 夜雨聆风
夜雨聆风如需转载本文,请注明本公众号
本文共计4848字,阅读约需要25分钟
文献来源:Novikov A, Vũ N, Eisenberger M, et al. AlphaEvolve: A coding agent for scientific and algorithmic discovery[J]. arXiv preprint arXiv:2506.13131, 2025.
摘要:本文介绍了AlphaEvolve,它是一种进化编码agent,可大幅提升最先进的 LLM 在高难度任务(如解决开放科学问题或优化计算基础设施的关键部分)上的能力。AlphaEvolve 负责协调 LLM 的自主流水线,其任务是通过直接修改代码来改进算法。AlphaEvolve 采用进化方法,不断接收来自一个或多个评估者的反馈,迭代改进算法,从而可能带来新的科学和实践发现。本文将这种方法应用于一些重要的商业问题,从而证明了它的广泛适用性。
01
引言
科学发现与算法设计本质上是一个高度复杂且耗时的过程。在传统研究范式中,研究人员需要经历从问题建模、假设提出,到实验验证与反复修正的一系列步骤。在这一过程中,往往需要在大量候选方案中不断试错,并逐步逼近最优解。这种过程不仅依赖经验与直觉,而且对时间和资源的消耗极大。
近年来,大语言模型(Large Language Models, LLMs)的快速发展为自动化科研提供了新的可能。这类模型在代码生成、推理以及知识表达方面展现出了强大的能力,能够在一定程度上辅助研究人员完成编程任务、生成研究思路甚至设计实验流程。然而,尽管LLM在这些方面取得了显著进展,其能力仍主要停留在“单次生成”的范畴,即根据已有上下文生成一个候选解,而缺乏持续改进和系统性探索的能力。
换言之,LLM虽然可以生成代码,但难以像人类研究者那样,通过不断实验与反馈,逐步优化算法并最终实现突破性的创新。
在这一背景下,Google DeepMind提出了AlphaEvolve。该系统尝试将进化计算与大语言模型相结合,使AI能够在自动评估的反馈机制下,对算法进行持续优化与迭代改进,从而在复杂问题空间中实现类似“科学发现”的过程。AlphaEvolve的核心思想在于,将算法设计问题转化为一个可自动评估的优化问题,并通过进化搜索在算法空间中不断探索,从而发现性能更优甚至全新的算法结构。
