夜雨聆风
夜雨聆风关于 Openclaw 记忆,你只需要看这一篇。
不讲论文,不甩术语。看完这篇,你会比 90% 的人更懂 AI 是怎么记事的。
我拿OpenClaw 开刀,带你看看工程师们是怎么一步步给 AI 治健忘的
从最粗暴的方案,到目前最前沿的思路。
先搞清楚一个基本问题:AI 的脑子长什么样。
你跟 ChatGPT、Claude 这些 AI 聊天的时候,可能以为它跟人一样,聊过的事情自然就记住了。
其实不是的。
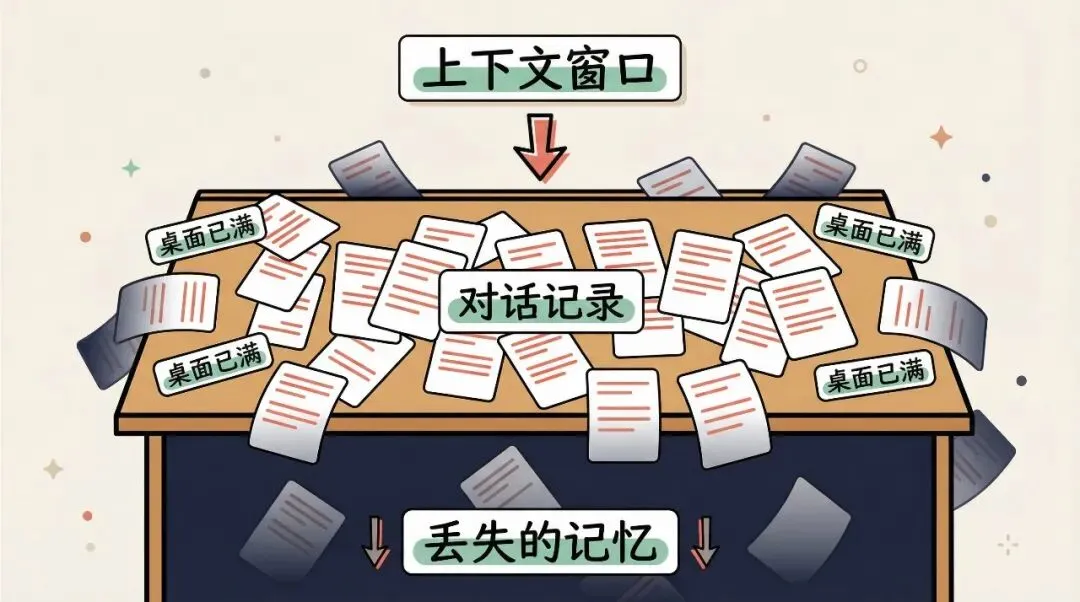
AI 的大脑不是硬盘,是一张书桌。书桌大小固定,你跟它说的每一句话、它回的每一句话,都是摊在桌上的纸。桌面满了,新的纸就放不下了。
这张书桌,技术上叫上下文窗口。
现在的大模型,桌子不算小,Claude 的桌子大概能摊开一整本《哈利波特》。听起来挺大?但问题是:你们聊的每一句话本身也在占桌面。聊得越久,桌上的对话记录越厚,留给真正干活的空间就越少。
更要命的是,AI 没有抽屉。人类可以把暂时不用的东西收进抽屉,需要时再翻出来。但对 AI 来说,不在桌上的东西就是不存在的。
桌面放满了,旧的东西就得被推下去,掉进虚空。
这不是 AI 笨,是架构的限制。就像你的浏览器,一屏就这么大,往下滚,上面的内容就看不见了。区别是,你还能往回翻,AI 不能。滚出去的内容,对它来说就是不存在的。
那桌面满了怎么办?最直觉的想法是,把旧的纸揉一揉、压一压,腾出空间。
OpenClaw 最早的方案,就是这么干的。
方案一:把旧笔记揉成纸团
OpenClaw 是一个开源的 AI 编程助手平台,你可以把它理解成一个 AI 程序员管理系统。
它最初处理记忆的方式很简单粗暴:
