设置反自治约束(禁止自我保护、复制、权力扩张)。
prompt 的动态性体现在大量条件分支上:Skills 段落仅在配置了 skillsPrompt 时出现;Memory 段落仅在有记忆工具时出现;Voice/TTS、Messaging 等各有独立激活条件。条件化组装避免了无关信息占用上下文窗口。
bootstrap 文件注入也值得关注。工作区中的 AGENTS.md、SOUL.md 等文件被嵌入到 prompt 中。当总量超过 bootstrapTotalMaxChars 限制时内容被裁剪,同时插入警告——告诉 Agent 上下文可能不完整,应主动读取原始文件。这种"不完整性自愈"让 Agent 在大型项目中也能正常工作。
最后一行 Runtime 标注将 Agent ID、主机名、模型名称等运行时信息编码为紧凑的键值对。prompt 还支持三种模式:"full" 用于主 Agent,"minimal" 用于子 Agent(只保留核心段落),"none" 只保留身份声明。
6.4 多 Agent 协作
OpenClaw 的多 Agent 架构实现了完整的父子协作机制,包含派生(spawn)、注册(registry)、控制(steer/abort)和协作式让出(yield)四个核心能力。
子 Agent 派生发生在父 Agent 调用 sessions_spawn 工具时。spawnSubagentDirect 处理整个流程:合法性验证(Agent ID 格式、派生深度限制、活跃数量上限——默认每个 Agent 最多 5 个并发子 Agent),创建独立会话,通过 Gateway RPC 启动子 Agent。
子 Agent 被注册到 subagent-registry.ts 的全局注册表中,每条记录跟踪完整的生命周期状态。注册表持久化到磁盘,确保 Gateway 重启后任务不丢失。
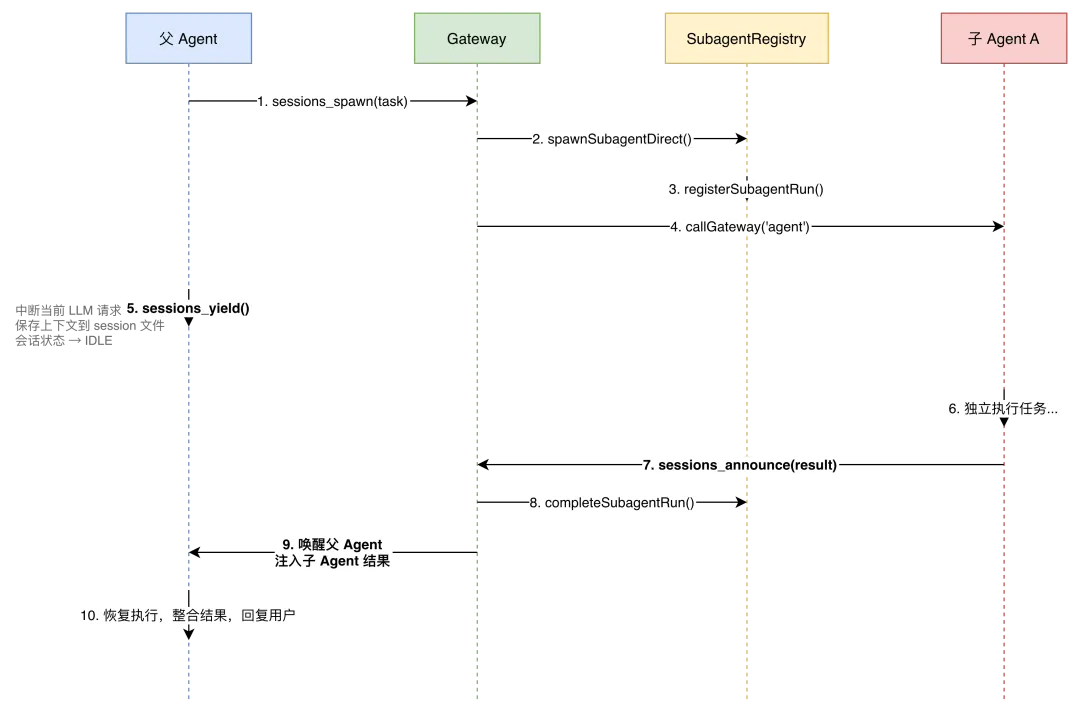
协作模型中最有特色的是 sessions_yield 机制。父 Agent 派生子 Agent 后可主动让出当前轮次,让出时执行四步:中断 LLM 请求、跳过未执行的工具调用、清理临时状态、持久化上下文到 session 文件。让出后会话进入 IDLE 状态,释放运行时资源。
恢复由外部事件触发。最常见的场景是子 Agent 完成后调用 sessions_announce 发送结果,Gateway 将结果投递到父 Agent 会话,恢复上下文继续执行。这种"协作式多任务"与操作系统中的协程思想一脉相承——切换由 Agent 自己决定,避免了抢占式调度带来的状态管理复杂性。
注册表还内置了完善的生命周期管理:超时检测、孤儿回收、带退避重试的 announce 投递(初始 1 秒、最大 8 秒),以及 60 秒间隔的 sweeper 清扫已归档记录。
第七章 Skill 系统——Agent 的专业知识库
在上一章中,我们看到系统提示词的构建过程中会注入一个 <available_skills> 索引。Skill 系统正是负责构建这个索引的模块——它为 Agent 提供了一套结构化的专业知识检索机制。
与工具(Tool)不同,Skill 本质上是一份 Markdown 文档(SKILL.md),描述特定任务的最佳实践或领域知识。Agent 根据 system prompt 中的索引判断是否需要某个 Skill,通过文件读取获取完整内容并遵循指引。
这种设计将"知识"和"能力"分离:Tool 是 Agent 的手,Skill 是 Agent 的参考手册。
发现与优先级
Skill 的发现由 resolveWorkspaceSkillPromptState(位于 src/agents/skills/workspace.ts)驱动,它会从六个来源按优先级从低到高依次扫描:
