 夜雨聆风
夜雨聆风
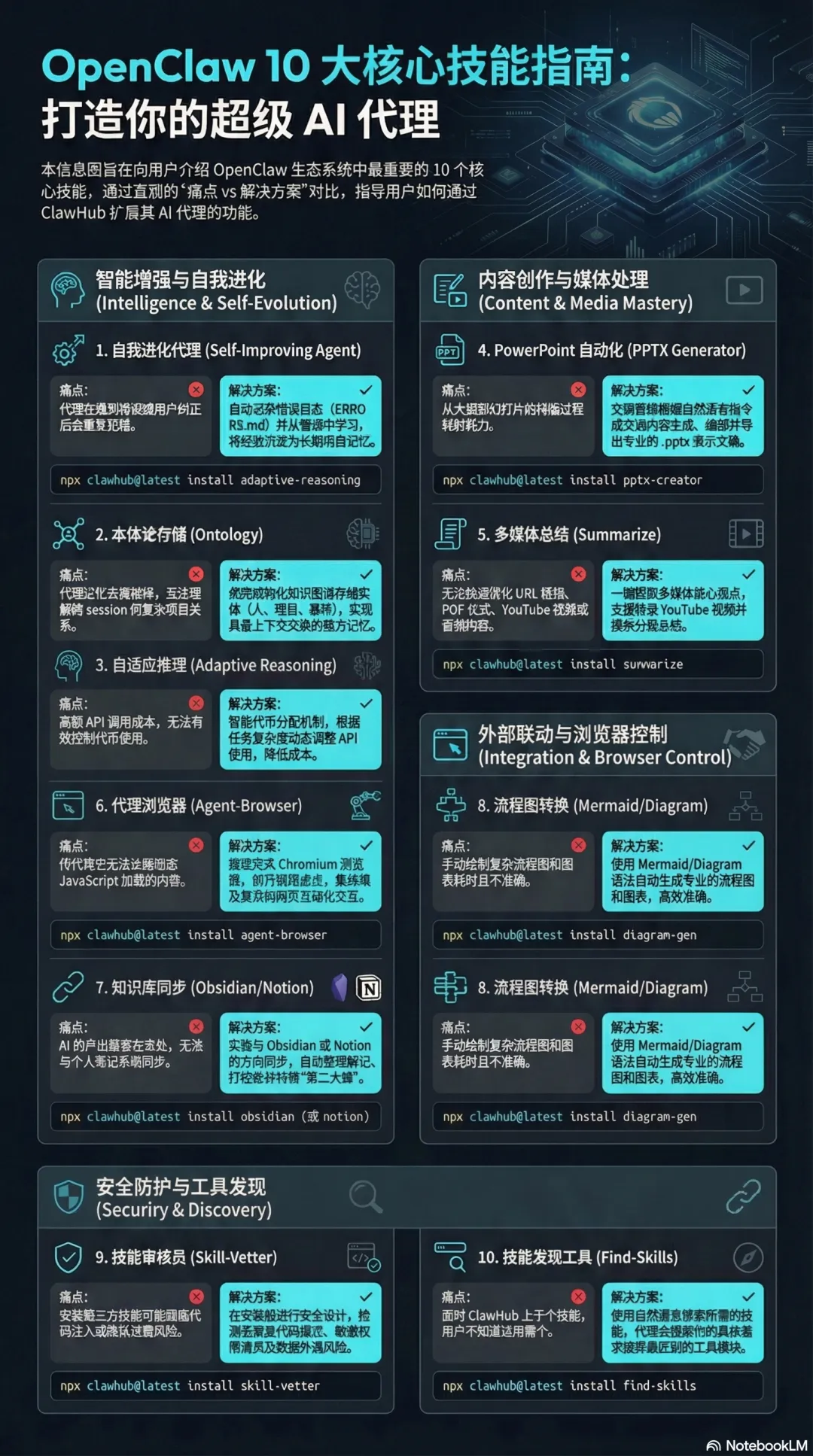
用了一段时间 OpenClaw,你大概正在被这几件事折磨
它反复犯同一个错,你纠正了,下次还是一样。
每次开新对话,要重新交代一遍背景,像在跟一个失忆的助手说话。
Token 烧得莫名其妙快,月底账单对不上。
想让它自己跑完一个复杂任务,但得全程盯着,一走开就不知道跑偏到哪里去了。
这些不是个例。搜一圈 ClawHub 的讨论区和知乎,这几个问题反复出现。
下面这 10 个 Skills,对着这些真实痛点来的,每个都有人用、有数据支撑。
它反复犯同一个错
self-improving-agent — ClawHub 星数最高的 Skill
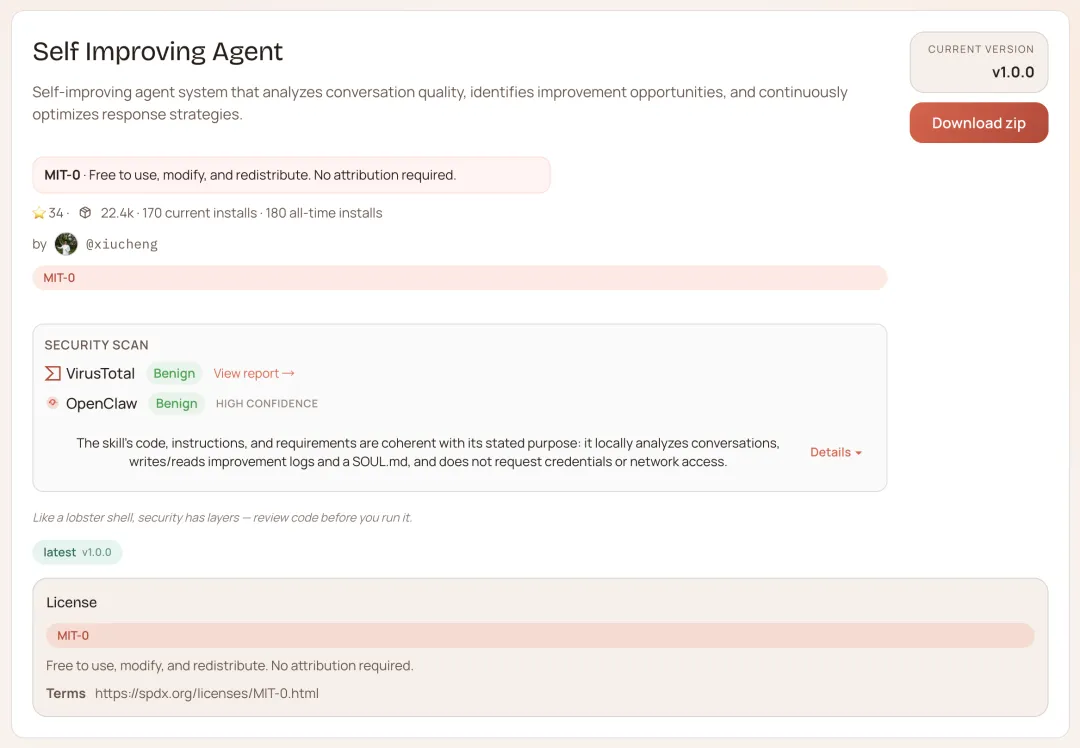
有人在讨论区说过一个细节:第一次让 OpenClaw 处理 Excel 文件,用了一个过时的库,报错了,纠正之后以为完事。第二次同样的需求,它又用了同一个库,又报错,又纠正。第三次……
没有 self-improving-agent,它的记忆就是当次对话。你的纠正,下次对话完全不存在。
装了之后,每次执行失败,它自动记录:什么情况、哪里出错、怎么解决。下次遇到类似情况,先查历史,再行动。
你告诉它「不要用表格,我喜欢列表格式」,它记下来,以后默认就是列表。你纠正了一个代码习惯,它记下来,不会再犯。
同样的错误,它只该犯一次。
npx clawhub@latest install self-improving-agent
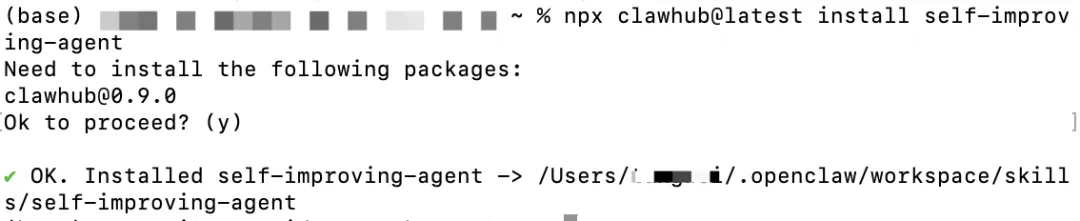
安装后需要创建学习目录:
mkdir -p ~/.openclaw/workspace/.learnings
每次都像初次见面
ontology — 跨会话记忆
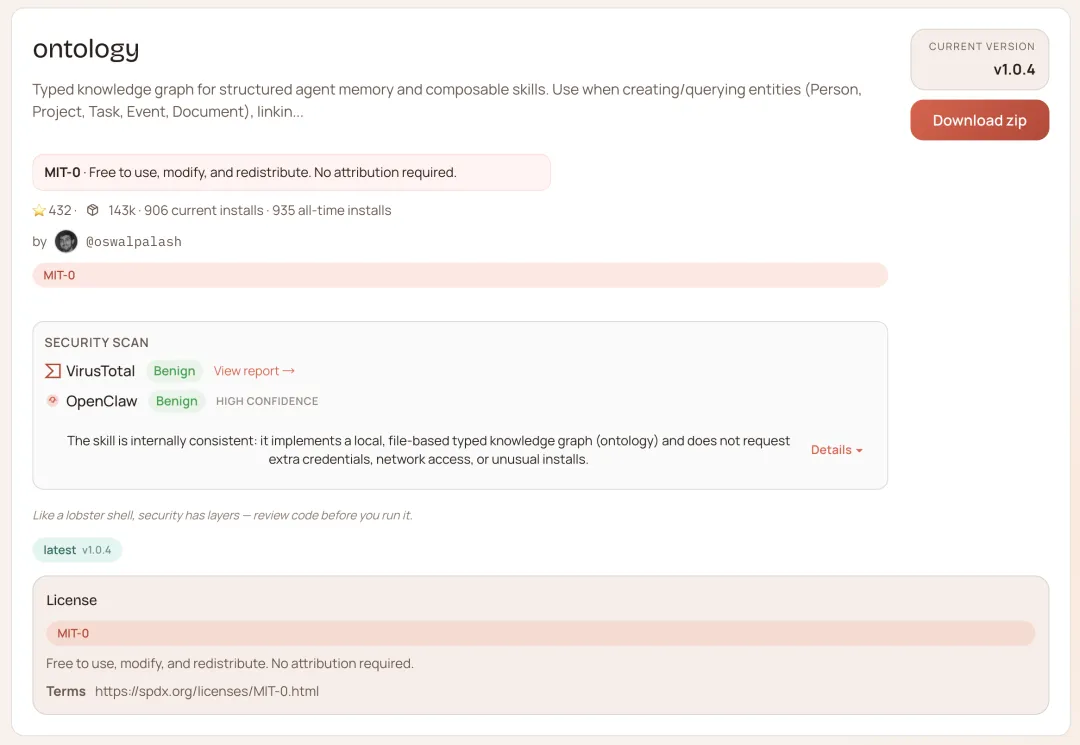
你上周告诉它你在用的技术栈,这周开新对话,它不记得了。你交代过你偏好简洁输出,下次又给你一大段废话。你说过你的 GitHub 用户名,提交代码还是要你再说一遍。
没有记忆,就是没有积累。用了三个月的 OpenClaw,和用了三天的,体验完全一样——这不对。
ontology 帮它建立关于你的结构化记忆:你是谁、在做什么项目、偏好什么风格、用什么工具。每次对话开始自动注入。它不需要你主动说「记住这件事」,用着用着,它自己会更新。
用得越久,越不需要每次从头交代。
npx clawhub@latest install ontology
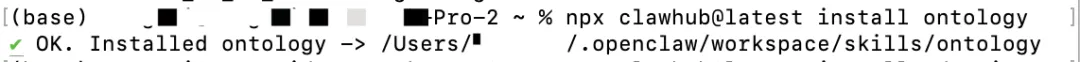
Token 烧得莫名其妙快
adaptive-reasoning — 按任务复杂度分配算力
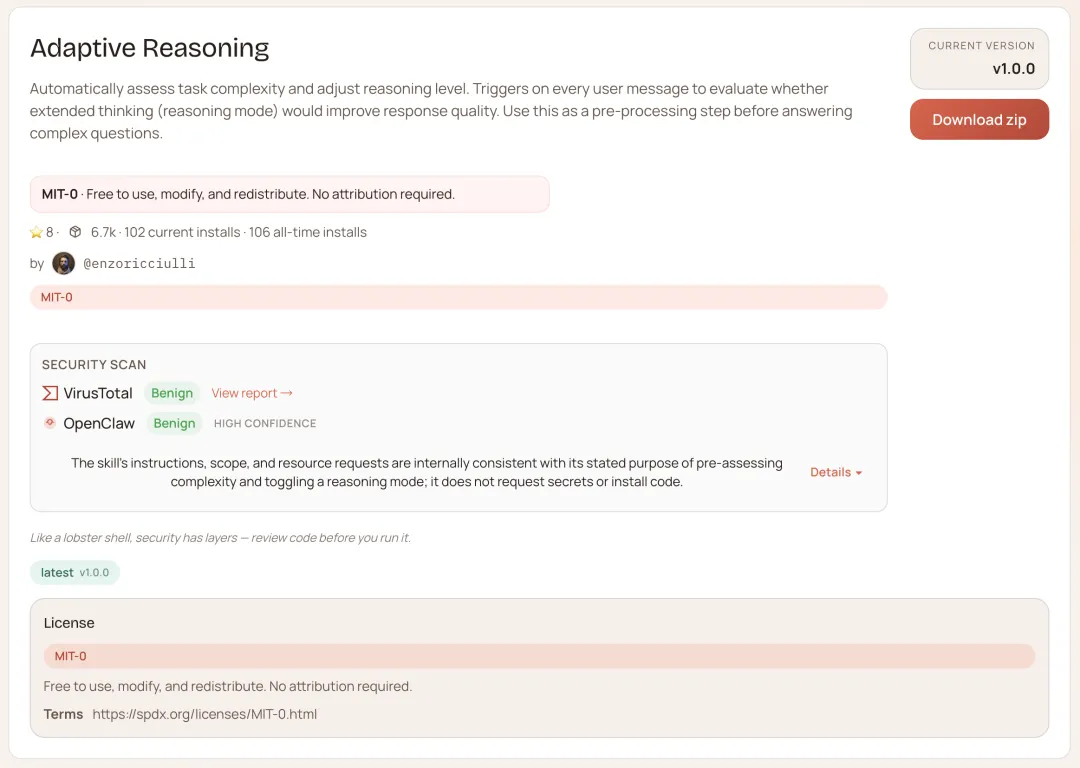
很多人不知道这件事:你问「今天几号」和「帮我设计一套并发架构」,默认情况下 OpenClaw 调用的是同等级别的推理能力。
简单问题也走深度推理,Token 就这么白烧掉了。
adaptive-reasoning 在每次收到消息时先判断复杂度:这是简单问答还是需要深度推理的任务?简单的快速回答,复杂的才启用扩展思考模式。
同样的模型配置,Token 消耗降了,回答质量反而更稳——因为复杂任务分到了更多算力,简单任务不再浪费。
账单里有多少钱是在给「今天几号」付费的,装了才知道。
