 夜雨聆风
夜雨聆风【导读】Z.ai发布开源模型GLM-5.1,754B参数、MIT协议全开源。在SWE-Bench Pro上以58.4分登顶全球第一,综合编程基准开源第一、全球第三。更震撼的是:这个模型能连续自主编程8小时,通过数千次迭代越跑越好——在向量数据库优化任务中,它跑了600多次迭代、6000多次工具调用,性能暴涨了整整6倍。
一条推文引爆AI圈:开源第一,全球第三
4月7日,Z.ai官方博客悄悄上线了一篇文章——标题很克制:《GLM-5.1: Towards Long-Horizon Tasks》。
第二天,官推发了一条帖子,直接炸了。
"Introducing GLM-5.1: The Next Level of Open Source"
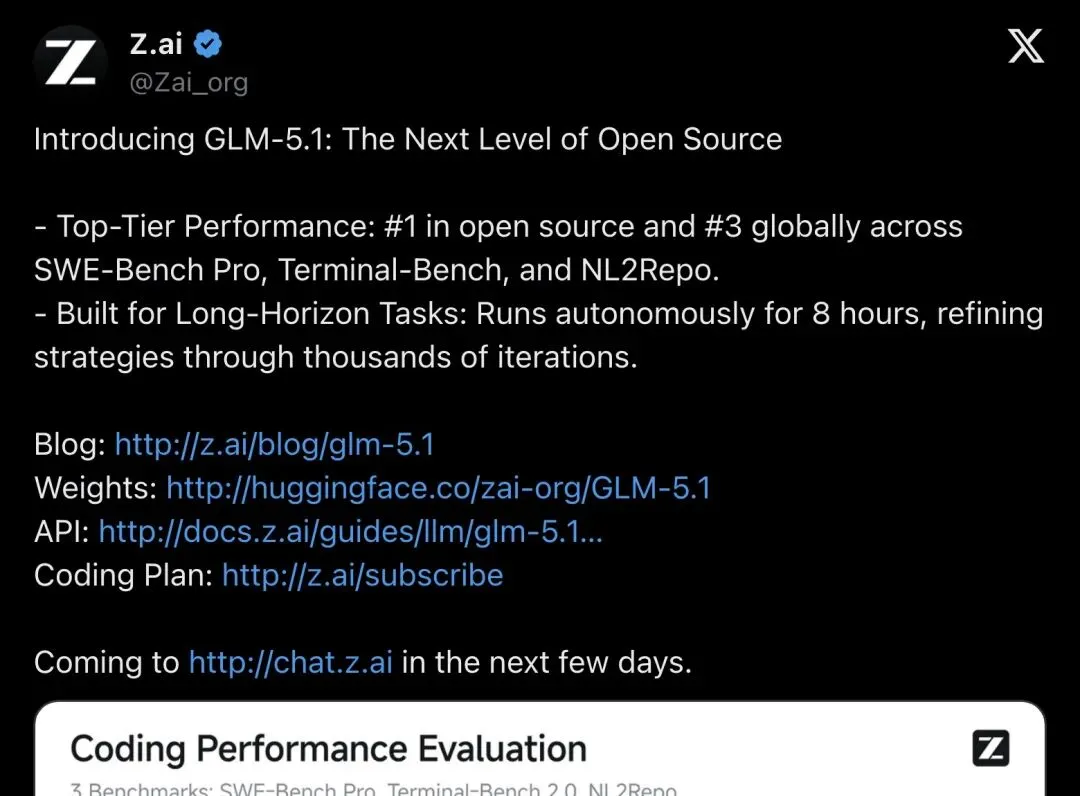
"Top-Tier Performance: #1 in open source and #3 globally across SWE-Bench Pro, Terminal-Bench, and NL2Repo."
「在SWE-Bench Pro、Terminal-Bench和NL2Repo上,开源第一,全球第三。」
▲ Z.ai官方推文宣布GLM-5.1发布,近30万次浏览
推文发出后浏览量迅速突破28万,转发近两千。
但真正让人坐不住的,是后面那句:
"Built for Long-Horizon Tasks: Runs autonomously for 8 hours, refining strategies through thousands of iterations."
