 夜雨聆风
夜雨聆风
 Nature:科学家用AI跑得越来越快,但赛道正在收窄。
Nature:科学家用AI跑得越来越快,但赛道正在收窄。


这两年,AI在科研圈的存在感已经强到无法忽视。
AlphaFold拿了诺贝尔奖,深度强化学习在可控核聚变里稳住了等离子体,自主实验室系统让化学家可以批量跑高通量实验,大语言模型甚至开始帮人写论文。每一条新闻都在告诉你同一件事:AI正在让科学变得更快、更强、更高效。
但问题是:当每个人都在欢呼「AI改变科研」的时候,有没有人认真看过,科研本身到底被改变成了什么样子?
2026年2月,清华大学电子工程系李勇教授团队联合芝加哥大学James Evans教授,在Nature正刊发表了一篇论文,标题非常直白——「Artificial Intelligence Tools Expand Scientists' Impact but Contract Science's Focus」。
研究团队用了OpenAlex数据库中4130万篇自然科学论文、横跨1980到2025年的数据,给出了一个让人不太舒服的结论:AI确实让每个科学家都变强了,但科学整体正在变窄。
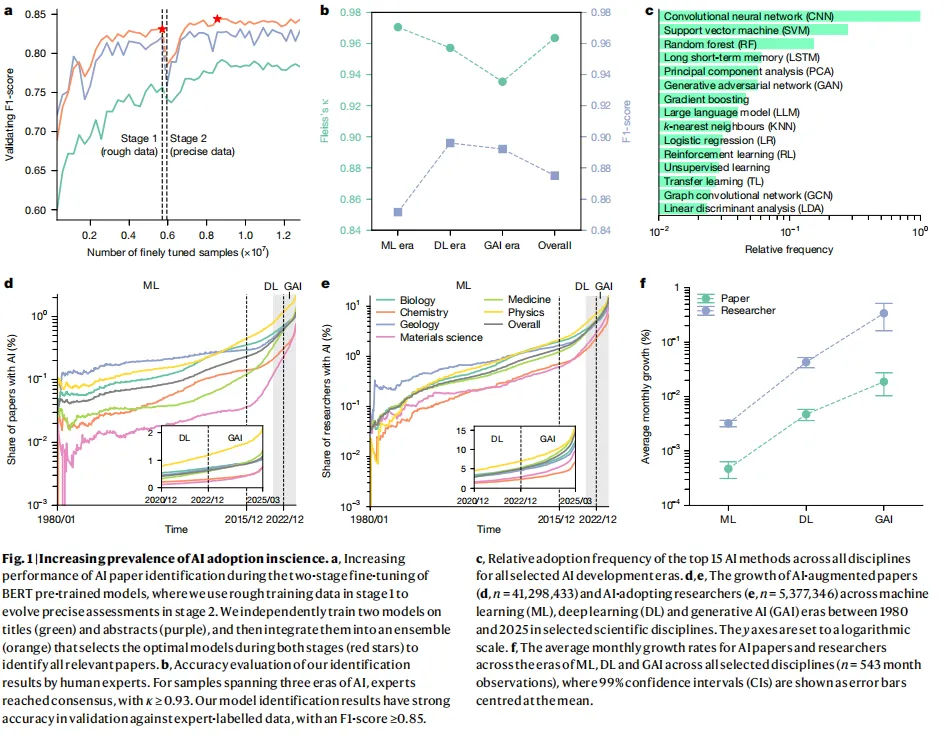
图源:Fig.1d/e,AI论文和AI研究者在各学科中的增长趋势
这不是一句口号,而是41,298,433篇论文和5,377,346名研究者的数据在说话。
从传统机器学习到深度学习再到生成式AI,三波浪潮下来,AI论文在生物学中的占比涨了51.89倍,采用AI的物理学研究者增长了362.16倍。AI在自然科学中的扩散,早已不是个别领域的偶发事件,而是一场系统性的变革。
那这场变革到底带来了什么?