extra/plugin dirs < bundled < managed (~/.openclaw/skills)
< agents-personal (~/.agents/skills) < agents-project (<workspace>/.agents/skills)
< workspace (<workspace>/skills)
优先级链的设计意图很明确:越靠近工作区的 Skill 优先级越高。项目自带的 Skill 可以覆盖全局同名 Skill,全局又可覆盖内置。这种"就近覆盖"策略类似 npm 的 node_modules 解析顺序,让用户无需修改全局配置就能为特定项目定制 Agent 行为。
发现过程中有多重安全检查:路径遏制检查通过 realpathSync 确保 SKILL.md 没有符号链接逃出;文件大小上限(256KB)防止异常大文件;候选数量上限(每源 300 个、最多加载 200 个)防止性能退化。
索引注入
发现和过滤后的 Skill 条目被组装成 XML 格式的索引,注入到 system prompt 的 Skills 段落中:
<available_skills>
<skill>
<name>checks</name>
<description>Run checks before landing changes.</description>
<location>/skills/checks/SKILL.md</location>
</skill>
<!-- ... -->
</available_skills>
索引大小有预算控制。applySkillsPromptLimits 实现两级降级:先尝试完整格式(name、description、location);超出预算(默认 30,000 字符)则降到紧凑格式(只保留 name 和 location);仍超出则通过二分搜索找到预算内能容纳的最大子集。路径也会被压缩——$HOME/... 替换为 ~/...。
前置元数据与资格校验
每个 SKILL.md 可包含 YAML 前置元数据,声明运行要求。frontmatter.ts 解析操作系统限制(os)、必需的二进制文件(requires.bins)、环境变量(requires.env)和安装指令等信息。
shouldIncludeSkill 根据元数据和当前环境做资格校验:Skill 声明只在 macOS 可用而系统是 Linux,则被排除;要求 ffmpeg 但未安装,同样排除。基于声明式元数据的过滤让 Skill 的跨平台分发很自然——同一份集合部署到不同环境,系统自动选择适用子集。
Skill 短路执行
部分 Skill 可通过 command-dispatch: tool 声明短路执行:用户消息匹配触发条件时直接调用工具,省去 LLM 推理。buildWorkspaceSkillCommandSpecs 构建斜杠命令规格,包括名称规范化(最长 32 字符)、描述截断和去重。
第八章 上下文引擎——有限窗口下的信息博弈
Agent 运行时面临的最大工程挑战之一,是在有限的上下文窗口中保持最大的信息密度。复杂对话可能涉及数十轮交互、每轮多个工具调用,累积起来很容易超出 context window 限制。
OpenClaw 的上下文引擎不是单一的截断逻辑,而是一套多层级的渐进式上下文管理策略。
8.1 转录策略:格式适配的第一道工序
对话历史送入 LLM 前必须经过格式适配。不同提供商有不同要求:OpenAI 接受 function_call_output,Anthropic 使用 tool_result,Gemini 要求严格的 turn 交替。TranscriptPolicy 定义格式化规则,resolveTranscriptPolicy 根据当前模型返回策略。
