 夜雨聆风
夜雨聆风大多数人用 OpenClaw 的方式是一个 Agent 干所有事。写代码找它,写推文也找它,做分析还是找它。就像一个人同时当 CEO、CTO 和 CMO,不是不行,但效率和质量都上不去
如果把一个全能 Agent 拆成四个专精 Agent,各司其职,再通过 MemOS 让它们共享记忆,会发生什么?我在一台 VPS 上实测了这套方案
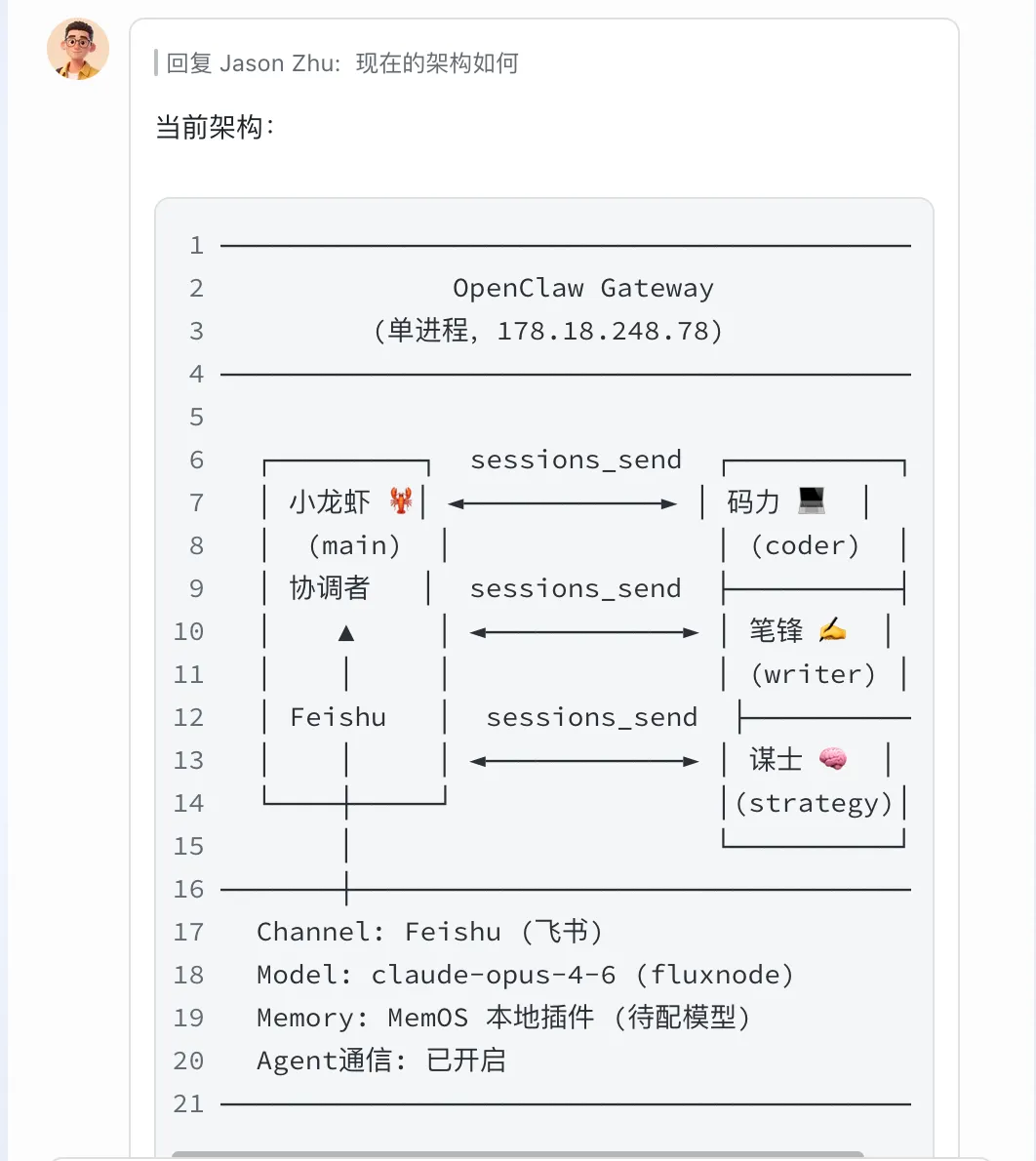
灵感来自 @servasyy_ai 的龙虾4兄弟。整个系统跑在 OpenClaw 上,一个 Gateway 进程管理4个 Agent
🦞 小龙虾(main)用 claude-opus-4-6,负责协调调度,接飞书消息,拆任务分发。贵的模型给最需要判断力的环节
💻 码力(coder)用 gpt-5.3-codex,全栈工程师。编码任务对文笔没要求,能跑就行,走免费额度
✏️ 笔锋(writer)用 claude-opus,首席内容官。写作质量直接影响产出,这个不能省
🧠 谋士(strategist)用 gpt-5.4,策略顾问。审稿分析复盘,免费模型实测够用但响应慢
核心思路就一句话:贵的模型只给最需要质量的环节,其他尽量白嫖
搭建过程:每个Agent有自己的人格
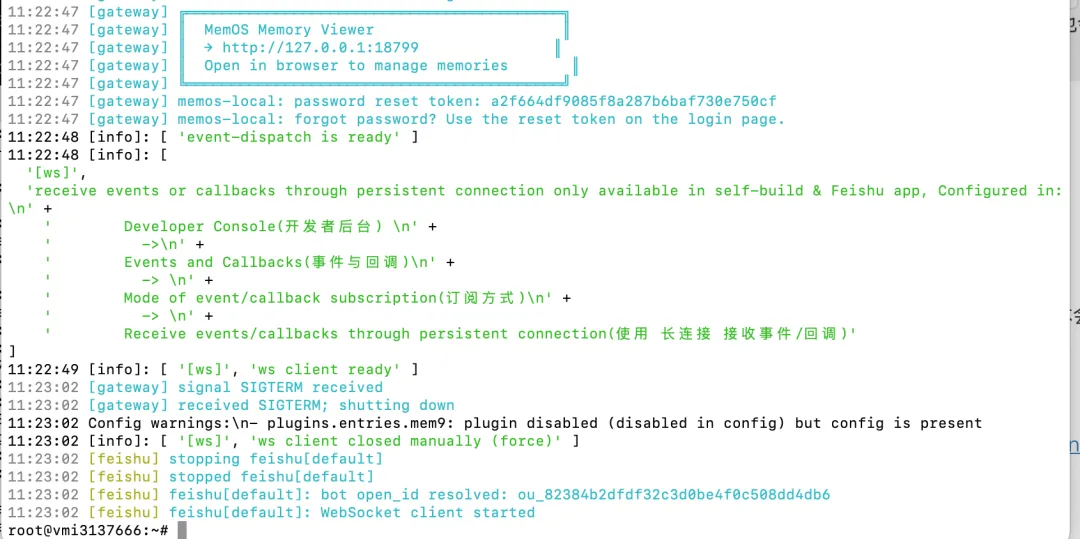
第一步是定义 Agent。每个 Agent 有独立的 SOUL.md 和 AGENTS.md。比如笔锋的人格设定是"语感好、对假大空天然反感",这比通用 prompt 有效得多。写出来的东西确实更有调性