▌个体的狂欢:不用AI,几乎等于主动放弃竞争优势
论文给出的数据非常扎眼。
在包含完整引用记录的27,405,011篇论文中,AI论文发表后的年均引用量比非AI论文高出98.70%。不只是平均数好看——无论你看top 1%还是top 10%,AI论文的引用表现都稳稳压过传统论文。
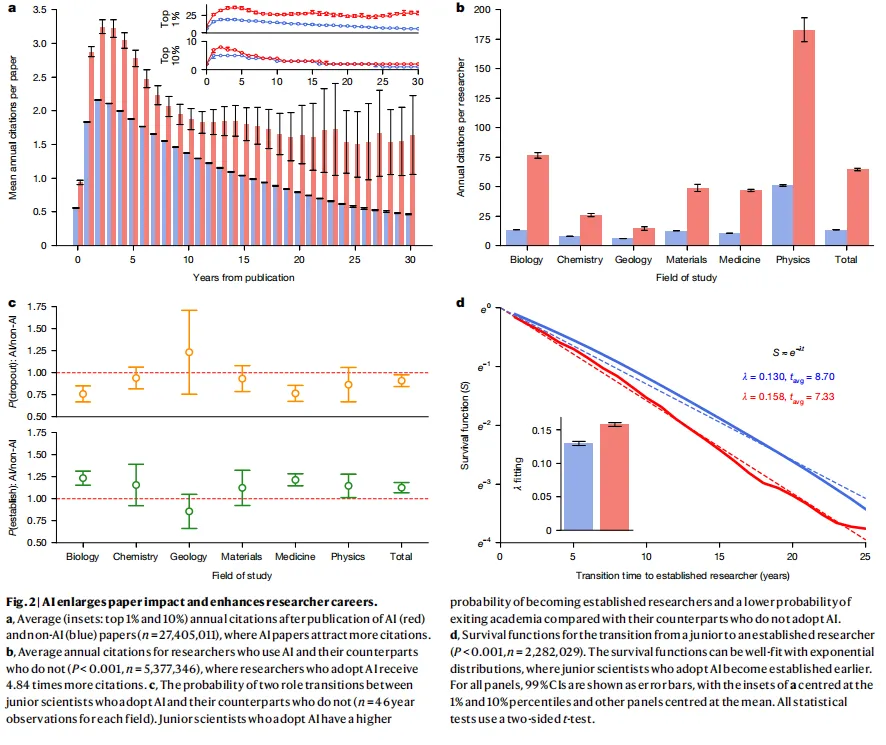
图源:Fig.2a/b,AI与非AI论文引用对比 + 研究者年均引用对比;c/d,初级科学家角色转变概率与生存函数
再看研究者层面,采用AI的科学家年均发表论文数量是未采用者的3.02倍,年均引用是4.84倍。而且这种优势不是因为「本来就厉害的人才用AI」——研究团队在控制了早期职业地位之后,差距依然显著存在。
换句话说,AI本身就是造成这种差异的重要因素。
更有意思的是职业发展的数据。
研究团队追踪了2,282,029名科学家的职业轨迹,把他们分成「初级科学家」和「既定研究者」(即项目负责人)两个阶段。结果发现,采用AI的初级科学家成为项目负责人的概率比同行高出13.64%,退出学术界的风险更低,而且平均提前1.37年完成这个跃迁——用AI的人7.33年就能成为项目负责人,不用的要8.70年。
还有一个容易被忽略的细节:AI辅助研究的团队规模反而更小,平均减少了1.33人。其中初级科学家的数量从非AI团队的2.89人降到了AI团队的1.99人,降幅超过31%;而既定科学家只减少了10.77%。
