夜雨聆风
夜雨聆风#AI #Coding #代码补全 #VibeCoding #Harness #SDD
一、目的:
大家对 AI Coding 已经不陌生了,代码补全、写工具函数、起一个页面、做一个 Demo,这些事情它大多都已经能做,而且很多时候做得还不错。但如果只是讨论“AI 会不会写代码”,这个问题其实已经没有太多讨论价值了。至少在局部编码这件事上,它的可用性基本已经被反复验证过了。 例如我们常用的 TabCoding vibeCoding 等等。
这次真正想验证的,不是 AI 能不能辅助写代码,而是它有没有可能从局部参与走到完整参与交付。AI Coding 能不能理解边界,能不能按要求推进,能不能在约束下把事情做完,能不能不堆屎山代码。
二、途径:
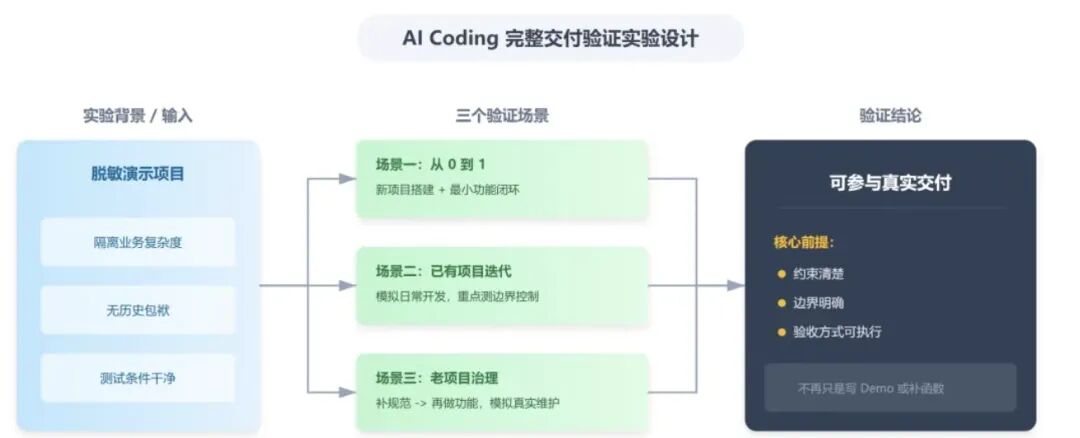
三种实验场景:
第一个场景,是从 0 到 1,直接让 AI 按要求搭一个新项目,并完成一个最小功能;
第二个场景,是在已经搭起来的项目里继续加需求,模拟更接近日常开发的迭代过程;
第三个场景,则是模拟一个文档不全、约束不清的老项目,先补规范,再继续做功能;
三、结论:
AI Coding 已经不只是适合写 Demo、补函数、起页面了。
在约束清楚、边界明确、验收方式可执行的前提下,它已经可以参与相当一部分真实交付工作。
AI 编程的可用范围理解成这样:
做 Demo、局部编码、小功能实现:已经比较成熟 做新项目初始化和最小功能闭环:可以承担 做已有项目中的小到中等规模迭代:可以承担,但前提是边界要先框清楚 做老项目直接功能开发:不建议直接开始,更适合先补规范、再做功能 做高不确定性、强业务耦合、约束大量依赖隐性经验的任务:仍然不够稳
也就是说,它已经可以参与交付,但更像一个需要被定义清楚、被约束好、被验证到位的协作对象,而不是一个把需求丢过去就能自动收口的全能开发者。
四、实践过程:
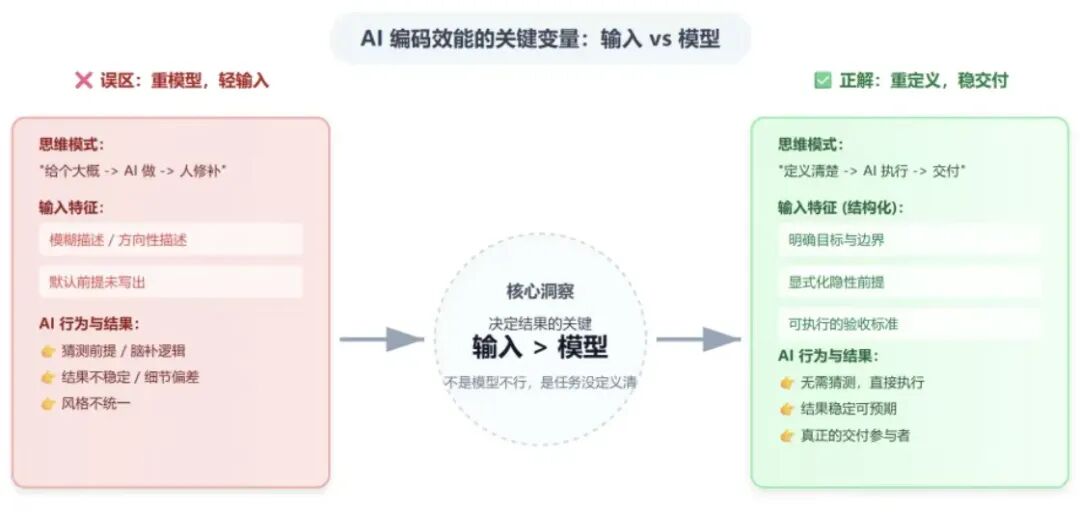
1、真正影响结果的,往往不是模型,而是输入
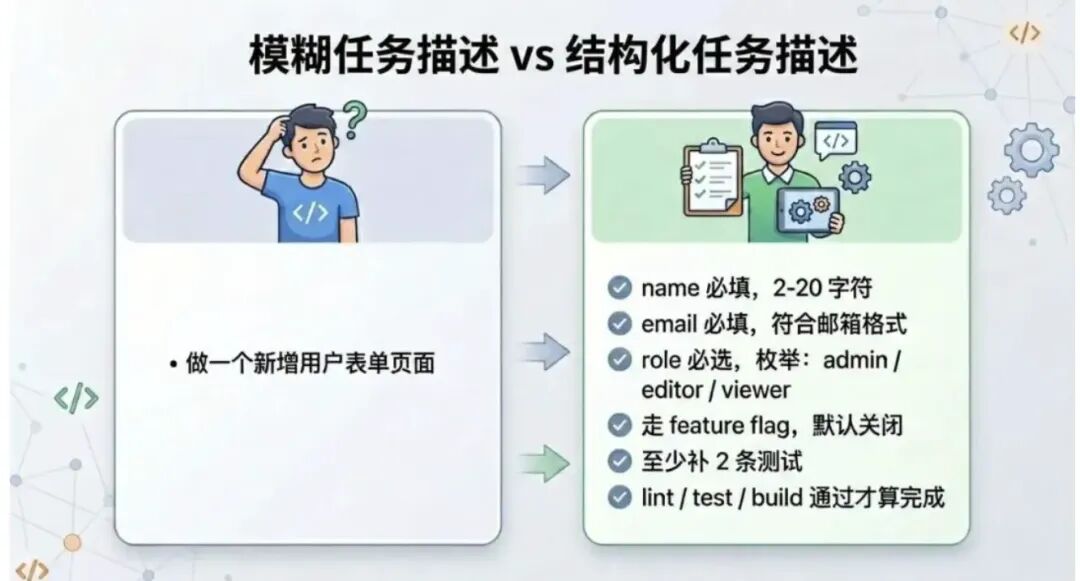
左边这种描述,人能靠经验补全很多前提;但放到 AI 面前,往往就会变成大量默认假设。
右边这种写法看起来更“啰嗦”,但真正能明显提升稳定性的,通常恰恰是这些被显式写出来的边界、规则和验收条件。
做完这次实践之后,我越来越确定,真正影响结果的,往往不是模型本身,而是你给它的输入,到底是不是一份足够清楚的任务定义。
2、配合模型--写出大家都知道但是AI不知道的潜在内容
其实就是像写代码一样写提示词,只是不局限于具体的开发语言和语法了。
3、从0到1探索实践
拿一个新项目做验证(没有太多想法和思路,只有一个目标的情况下)
输入第一版提示词如下:
我想开发一个数据分析智能体,帮我生成功能描述文档并制定开发计划
核心流程是:用户提供数据库连接信息,然后用户使用自然语言提问。
整体功能分为两部分,第一部分是对话并分析数据工作流,第二部分是数据处理流程。具体要求如下:
一、核心问答工作流 (Core Interaction Pipeline)
该流程属于前台/实时任务,负责处理用户请求并输出最终分析结论。
1. 多级意图识别 (Intent Routing)
• 分类分流: 判定输入是“闲聊/通用百科”还是“本地数据库查询”。
• 闲聊响应: 非数据需求直接由 LLM 回复。
• 需求补全: 若是数据需求但描述模糊,触发反问机制。
2. 动态上下文组装 (Context Construction)
• 示例检索: 从 Few-Shot 库中检索 2-3 条相似的问答对。
• Schema 筛选: 根据问题从索引中挑选最匹配的 DDL 片段。
3. SQL 生成与校验 (SQL Generation)
• Prompt 注入: 将“语义化元数据 + Few-Shot 示例 + 用户问题”输入模型。