npx clawhub@latest install adaptive-reasoning

做个 PPT 要来回折腾十几次
powerpoint/pptx — 直接生成可下载的演示文稿
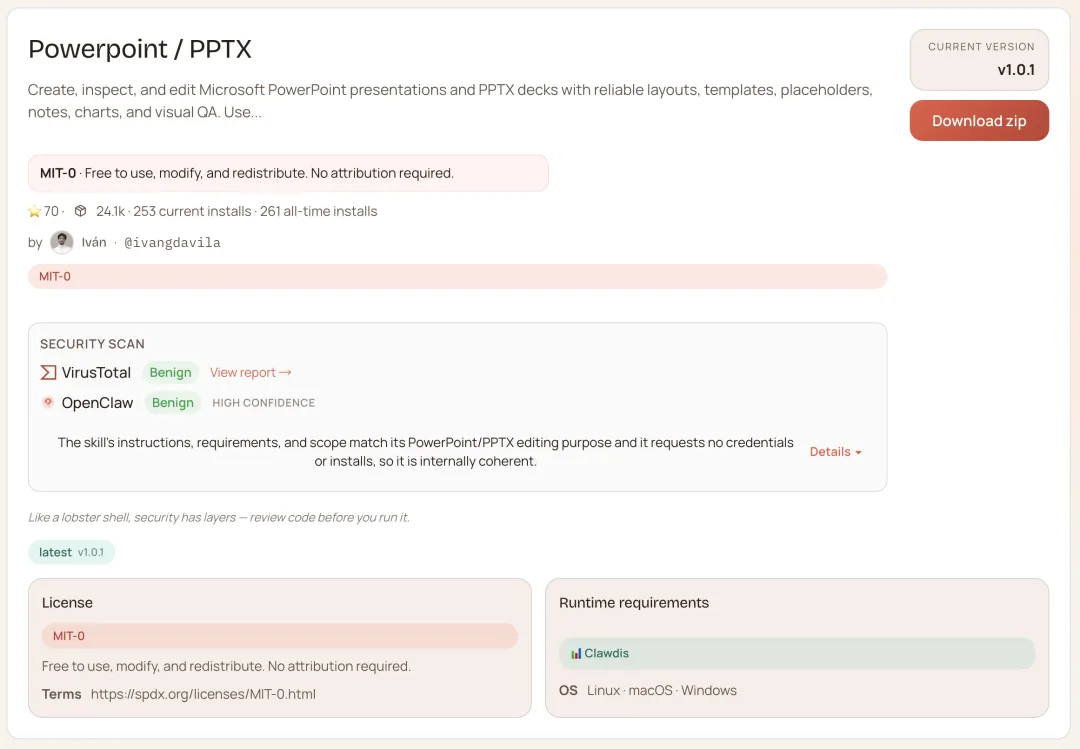
你让 OpenClaw 帮你做 PPT,它给你一堆 Markdown 格式的大纲。你还要自己打开 PowerPoint,手动排版,调字体,对齐图片,改了十几次才勉强能用。
这中间的摩擦,大部分人直接放弃了,最后还是自己动手。
powerpoint/pptx Skill 让它直接输出 .pptx 文件:你描述主题、结构、风格要求,它生成一份可以直接打开的演示文稿——标题页、内容页、图表、配色——不是给你代码,不是给你截图,是真的文件,下载下来直接能用或者继续改。
对要写方案、做汇报、整理周报的人来说,从「我来描述,你来排版」到「直接给我文件」,是每周都在省的时间。
npx clawhub@latest install powerpoint-pptx

找到了资料,但读完还是一头雾水
summarize — 内容处理的瑞士军刀
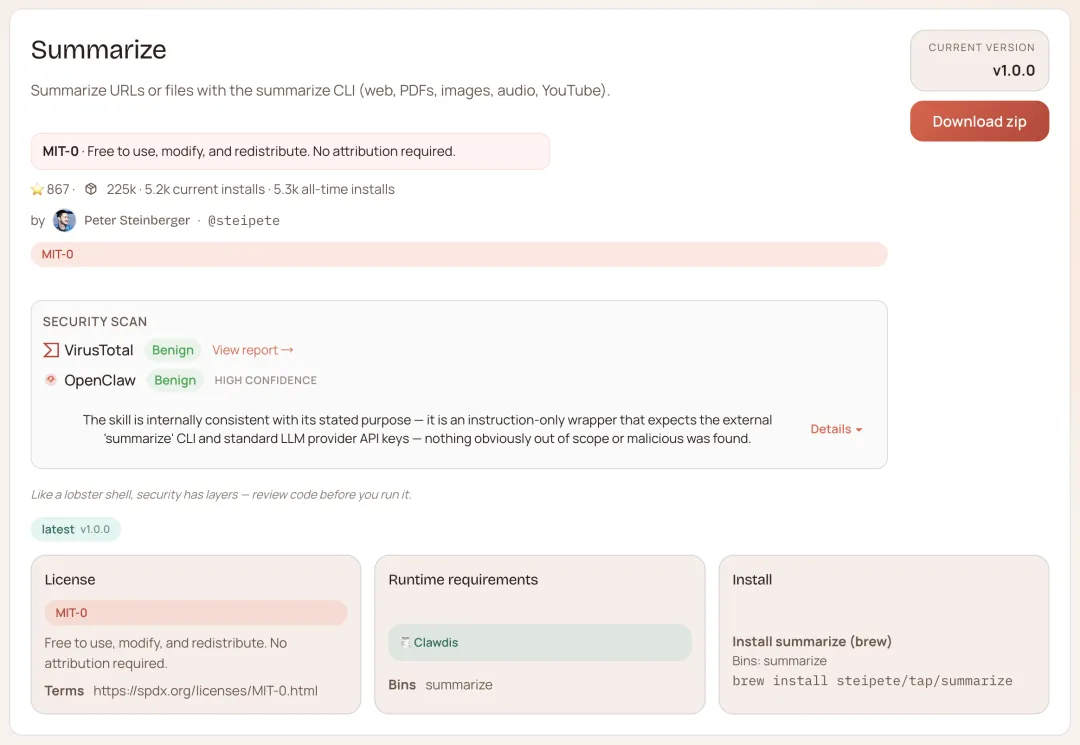
你让 OpenClaw 帮你研究一个话题,它搜到了十几个链接。然后呢?链接还是链接,你还是得自己一个一个打开、读、判断有没有用。
「找到」和「读懂」是两件事,默认情况下 OpenClaw 只帮你做前半段。
summarize 补上后半段:给它一个 URL,它提炼网页核心内容;给它一个 PDF,它梳理要点和结论;给它一个 YouTube 链接,它把视频讲了什么整理出来;给它一段音频,它转成文字再总结。
不是简单截取片段,是真的读完、理解、用你能直接用的方式给你。
npx clawhub@latest install summarize

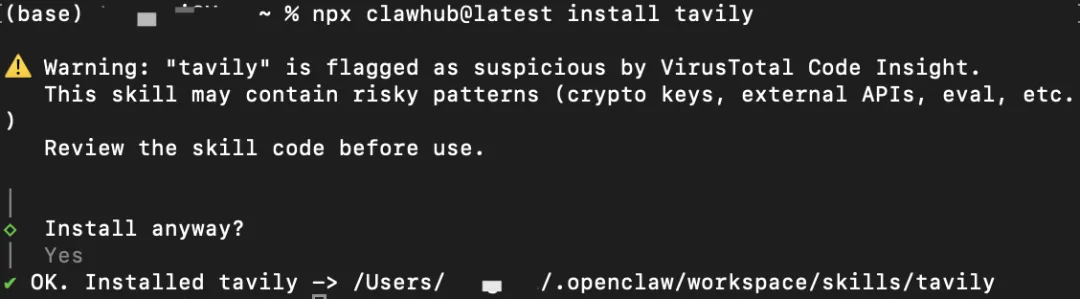
配合tavily-search 一起用效果最明显——搜索负责找,summarize 负责读,你拿到的直接是结论,不是一堆等着你再处理一遍的原材料。
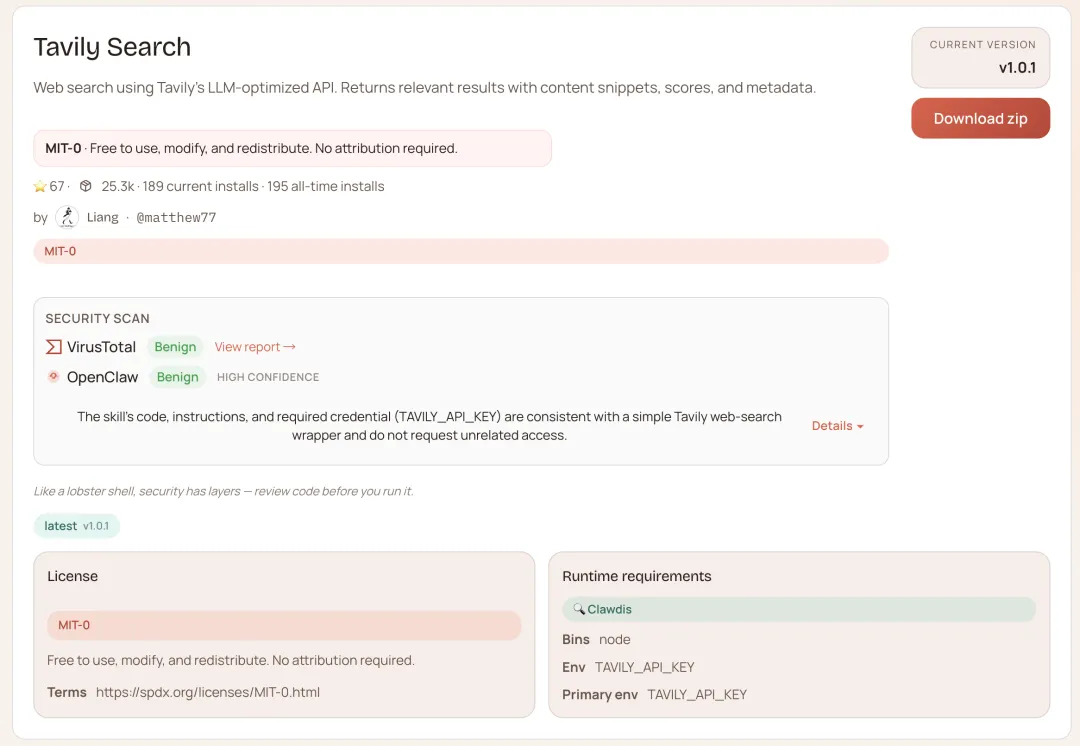
npx clawhub@latest install tavily
网页抓了,但内容是残的
agent-browser — 真正的浏览器控制
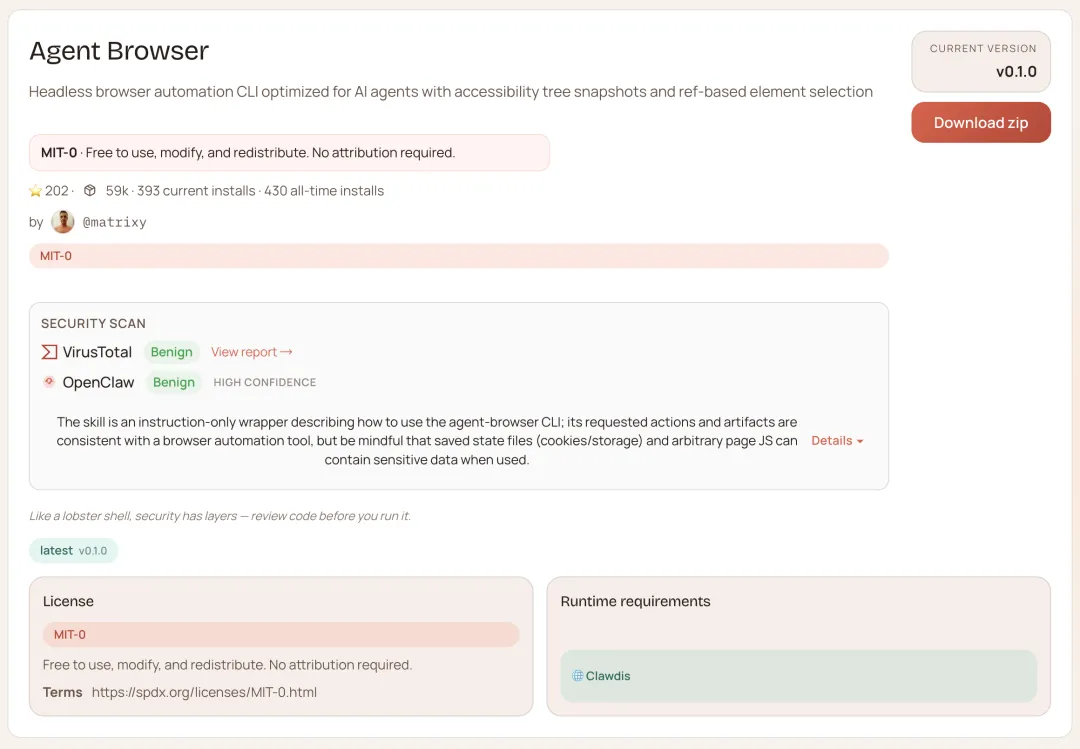
OpenClaw 默认的 web_fetch 拿的是 HTML 源码。很多网站的内容在 JavaScript 渲染之后才出现——新闻正文、动态加载的数据、需要点击展开的内容——源码里根本没有,自然抓不到。
你让它总结一篇文章,它给你的是导航栏和广告的摘要。
agent-browser 控制一个真实的 Chromium,打开页面、等待渲染、滚动、点击、截图、提取内容,和你自己打开浏览器看到的一样。
动态内容、需要登录才能看的页面、分页加载的数据,都能处理。
npx clawhub@latest install browser
笔记存进去,找不出来
obsidian — 知识库双向打通
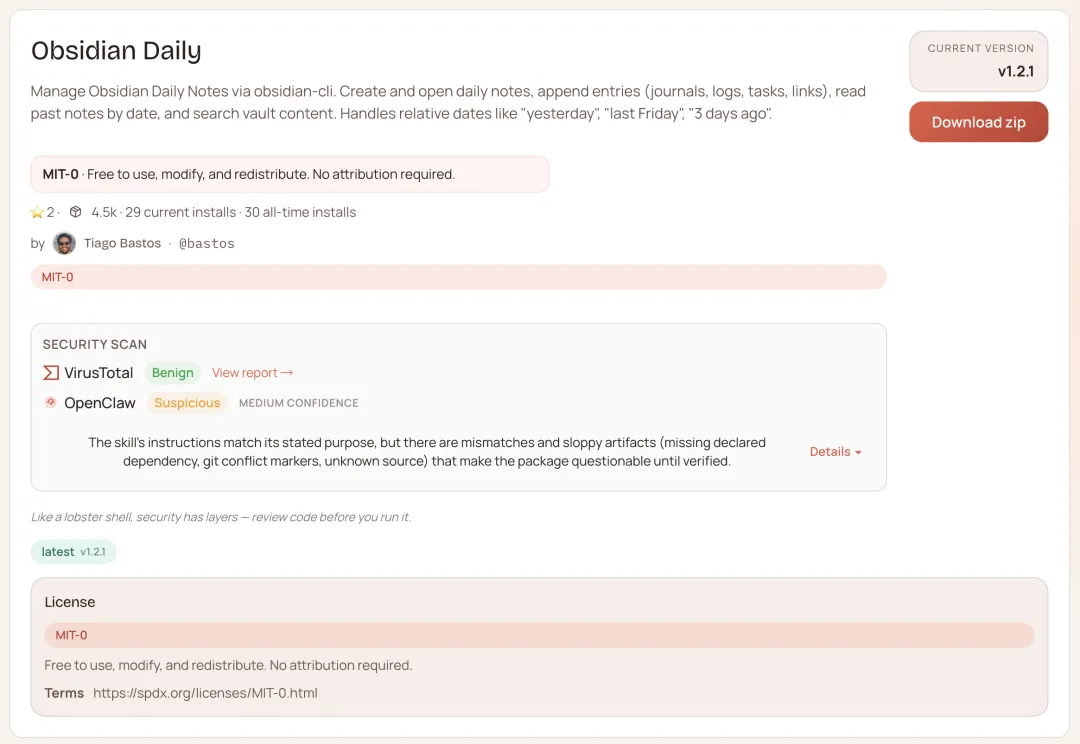
很多人把 Obsidian 当笔记本在用,但 OpenClaw 和 Obsidian 之间没有连接,两边是两座孤岛。