「为长周期任务而生:自主运行8小时,通过成千上万次迭代不断改进策略。」
8小时。自主运行。成千上万次迭代。
你没看错。
SWE-Bench Pro登顶:58.4分力压GPT-5.4
先看硬数据。
GLM-5.1在三大编程基准上的表现:
- SWE-Bench Pro:58.4分
— 全球第一 - Terminal-Bench 2.0(Terminus-2):63.5分
- NL2Repo:42.7分
三项综合,开源模型第一、全球第三,仅次于GPT-5.4(58.0)和Claude Opus 4.6(57.5)。
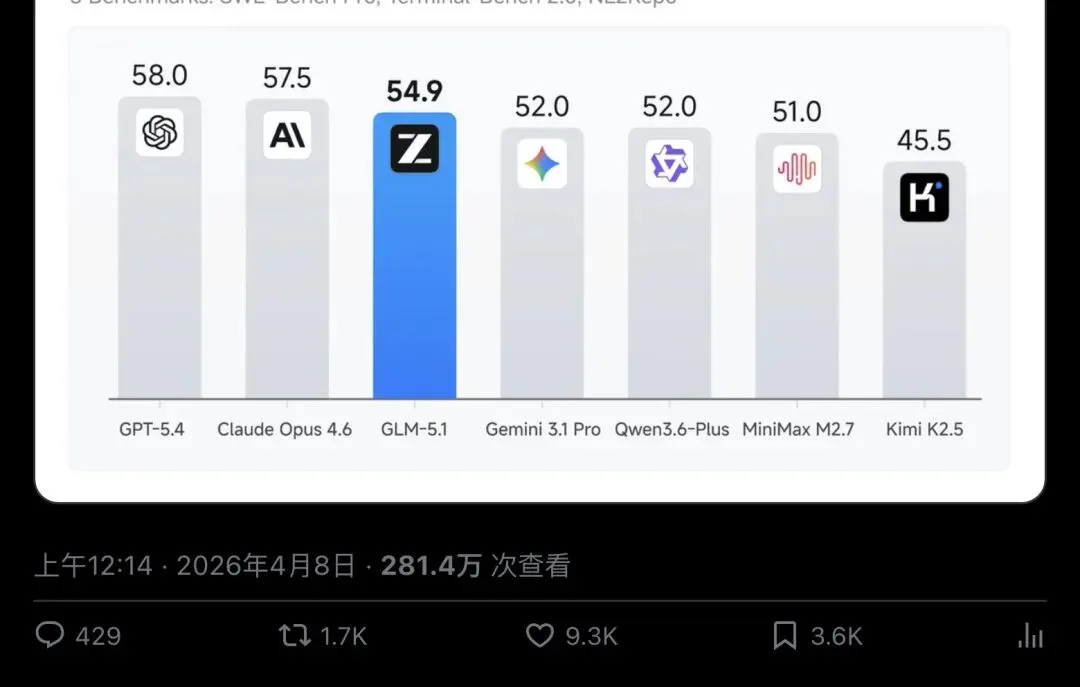
但最核心的一项——SWE-Bench Pro——GLM-5.1以58.4分登顶,力压GPT-5.4的57.7和Claude Opus 4.6的57.3。
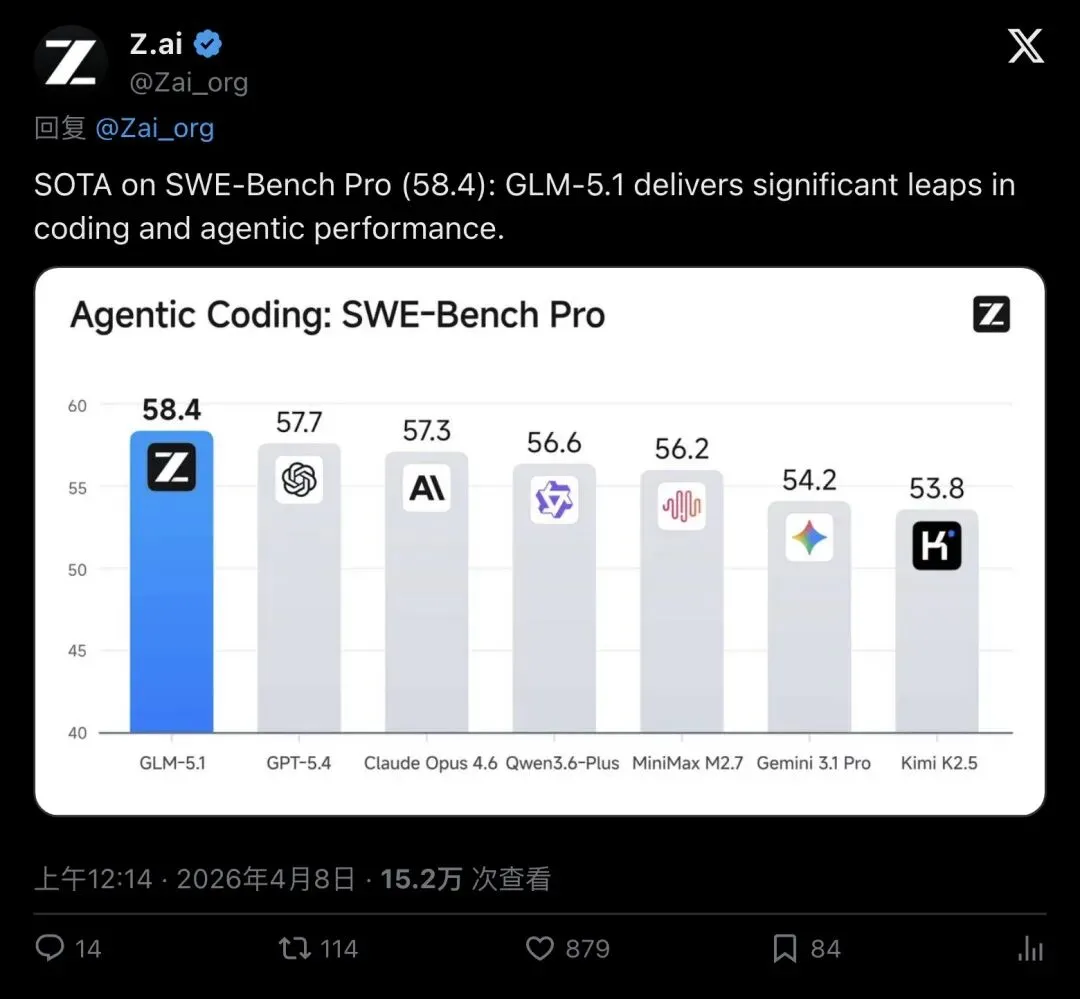
▲ SWE-Bench Pro排行榜:GLM-5.1(58.4)超越GPT-5.4(57.7),登顶全球第一
什么概念?
