 夜雨聆风
夜雨聆风一条推文、一张图,把Anthropic、OpenAI和Google同时钉在了耻辱柱上——有人指控:三大AI巨头发布新模型时故意拉满质量,然后在后续数周里悄悄"nerf"(削弱),等到下一代模型发布时,用户就会觉得"哇,进步好大"。这条推文24小时内获得超过5000赞、26万次浏览,连AI批评界的"教父"Gary Marcus都坐不住了。真相究竟如何?
那张"致命"的图
事情的起点是开发者Marcin Krzyzanowski在X上转发的一张图表。
图表标题写着"Perceived capability over time"(感知能力随时间变化),三条曲线分别代表OpenAI、Anthropic和Google。每条曲线的走势惊人地一致:新模型发布时冲到峰值,然后缓慢下滑,直到下一个新模型发布,再次冲高——形成一个又一个"锯齿形"的波峰波谷。
Krzyzanowski转发时只加了四个字:"sounds right what's happening"(听起来就是正在发生的事)。

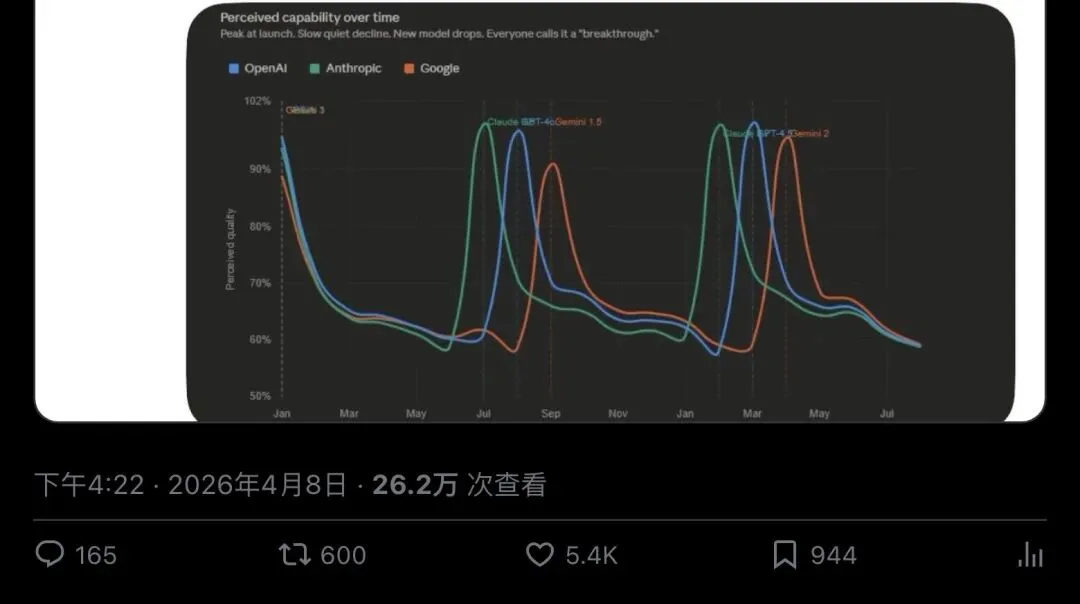
▲ Krzyzanowski的推文,附带那张"致命曲线图",5400+赞,26万+浏览
这条推文瞬间点燃了整个AI社区。
Gary Marcus下场:「图很致命,但出处在哪?」
当AI学术界最著名的"质疑者"Gary Marcus看到这张图时,他的反应耐人寻味——
"If true (and it does fit with my perceptions FWIW), this is an amazing and incredibly damning graph."
「如果为真(而且确实符合我的感受),这张图简直惊人,极具杀伤力。」
但紧接着,他问了一个关键问题:
"Can anyone find the source on which it is based?"
「有人能找到这张图的原始来源吗?」
▲ Gary Marcus:图很致命——但来源呢?
这个追问至关重要。一张没有来源的图,无论多么"符合直觉",都可能只是精心制作的阴谋论素材。Gary Marcus用一个问号,把整场讨论从"情绪宣泄"拉回到了"证据审查"。
反方开火:「证据呢?现代社会的推理还停留在'听起来对'?」
质疑声几乎同步而来。
网友Ruby直接开怼:
"Lol, so where are sources and evidence? I like how reasoning in modern society still at the level of 'sounds right'."