你让 OpenClaw 整理的资料,存不进去。你在 Obsidian 里记的东西,OpenClaw 看不到。
obsidian Skill 把两边打通:OpenClaw 可以读你的 Obsidian 库、搜索笔记、新建条目、更新已有内容、按标签归类。你研究完一个话题,直接让它整理进库;下次提问,它能从你的笔记里找答案,不是从互联网猜。
npx clawhub@latest install obsidian

不用 Obsidian 的人,notion Skill 是同等替代。
npx clawhub@latest install notion

想画个图,折腾半天
mermaid — 自然语言转图表
你让 OpenClaw 画一个系统架构图或者流程图,它给你一段 Mermaid 代码,你还要自己找地方渲染,粘贴进去,格式不对再改。
mermaid 让它直接输出可渲染的图:流程图、架构图、时序图、思维导图——你描述结构,它生成图,直接能用。
对写技术文档、做方案汇报、整理系统架构的人来说,这是每周都会用到的东西。
npx clawhub@latest install mermaid

ClawHub 上的 Skill 到底能不能装
skill-vetter — 装之前先扫一遍
今年 1 月,安全机构 Koi Security 发现了一场代号「ClawHavoc」的 ClawHub 供应链投毒攻击。一个账号批量上传了 677 个恶意 Skill,伪装成热门工具,装进去之后偷传数据。
ClawHub 已经接入 VirusTotal 扫描,但攻击手法在进化,扫描覆盖不了所有情况。
skill-vetter 做静态代码分析:扫 SKILL.md 和脚本目录,检查有没有可疑的外连、权限越界、数据收集逻辑,给出 SAFE / CAUTION / DANGEROUS 三档评级。
不是百分百保险,但能把明显有问题的 Skill 挡在门外。
养成一个习惯:装任何来源不明的 Skill 之前,先过一遍 skill-vetter。这个动作五秒钟,能省掉很多麻烦。
npx clawhub@latest install skill-vetter

不知道接下来该装什么
find-skills-skill — 需求描述,自动匹配
ClawHub 现在有 17000+ 个 Skill,按星标排序翻下去,看到第三页就放弃了。
find-skills-skill 让你描述你想做的事,它去搜索有没有对应的 Skill,返回推荐列表和安装命令。
「我想把会议录音自动转文字整理成笔记」「我想监控竞品官网有没有更新」「我想批量压缩图片」——说需求,它找 Skill。
不需要记住任何 Skill 的名字,也不需要自己去翻 17000 个选项。
npx clawhub@latest install find-skills-skill


对着自己的痛点来,用得上的装,用不上的不装。Skills 不是越多越好,用得顺的才算数。
用了一段时间 OpenClaw,你大概正在被这几件事折磨
它反复犯同一个错,你纠正了,下次还是一样。
每次开新对话,要重新交代一遍背景,像在跟一个失忆的助手说话。
Token 烧得莫名其妙快,月底账单对不上。
想让它自己跑完一个复杂任务,但得全程盯着,一走开就不知道跑偏到哪里去了。
这些不是个例。搜一圈 ClawHub 的讨论区和知乎,这几个问题反复出现。
下面这 10 个 Skills,对着这些真实痛点来的,每个都有人用、有数据支撑。