将进化方法与编程大型语言模型相结合的想法,之前已经在各种专业场景中得到探索。特别是,AlphaEvolve 是对 FunSearch(见图1)的重大提升,后者利用 LLM 指导的进化来发现启发式方法,以构建新的数学对象或驱动在线算法的运行。此外,相关方法还被应用于诸如为仿真机器人发现策略、符号回归以及为组合优化综合启发式函数等任务。与这些系统相比,AlphaEvolve 利用最先进的大型语言模型,进化实现跨越多个函数和组件的复杂算法的大段代码。因此,它在规模和通用性上都远远超越了前辈系统。
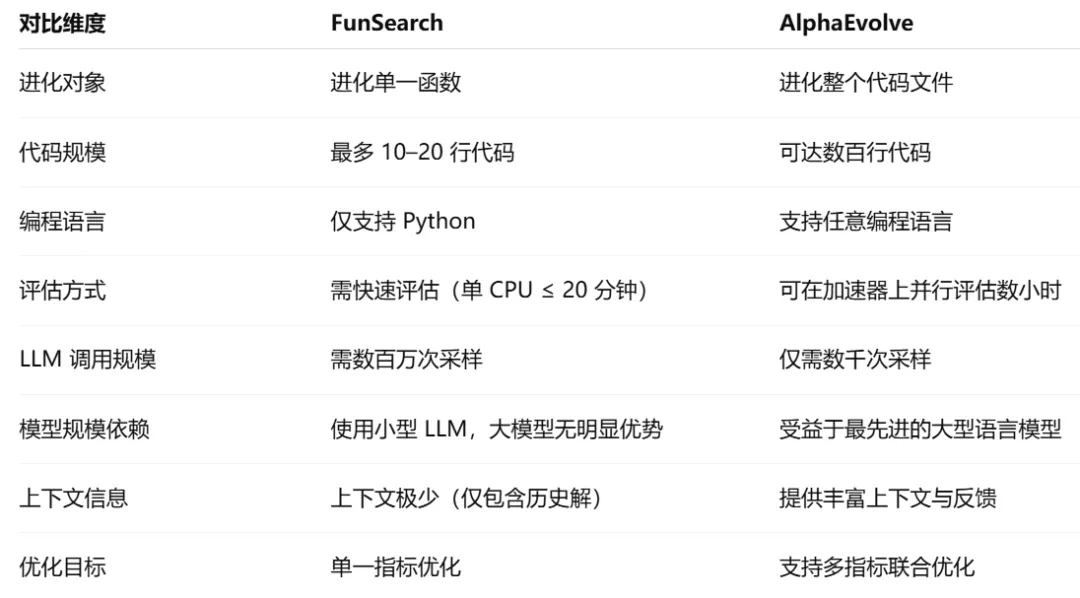
图 1 FunSearch 与 AlphaEvolve 对比
02
AlphaEvolve的整体框架
AlphaEvolve并不是一个单一模型,而是一个由多个模块组成的系统性框架,其核心是一个由大语言模型驱动的进化搜索过程。该系统以程序(代码)作为基本表示形式,将候选解统一表示为可执行算法,并通过自动评估机制对其性能进行量化,从而实现闭环优化。
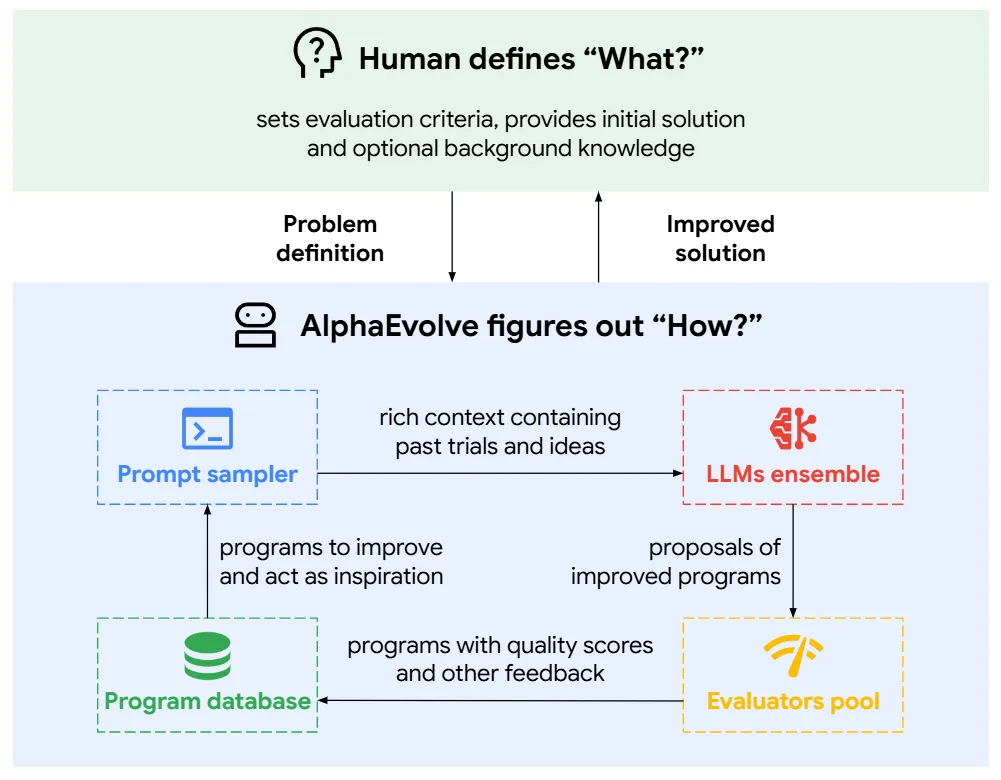
图 2 AlphaEvolve整体框架图
2.1 明确任务
在系统初始化阶段,人类研究者需要定义问题,包括提供初始程序、评价函数以及必要的背景信息。其中,评价函数通常表示为一个从程序到若干性能指标的映射,用于衡量算法在特定任务上的表现,例如运行时间、准确率或资源消耗等。该机制表现为一个函数h,它将某个解映射到一组标量评估指标。通常,这些评估指标需要被最大化。在我们的当前设置中,h通常作为一个 Python 函数实现,称为evaluate,具有固定的输入/输出签名,返回一个标量字典。
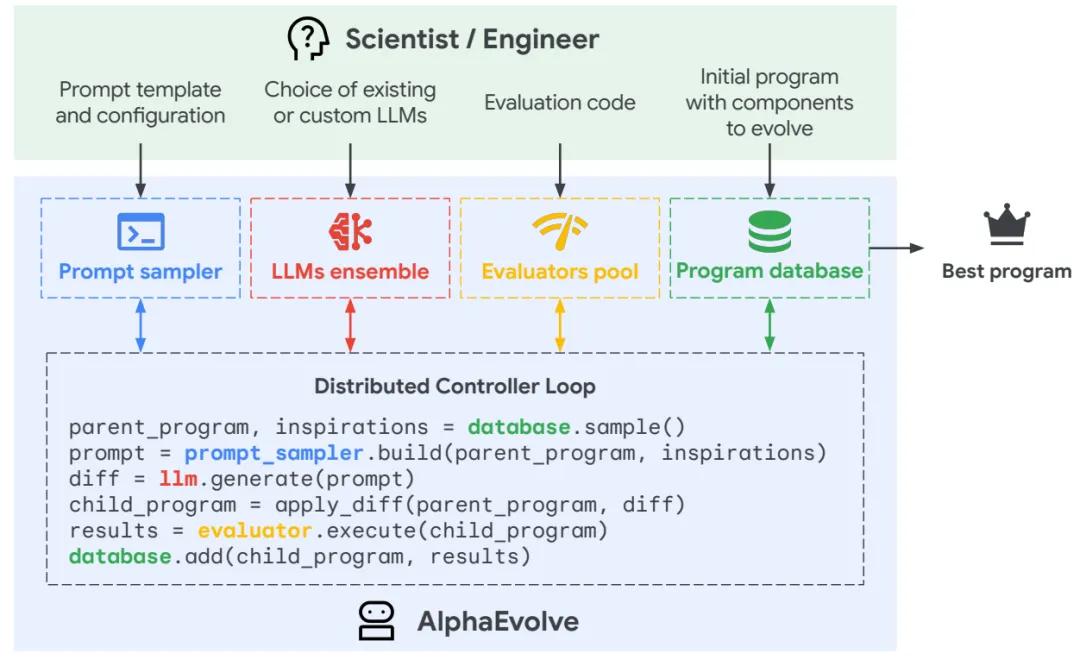
图 3 AlphaEvolve具体流程图
为了支持在完整代码库层面对多个模块进行进化,AlphaEvolve设计了一套输入接口,允许用户通过标注的方式指定哪些代码片段需要参与进化。具体做法是在代码中以注释形式添加特殊标记(如#EVOLVE-BLOCK-START 和#EVOLVE-BLOCK-END),从而明确系统可以修改的范围。这种方式对原有代码改动极小,因此能够较为方便地嵌入现有工程体系中。