格式化分四个有序阶段:
第一阶段 Sanitize(清洗),移除目标提供商不支持的内容。例如 dropThinkingBlocks 在签名不可重现时移除 Anthropic 的 thinking block。
第二阶段 Validate(校验),确保消息角色交替符合要求。连续的同角色消息会被合并,Gemini 尤其严格,需要时插入占位消息。
第三阶段 Limit(截断),根据 limitHistoryTurns 只保留最近 N 轮消息。截断在消息边界进行,但可能导致 tool call 被截掉而对应 tool result 留下。
第四阶段 Repair(修复)解决这个问题。sanitizeToolUseResultPairing 扫描所有 tool result,找不到对应 tool call 的孤立结果会被移除。四个阶段严格有序,每阶段的输出是下阶段的输入,复杂性被分解到可管理的单元中。
8.2 上下文裁剪的双保险机制
格式化流水线之外,上下文的绝对大小仍需主动管理。OpenClaw 设计了两套互补机制。
Tool Result Context Guard 是"逢调必触"的防线。installToolResultContextGuard 通过 monkey-patch agent.transformContext,在每次 LLM 调用前执行三重预算检查。
第一重:单个 tool result 不得占用超过上下文窗口的 50%,超出部分被截断(优先在换行符处断开)。第二重:总量超过窗口的 75% 时,从最旧的 tool result 开始逐个替换为占位符。第三重:经前两步后仍超过 90%,抛出预防性溢出异常,触发完整的会话压缩。
Context Pruning 是"间歇触发"的渐进清理机制。它作为 pi-coding-agent 扩展注册了 "context" 事件处理器,默认 5 分钟冷却期内只执行一次。
裁剪分两阶段。软裁剪在上下文占比超 30% 时触发:超过 4000 字符的 tool result,保留头部和尾部各 1500 字符,中间用 "..." 替代——工具输出的开头通常有关键元信息,结尾有结论,中间往往是冗余细节。
硬裁剪在占比超 50% 且可裁剪内容超过 50,000 字符时触发,更激进地替换整个 tool result。
两者的互补关系值得体会:Context Guard 无条件兜底、策略激进;Context Pruning 有冷却期、策略精细,通过 allow/deny glob 保护特定工具输出。组合起来既有常态维护,又有极端兜底。
为什么总是优先裁剪 tool result?因为它们是上下文膨胀的主要来源(一次 cat 可能返回数千行),且信息密度相对较低——LLM 已从中提取关键信息用于后续推理,替换为占位符通常不影响理解。
8.3 上下文溢出的降级策略
当裁剪仍无法控制上下文大小,LLM API 返回 contextOverflowError。run.ts 的重试循环会启动分级恢复:
检测到 contextOverflowError
├─ 策略1: 已有内部压缩 → 直接重试
├─ 策略2: 显式压缩(contextEngine.compact)→ 生成摘要替换旧消息
├─ 策略3: 截断超大 tool result
└─ 所有策略失败 → 返回错误给用户
策略 2 的 compact 是重量级操作,本身需要调用 LLM 生成摘要,涉及 session 文件锁定和 transcript 重写。compact.ts 近 1500 行代码,因为摘要生成本身就是一次 Agent 运行。
Context Engine 的插件化架构