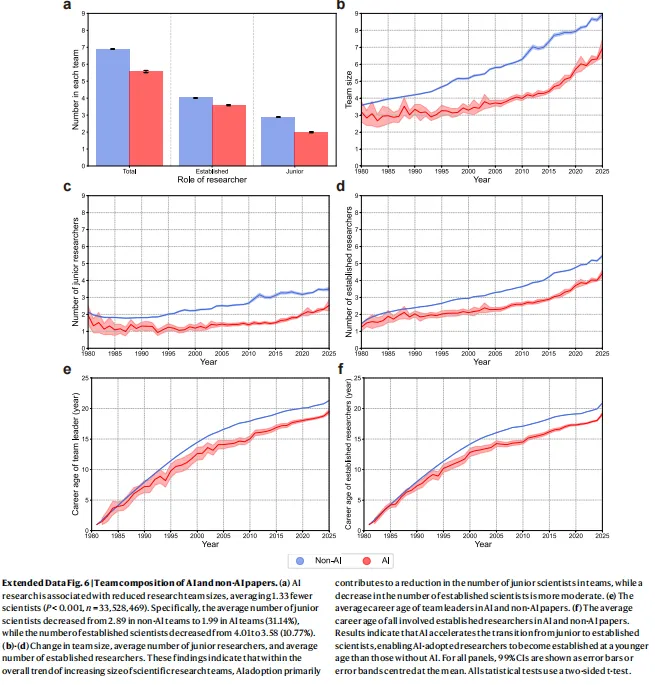
图源:Extended Data Fig.6a,AI与非AI团队规模对比
这意味着什么?AI不只是在「帮」科学家,它还在「替代」一部分初级研究人员承担的数据处理和模式识别工作。对于个体科学家来说,这套逻辑非常清晰:用AI,论文更多、引用更高、晋升更快、团队还能更精简。在这种激励下,不用AI几乎等于在学术竞争中主动让出身位。
▌集体的代价:科学的「知识直径」正在缩小
个体层面的数据看起来像一场狂欢。但当研究团队把视角从个人拉远到整个科学生态时,画风就完全变了。
为了衡量科学探索的广度,研究团队用了SPECTER 2.0——一个在大量科学文献上预训练、并用引用信息微调过的文本嵌入模型——把论文投射到768维的向量空间里。在这个空间中,他们定义了一个叫「知识广度」(Knowledge Extent)的指标,本质上就是一批论文在向量空间中覆盖的最大距离,可以理解为这批研究的「知识直径」。
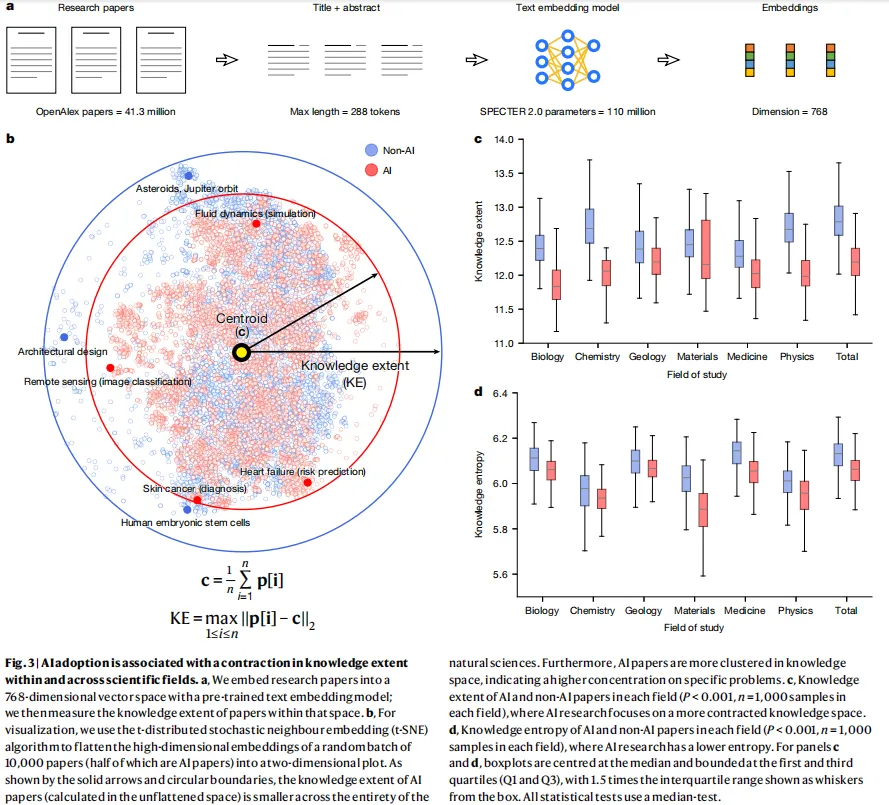
图源:Fig.3a/b,嵌入方法示意 + t-SNE二维可视化;c/d,各学科知识广度与知识熵的箱线图对比
直径越大,说明这批论文涵盖的主题越多元、越分散;直径越小,说明大家在做的事情越相似、越集中。
结果呢?AI研究的集体知识广度中位数比传统研究收缩了4.63%,而且这种收缩在所有六个学科中都一致存在。
4.63%听起来不大?