SWE-Bench Pro测的是真实软件工程任务——从真正的代码仓库里挑出bug让模型去修。这是目前公认最接近实际工程能力的编码基准。
而一个MIT开源模型,在这项基准上把所有闭源巨头踩在了脚下。
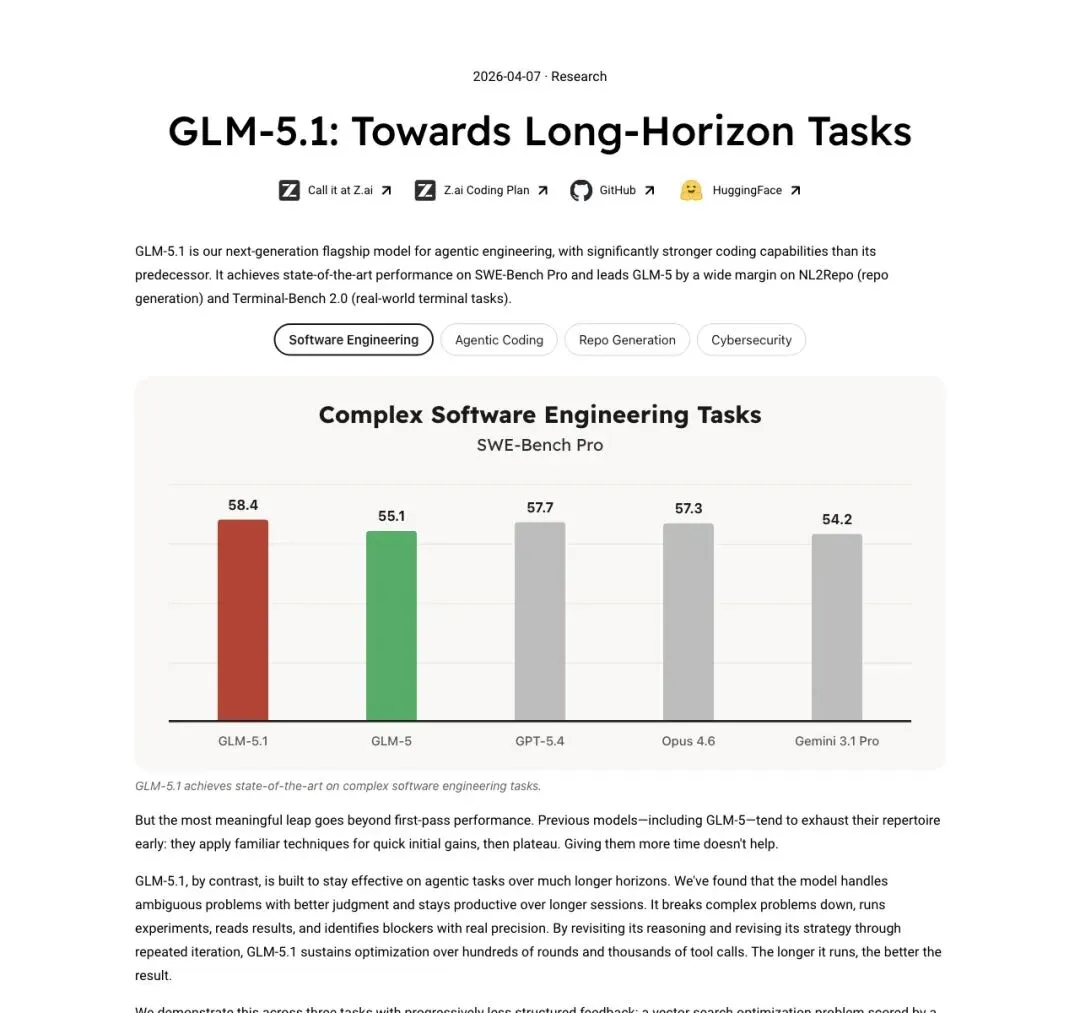
▲ Z.ai博客图表:GLM-5.1在SWE-Bench Pro上达到SOTA,较前代GLM-5(55.1)跃升3.3分
从Hugging Face模型卡上看,GLM-5.1是一个754B参数的MoE架构模型,License写着两个大字:MIT。
商用、修改、分发——随便来。
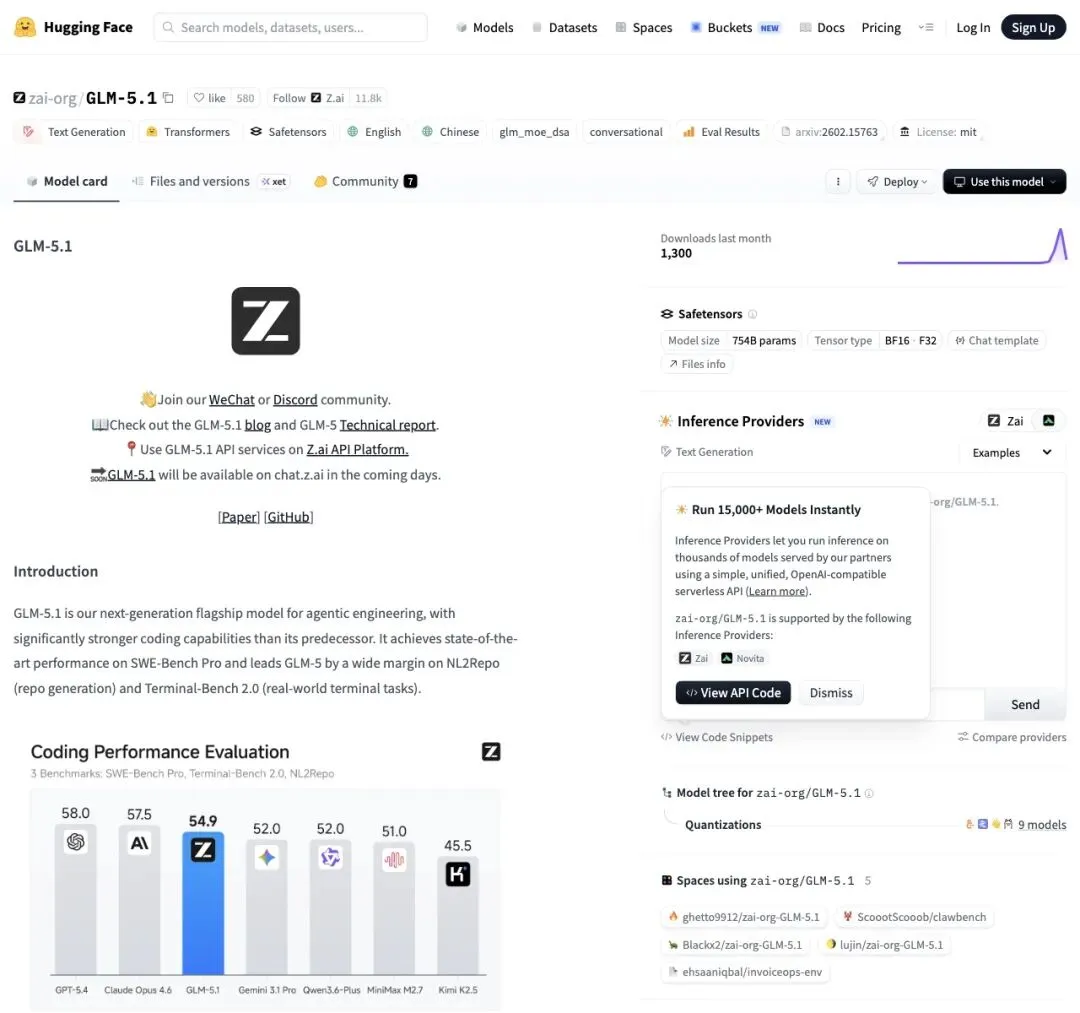
▲ Hugging Face模型卡:GLM-5.1,754B参数,MIT协议
不是更聪明,是更持久——重新定义AI写代码
数字很亮眼。但GLM-5.1真正的野心不在刷分。
传统模型怎么写代码?你给它一个问题,它给你一个答案。好不好,全看这一轮输出。写完就结束了。
GLM-5.1说:这不对。真正的工程师不是这么干活的。
Z.ai在官方博客中写了一段话,值得每个关注AI编程的人细品:
"GLM-5.1 is built to stay effective on agentic tasks over much longer horizons."
「GLM-5.1的设计目标,是在更长的时间跨度内保持代理式任务的有效性。」
"By revisiting its reasoning and revising its strategy through repeated iteration… The longer it runs, the better the result."