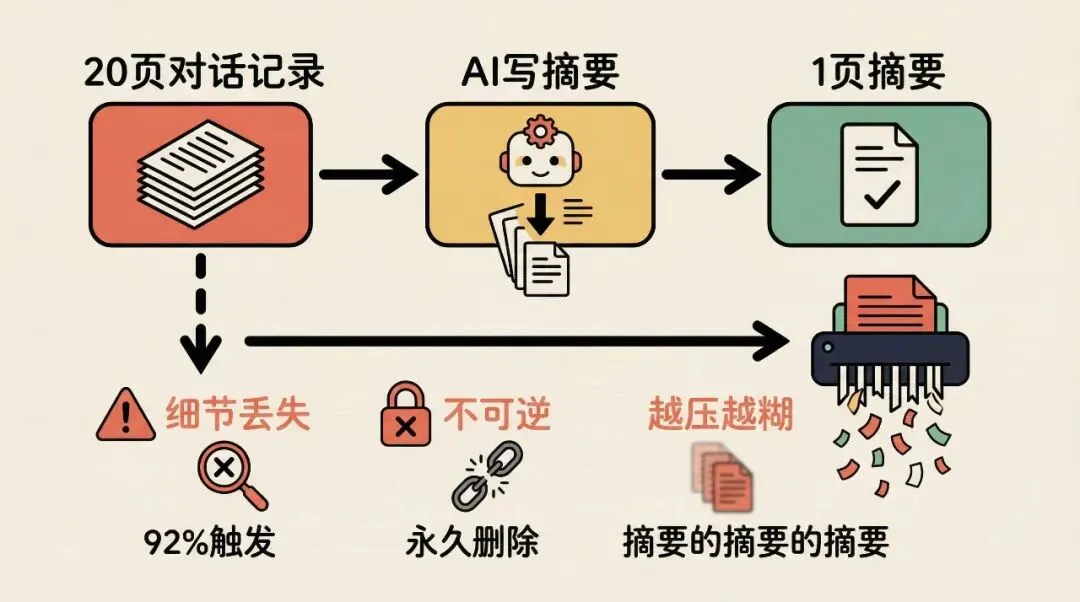
当对话占满桌面的 92%,系统自动触发压缩。保留最近 3 轮对话,前面所有内容打包送给另一个 AI 写摘要。摘要写完,贴回桌面。
原来的对话呢?永久删除。找不回来了。
就像你的桌子快满了,你把前面 20 页笔记让同事帮你写了一页摘要,然后把那 20 页扔进碎纸机。桌面是清爽了,但下次你想回忆当时那个参数具体是多少来着,对不起,碎纸机里找不回来。
这个方案有三个问题:
第一,摘要会丢细节。 你告诉 AI 这个变量名后来改了,20 轮之后这条信息被压缩掉了,AI 又用回旧名字。
第二,不可逆。 原始对话永久丢失,想查当时为什么选了方案 A,查不到。
第三,越压越糊。 如果压缩触发了多次,就是摘要的摘要的摘要,信息像复印件反复复印,越来越看不清。
能用,但每压缩一次就丢一次。聊得越久,丢得越多。
那有没有办法,压缩,但不丢东西?
方案二:建一个分层档案馆
OpenClaw 社区里一个很强的团队做了第二代方案,叫 Lossless Cloud。核心承诺是无损,原始消息永远保留,一条都不删。
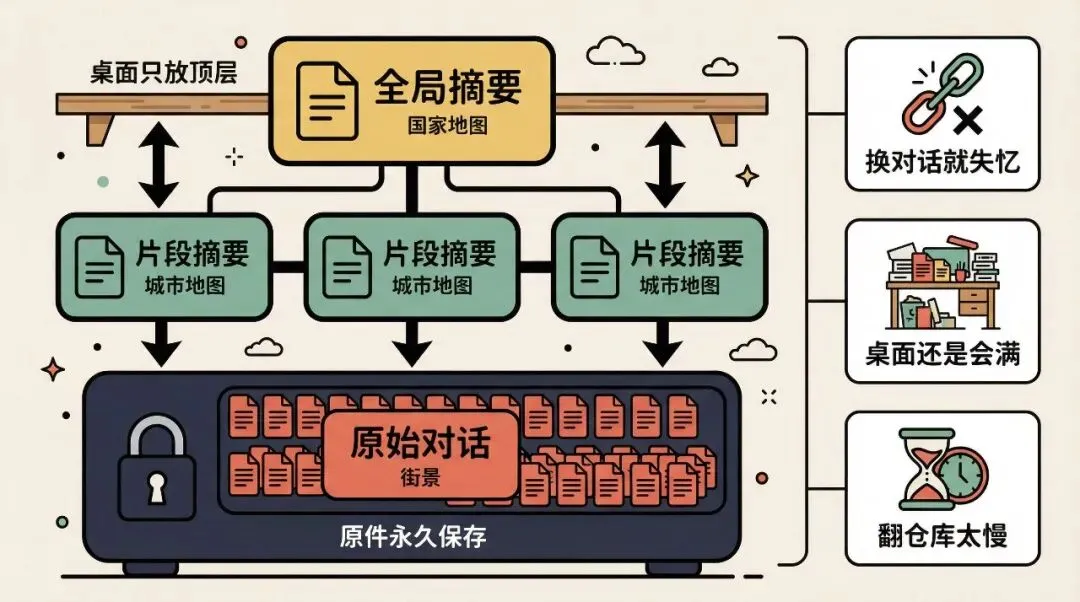
它的思路很巧妙。不删原件,搞一套缩略图系统。
想象 Google Earth。你不会把全球每一寸街景同时加载出来。你看的是:地球全景 → 放大看国家 → 放大看城市 → 拉到街景。
Lossless Cloud 做的就是这件事:
- 底层(街景):每一句原始对话,一字不差,永远存在本地数据库里
- 中层(城市地图):相关对话的片段摘要
- 顶层(国家地图):整个对话的全局摘要