上下文管理的整体架构是可插拔的。ContextEngine 接口定义了 bootstrap、maintain、compact 等生命周期方法,默认实现 LegacyContextEngine 基本上是 pass-through。
外部引擎可通过 api.registerContextEngine(id, factory) 注册,在配置中通过 plugins.slots.contextEngine 指定使用。注册表使用 Symbol.for("openclaw.contextEngineRegistryState") 存储——又一个 Symbol-keyed 全局单例。
第九章 记忆系统——跨会话的知识持久化
上下文引擎解决单次会话内的信息管理,记忆系统则解决更大的挑战:跨会话的长期记忆。
OpenClaw 的记忆建立在简洁的理念上:记忆存储在 Markdown 文件中。用户在工作区维护 MEMORY.md 和 memory/ 目录,系统负责索引,Agent 通过 memory_search 和 memory_get 工具检索。
分块与向量化
chunkMarkdown 按配置的 token 预算和重叠量将文件切分为多个 chunk。算法按行遍历,累积到 maxChars 上限后刷新为一个 chunk,超长行会被预先按上限切分。
分块的精巧之处在于上下文衔接:每次刷新时保留尾部一部分行作为下一个 chunk 的开头,保留量由 overlapChars 控制。这种滑动窗口式分块确保相邻 chunk 有内容重叠,避免 chunk 边界处的信息被遗漏。
每个 chunk 被封装为 MemoryChunk,包含行号范围、文本、SHA-256 哈希(用于增量更新的变化检测)和嵌入向量。
存储结构
索引数据存储在 SQLite 中,由 MemoryIndexManager 管理,包含五张核心表。
meta 存储元数据键值对。files 记录已索引文件路径。chunks_vec 是向量表,存储分块和嵌入向量用于语义搜索。embedding_cache 缓存已计算的嵌入向量,避免对未修改文本重复调用 API——这是重要的成本优化。chunks_fts 是 FTS 全文检索表。
嵌入向量计算支持多个提供商(OpenAI、Gemini、Voyage 等),支持回退链,主提供商不可用时自动尝试备用。
三种检索模式
Agent 通过 memory_search 触发检索,根据配置走三条路径。
没有嵌入提供商时,降级到纯 FTS 检索——从查询中提取关键字在 chunks_fts上搜索。效果有限,但确保无嵌入 API 时仍有基本检索能力。配置了嵌入提供商时,可用向量检索——查询转为嵌入向量,在 chunks_vec中做余弦相似度搜索。最理想的是混合检索:BM25 关键字评分和向量相似度评分通过 MMR(最大边际相关性)算法融合,兼顾时间衰减。MMR 在结果的相关性和多样性之间取平衡,避免返回语义相似但实质重复的 chunk。
memory_get 则更直接——通过文件路径获取内容,不经过检索。
降级与边界
嵌入提供商未配置时,系统无法建立向量索引,Agent 只能通过 memory_get 指定路径获取记忆。这种降级是有意为之——记忆系统不应成为硬性依赖,条件允许时提供增强检索,不满足时优雅降级。
管理器实例使用 Symbol.for("openclaw.memoryIndexManagerCache") 在全局缓存,每个 agent/workspace 组合对应一个。文件变化通过 chokidar 监控,触发增量同步,通过 SHA-256 哈希跳过未变化的 chunk。
第十章 安全机制——设备验证与信任建立
在前面的章节中,我们多次提到 Gateway 在接受 WebSocket 连接时会进行身份认证。这一章将完整展开 OpenClaw 的设备安全体系——一套基于 Ed25519 非对称加密的设备认证与配对协议。