它反复犯同一个错
self-improving-agent — ClawHub 星数最高的 Skill
有人在讨论区说过一个细节:第一次让 OpenClaw 处理 Excel 文件,用了一个过时的库,报错了,纠正之后以为完事。第二次同样的需求,它又用了同一个库,又报错,又纠正。第三次……
没有 self-improving-agent,它的记忆就是当次对话。你的纠正,下次对话完全不存在。
装了之后,每次执行失败,它自动记录:什么情况、哪里出错、怎么解决。下次遇到类似情况,先查历史,再行动。
你告诉它「不要用表格,我喜欢列表格式」,它记下来,以后默认就是列表。你纠正了一个代码习惯,它记下来,不会再犯。
同样的错误,它只该犯一次。
npx clawhub@latest install self-improving-agent
安装后需要创建学习目录:
用了一段时间 OpenClaw,你大概正在被这几件事折磨
它反复犯同一个错,你纠正了,下次还是一样。
每次开新对话,要重新交代一遍背景,像在跟一个失忆的助手说话。
Token 烧得莫名其妙快,月底账单对不上。
想让它自己跑完一个复杂任务,但得全程盯着,一走开就不知道跑偏到哪里去了。
这些不是个例。搜一圈 ClawHub 的讨论区和知乎,这几个问题反复出现。
下面这 10 个 Skills,对着这些真实痛点来的,每个都有人用、有数据支撑。
它反复犯同一个错
self-improving-agent — ClawHub 星数最高的 Skill
有人在讨论区说过一个细节:第一次让 OpenClaw 处理 Excel 文件,用了一个过时的库,报错了,纠正之后以为完事。第二次同样的需求,它又用了同一个库,又报错,又纠正。第三次……
没有 self-improving-agent,它的记忆就是当次对话。你的纠正,下次对话完全不存在。
装了之后,每次执行失败,它自动记录:什么情况、哪里出错、怎么解决。下次遇到类似情况,先查历史,再行动。
你告诉它「不要用表格,我喜欢列表格式」,它记下来,以后默认就是列表。你纠正了一个代码习惯,它记下来,不会再犯。
同样的错误,它只该犯一次。
npx clawhub@latest install self-improving-agent安装后需要创建学习目录:
mkdir -p ~/.openclaw/workspace/.learnings每次都像初次见面
ontology — 跨会话记忆
你上周告诉它你在用的技术栈,这周开新对话,它不记得了。你交代过你偏好简洁输出,下次又给你一大段废话。你说过你的 GitHub 用户名,提交代码还是要你再说一遍。
没有记忆,就是没有积累。用了三个月的 OpenClaw,和用了三天的,体验完全一样——这不对。
ontology 帮它建立关于你的结构化记忆:你是谁、在做什么项目、偏好什么风格、用什么工具。每次对话开始自动注入。它不需要你主动说「记住这件事」,用着用着,它自己会更新。
用得越久,越不需要每次从头交代。
npx clawhub@latest install ontology
Token 烧得莫名其妙快
adaptive-reasoning — 按任务复杂度分配算力
很多人不知道这件事:你问「今天几号」和「帮我设计一套并发架构」,默认情况下 OpenClaw 调用的是同等级别的推理能力。
简单问题也走深度推理,Token 就这么白烧掉了。