• 方言适配: 约束生成符合特定数据库(如 MySQL/PG)语法的 SQL。
4. 执行引擎与自愈重试 (Execution & Self-Healing)
• 沙箱执行: 运行 SQL 并捕获报错。
• 闭环修复: 遇错时,自动将 报错信息 + 原始 SQL 回传模型进行反思修复(设定上限为 2 次)。
5. 结果解读与洞察生成 (Reasoning & Response)
• 数据结构化: 将执行结果转化为易读的表格或数值。
• 深度总结: 结合原始问题,用自然语言总结核心结论,不仅给数据,更给洞察。
二、 数据处理流程 (Data Preparation Pipeline)
该流程属于后台/初始化任务,旨在为智能体建立高质量的“知识库”,解决模型“看不懂表”和“写不对复杂逻辑”的问题。
1. 元数据语义化预处理 (Metadata Enrichment)
• 自动扫描: 接入数据库 DDL,提取表名、字段名、类型及注释。
• AI 增强描述: 利用 LLM 为晦涩的字段(如 is_act_v2)生成通俗易懂的中文语义标签(如“是否二期活跃用户”)。
• 枚举值采样: 扫描状态类字段的取值(如 0: 禁用, 1: 启用),形成查询字典,避免 SQL 生成时条件写错。
2. Few-Shot 示例库建设 (Dynamic Exemplar Library)
• 知识沉淀: 收集业务中高频、复杂的自然语言提问及其对应的标准 SQL。
• 向量化存储: 将“问题”转化为向量存入数据库,以便问答流程中进行语义匹配。
3. 模式索引构建 (Schema Indexing)
• 对表描述和字段描述建立索引,支持在大规模数据库(成百上千张表)中快速检索出相关的表结构。
三、其他约束:
1、数据库类型只做 MySQL 、 PostgreSQL轻量级的可以选sqllite
2、前台通信需要用http,部分阶段行输出需要考虑使用的sse流式输出。