自托管场景的安全挑战与云服务截然不同。没有中心化的账号体系和 TLS 证书链,OpenClaw 采用"先验证身份、再建立信任"的两阶段安全模型。
设备身份的生成与管理
每个客户端首次启动时生成持久的设备身份。loadOrCreateDeviceIdentity 检查 device.json 是否存在,不存在则生成 Ed25519 密钥对。
设备 ID 从公钥确定性推导——取 SPKI 编码中的原始 32 字节公钥数据的 SHA-256 哈希。这确保了设备 ID 与密钥对的一一对应:任何持有公钥的一方都可独立计算设备 ID 来验证声称。
身份文件权限设为 0o600。加载时还有自愈机制:如果存储的 deviceId 与从公钥重新推导的值不一致,以推导值为准覆盖。
连接认证流程
WebSocket 连接建立后,Gateway 发送 connect.challenge(含随机 nonce)。nonce 是一次性的,防止重放攻击。
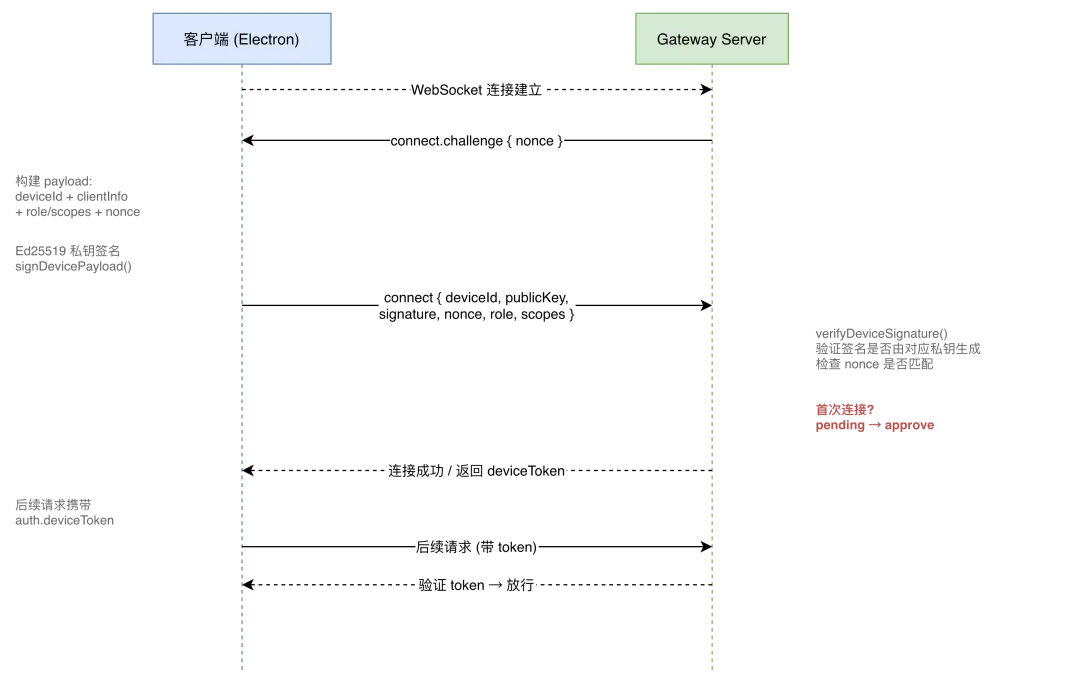
客户端收到 challenge 后,构建 payload(含 deviceId、客户端信息、角色、权限范围和 nonce),用 Ed25519 私钥签名,连同公钥一起发送给 Gateway。
Gateway 调用 verifyDeviceSignature 验证:用公钥验签确认 payload 由对应私钥生成,同时检查 nonce 匹配。通过后进入配对流程。
静默配对
首次连接的设备需要经过配对(pairing)才能被授权。配对请求(DevicePairingPendingRequest)有 5 分钟的 TTL,超时未被处理将自动过期。
OpenClaw 支持"静默配对"——特定条件下自动批准首次连接的设备。关键约束是必须是本机连接(isLocalClient),且不带浏览器 Origin header(除非是管理界面或 WebChat)。
浏览器 Origin header 意味着请求可能来自网页,可能被恶意脚本控制。只有 Electron 的 Node 进程建立的 WebSocket(不带 Origin header)才被视为可信本地连接。
配对成功后返回 deviceToken,后续请求携带 token 即可,无需每次签名。token 无过期时间——在自托管场景下合理,用户完全控制 Gateway 实例。
三种客户端类型的安全策略差异
OpenClaw 对三种客户端类型实施不同的安全策略。
gateway-client 运行在 Electron Node 进程中,不带 Origin header,必须通过完整的设备身份验证。webchat-ui 同样运行在 Node 中,安全要求稍低。openclaw-control-ui 运行在浏览器中,无法安全地生成和存储密钥对,当 allowInsecureAuth 为 true 时可跳过设备校验。
这三级策略体现了"根据威胁模型定制安全措施"的原则。Node 进程有完整的密码学能力,可承受严格验证;浏览器受限于 Web 安全沙箱,但 localhost 访问本身提供了物理安全保障。
第十一章 心跳与定时任务——自动化的脉搏
前面的章节覆盖了用户主动请求的完整链路。但 Agent 的价值不止于应答——心跳和定时任务让 Agent 能主动执行周期性工作,成为真正的"自主代理"。
心跳:用户定义的周期性巡检
心跳的核心理念是让用户通过 HEARTBEAT.md 定义周期性任务。文件内容作为 prompt 发送给 Agent,回复投递到指定渠道。典型用法包括邮件监控、系统巡检和日报生成。