第二步打通通信。通过 agentToAgent: true 和 sessions.visibility: all 开启互通。飞书收到指令后,小龙虾判断该交给谁,直接 sessions_send 派活
流程就是:我(飞书)→ 小龙虾 🦞 → 笔锋 ✏️ / 谋士 🧠 / 码力 💻
MemOS 记忆系统:让四只虾越用越聪明
这是整套方案最有意思的部分。安装 MemOS 本地插件后,记忆系统分三层模型分级
Embedding 用本地离线的 Xenova,零成本不调 API。Summarizer 用 MiniMax-M2.5,便宜到几乎免费。Skill Evolution 偶尔触发时才调 Opus
OpenClaw 记忆面板跑在 18799 端口,通过 Gateway 的本地 token 控制权限。只需要 openclaw.json 里 gateway.auth.token 的后四位就行
团队共享:MemOS Hub架构打通记忆
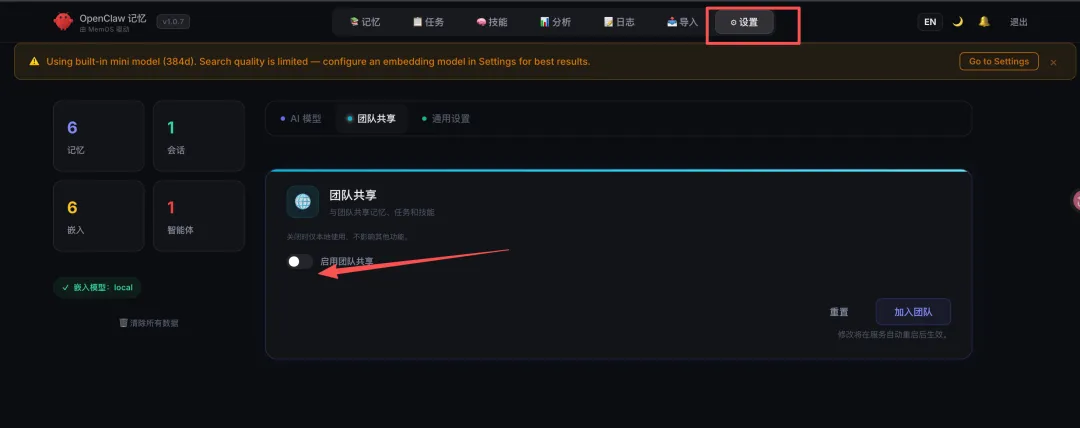
默认情况下每个 Agent 各记各的。通过 MemOS 的 Team Sharing 功能可以打通
MemOS Hub:一个 Hub 存共享数据,各 Agent 作为 Client,开启后有三个核心能力
task_share 把某个任务的记忆共享给其他 Agent
skill_publish 把自己学会的技能发布给团队
MemOS Hub让共享数据集中管理