「笑死,证据和来源呢?我真是喜欢现代社会的推理水平——'听起来对'就行了。」
她还补了一刀:"你说benchmark没用?行。但如果模型真的变差了,benchmark一定能捕捉到。"
▲ Ruby:证据呢?"听起来对"不是证据
另一位科学家Kamil Pabis则直接给这条推文贴上了FUD(Fear, Uncertainty, Doubt,恐惧、不确定、怀疑)的标签:
"Sounds like FUD. It is a serious allegation that has been denied repeatedly by the labs and also not something I have ever noticed for myself."
「听起来像FUD。这是一项严重的指控,各实验室已经多次否认,而且我自己从来没注意到过这种现象。」
▲ Kamil Pabis:这像FUD,实验室已多次否认
Benchmark大战:到底能不能测出「偷偷变差」?
讨论很快进入了最核心的技术争议:如果模型真的在发布后被削弱,标准benchmark为什么抓不到?
网友tmuxvim抛出了一个简洁有力的问题:
"why would benchmarks not identify it, as long as you run them when the model comes out"
「只要你在模型发布时跑benchmark,之后再跑一次,为什么会发现不了?」
▲ tmuxvim:发布时跑一次benchmark,之后再跑一次,就能发现了吧?
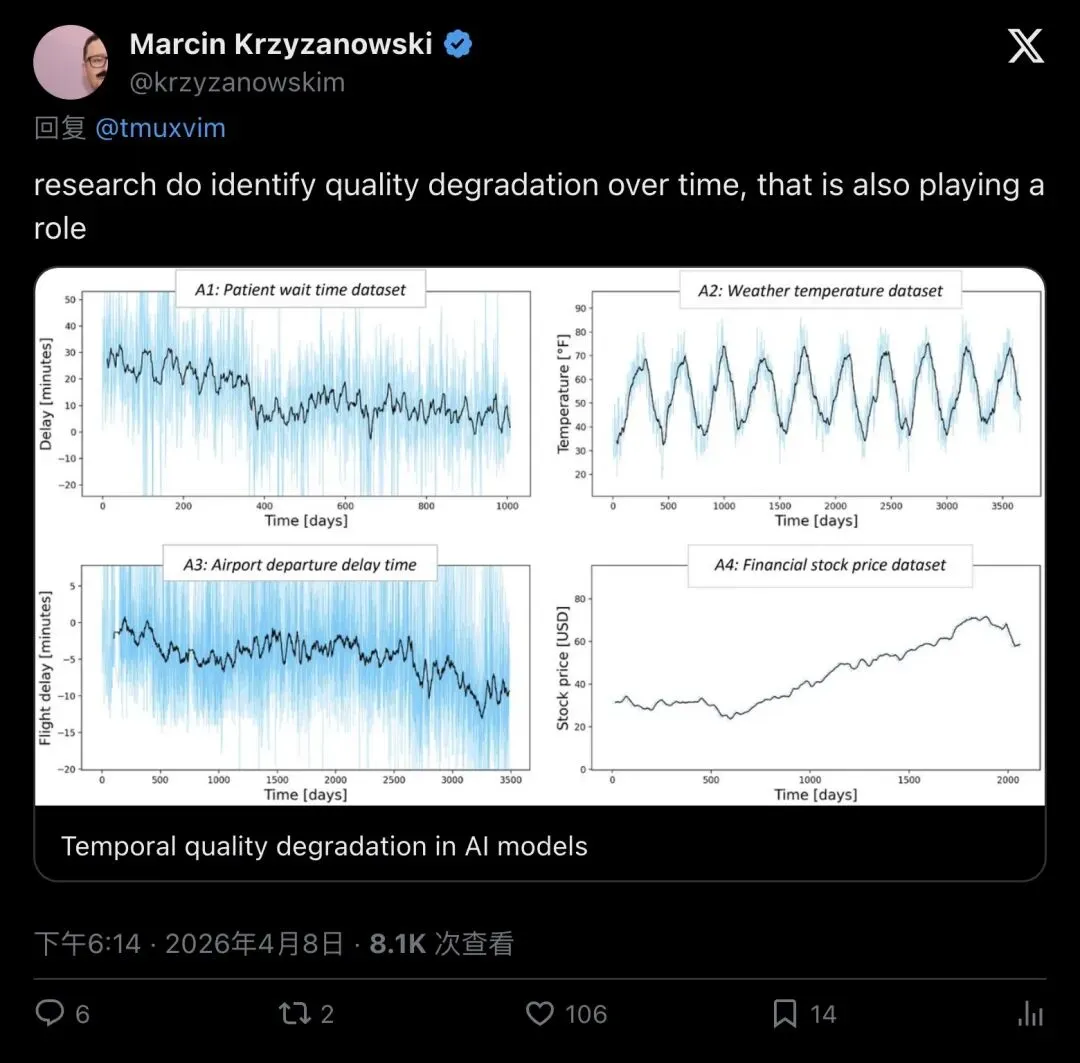
对此,Krzyzanowski给出了两条回应。第一条:他贴出了一组学术图表,标题为"Temporal quality degradation in AI models"(AI模型的时间维度质量退化),显示多个数据集上存在随时间推移的性能变化趋势。