「通过反复审视自己的推理、修正策略……它运行得越久,结果越好。」
越跑越好。
这四个字,是理解GLM-5.1的钥匙。
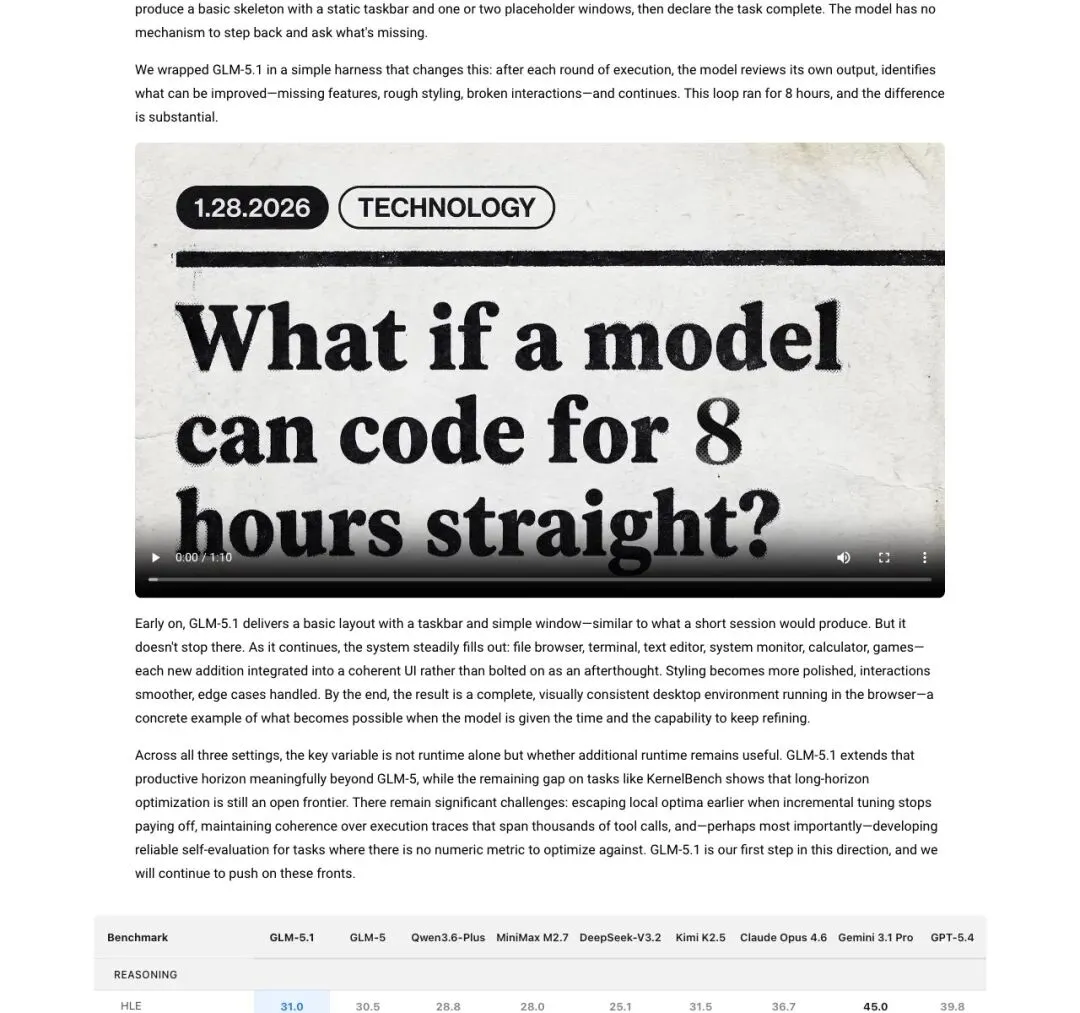
▲ Z.ai博客发出灵魂之问:"What if a model can code for 8 hours straight?"
博客详细对比了GLM-5和GLM-5.1的长周期表现:前代模型开局猛,但很快"用完招数"进入平台期——给它更多时间也写不出更好的代码。而GLM-5.1不同,它能在漫长的迭代中持续发现新的优化方向,保持有效输出。
科技博主Wes Roth在推特上的总结一针见血:
"Unlike standard conversational models, GLM-5.1 is specifically engineered for long-horizon, autonomous tasks. It is capable of running independently for up to 8 hours…"
「它不是标准对话模型。GLM-5.1是专门为长周期自主任务打造的,能独立运行长达8小时……」
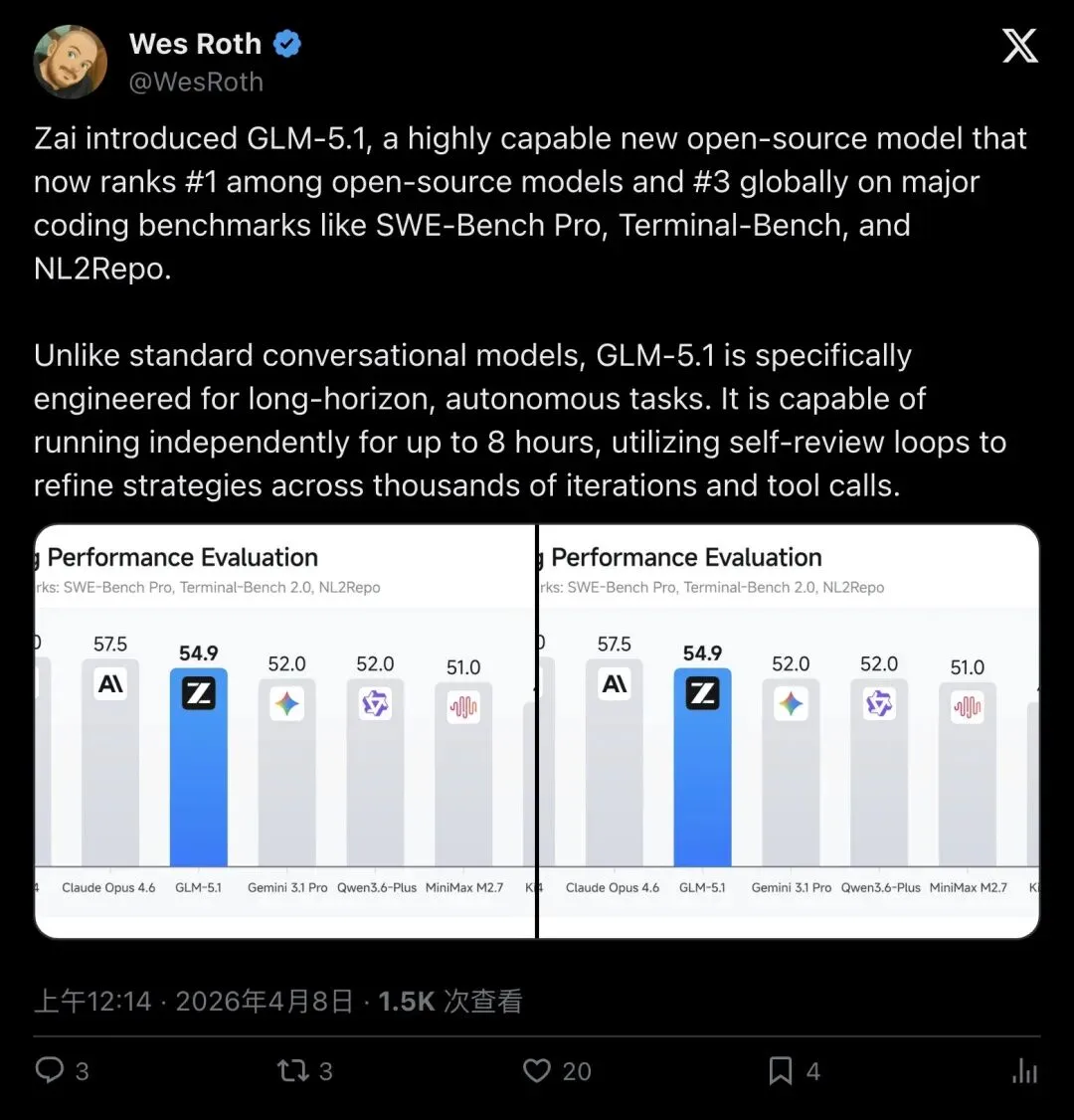
▲ Wes Roth评价GLM-5.1:专为长周期自主任务设计,能独立运行8小时