在记忆面板的设置功能下打开团队共享就行
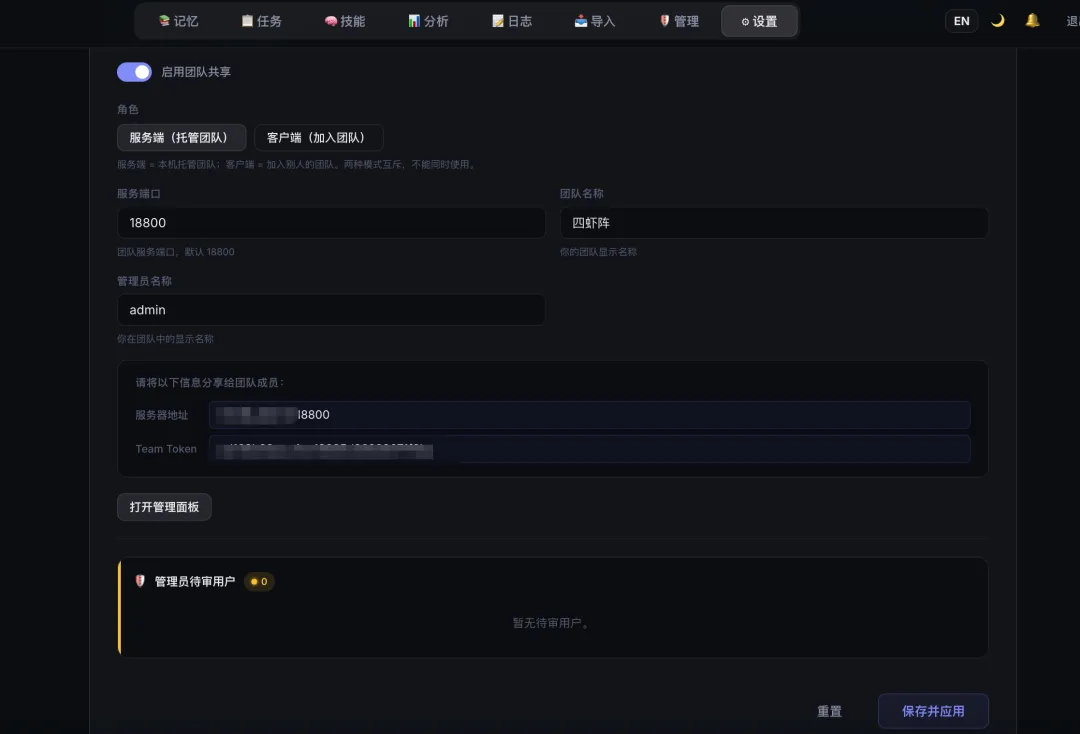
共享记忆之后,跨 Agent 复用信息的成本极低。笔锋学会的写作套路谋士也能参考,小龙虾记得每个 Agent 的能力边界
实战数据:写→审→改全流程

说再多不如跑一遍。给了一个真实任务:写一条推文,杰森AI出海风格
谋士给笔锋的初稿打了 8.2/10,建议是把 hook 前置,把"能跑"变成"能解决问题"。这就是多 Agent 协作的价值:写手负责产出,策略负责把关,协调者负责流转
日常运行状态下只有小龙虾在持续消耗(因为要接飞书消息做调度判断),其他三个 Agent 都是按需唤醒。日常成本:一杯咖啡钱都不到
踩过的坑
免费模型响应慢,GPT-5.4 大概5分钟。解决方案是 fire-and-forget + 异步回传。小龙虾把任务派出去就不等了,谁先做完谁主动汇报
改 agentToAgent 必须重启 Gateway 才生效。不是 bug 是设计如此,第一次搞的时候排查了好一会儿
给码力的任务描述写得太短,出来的脚本就是最简版。多 Agent 协作不代表你可以偷懒写 prompt,每个 Agent 的输入质量决定输出质量
你不需要先有团队。很多时候你只需要先有一个能分工的虾队
MemOS 开源地址:https://github.com/MemTensor/MemOSOpenClaw 开源地址:https://github.com/openclaw/openclaw
