 夜雨聆风
夜雨聆风3月23日,美国国会下属的一家咨询机构发布警告称:中国在开源AI模型领域的统治地位正“威胁到美国的领先地位”。
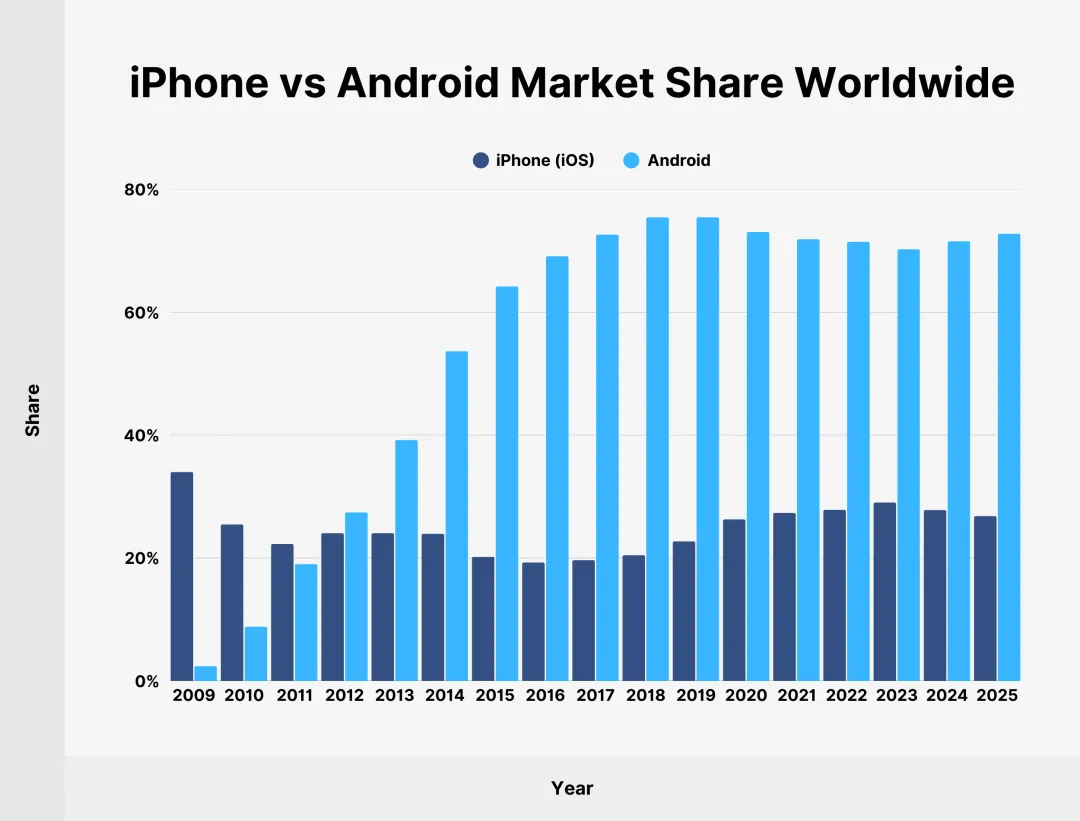
数据显示,过去一年中,中国开发的模型在全球下载量中的占比达到41%,而美国模型占比为36.5%。其中,DeepSeek和通义千问(Qwen)的表现尤为抢眼,两者的全球市场份额在短短12个月内从1%飙升至15%。
路透社将其解读为一种威胁,但如果复盘科技史,你会发现这更像是一场“美式剧本”的翻演。至于结局是否会殊途同归,则是另一个层面的博弈。
01
谷歌当年的“反直觉”豪赌:把操作系统白送
2005年,谷歌以5000万美元(约3.5亿元人民币)的价格收购了一家名为安卓(Android)的小型移动软件公司。随后,它做出了一个在当时看来极其不理性的决定:将整个操作系统完全免费。
免费的系统、免费的应用商店、免费的API。任何手机制造商都可以直接拿去用,一分钱授权费都不用交。
这种逻辑只有在你理解谷歌到底在卖什么时才成立。谷歌的核心业务是搜索广告,仅在2021年就创造了约1490亿美元(约1万亿元人民币)的收入。在21世纪初,移动互联网取代桌面端已成定局。如果苹果掌控了唯一的移动操作系统,就等于掌控了通往谷歌收入的咽喉。
安卓从来不是产品,安卓是保护核心产品可及性的工具。
通过免费模式,谷歌将用户与搜索之间的那个“层”彻底变成了廉价的大宗商品(Commoditize)。手机厂商得到了免费系统,开发者得到了免费平台,而谷歌则在全球每10台移动设备中的7台里,成功植入了自己的搜索引擎。
Stack Overflow的联合创始人Joel Spolsky在2002年就总结过这个底层逻辑:“将你的互补品商品化”(Commoditize your complement)。
如果你的业务依赖于某种互补产品,那就把那个互补品的价格打到零。当互补品变得越便宜,对你核心产品的需求就会越高。谷歌不需要靠安卓赚钱,它只需要安卓确保没人能在通往”谷歌搜索”的路上收过路费。
02
同样的棋局,不同的战
过去一个月,中国科技界发生了三件看似孤立、实则逻辑高度一致的事情。
首先,阿里云的通义千问和DeepSeek持续推进开源步伐。3月初发布的DeepSeek V4,其输入token的价格约为每百万个0.3美元(约2元人民币),仅为GPT-5.4 Standard成本的八分之一。过去一年,中国大模型的价格战已近乎惨烈。