3、需要限制只能使用select语句查询数据
4、输出需要总结+表格 + 指标,还是还要图表
5、Few-shot 来源前期可以整理成QA对,放到本地固定目录下临时用着,后面再考虑具体实现。
6、知识库更新需要提供手动全量更新的能力。
如果目标只是让 AI 帮忙写点代码,那以前那种偏描述性的需求文档也许还能凑合;但如果目标是让它真正参与交付,需求本身就不能只写给人看。
从 0 到 1,AI 不只是能把项目基线搭起来,也不只是能把第一个功能写出来,而是已经能够借助自动化工具,把这个功能从实现一路推进到最基本的验收。
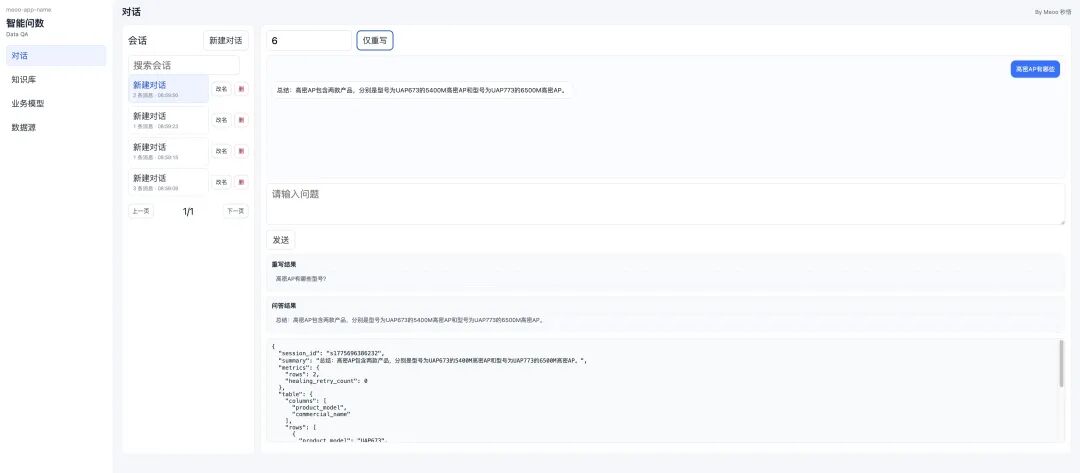
如果一开始只是追求“先跑起来”,那很容易得到一个表面很快、后面却越来越难接着做的项目。反过来,如果先把项目级别的规则说清楚,再让 AI 往下执行,并在最后补上一层真正从用户视角出发的自动化验收,整个过程会稳很多。
4、难点-叠加功能
——项目搭起来之后,真正难的是继续往里加需求
因为真实开发里,大多数时候并不是从 0 开始,而是在一个已经存在的项目里不断往下加需求、补功能、做调整。
可以参考下面这个提示词框架
## 目标
在现有项目基础上新增一个用户列表页面,用于模拟已有项目中的功能迭代。
## 功能要求
1. 展示 mock 用户列表
2. 提供搜索输入框
3. 支持按 `name` 或 `email` 过滤
4. 无结果时展示空态
## 本次任务重点
这个任务的重点不只是实现列表,而是控制改动边界。
开始实现前,需要先明确:
- 会新增哪些文件
- 会修改哪些文件
- 改动边界在哪里
- 风险点是什么
不要顺手调整无关结构。
## 输出要求
开始改动前,先输出:
1. 文件改动清单
2. 实现计划
3. 风险与边界说明
4. 验证命令
这一步让我比较满意的一点,不是它把列表做出来了,而是它没有为了一个小需求去撬动原有结构。
