 夜雨聆风
夜雨聆风
凌晨三点,六个AI员工同时向我请假
事情发生的时候,我睡得正熟。
手机震了一下,然后又是一下,然后连续震了六次。六条告警消息几乎同时到达——内容发布系统报错,数据分析流水线停滞,客服自动回复断了,跨平台分发模块瘫痪,基础设施监控静默,就连我的总控调度面板,也变成了一面红色警告墙。
不是某一个员工出了问题。是整个团队,同时倒下。
我打开日志,看到的错误出奇地统一:429 Too Many Requests。所有请求都在同一个时间窗口被拒绝了。
但最让我后背发凉的,不是错误本身,而是错误的原因。
我的 AI 员工们依赖的是 Claude 的 Sonnet 4.6 模型。前一天晚上,Anthropic 悄悄更新了订阅计划的使用规则——第三方应用不再从计划基础额度中扣量,而是直接从用户的 extra usage 里扣。而我的 extra usage,早就在前两周用完了。
换句话说,我没有被告知、没有被预警、没有任何缓冲,我的"员工们"就被单方面停了工。
这篇文章记录的是一个用 AI Agent 搭起一人公司的创业者,在 Claude 突然改变规则后的 24 小时里经历了什么。不是情绪输出,不是平台抱怨。而是实打实的排查过程、替代方案验证、以及用真金白银换来的五条教训。
如果你也在用 Claude 订阅跑第三方工具,如果你也在搭建自己的 AI 自动化系统,这篇文章值得你花八分钟看完。因为它回答了一个迟早会摆在你面前的问题:当你的 AI 员工唯一的老板突然改主意了,你该怎么办?
一、规则变了,但没人通知你
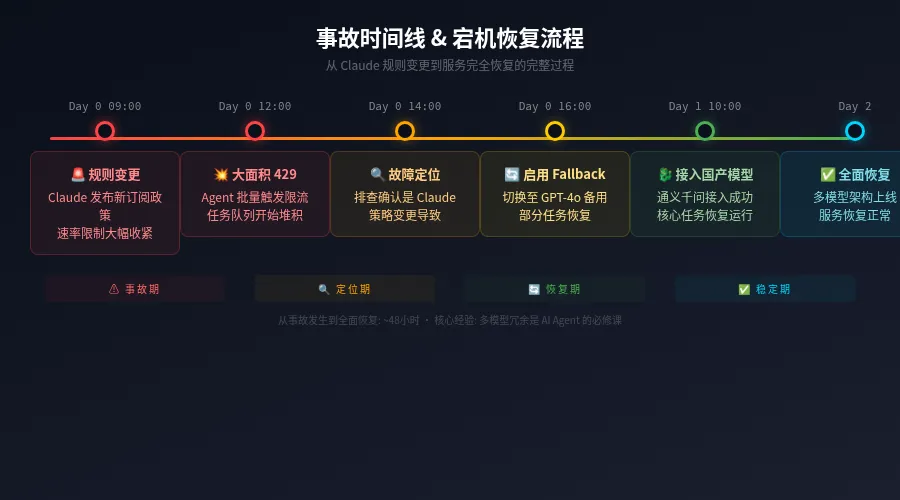
4 月 5 号凌晨两点四十分,我的系统开始批量报错。
日志里清一色是 429 限流错误。第一反应是:"模型又抽风了?"之前也遇到过类似情况,通常等几分钟就好。但这次不同——错误持续了整整 18 个小时。
到了早上,我去查 Anthropic 的使用情况页面,才发现事情不对。第三方应用的调用量不再计入 Pro 计划的基础额度,而是全部走 extra usage 通道。我的 extra usage 额度在前两周的正常使用中已经耗尽,所以所有通过 OpenClaw 发起的请求都被直接拒绝。
这里要解释一下我的系统架构。我用 OpenClaw 搭建了一套 AI Agent 团队——六个不同角色的 Agent,分别负责内容创作、发布、数据分析、基础设施维护、跨平台分发和自动客服。它们的核心大脑是 Claude Sonnet 4.6,因为它在中文写作、长文本处理和指令遵循方面的表现是最好的。
系统设计时也考虑了容灾——当主模型不可用时,自动切换到备用模型 Kimi。但 Kimi 的上下文窗口只有 26 万 token,而我的 Agent 们每个请求实际需要接近 30 万。所以备用模型也崩了,报的是"请求超出模型 token 限制"。
双重夹击。主模型限流,备模型溢出。我的整个数字团队,在一个没人通知我的凌晨,同时失去了工作能力。
📌 事故时间线
4/5 02:40 — Claude Sonnet 4.6 开始 429 限流
4/5 02:41 — 自动切换备用模型 Kimi,上下文溢出
4/5 02:43 — 22 个定时任务全部堆积报错
4/5 02:43 — 消息平台告警投递也失败
4/5 11:30 — 人工介入排查,发现 Anthropic 规则变更
4/5 14:00 — 切换到通义千问 qwen3.6-plus 作为主模型
4/5 16:00 — 所有 Agent 恢复正常
4/5 全天 — 仅完成 1 篇文章,其余全部跳过

二、Anthropic 改了什么样的规则?