那我们换一个角度看:当论文团队把这六个学科细分为200多个子领域后,超过70%的子领域都观察到了AI研究相比传统研究的知识广度收缩。这不是某个学科的特殊现象,而是几乎遍布自然科学的结构性趋势。
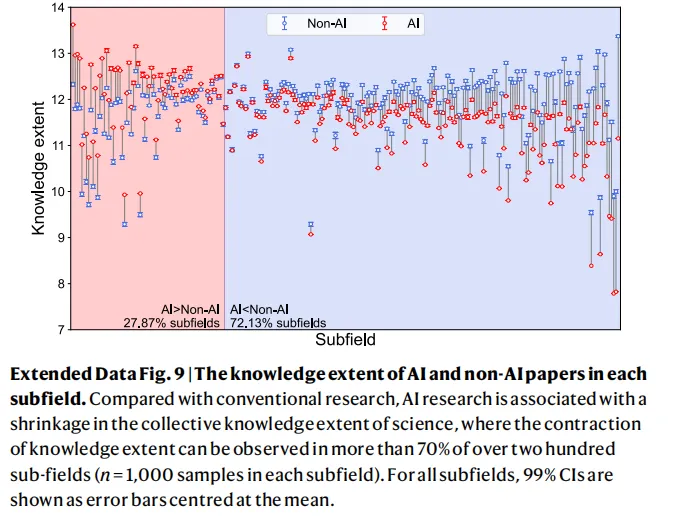
图源:Extended Data Fig.9,200多个子领域知识广度对比
与此同时,AI研究的知识分布熵值也更低。
翻译成大白话就是:AI研究不是在均匀地推动整个学科的前沿,而是不成比例地集中在特定的热门问题上。大家都在往数据最丰富的方向涌,结果就是方法越来越花哨,做出来的东西却越来越像。
为什么会这样?
研究团队进一步分析了引用同一篇AI论文的后续研究之间的互动关系。结果发现,这些后续论文彼此引用的频率比非AI领域低了22%。这意味着AI研究更容易形成围绕少数热门成果的「星状结构」——所有人都引用那几篇核心论文,但彼此之间缺乏对话和连接,不像新兴领域那样会自发形成密集的研究网络。
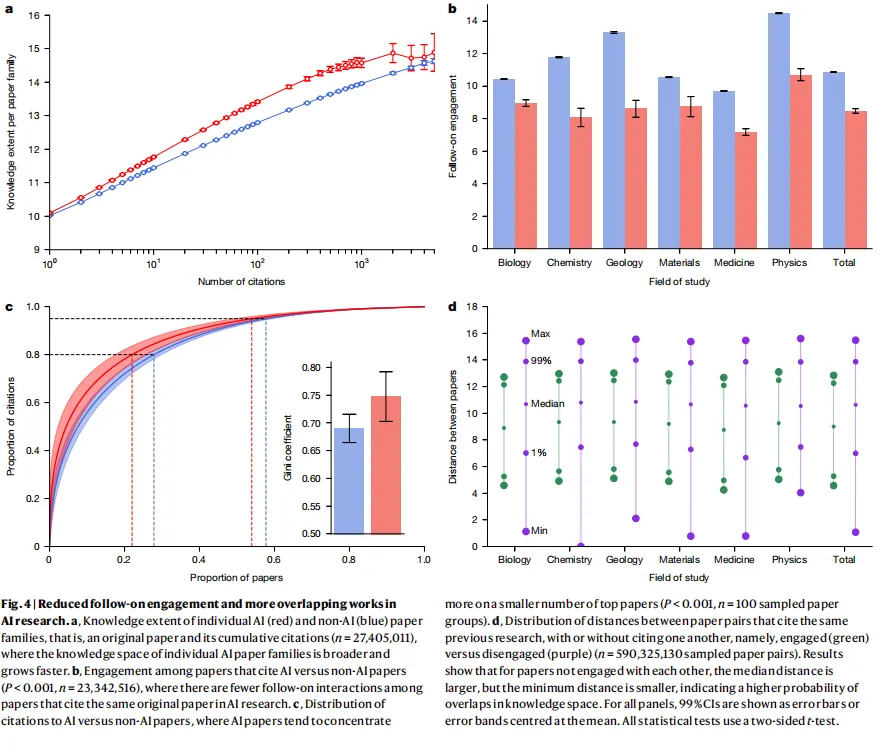
图源:Fig.4b/c,后续互动减少 + 引用分布马太效应;d,互引与非互引论文对的距离分布
马太效应也更加触目。
在AI研究中,前22.20%的顶尖论文拿走了80%的引用,前54.14%拿走了95%。引用分布的基尼系数达到0.754,显著高于非AI论文的0.690。少数「超级明星」论文吸走了几乎全部的注意力,剩下的大量工作则沦为沉默的大多数。
那些没有互相引用的论文之间,距离分布也很有意思:中位距离比互相引用的论文对大了18.11%,但最近距离反而小了76.51%。
这说明什么?大部分不互引的论文确实在做不同的事情,所以距离更远;但偶尔,因为彼此不知道对方的存在,两篇论文反而做了高度重叠的工作却毫不自知。研究团队用了一个精准的比喻来形容这种现象:「孤独的群体」(lonely crowds)。所有人都挤在热门方向上,看似热闹,实则缺乏真正的交流和碰撞。