从这次 AI 给出的总结里,信息其实已经比较完整了:新增了 mock 数据和过滤工具函数,新增了用户列表页和测试,App.tsx 只做了最小页面切换,最终 pnpm lint、pnpm test 和 pnpm build 都通过了。
总结:在已有项目里,AI 的可用性并不只取决于它写得快不快。 更重要的是,你有没有先把边界框出来。
5、最后问题:老项目重构
项目已经跑了很久,功能不少,代码也不一定不能用,但很多最基础的东西其实是缺的。文档不全,脚本不统一,测试没有形成基线,目录结构也未必一致,很多规则都存在于人的脑子里,而不是写在项目里。
先给模板提示词:
## 目标
针对一个“可运行但约束不完整”的前端项目,先补齐最小工程规范,再为后续功能迭代建立稳定基础。
## 本次要做的事
在不大规模重构的前提下,优先补齐以下内容:
1. README
2. 统一 scripts
3. lint / test / build 基线
4. 最小测试样例
5. 项目结构说明
6. 必要的工程说明
## 本次任务原则
- 只补最小可执行规范
- 不进行大范围重构
- 不借机重写项目
- 不调整无关业务逻辑
- 以“先建立最小秩序”为目标
## 结果要求
本次完成后,项目至少应满足:
- README 可读
- 常用命令统一
- lint 可执行
- test 可执行
- build 可执行
- 至少存在 1 条最小测试样例
老项目并不是不能让 AI 参与。但如果约束长期缺失,直接做功能的体验通常会比较差。
更合理的顺序,往往是先补最小规范,再逐步把后面的功能迭代交给它。换句话说,在老项目里,最先要补的,不是功能,而是约束。
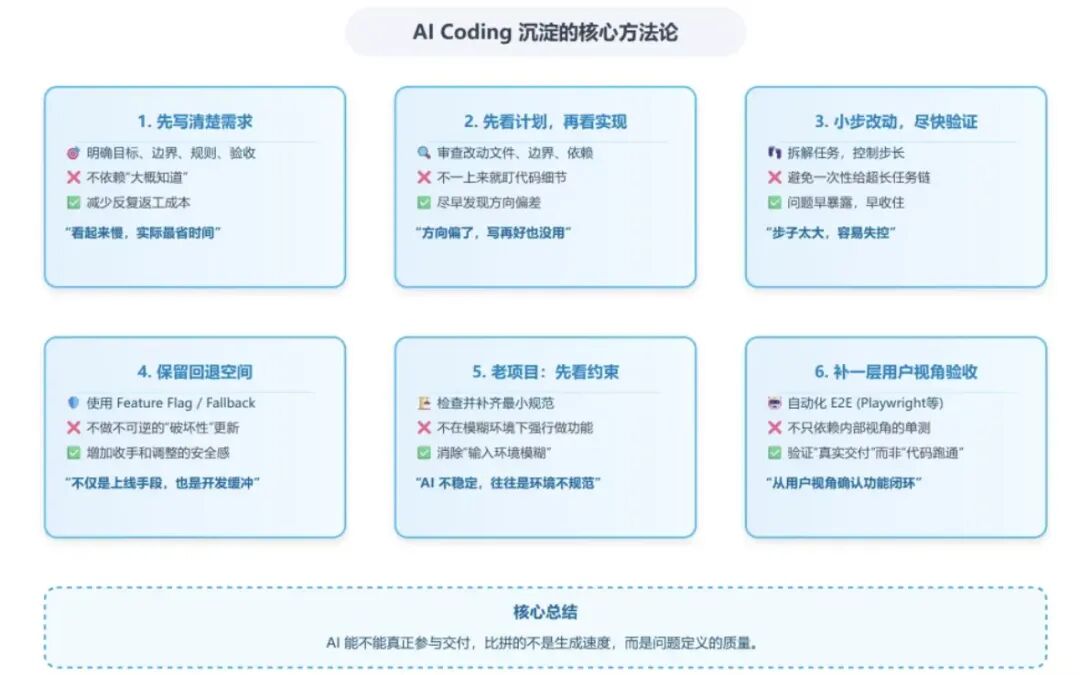
6、结论:
我最后沉淀下来的几条固定做法,大致是这几项:
先把需求写清楚,再让 AI 动手 先看计划,再看实现 小步改动,及时验证 新能力尽量保留回退空间 老项目先补规范,再做功能 对界面功能尽量补一层接近真实使用的自动化验收