调度模型是 per-agent 的。startHeartbeatRunner 为每个配置了心跳的 Agent 创建独立的 HeartbeatAgentState,记录间隔时间(默认 30 分钟)、上次执行时间和下次到期时间。调度器使用"最近任务优先"算法:扫描所有 Agent 的到期时间,选最近的设置 setTimeout。
定时器到期
↓
requestHeartbeatNow({ reason: "interval" })
↓
heartbeat-wake handler: schedule() 触发
↓
run() 遍历到期的 targetAgent
↓
runHeartbeatOnce() → 单次心跳执行
↓
advanceAgentSchedule() → 更新下次到期时间
↓
scheduleNext() → 设置下一个最近的定时器
单次心跳执行(runHeartbeatOnce)远比表面看起来复杂。LLM 调用前有一系列门控:心跳开关、间隔有效性、活跃时间段、消息队列是否为空(不为空说明有用户请求,心跳应让路)。
通过门控后读取并解析 HEARTBEAT.md,配置了隔离模式时创建独立会话,避免心跳信息污染正式对话。
心跳 prompt 不仅是 HEARTBEAT.md 的内容,还会拼装待处理的 exec 完成事件和 cron 通知,让 Agent 每次心跳时也能处理积压的异步事件。
回复投递有多层过滤:空回复或 HEARTBEAT_OK 被视为正常无事;与上次相同的回复被静默忽略;找不到投递目标也静默丢弃。只有真正有价值的新信息才会到达用户。投递后还会裁剪心跳会话 transcript,移除无实质内容的轮次。
Cron:精确的定时任务
Cron 是更精确的定时任务系统,支持三种调度:at(一次性)、every(固定间隔)、cron(Cron 表达式,如"每周一上午 9 点")。
CronService 是薄包装,状态管理和操作逻辑委托给内部状态对象。任务持久化为 JSON 文件,序列化时剥离运行时字段避免不必要的配置备份。
底层使用 setTimeout 而非系统 crontab——这是合理的决策。OpenClaw 的 Cron 任务是动态管理的,执行需要调用 Agent 运行时等进程内资源,用系统 crontab 需要跨进程通信,增加复杂度却无实际收益。对于"每 30 分钟检查邮件"这类场景,setTimeout 的精度绰绰有余。
每个任务的 payload 可以是 systemEvent 或 agentTurn(完整的 Agent 轮次)。结果通过 "announce" 投递到渠道或 "webhook" POST 到外部端点。会话目标支持 "main"、"isolated"、"current" 和指定 session key 四种模式。
第十二章 设计哲学与工程实践总结
走过前面十一个章节,我们覆盖了 OpenClaw 的全部核心子系统。这一章从具体实现中提炼贯穿整个项目的设计哲学。
单一控制面的取舍。单进程、单 Gateway 的架构与产品定位高度吻合——自托管场景下部署和运维的简单性远比水平扩展重要。Lane 队列实现并发控制,session 文件持久化实现重启恢复。这不是"偷懒",而是对目标场景的深刻理解。
插件优先的可扩展性。核心运行时只定义契约,具体能力都以插件形式存在。严格的 SDK 边界、Symbol-keyed 全局单例、两阶段加载模式、发现阶段的安全检查——这些共同构成生产级的插件运行时。
流式优先的响应管道。从 onToolResult/onBlockReply 回调到出站分块处理再到 TTS 合成,整个系统以"流式"为默认假设。Agent 回复随推理进行逐块投递,用户不会面对漫长的空白等待。