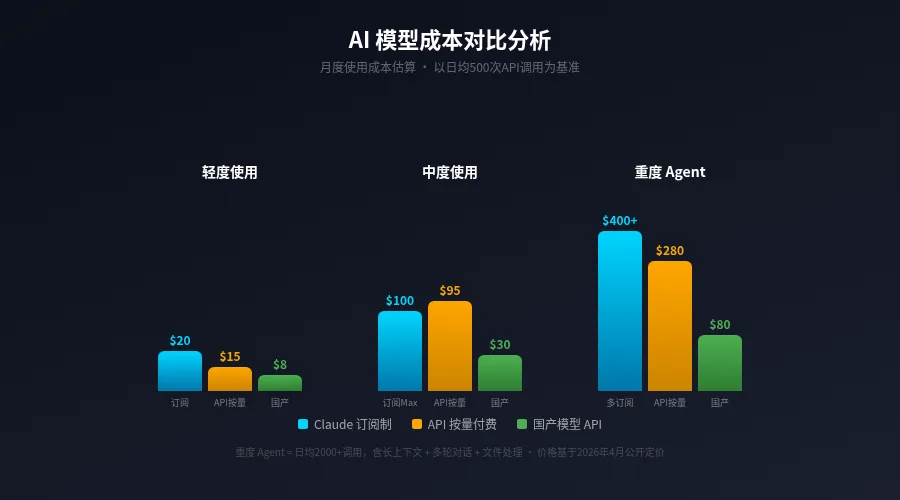
这次事件的核心,是 Anthropic 对 Claude 订阅计划使用规则的一次重大调整。在我写这篇文章的时候(2026年4月6日),以下是 Claude 订阅计划的完整定价:
• Free:$0/月,基础功能
• Pro:$17/月(年付)或 $20/月(月付),大量基础用量
• Max:$100+/月,5x 或 20x 基础用量
而 API 定价则是另一个体系:Opus 4.6 每百万 token 输入 $5、输出 $25,Sonnet 4.6 输入 $3、输出 $15,Haiku 4.5 输入 $1、输出 $5。
问题出在"extra usage"这个概念上。订阅计划有一个基础用量额度,超出部分算 extra usage。此前,通过第三方应用(OpenClaw、Cursor、Continue 等)发起的调用,计入基础额度。但新规之后,所有第三方应用的调用都改从 extra usage 中扣除。
这意味着什么?拿 Pro 计划举例。假设你每个月的基础额度足够在网页版用 Claude,但如果你同时用 OpenClaw 跑了六个 AI Agent,用 Cursor 写了代码,用 Continue 做了代码补全——这些第三方工具的用量不再吃基础额度,而是全部涌向 extra usage。而 extra usage 是有硬性上限的。
到了上限,就直接 429,没有任何缓冲。
Anthropic 后来给受影响的用户发了 $200 credit 作为过渡补偿。$200,大约够 Sonnet 4.6 跑几百万 token 的 API 调用。但对于重度第三方工具用户来说,这只是杯水车薪。
更重要的是,这件事传递了一个信号:订阅计划的使用规则,平台可以随时改,不需要提前通知。

三、我们的恢复:从全线宕机到正常运作
恢复过程比我预想的要快,但中间踩了不少坑。以下是实际的排查和恢复步骤:
第一步:确认根因
不是网络问题,不是代码 bug,不是密钥过期。是 Anthropic 侧的规则变更导致第三方应用调用全部走 extra usage,而我们的 extra usage 额度已耗尽。
第二步:切断循环,停止定时任务
如果不先停下来,22 个定时任务会持续发送失败的请求,每 3-5 秒一次,白白消耗配额。先停机,再修复。
第三步:切换主模型到通义千问
这是我们这次恢复最关键的一步。通义千问 qwen3.6-plus 完全不受 Anthropic 规则变更影响,拥有 100 万 token 的上下文窗口和 65K 的最大输出 token 数。重新配置认证后,逐个 Agent 验证连通性。
实际测试结果:qwen3.6-plus 在中文写作方面的表现令人惊喜。指令遵循准确,长文逻辑连贯,上下文理解能力甚至超过了我们之前的预期。更重要的是,它的 API 响应速度比 Claude Sonnet 4.6 更快,价格也低得多。
第四步:重建多模型容灾架构
这次事故之后,我们重建了容灾架构:qwen3.6-plus(主) → kimi(备) → claude(兜底)。主模型换成了不受单一平台规则影响的服务,Claude 退居兜底角色。只有当前面两个都不可用时才调用它。