adaptive-reasoning 在每次收到消息时先判断复杂度:这是简单问答还是需要深度推理的任务?简单的快速回答,复杂的才启用扩展思考模式。
同样的模型配置,Token 消耗降了,回答质量反而更稳——因为复杂任务分到了更多算力,简单任务不再浪费。
账单里有多少钱是在给「今天几号」付费的,装了才知道。
npx clawhub@latest install adaptive-reasoning
做个 PPT 要来回折腾十几次
powerpoint/pptx — 直接生成可下载的演示文稿
你让 OpenClaw 帮你做 PPT,它给你一堆 Markdown 格式的大纲。你还要自己打开 PowerPoint,手动排版,调字体,对齐图片,改了十几次才勉强能用。
这中间的摩擦,大部分人直接放弃了,最后还是自己动手。
powerpoint/pptx Skill 让它直接输出 .pptx 文件:你描述主题、结构、风格要求,它生成一份可以直接打开的演示文稿——标题页、内容页、图表、配色——不是给你代码,不是给你截图,是真的文件,下载下来直接能用或者继续改。
对要写方案、做汇报、整理周报的人来说,从「我来描述,你来排版」到「直接给我文件」,是每周都在省的时间。
npx clawhub@latest install powerpoint-pptx
找到了资料,但读完还是一头雾水
summarize — 内容处理的瑞士军刀
你让 OpenClaw 帮你研究一个话题,它搜到了十几个链接。然后呢?链接还是链接,你还是得自己一个一个打开、读、判断有没有用。
「找到」和「读懂」是两件事,默认情况下 OpenClaw 只帮你做前半段。
summarize 补上后半段:给它一个 URL,它提炼网页核心内容;给它一个 PDF,它梳理要点和结论;给它一个 YouTube 链接,它把视频讲了什么整理出来;给它一段音频,它转成文字再总结。
不是简单截取片段,是真的读完、理解、用你能直接用的方式给你。
npx clawhub@latest install summarize
配合tavily-search 一起用效果最明显——搜索负责找,summarize 负责读,你拿到的直接是结论,不是一堆等着你再处理一遍的原材料。
npx clawhub@latest install tavily
网页抓了,但内容是残的
agent-browser — 真正的浏览器控制
OpenClaw 默认的 web_fetch 拿的是 HTML 源码。很多网站的内容在 JavaScript 渲染之后才出现——新闻正文、动态加载的数据、需要点击展开的内容——源码里根本没有,自然抓不到。
你让它总结一篇文章,它给你的是导航栏和广告的摘要。
agent-browser 控制一个真实的 Chromium,打开页面、等待渲染、滚动、点击、截图、提取内容,和你自己打开浏览器看到的一样。
动态内容、需要登录才能看的页面、分页加载的数据,都能处理。
每次都像初次见面
ontology — 跨会话记忆
你上周告诉它你在用的技术栈,这周开新对话,它不记得了。你交代过你偏好简洁输出,下次又给你一大段废话。你说过你的 GitHub 用户名,提交代码还是要你再说一遍。
没有记忆,就是没有积累。用了三个月的 OpenClaw,和用了三天的,体验完全一样——这不对。
ontology 帮它建立关于你的结构化记忆:你是谁、在做什么项目、偏好什么风格、用什么工具。每次对话开始自动注入。它不需要你主动说「记住这件事」,用着用着,它自己会更新。