▲ Krzyzanowski贴出研究图表:有论文识别出AI模型的质量退化现象
第二条:他称"有多个网站每天追踪benchmark,可以展示逐日差异"。
▲ Krzyzanowski:有网站每天追踪benchmark,能看到日常波动
但当被进一步追问时,他又滑向了另一个极端——
"benchmarks are useless, who's surprised in 26"
「benchmark就是没用的东西,2026年了谁还会吃惊?」
▲ Krzyzanowski最后的立场:benchmark本身就没用
这段争论暴露了整个讨论的核心矛盾:如果你认为benchmark能捕捉退化,那就拿数据出来说话;如果你认为benchmark根本无效,那你凭什么说模型变差了?两头都想占,逻辑链就断了。
「Enshittification降临奇点」:一句话戳中所有人
在技术辩论的间隙,一条评论获得了病毒式传播。网友John Carter只说了一句话:
"Enshittification comes for the Singularity."
「Enshittification(劣质化)降临了奇点时代。」
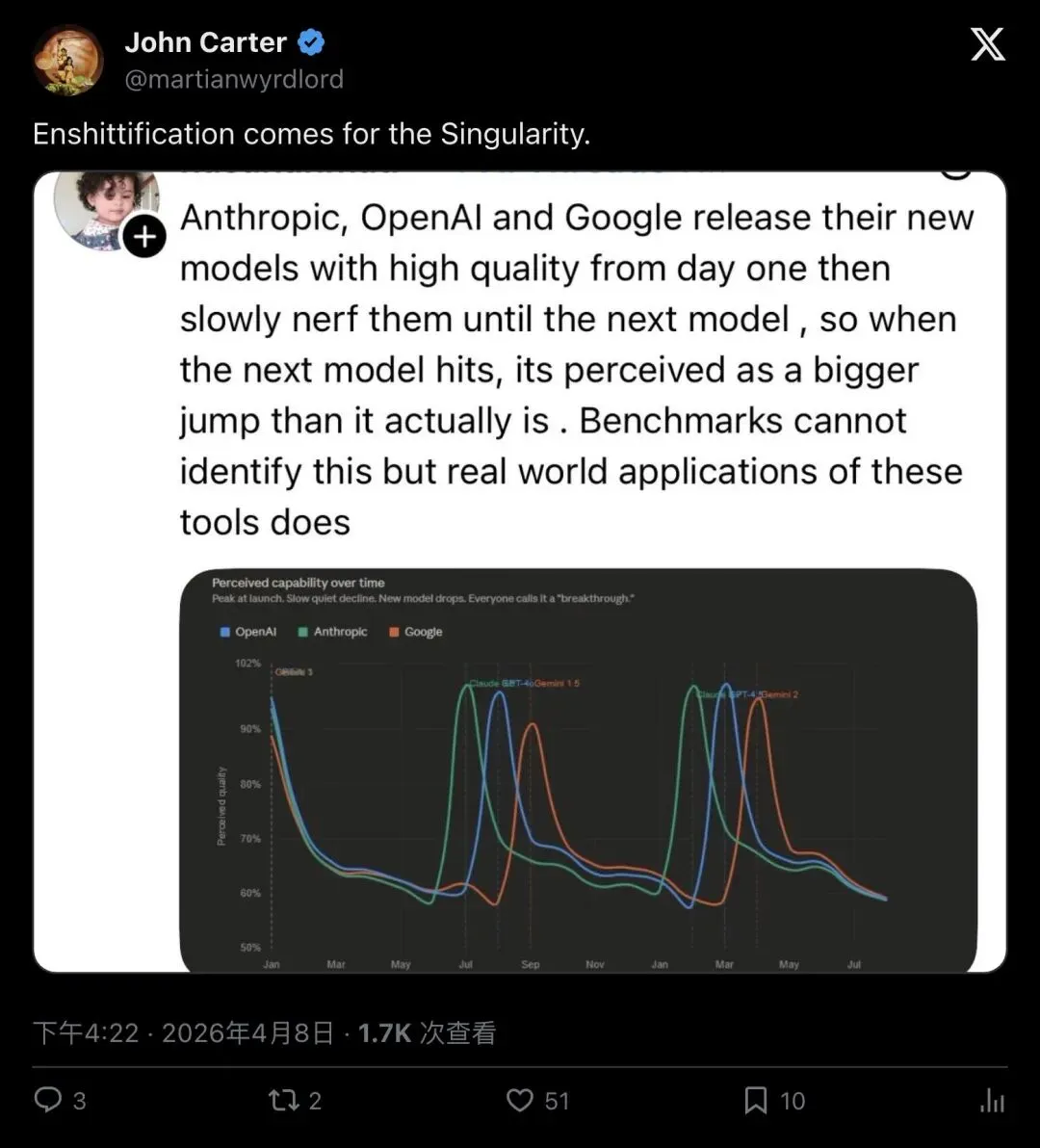
▲ John Carter的一句话浓缩了所有人的情绪
Enshittification——这个由Cory Doctorow发明的词,原本用来描述互联网平台从"对用户好"到"榨取用户"的退化过程。现在,它被直接嫁接到了AI模型上。
这句话之所以能引爆传播,是因为它精准捕捉到了一种弥漫在AI用户群体中的集体焦虑:我每月付20美元订阅的模型,还是上个月那个模型吗?
真正该问的问题:我们买到的到底是什么?