其次,小米、蚂蚁集团和阿里达摩院在2月和3月接连发布了针对机器人应用的开源模型。这意味着任何开发机器人控制系统的人,都可以免费获得模型权重。
第三,字节跳动旗下的飞书(Lark)和阿里云旗下的钉钉,在24小时内先后开源了各自的命令行界面(CLI)。3月28日,飞书发布Lark CLI v1.0.0,采用MIT协议,开放了超过2500个API;而钉钉在3月27日发布的CLI则采用Apache 2.0协议,向AI Agent开放了日历、消息和任务管理等10项核心能力。
这些举动都在”白送”:送模型、送机器人大脑、送企业级基础设施。路透社的警告只盯着模型本身,但模型其实就是这一代的安卓——它们是被推向”大宗商品化”的互补品,目的是为了在其他环节捕捉价值。

当模型层变得免费或近乎免费,价值就会向其上下游高度集中。在下游,是硬件与物理基础设施;在软件层,是飞书和钉钉这种生态平台;在底层,是数亿用户在生产环境中产生的真实世界数据
美中经济与安全审查委员会(USCC)的研究将其描述为”双环”战略:一个是数字环,开源模型驱动快速迭代和社区贡献;一个是物理环,制造规模和物流部署产生真实数据,再反哺数字环。美国AI实验室拥有强大的数字环,但在物理制造层(边缘硬件、物流、实地部署数据)面临着巨大的鸿沟。
03
历史不会简单重复
虽然逻辑相似,但这场类比也有其局限性。
谷歌开源安卓时,身后是一个年入千亿美元的搜索广告帝国。变现模式是现成的,安卓的任务是防御,是守住这条财路。
而中国AI公司所处的阶段完全不同。DeepSeek和通义千问在免费输出模型,但它们身后并没有一个1490亿美元的现金奶牛在支撑。硬件、制造、企业软件的下游价值虽然想象空间巨大,但尚未在同等规模上得到验证。这套战略假设价值会向这些层级转移,但这取决于尚未完成的执行过程。
摩擦力同样存在。DeepSeek的许可证包含基于用途的限制和内容过滤要求,这与Apache 2.0这种完全许可的开源协议不同。相比之下,通义千问3.5则采用了无限制的Apache 2.0协议。西方企业在评估中国模型时,会权衡数据治理等合规成本。开源并不意味着能自动解决监管行业的信任难题。
企业基础设施的开源也暗藏玄机。36kr在分析飞书和钉钉的CLI发布时指出,飞书采取的是层级化开放,保留了深度上下文和工作流智能作为私有价值;而钉钉则奉行“有界开放”,开放日历、消息等高频场景,却将核心的业务操作保留在封闭的“悟空”平台内。