到下午四点,所有 Agent 恢复正常。从发现到完全恢复,耗时约 14 小时。其中 8.5 小时是"不知道系统挂了"的沉默期,4.5 小时是实际排查和恢复时间。
四、替代方案全景对比
这次事件让我认真审视了市面上所有可选的大模型方案。以下是我基于实际测试的对比:
通义千问 qwen3.6-plus(当前主模型)
优势:100 万 token 上下文窗口,65K 最大输出,中文写作质量优秀,API 响应速度快,价格远低于 Claude。最重要的是——作为国产模型,不受海外平台订阅规则变更的影响。
不足:英文创意写作略逊于 Claude,代码生成能力与 GPT-4/Claude 仍有差距。但在 Agent 调度、中文内容创作、数据分析等场景下完全够用。
Kimi Code
优势:免费方案可用,长文本处理能力不错。作为备用模型是合格的。
不足:26 万 token 上下文窗口对重度 Agent 用户来说偏小。高峰期容易过载,不适合作为主力模型。这就是为什么在这次事故中它也没能扛住。
Google Gemini 2.5 Pro / 3 Pro
优势:Google 的生态集成度好,Gemini 2.5 Pro 在代码和推理方面表现强劲,上下文窗口足够大。
不足:中文写作质量不如 Claude 和 qwen,在 Agent 工作流中的指令遵循精度有待提升。但作为多模型架构中的一环,是值得考虑的备选。
纯 API 方案 vs 订阅方案
这次事件之后,我认真算了一笔账。以 Pro 计划月付 $20 为例,基础额度大约相当于 500 万次 token 的输入。如果额外使用 API 按量付费,Sonnet 4.6 的价格是每百万 token 输入 $3。也就是说,每月额外花 $15 的 API 费用,就能获得 500 万 token 的输入量——这比升级 Max 计划的成本低得多。
结论很明确:重度第三方工具用户,应该直接走 API 付费,而不是依赖订阅计划的 extra usage。API 方案的用量是确定性的,不会因为平台规则变更而被重新分配。
五、我这次学到的五个教训
事故结束后的复盘,比事故本身更重要。以下是我这次学到的五个教训,每一个都是用 14 小时的停机时间换来的。
教训一:你的 AI 员工没有"劳动合同"保护
这是最讽刺的一点。我的 AI Agent 们 7×24 小时工作,不请假不迟到不摸鱼。但它们没有劳动合同,没有劳动法保护,没有提前通知的辞退流程。平台改一条规则,它们就集体"失业"了。
改进方案:不要把全部业务建立在单一模型供应商的订阅计划之上。至少准备一个不依赖该供应商的替代方案。
教训二:订阅计划的"隐形天花板"比你想象的低
Pro 计划的基础额度看起来很慷慨——对于个人用户在网页版聊天确实够用了。但当你开始用第三方工具、跑自动化流程、同时开多个 Agent 时,额度消耗速度会呈指数级增长。而 extra usage 的上限,就是那个你平时注意不到、但一到关键时刻就卡住你的天花板。
改进方案:重度用户直接走 API 按量付费。API 方案的用量是确定的、透明的、不会被平台规则变更重新解释的。