600次迭代、6000次调用:向量数据库性能飙升6倍
光喊"越跑越好"当然不够,得拿案例说话。
Z.ai给出了一个极具说服力的实战验证:VectorDBBench——向量数据库性能基准测试。
原始任务设定:50轮工具调用预算的代理编程挑战,在Recall≥95%的条件下比拼QPS(每秒查询数)。普通模型跑完50轮就交卷了。
GLM-5.1怎么做的?
它在外层套了一个持续优化循环——跑了600多次迭代、发起6000多次工具调用——最终将QPS推到了21.5k。
这是什么水平?大约是单次50轮会话最优结果的6倍。
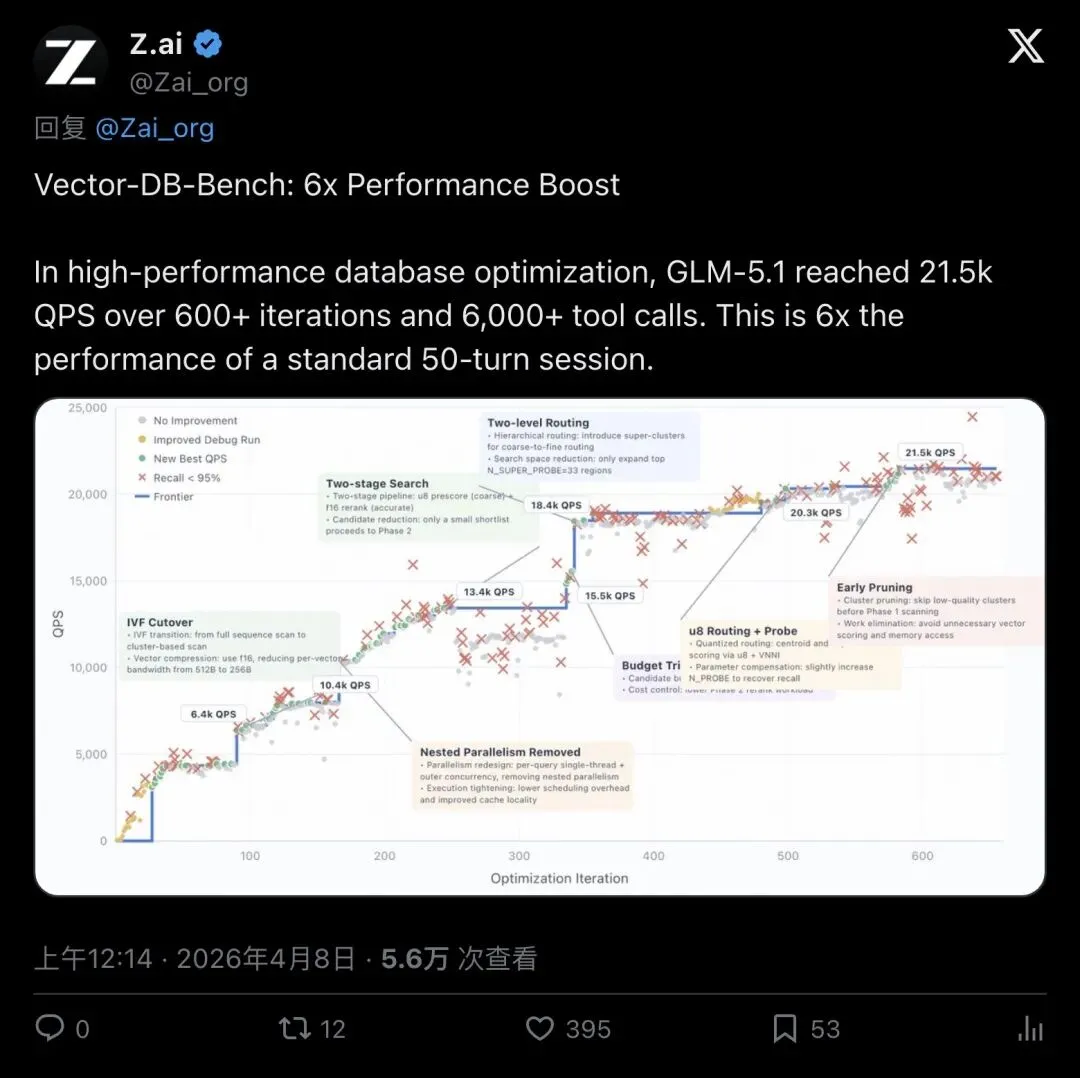
▲ VectorDBBench优化曲线:从几千QPS一路飙升到21.5k,600+迭代、6000+工具调用
看那条优化曲线——充满了锯齿状的探索和突破。Two-stage Search、Budget Tri、Early Pruning……模型在不断尝试不同策略,就像一个资深工程师在profiling、定位瓶颈、反复调优。
尝试-失败-换策略-突破-再尝试。
这才是真实工程优化的样子。
8小时从零搭建Linux桌面:全程无人干预
另一个案例更加直观。
Z.ai让GLM-5.1用self-review loop(自我审阅循环)连续运行8小时,从零开始构建一个Linux风格的桌面Web应用。