桌面上只放最顶层那页摘要。需要细节?往下翻就行,原件一直都在。
比方案一好多了。至少不丢东西了。
但深入用下来,三个问题浮出来了:
第一,换个对话窗口就失忆。 这套档案馆只服务一次对话。你关掉窗口开一个新的,AI 又是一张白纸。上个项目踩过的坑,这个项目还得再踩一遍。
第二,桌面还是会满。 虽然原件进了仓库,但摘要本身也占空间。对话越长,摘要越厚。就像你的书越来越多,光目录就占了半张桌子。
第三,翻仓库太慢。 想找一条具体的原始记录,得从顶层一级级展开,过程需要反复调用 AI,你可能要干等两分钟才能拿到结果。
它确实做到了不忘。但你需要它记起来的时候,它翻得太慢了。而且每次开新对话,等于住进了一间新的空房子。
到这里,一个更根本的问题冒出来了:
这两个方案都在想同一件事,怎么把越来越多的东西塞进一张有限的桌子。一个是扔掉,一个是压缩。
但有没有可能,思路本身就错了?
方案三:别往桌上堆了,按需取就好
这就是 MemOS 的思路。我自己一直在用的方案,也是我目前见过在 Agent 记忆这件事上做得最完整的方案。它是 OpenClaw 的一个插件,开源免费,100% 本地运行,所有数据都在你自己电脑上,零上传网络。
MemOS 不再纠结怎么压缩,它问了一个完全不同的问题:为什么所有东西都得放桌上?
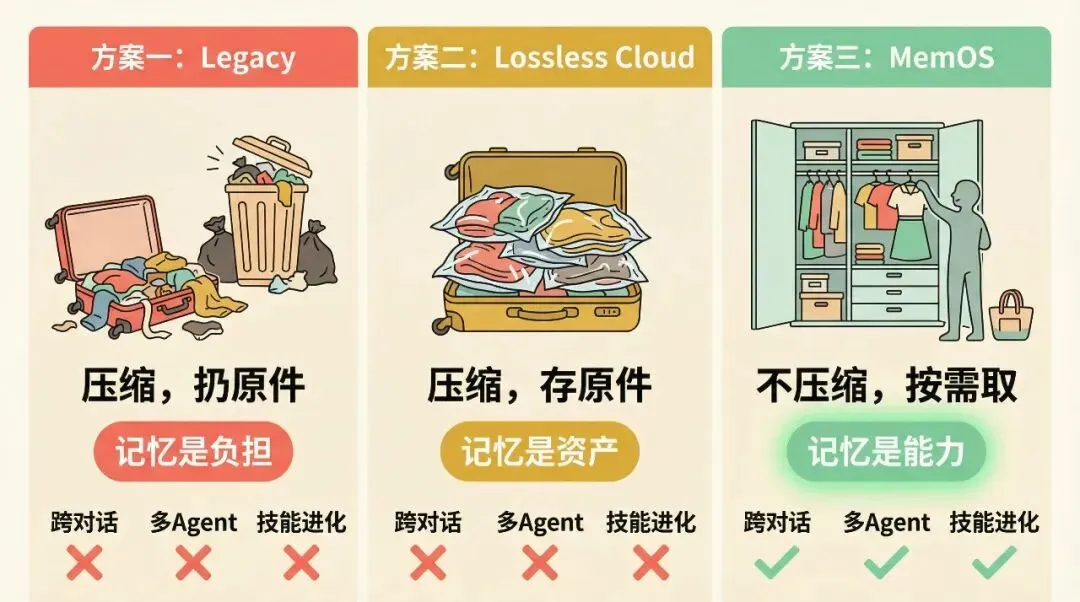
前两个方案像什么?像你要出差,硬往一个行李箱里塞所有的衣服。一种是扔掉几件(Legacy),一种是用真空压缩袋(Lossless Cloud)。行李箱还是那么大,早晚塞满。
MemOS 说:别背行李箱了。把衣服放在衣柜里,出门只带今天要穿的。
具体怎么做到的?