防御性的安全设计。安全渗透在每一层:插件发现的路径逃逸检测、Gateway 的 nonce-challenge、Skill 的路径遏制、子 Agent 的深度限制、system prompt 的反自治约束。每层都假设外部输入不可信。
协作式多任务。sessions_yield/sessions_announce 没有采用抢占式调度,而是协作式让出-恢复模型。保持并发效率的同时大幅简化状态管理。
渐进式的上下文管理。在信息保持、成本控制和窗口限制三个矛盾目标间取平衡。常态下温和裁剪,每次调用时预算检查,溢出时摘要压缩——分层渐进。
声明式的能力发现。插件 manifest、Skill frontmatter、渠道 capabilities 声明——广泛使用声明式元数据描述能力和需求,运行时按环境过滤匹配。
从工程实践角度,几个反复出现的模式值得提炼:Symbol-keyed 全局单例保持热重载时的状态连续性;惰性动态导入控制冷启动的模块加载量;LRU 缓存广泛用于插件注册表、Cron 解析和发现结果;钩子系统提供标准化的生命周期扩展点;Lane 队列在多个场景下提供统一的并发控制原语。
这些模式并非刻意套用,而是在解决真实工程问题中自然演化出来的——各子系统面临相似的底层挑战:单进程中的状态共享、启动性能与可选模块的平衡、可扩展性与运行时复杂度的控制。
第十三章 OpenClaw 对 Agent 系统设计的启示
前面十二章完整拆解了 OpenClaw 的架构与实现。这一章换一个视角:如果你正在设计或构建一个 Agent 系统,OpenClaw 的哪些经验值得借鉴?
关于架构选型:单体未必是退步
微服务在 Agent 系统领域几乎成了默认选择。但 OpenClaw 用它的实践证明,在自托管和小团队场景下,单进程架构可能是更优的起点。
核心原因在于 Agent 系统的状态密集性。一次 Agent 执行涉及对话历史、工具状态、子 Agent 注册表等大量运行时上下文,这些状态在分布式架构下需要复杂的同步机制。OpenClaw 的 Gateway 将所有状态集中管理,通过 Lane 队列在进程内解决并发,session 文件实现持久化——架构简洁,运维成本极低。
这不意味着单体是唯一选择,而是提醒我们:在追求"先进架构"之前,先认清自己的场景。如果你的 Agent 系统不需要处理数万并发用户,单进程加上精心设计的持久化可能比 Kubernetes 集群更合适。
关于可扩展性:插件化是值得的投入
OpenClaw 超过 80 个插件覆盖了 LLM 提供商、通讯渠道和功能增强三大维度。这种可扩展性不是凭空而来——它建立在严格的模块边界之上。
值得学习的是 OpenClaw 如何平衡"开放"与"隔离"。jiti 加载器 + SDK 路径别名确保插件只能访问公开 API;Symbol-keyed 全局单例解决了热重载时的状态丢失问题;两阶段加载(setup-only vs full)避免了配置未就绪时的启动失败。
如果你的 Agent 系统需要接入多种 LLM 或多种外部服务,在早期就定义清晰的插件接口和 SDK 边界,后期的扩展成本会大幅降低。
关于上下文管理:没有银弹,只有分层策略
上下文窗口管理可能是 Agent 系统中最容易被低估的工程挑战。很多系统简单地"截断最旧的消息"就了事,但实际使用中这很快会导致 Agent "遗忘"关键上下文。
OpenClaw 给出的答案是多层渐进策略。这个思路可以被抽象为三条原则:
第一,区分内容类型的信息密度。tool result 是上下文膨胀的主要来源但信息密度低,优先裁剪它们而非对话消息,这个决策背后的逻辑普适于所有 Agent 系统。
第二,裁剪力度应该渐进。从保留首尾的软裁剪,到替换整块内容的硬裁剪,再到调用 LLM 生成摘要的压缩,每一级的成本和信息损失递增。常态下用最温和的策略,紧急时才动用重量级手段。