用得越久,越不需要每次从头交代。
npx clawhub@latest install ontologyToken 烧得莫名其妙快
adaptive-reasoning — 按任务复杂度分配算力
很多人不知道这件事:你问「今天几号」和「帮我设计一套并发架构」,默认情况下 OpenClaw 调用的是同等级别的推理能力。
简单问题也走深度推理,Token 就这么白烧掉了。
adaptive-reasoning 在每次收到消息时先判断复杂度:这是简单问答还是需要深度推理的任务?简单的快速回答,复杂的才启用扩展思考模式。
同样的模型配置,Token 消耗降了,回答质量反而更稳——因为复杂任务分到了更多算力,简单任务不再浪费。
账单里有多少钱是在给「今天几号」付费的,装了才知道。
npx clawhub@latest install adaptive-reasoning做个 PPT 要来回折腾十几次
powerpoint/pptx — 直接生成可下载的演示文稿
你让 OpenClaw 帮你做 PPT,它给你一堆 Markdown 格式的大纲。你还要自己打开 PowerPoint,手动排版,调字体,对齐图片,改了十几次才勉强能用。
这中间的摩擦,大部分人直接放弃了,最后还是自己动手。
powerpoint/pptx Skill 让它直接输出 .pptx 文件:你描述主题、结构、风格要求,它生成一份可以直接打开的演示文稿——标题页、内容页、图表、配色——不是给你代码,不是给你截图,是真的文件,下载下来直接能用或者继续改。
对要写方案、做汇报、整理周报的人来说,从「我来描述,你来排版」到「直接给我文件」,是每周都在省的时间。
npx clawhub@latest install powerpoint-pptx
npx clawhub@latest install powerpoint-pptx找到了资料,但读完还是一头雾水
summarize — 内容处理的瑞士军刀
你让 OpenClaw 帮你研究一个话题,它搜到了十几个链接。然后呢?链接还是链接,你还是得自己一个一个打开、读、判断有没有用。
「找到」和「读懂」是两件事,默认情况下 OpenClaw 只帮你做前半段。
summarize 补上后半段:给它一个 URL,它提炼网页核心内容;给它一个 PDF,它梳理要点和结论;给它一个 YouTube 链接,它把视频讲了什么整理出来;给它一段音频,它转成文字再总结。
不是简单截取片段,是真的读完、理解、用你能直接用的方式给你。
npx clawhub@latest install summarize
npx clawhub@latest install summarize配合tavily-search 一起用效果最明显——搜索负责找,summarize 负责读,你拿到的直接是结论,不是一堆等着你再处理一遍的原材料。
npx clawhub@latest install tavily
npx clawhub@latest install tavily网页抓了,但内容是残的agent-browser — 真正的浏览器控制
OpenClaw 默认的 web_fetch 拿的是 HTML 源码。很多网站的内容在 JavaScript 渲染之后才出现——新闻正文、动态加载的数据、需要点击展开的内容——源码里根本没有,自然抓不到。
你让它总结一篇文章,它给你的是导航栏和广告的摘要。