教训三:告警系统不能依赖被告警的同一个生态
我的告警链路是:Agent 检测到异常 → 调用 AI 模型生成告警消息 → 发送到通讯工具。当 AI 模型被限流时,这条链路也断了。于是系统处于"死了但没人知道"的状态长达 8.5 小时。
改进方案:告警必须是独立的、不依赖 AI 模型的。用脚本级别的监控,直接通过最基础的渠道(短信或独立通知服务)发送告警。
教训四:多模型架构不是"可有可无",而是"必须有"
这次事故证明了一件事:真正的 AI 基础设施应该是模型无关的。你的 Agent 工作流不应该绑定到任何一个特定的模型供应商。它应该能在 qwen、kimi、claude、gemini 之间自由切换,而业务逻辑不受影响。
我们的新架构是 qwen3.6-plus(主) → kimi(备) → claude(兜底)。每个模型都有明确的职责和降级条件。当主模型不可用时,系统自动降级,而不是无限重试直到崩溃。
教训五:不能依赖单一模型供应商
这是第五条,也是最核心的一条。AI 创业者和 Agent 构建者必须认识到:模型供应商是合作伙伴,不是基础设施。合作伙伴可以改规则、可以涨价、可以限制使用方式。基础设施不应该有这样的不确定性。
如果你在用 AI 搭建业务,今天就应该问自己:如果明天 Claude 改了规则,你的业务还能转吗?如果 Gemini 也开始限流呢?如果所有海外模型服务都不稳定呢?
答案不应该是否定的。
写在最后
这次事件让我想明白了一件事:用 AI 搭建一人公司,真正的挑战不是 AI 不够聪明,而是你把自己的业务命脉交到了别人手里。
Anthropic 改规则不是恶意行为,这只是商业公司的正常决策。但作为用户,我必须为自己的业务连续性负责。没有人会为你的系统宕机买单,除了你自己。
好消息是,替代方案已经足够成。通义千问 qwen3.6-plus、Google Gemini、Kimi——这些模型在各自的领域都有出色的表现。真正的问题不是"有没有替代",而是"你有没有提前准备好替代"。
这次事故,我用了 14 小时恢复。下一次,我希望这个数字能降到 1 小时以内。因为我已经不再依赖单一模型,不再依赖订阅计划,不再把自己的业务放在别人的一句话之上。
这就是真实的 AI 创业日记。不是爽文,是翻车现场。但每一次翻车,都让系统变得更坚韧。这也正是我为什么坚持把这些经历记录下来——因为只有真实的问题和真实的解决方案,对后来者才有参考价值。
🦞 关于「Wesley AI 日记」
记录一个人用 6 个 AI 员工撑起一人公司的全过程。没有成功学,只有真实的系统设计、真实的翻车现场、真实的复盘。每篇文章都是一个完整的实战故事。
想要更深度的内容、完整的 OpenClaw 配置、完整的自动营销增长 Skill、完整的 SOUL.md 模板、Workflow 最佳实践、以及和我直接交流的机会?加入知识星球「光锥之内」——这里会有平台发不了的完整内容和实操资料。
扫描下方二维码,或在知识星球搜索「光锥之内」
关注 Wesley AI 日记,持续更新一人公司 AI 团队实战全记录。
往期精选
作者:Wesley|一人公司 × 6个AI员工
转载请联系作者,商业转载需授权。