模型从一个基础骨架出发,每一轮自动审查产出、识别缺陷、规划改进——功能、样式、交互逻辑,一步步迭代完善。
▲ GLM-5.1用self-review loop跑了8小时,从零构建出功能完整的桌面环境
Z.ai在博客里解释:网站和应用类任务没有单一评价指标,"好不好"更主观,难点在于模型能否自己发现问题、自己决定怎么改。
8小时后,一个包含任务栏、窗口管理、多应用交互的桌面环境被完整构建出来。
全程零人类干预。
社区炸锅:量化、硬件、第三方认证,全跟上了
GLM-5.1发布后,开源社区的响应速度堪称闪电。
量化团队第一个冲上来。Unsloth在模型发布仅25分钟后就放出了Dynamic GGUF量化版本,方便有算力的开发者本地跑。
▲ Unsloth火速跟进,提供GLM-5.1 GGUF动态量化版本
硬件需求查询紧随其后。RunThisLLM网站第一时间更新了GLM-5.1的配置需求——毕竟754B参数的MoE模型,不是随便一台机器能带的。
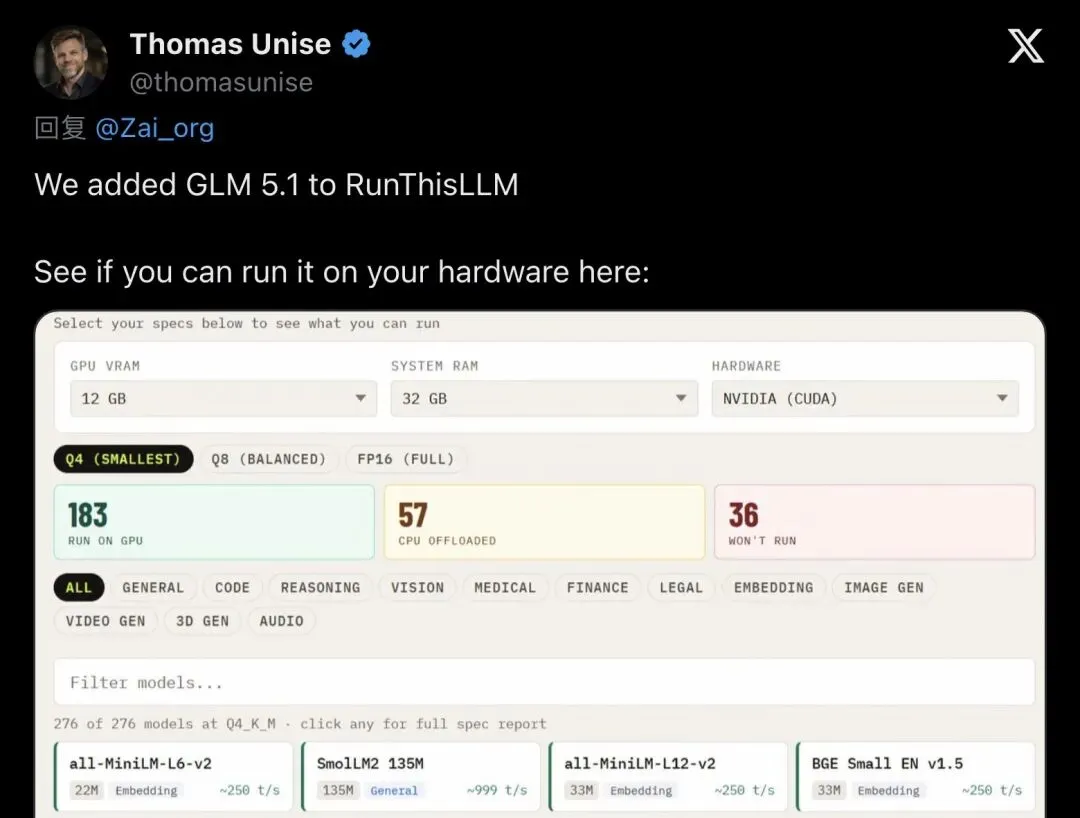
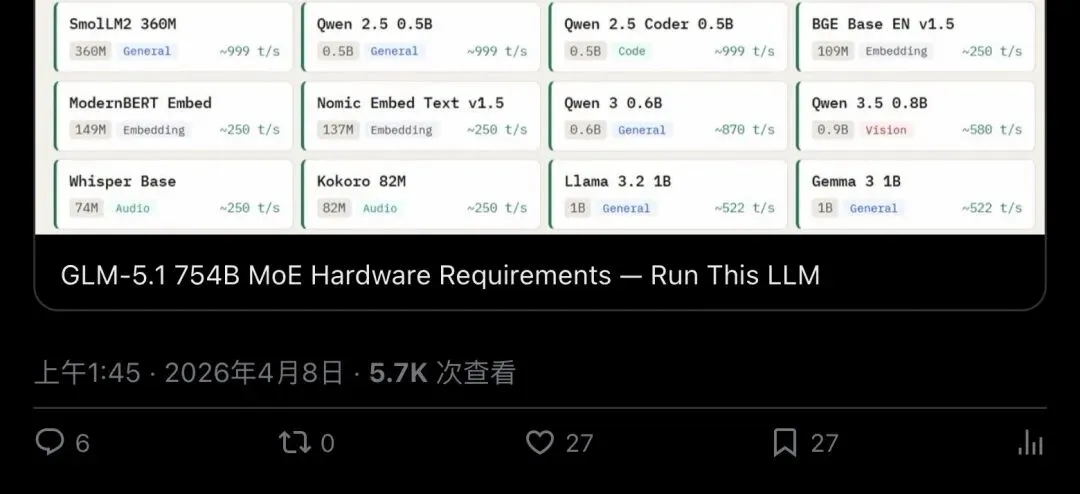
▲ RunThisLLM加入GLM-5.1:754B MoE的硬件需求一目了然
第三方评测平台也迅速给出了认证。Vals AI直接在开放权重类别中给GLM-5.1打上了"State of the Art"的标签。