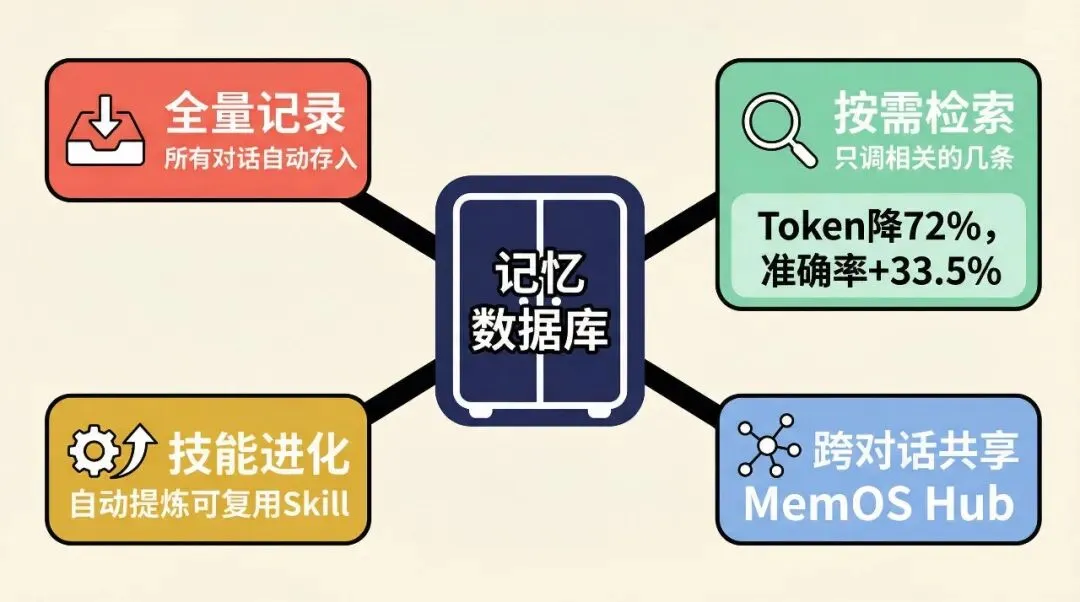
全量记录,但不往桌上放。 你跟 AI 的每一句对话、每一次操作,都自动存进一个独立的本地数据库。不挑不拣,全存。但这些记录不占桌面,它们安静地待在数据库里。如果你之前用的是 OpenClaw 自带的记忆功能,MemOS 支持一键迁移,之前积累的上下文不会白费。
按需检索,只调相关的。 AI 接到新任务时,不会把所有历史搬上桌面,而是像搜索引擎一样,根据当前任务去数据库里检索,只调出相关的几条。上周配过 Nginx?这次任务跟 Nginx 有关,那条记忆自动出现。无关的不占一寸桌面。
这个按需取的效果有多大?MemOS 团队跑了两组实测。
第一组是公开数据集 LOCOMO 的测试:token 消耗直接降了 72% 以上,同时准确率反而提升了 33.5%。省钱的同时还答得更准,因为上下文里塞的都是相关信息,噪音少了。
第二组是真实工程场景,跨多个会话完成复杂开发任务:对话轮次从平均 116 轮降到 54 轮,总 token 消耗从 220 万降到 112 万,砍掉了 49%。任务完成速度提升 2.15 倍。
以前桌面消耗跟聊了多久成正比,现在跟当前任务需要什么挂钩,基本恒定。
自动总结,浓缩经验。 每完成一个任务,系统自动生成结构化总结:做了什么、结论是什么、踩了什么坑。两小时的调试过程,浓缩成一张卡片。下次遇到类似任务,直接调出卡片就行。
技能自动进化。 这条最狠。系统会从重复出现的模式里提炼出可复用的 Skill。比如你让 AI 连续三次用同样的方式处理 CSV 文件,它自动总结出一条规则,下次直接照着来。而且这些 Skill 不是一成不变的,遇到更好的做法,它会自己升级。就像新员工从什么都要问变成有了自己的工作方法论,还在持续迭代。
跨对话、跨 Agent 共享。 前两个方案,换个对话窗口 AI 就失忆了。MemOS 不会。新对话开始时,系统自动检索相关记忆注入进来,上个项目的经验这个项目直接能用。如果你有多个 Agent,比如一个写代码,一个跑测试,它们共享同一个记忆库,一个人踩的坑全团队都能看到。MemOS 管这个叫 MemOS Hub,本质上就是一个团队知识中枢。
三种方案放在一起看
| 方案一(Legacy) | 方案二(Lossless Cloud) | 方案三(MemOS) | |
|---|---|---|---|
| 核心思路 | 压缩,扔原件 | 压缩,存原件 | 不压缩,按需取 |
| 原始信息 | 永久丢失 | 永久保存 | 永久保存 |
| Token 消耗 | 锯齿波动 | 持续增长 | 节省 72%+,基本恒定 |
| 跨对话记忆 | 不支持 | 不支持 | 支持 |
| 多 Agent 共享 | 不支持 | 不支持 | 支持(MemOS-Hub) |
| 技能自动进化 | 不支持 | 不支持 | 支持 |
| 数据隐私 | 取决于平台 | 本地存储 | 100% 本地,零上传 |
三个方案,对应了三种完全不同的记忆观:
方案一觉得记忆是负担,太多了,得压缩掉。
方案二觉得记忆是资产,不能丢,得保存好。
方案三觉得记忆是能力,不只是存着,还得会用,还得能进化。
想试试 MemOS?