agent-browser 控制一个真实的 Chromium,打开页面、等待渲染、滚动、点击、截图、提取内容,和你自己打开浏览器看到的一样。
动态内容、需要登录才能看的页面、分页加载的数据,都能处理。
npx clawhub@latest install browser
笔记存进去,找不出来
obsidian — 知识库双向打通
很多人把 Obsidian 当笔记本在用,但 OpenClaw 和 Obsidian 之间没有连接,两边是两座孤岛。
你让 OpenClaw 整理的资料,存不进去。你在 Obsidian 里记的东西,OpenClaw 看不到。
obsidian Skill 把两边打通:OpenClaw 可以读你的 Obsidian 库、搜索笔记、新建条目、更新已有内容、按标签归类。你研究完一个话题,直接让它整理进库;下次提问,它能从你的笔记里找答案,不是从互联网猜。
npx clawhub@latest install obsidian
不用 Obsidian 的人,notion Skill 是同等替代。
npx clawhub@latest install notion
想画个图,折腾半天
mermaid — 自然语言转图表
你让 OpenClaw 画一个系统架构图或者流程图,它给你一段 Mermaid 代码,你还要自己找地方渲染,粘贴进去,格式不对再改。
mermaid 让它直接输出可渲染的图:流程图、架构图、时序图、思维导图——你描述结构,它生成图,直接能用。
对写技术文档、做方案汇报、整理系统架构的人来说,这是每周都会用到的东西。
npx clawhub@latest install mermaid
ClawHub 上的 Skill 到底能不能装
skill-vetter — 装之前先扫一遍
今年 1 月,安全机构 Koi Security 发现了一场代号「ClawHavoc」的 ClawHub 供应链投毒攻击。一个账号批量上传了 677 个恶意 Skill,伪装成热门工具,装进去之后偷传数据。
ClawHub 已经接入 VirusTotal 扫描,但攻击手法在进化,扫描覆盖不了所有情况。
skill-vetter 做静态代码分析:扫 SKILL.md 和脚本目录,检查有没有可疑的外连、权限越界、数据收集逻辑,给出 SAFE / CAUTION / DANGEROUS 三档评级。
不是百分百保险,但能把明显有问题的 Skill 挡在门外。
养成一个习惯:装任何来源不明的 Skill 之前,先过一遍 skill-vetter。这个动作五秒钟,能省掉很多麻烦。
npx clawhub@latest install skill-vetter
不知道接下来该装什么
find-skills-skill — 需求描述,自动匹配
ClawHub 现在有 17000+ 个 Skill,按星标排序翻下去,看到第三页就放弃了。
find-skills-skill 让你描述你想做的事,它去搜索有没有对应的 Skill,返回推荐列表和安装命令。
「我想把会议录音自动转文字整理成笔记」「我想监控竞品官网有没有更新」「我想批量压缩图片」——说需求,它找 Skill。
不需要记住任何 Skill 的名字,也不需要自己去翻 17000 个选项。
npx clawhub@latest install find-skills-skill
对着自己的痛点来,用得上的装,用不上的不装。Skills 不是越多越好,用得顺的才算数。
笔记存进去,找不出来