▲ Vals AI将GLM-5.1评为开放权重类别的State of the Art
AI编程的竞争维度,变了
GLM-5.1发出的信号非常明确:AI编程的竞赛规则正在被改写。
过去,所有人比的是"谁一次性写出更好的代码"。现在,竞争转向了一个更真实、更硬核的维度——谁能在长周期任务中持续保持有效?
没有哪个程序员看一眼需求就能写出完美代码。真实工程是一个不断迭代、试错、profiling、优化的漫长过程。
GLM-5.1正在学会用这种方式工作。
当然,需要保持清醒:
- "开源第一、全球第三"是官方口径
,基于SWE-Bench Pro、Terminal-Bench、NL2Repo三项综合,具体的综合方法与权重,官方未详细公开 - 8小时连续运行是展示案例
,真实落地还要面对工具链稳定性、环境一致性、算力成本等现实问题 - 754B的MoE模型
,本地部署的硬件门槛不容小觑
但有一个事实无法否认:一个MIT协议的开源模型,在SWE-Bench Pro上打败了GPT-5.4和Claude Opus 4.6。
仅这一条,就足以让所有人重新审视开源与闭源之间的力量格局。
"The longer it runs, the better the result."
它运行得越久,结果越好。
当AI从"一轮对话"走向"八小时持续工程"——也许,这才是AI编程真正该去的方向。
— END —