谁都没有把底牌全部掀开。 它们在开放那些能吸引开发者的部分,同时死守着能产生收入的部分。这与谷歌当年保留搜索专利、开放手机系统的策略如出一辙。
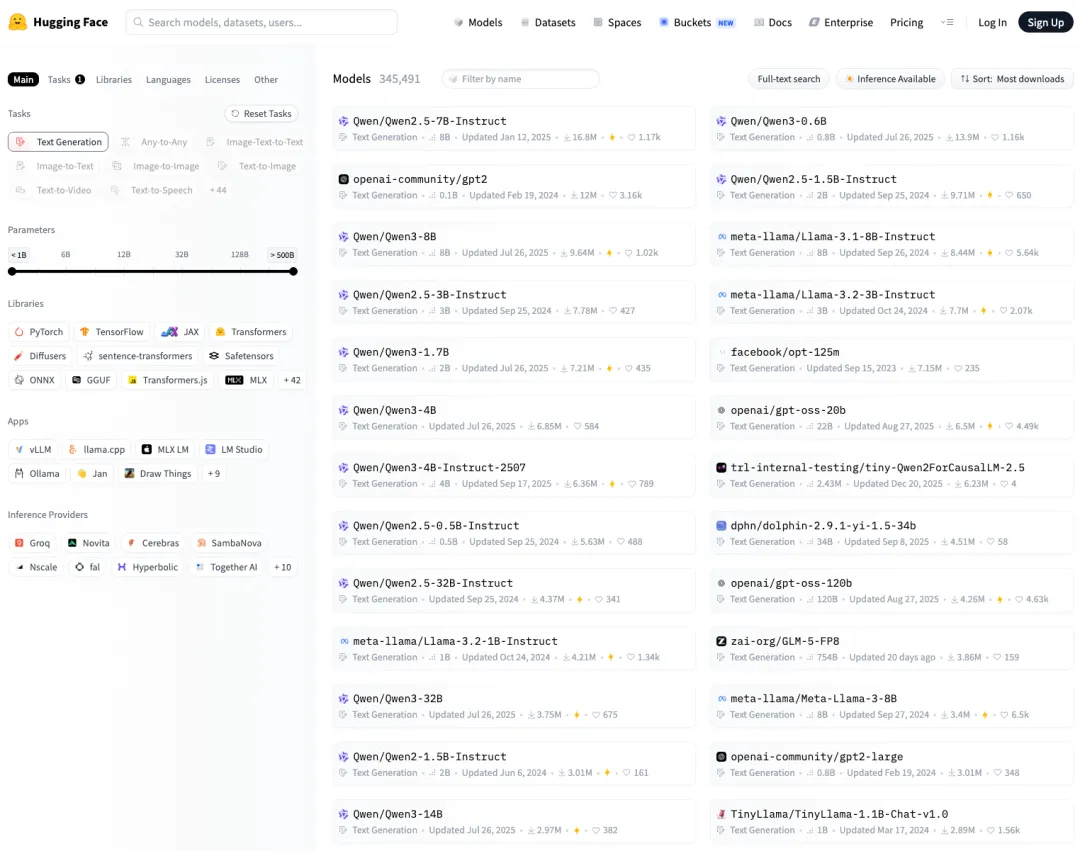
但策略上的含蓄掩盖不住下载量上的碾压。打开Hugging Face按下载量排序,通义千问(Qwen)几乎占满了整个榜单。
04
当”好用”撞上”便宜”
不可否认,美国顶尖模型在原生性能基准上依然领先。Claude Opus 4.6在代码任务测试SWE-bench Verified中得分80.8%;GPT-5.4在Agent执行力测试Terminal-Bench 2.0中独占鳌头。在最苛刻的推理测试中,美国闭源模型与中国开源模型之间确实存在代差。
但数据同时也揭示了采纳率的真相:中国开源模型目前已占据全球AI使用量的约30%。仅通义千问在Hugging Face上的下载量就突破了7亿次。
当顶级闭源模型与顶级开源模型之间的差距缩小到一定程度时,对于大多数生产应用而言,成本的权重就会压过性能的权重。
在带工具测试的Humanity's Last Exam基准中,月之暗面(Moonshot)的Kimi K2得分44.9%,略高于谷歌Gemini的44.7%。价格仅为GPT-5.4八分之一的DeepSeek V4,并不需要在每一项指标上都超越GPT-5。它只需要在具体场景中“足够好用”,并且“足够便宜”,就能彻底改变商业计算公式。
安卓手机从未像iPhone那样精致,但它们足够好用,且遍布每一个运营商、每一个价位段、每一个市场。安卓巨大的装机量创造了一个开发者生态,这个生态是靠规模而非利润率支撑起来的。
美国咨询机构的警告将“开源优势”视为一个需要反击的问题,这本身就假设了竞争的焦点在于模型。但如果真正的竞争在于谁能基于这些“廉价商品化”的模型,在硬件、软件、制造和边缘端构建出最高的价值,那么模型层就只是投入,而非产出。
纠结于谁的模型下载量最高,就像当年纠结谁的免费操作系统最好用一样,真正重要的问题是:谁能在这些系统之上,盖起最稳固的大楼?
中国公司能否像谷歌那样,将开源的流量转化为持久的商业价值?目前还没有定论。未来两年,值得关注的不是下载量或跑分,而是这些公司中,是否有人能在这片被推平的低价土地上,长出可持续的盈利模式。