MemOS 是 OpenClaw 的插件,开源免费,一行命令就能装。
Mac / Linux:
curl -fsSL https://cdn.memtensor.com.cn/memos-local-openclaw/install.sh | bashWindows(PowerShell):
powershell -c "irm https://cdn.memtensor.com.cn/memos-local-openclaw/install.ps1 | iex"插件主页和文档:https://memos-claw.openmem.net/
装完配好大模型就能用,不需要额外的数据库和外部依赖。
记忆决定了 AI 能走多远
回到开头的承诺。
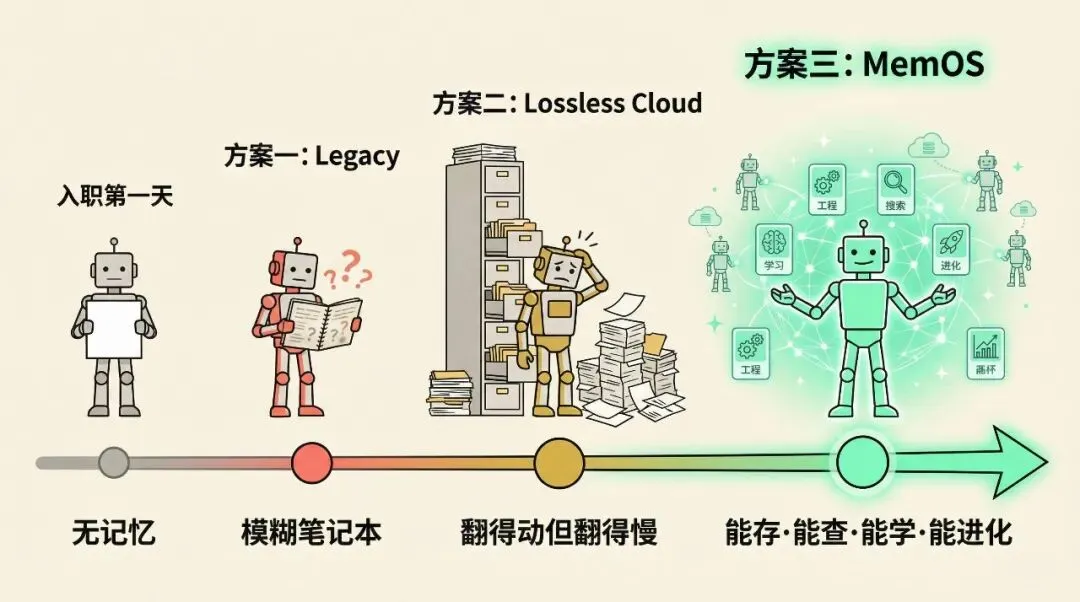
一个没有记忆的 AI,再聪明也只是永远停在入职第一天的实习生。每天来都很厉害,但昨天教的东西今天全忘了。
方案一给了它一本越写越模糊的摘要笔记。方案二给了它一个翻得动但翻得慢的档案馆。方案三给了它一套真正能用的知识管理系统,能存、能查、能学、能进化。
Agent 记忆这件事还很早期,但方向已经很明确了。未来的 AI 不只会更聪明,还会更记事。
一个记事的 AI,才是一个你愿意长期合作的 AI。