 夜雨聆风
夜雨聆风
告别云端拥堵!云边协同算力调度:让 AI 从 "延迟卡顿" 到 "毫秒级响应" 的实战密码
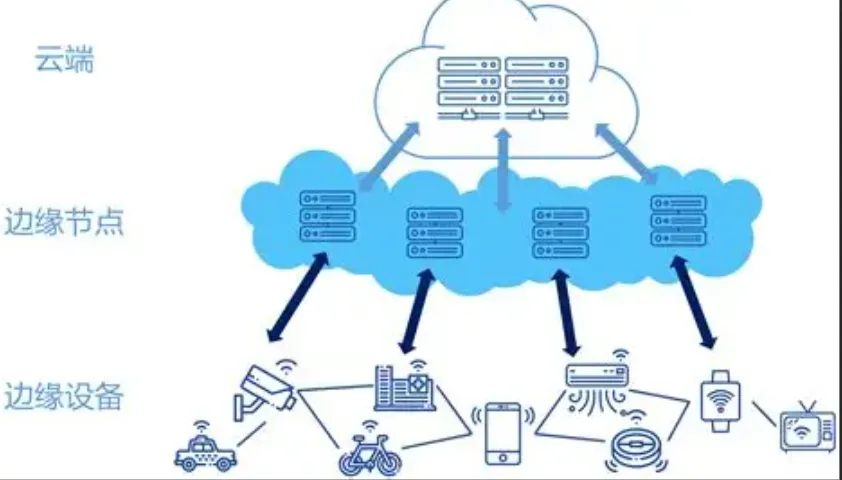
当工业机器人的控制指令因云端延迟慢了 0.1 秒、自动驾驶的避障决策因算力排队错过最佳时机、智慧工厂的质检 AI 因网络波动全线卡顿 —— 你会发现,传统中心化云计算的 "算力瓶颈",正成为智能时代最致命的短板。云边协同算力调度,不是技术概念,而是让 AI 落地从 "实验室理想" 走向 "现场实用" 的核心命脉。2026 年,边缘算力占比已从 15% 飙升至 35%,"云端训练 + 边缘推理 + 终端交互" 的三层架构,彻底重构了算力分配的底层逻辑。
一、传统算力模式:三大死穴,卡死智能落地
1. 延迟死穴:千里之外的算力,救不了近火
纯云端架构下,所有数据必须回传数据中心处理。某汽车零部件工厂实测:焊接机器人每秒产生 500 + 条传感器数据,全部上传云端后,控制指令延迟达320ms,直接导致产线良品率下降 3%。自动驾驶场景更残酷:紧急制动的决策延迟每增加 10ms,事故率上升 17%—— 云端算力再强,也抵不过 "物理距离" 的致命延迟。
2. 成本死穴:带宽与算力,双重烧钱
海量 IoT 设备实时回传数据,让骨干网带宽不堪重负。一家中型智能制造企业,仅设备数据上传的月均带宽费就超 40 万元;同时云端 GPU 集群 7×24 小时满负荷运转,算力利用率却不足 40%——大量资源浪费在 "无效传输" 与 "空载等待" 中。
3. 稳定性死穴:断网即瘫痪,离线即失效
矿山、深海、偏远厂区等网络不稳定场景,纯云端架构一旦断联,所有智能业务立即停摆。某海上钻井平台曾因卫星通信中断,导致设备监控系统瘫痪 6 小时,直接经济损失超千万元 ——没有 "本地算力兜底",智能就是空中楼阁。
二、云边算力调度:三层协同,破解算力困局
1. 云端算力:做 "大脑",不做 "苦力"
云端不再处理琐碎实时任务,专注三大核心:大规模模型训练、全局数据聚合、复杂决策优化。比如训练千亿参数大模型、分析全国工业设备运行大数据、制定跨区域供应链调度策略 —— 用最强算力解决 "全局性、高复杂度、非实时" 问题,算力利用率从 40% 提升至 80%。