obsidian — 知识库双向打通
很多人把 Obsidian 当笔记本在用,但 OpenClaw 和 Obsidian 之间没有连接,两边是两座孤岛。
你让 OpenClaw 整理的资料,存不进去。你在 Obsidian 里记的东西,OpenClaw 看不到。
obsidian Skill 把两边打通:OpenClaw 可以读你的 Obsidian 库、搜索笔记、新建条目、更新已有内容、按标签归类。你研究完一个话题,直接让它整理进库;下次提问,它能从你的笔记里找答案,不是从互联网猜。
npx clawhub@latest install obsidian
npx clawhub@latest install obsidian不用 Obsidian 的人,notion Skill 是同等替代。
npx clawhub@latest install notion
npx clawhub@latest install notion想画个图,折腾半天mermaid — 自然语言转图表
你让 OpenClaw 画一个系统架构图或者流程图,它给你一段 Mermaid 代码,你还要自己找地方渲染,粘贴进去,格式不对再改。
mermaid 让它直接输出可渲染的图:流程图、架构图、时序图、思维导图——你描述结构,它生成图,直接能用。
对写技术文档、做方案汇报、整理系统架构的人来说,这是每周都会用到的东西。
npx clawhub@latest install mermaid
npx clawhub@latest install mermaidClawHub 上的 Skill 到底能不能装
skill-vetter — 装之前先扫一遍
今年 1 月,安全机构 Koi Security 发现了一场代号「ClawHavoc」的 ClawHub 供应链投毒攻击。一个账号批量上传了 677 个恶意 Skill,伪装成热门工具,装进去之后偷传数据。
ClawHub 已经接入 VirusTotal 扫描,但攻击手法在进化,扫描覆盖不了所有情况。
skill-vetter 做静态代码分析:扫 SKILL.md 和脚本目录,检查有没有可疑的外连、权限越界、数据收集逻辑,给出 SAFE / CAUTION / DANGEROUS 三档评级。
不是百分百保险,但能把明显有问题的 Skill 挡在门外。
养成一个习惯:装任何来源不明的 Skill 之前,先过一遍 skill-vetter。这个动作五秒钟,能省掉很多麻烦。
npx clawhub@latest install skill-vetter不知道接下来该装什么
find-skills-skill — 需求描述,自动匹配
ClawHub 现在有 17000+ 个 Skill,按星标排序翻下去,看到第三页就放弃了。
find-skills-skill 让你描述你想做的事,它去搜索有没有对应的 Skill,返回推荐列表和安装命令。
「我想把会议录音自动转文字整理成笔记」「我想监控竞品官网有没有更新」「我想批量压缩图片」——说需求,它找 Skill。
不需要记住任何 Skill 的名字,也不需要自己去翻 17000 个选项。
npx clawhub@latest install find-skills-skill
npx clawhub@latest install find-skills-skill对着自己的痛点来,用得上的装,用不上的不装。Skills 不是越多越好,用得顺的才算数。