第三,防御要前置。不要等 API 报错了再处理溢出——Context Guard 在每次调用前做预算检查,比事后补救高效得多。
关于多 Agent 协作:协作式优于抢占式
当你需要让多个 Agent 协同工作时,sessions_yield/sessions_announce 模式值得认真研究。
抢占式调度在 OS 内核中是成熟方案,但在 Agent 场景下会引入巨大的状态管理复杂性——Agent 可能正在执行工具调用、等待 LLM 响应、或者处理中间结果,被抢占时的状态保存和恢复极其困难。
协作式让出完美绕过了这个问题。父 Agent 在自己选择的安全点(通常是工具调用返回后)让出,状态被完整持久化;子 Agent 完成后通过 announce 触发恢复。整个过程只有两个明确的状态——"运行中"和"IDLE"——不存在中间态。
如果你正在构建多 Agent 编排系统,这种"由 Agent 自己决定何时让出"的模型可以省去大量的状态管理代码。
关于安全性:按威胁模型分级
很多开发者在安全设计上走向两个极端:要么忽视安全,要么过度设计。OpenClaw 的三级客户端安全策略(Node 进程严格验证、WebChat 适度放宽、浏览器管理界面依赖物理安全)是一个很好的折中范例。
核心思路是:根据威胁模型定制安全措施。在本地场景下,localhost 连接的物理安全保障是一层隐含的防线。在这层防线之上,Ed25519 设备身份提供密码学层面的身份绑定,nonce-challenge 防止重放攻击。每一层安全措施都有明确的威胁对象,不做多余的安全性投入,也不遗漏关键的攻击面。
对于自托管的 Agent 系统,这种分级安全设计比"一刀切"的认证方案更实际。
关于用户体验:流式和主动性
两个小的设计决策对用户体验影响很大。
一是流式投递。Agent 的推理过程可能需要数十秒甚至几分钟,如果用户在这期间只看到一个 loading 状态,体验极差。OpenClaw 的 onBlockReply + 出站分块机制让用户实时看到 Agent 的思考进展,这在所有面向用户的 Agent 系统中都值得实现。
二是心跳机制。让 Agent 从"被动应答"进化为"主动巡检"——定期检查邮件、监控系统状态、生成日报——这个功能看似简单,但极大拓展了 Agent 的价值边界。HEARTBEAT.md 用一个 Markdown 文件就定义了周期性任务,是 Agent 自主性的优雅实现。
可直接复用的设计模式
最后梳理几个可在其他 Agent 项目中直接借鉴的设计模式。
Symbol-keyed 全局单例:如果你的系统需要支持模块热重载,用 Symbol.for() 代替模块级变量来存储全局状态,可以避免重载时的引用丢失。
惰性动态导入:Agent 系统通常有大量可选功能路径,用 async import() 延迟加载非关键路径模块,可以显著优化冷启动时间。
Lane 队列:在需要对某类操作做并发控制时(如同一会话的 Agent 运行必须串行),Lane 队列是比 mutex 更直观的抽象。
Sanitize-Validate-Limit-Repair 流水线:处理不可控的外部数据时,将清洗、校验、限制、修复拆成有序阶段,每阶段只关注一个维度,比一个大函数更容易维护和调试。
声明式能力发现:让组件通过元数据(frontmatter、manifest)声明自己的能力和需求,运行时自动匹配过滤。这比硬编码 if-else 更灵活,也更适合需要跨平台运行的系统。
OpenClaw 作为一个开源的 Agent 网关项目,其价值不仅在于它能用来做什么,更在于它展示了一种经过生产环境验证的 Agent 系统设计思路。从单一控制面的架构简洁性,到插件化的扩展能力,再到渐进式的上下文管理,它提供了一套完整的、相互支撑的工程方案,值得每一个 Agent 系统的设计者和开发者参考。