2. 边缘算力:做 "手脚",毫秒级响应
在车间、路侧、厂区部署边缘节点(如浪潮 EIS860、华为 Atlas 800),就近承接实时数据过滤、本地推理、设备协同控制。智能工厂中,边缘节点直接处理产线传感器数据,工艺参数优化延迟从 320ms 降至48ms;自动驾驶路侧单元(RSU)本地完成点云降噪、目标粗分类,紧急避障决策10ms 内响应。
3. 终端算力:做 "末梢",轻量化执行
传感器、摄像头、工业网关等终端设备,负责数据采集、基础预处理、本地指令执行。比如摄像头完成画面裁剪、传感器做信号降噪,减少 80% 无效数据上传 —— 让 "最小算力单元" 发挥最大价值。
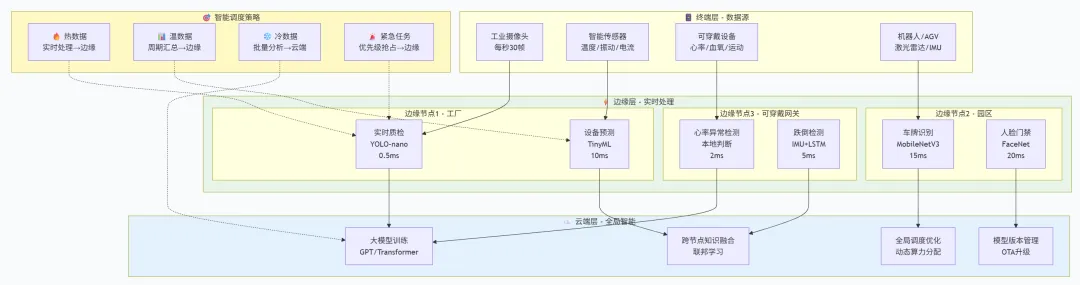
三、实战核心:智能调度算法,让算力 "按需流动"
1. 基于强化学习的动态分配(DQN-TaskSplit)
系统实时感知网络状态、算力负载、任务优先级,自动分配计算位置:
低延迟、高隐私任务(如设备控制)→ 边缘 / 终端执行 大模型、大数据任务(如全局分析)→ 云端执行 混合场景(如路径规划)→ 边缘实时决策 + 云端全局优化 某企业应用后,云端算力成本降低43%,响应速度提升6 倍。
2. 异构算力统一纳管:打破厂商壁垒
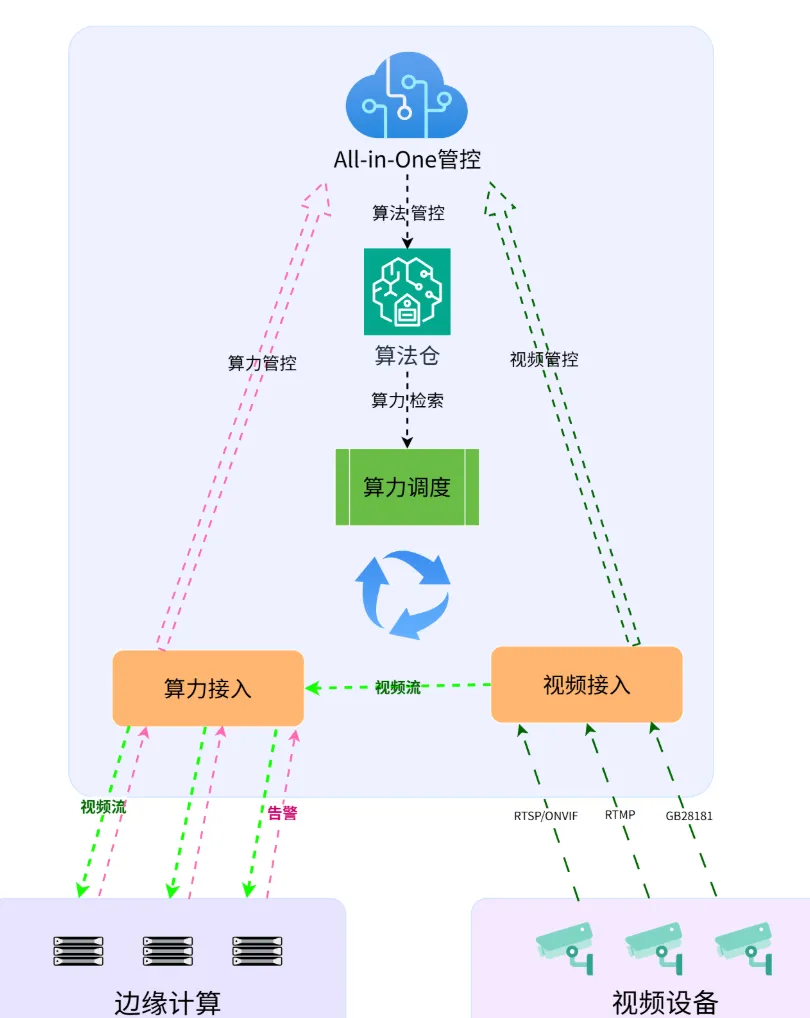
通过 "灵犀使能平台" 等技术,统一调度超 10 家厂商、70 余款异构 GPU/CPU/NPU。支持 x86、ARM、RISC-V 等多架构,可视化门户实现资源 "按需申请、自动部署、弹性扩缩"—— 低峰期自动缩容节省成本,高峰期秒级扩容应对流量洪峰。
3. 离线自治 + 断网续连:极端场景不掉链
边缘节点内置 "离线算力池",断网时本地缓存模型与数据,72 小时内独立运行;网络恢复后,自动同步任务结果与状态,无需人工干预。矿山、野外、工厂内网等场景,彻底告别 "断网即瘫痪"。

欢迎关注"AIoT智联慧讯"

免责声明 :
本文档可能含有预测信息,包括但不限于有关未来的财务、运营、产品系列、新技术等信息。由于实践中存在很多不确定因素,可能导致实际结果与预测信息有很大的差别。因此,本文档信息仅供参考,不构成任何违约或承诺。可能不经通知修改上述信息,恕不另行通知。