研究团队还检验了几个直觉上可能的解释——
是不是因为某些主题本身更热门?
是不是因为早期影响力更大的方向更容易吸引AI?
是不是因为资助政策的倾斜?
结果这些因素的解释力都不强。真正的关键驱动因素是数据可用性:AI去了数据最富的地方,而不是最需要探索的地方。
▌所以,这对我们意味着什么?
这篇论文揭示的矛盾其实非常现实:每个科学家都在做理性选择——用AI确实能发更多论文、拿更多引用、更快晋升——但所有人的理性选择加在一起,却导致了集体层面的非理性结果。
科学界正在扎堆解决已知问题,甚至在重复性地优化现有方案,而那些缺乏数据但可能更具开创性的基础问题,正在被系统性地边缘化。
这对科研政策的挑战是直接的。如果学术评价体系继续主要奖励论文数量和引用次数,AI带来的个人激励会被进一步放大,而科学整体的研究集中和探索收缩也会随之加剧。单纯增加对AI科研的资助,很可能只是让「富数据区」更加拥挤。
论文团队在讨论部分提出了一个值得深思的方向:未来的AI系统不应仅仅局限于增强认知能力——也就是更好地分析已有数据——更需要扩展「感知和实验能力」,帮助科学家去那些还没有数据的地方采集新数据、发现新现象。毕竟,科学史上真正重大的突破,往往不是来自对已有数据的极致优化,而是来自对自然的全新观察视角。
与其说是AI限制了我们,不如说是我们为了追求效率,主动选择了去摘那些AI够得着的果实。
赛道上的人越来越多,速度越来越快,但赛道本身并没有变宽。
如何让AI不只是帮我们在已知的地方跑得更快,而是带我们去那些还没有路的荒原——这大概是AI for Science接下来最需要回答的问题。




▌往期精选:

读懂这篇 Nature 综述,看透未来 10 年材料实验室的终极形态
原文链接:https://www.nature.com/articles/s41586-025-09922-y
点击👇阅读原文可跳转原论文链接