在所有喧嚣之中,一条评论指向了最本质的问题。网友Focused Entropy写道:
"The AI regulation we need is consumer protection laws. We have no idea what we're paying for."
「我们真正需要的AI监管,是消费者保护法。我们根本不知道自己花钱买到的是什么。」
▲ Focused Entropy:我们需要的AI监管,是消费者保护
这或许才是整场争论中最清醒的一条。
无论"故意nerf"的指控是否成立,一个事实是不可否认的:AI公司可以在不通知用户的情况下修改模型行为。没有版本锁定、没有变更日志、没有第三方审计。你今天用的Claude和下周用的Claude,可能参数已经被调整过——而你永远不会收到一封邮件告诉你这件事。
在传统软件行业,这叫无声更新(silent update),通常会受到严格监管。但在AI领域?目前是一片灰色地带。
阴谋论还是系统性问题?
让我们回到最初的问题:AI大厂真的在"先发满血版,再偷偷削弱"吗?
目前没有确凿的公开证据证明这是一种有组织的商业策略。那张在推特上疯传的图表,至今没人找到可验证的原始来源。Gary Marcus问了,没人答得上来。
但"没有证据"和"不存在"是两码事。
可以确认的是:用户对模型质量波动的感知是真实的。无数开发者在Reddit、HN和X上报告过"同一个模型,上个月好用,这个月就不行了"。而AI公司对此的标准回复往往是"我们没有改变模型"——但他们也承认会进行A/B测试、调整采样参数、修改系统提示词。
真正可怕的地方在于:你无法区分"故意削弱"和"正常的服务端调整"。因为这一切都发生在黑箱里。
这场5000赞的推特风暴,表面上是一个阴谋论,本质上是一个治理问题——当你为一个持续变化的AI模型付费时,你到底拥有什么权利?
— END —