在被标记的进化代码块中,用户提供的代码将作为初始解,由系统在后续过程中不断优化;而未被标记的部分则构成程序的整体框架,用于组织和调用这些被进化的模块,通常通过 evaluate 函数进行统一评估。需要注意的是,初始代码必须是可运行的完整实现,但其复杂度可以很低,例如仅包含返回固定值的简单函数即可,后续性能的提升主要依赖于AlphaEvolve的迭代优化过程。
2.2 提示词采样与生成机制
在提示构建方面,AlphaEvolve充分利用了当前最先进的大语言模型(SOTA LLMs)的能力,使其不仅能够处理较长上下文,还支持多种形式的定制化输入。具体来说,系统在生成进化提示时,会从程序数据库中抽取多个历史上表现较好的候选程序,并结合这些程序的评估结果,构建出包含丰富上下文信息的提示。同时,提示中还会包含针对当前待优化程序的修改指令,从而引导模型生成更有针对性的改进方案。
在这一基础框架之上,AlphaEvolve还允许用户根据具体任务进一步扩展提示内容。例如:
显式上下文(Explicit context):关于所解决问题的详细信息,例如人工编写的固定指令、公式、代码片段或相关文献(如 PDF 文件)。
随机格式化(Stochastic formatting):模板中的占位符由人工提供的多样化替代项组成,以增加多样性,这些替代项通过单独配置文件中给定的概率分布进行实例化。
结果渲染(Rendered evaluation results):通常包括一个程序、该程序的执行结果,以及由evaluate函数分配的得分。
元提示词进化(Meta prompt evolution):由 LLM 本身在额外的提示生成步骤中提出的指令和上下文,这些指令和上下文与解程序类似,在单独的数据库中共同进化。
2.3 开放性生成
在具体的生成阶段,AlphaEvolve利用大语言模型对已有程序进行理解与重构,并提出多样化的改进方案。模型的核心任务并非从零开始生成完整程序,而是在已有解的基础上进行迭代优化,这使得搜索过程更加稳定且高效。实验表明,虽然该框架本身对底层模型没有严格限制,但随着所使用LLM能力的提升,系统整体性能也会显著增强。

图 4 AlphaEvolve在监督学习任务中的代码进化示例
输出格式:当 AlphaEvolve 要求 LLM 修改现有代码,尤其是在较大的代码库中时,它会要求以特定格式的一系列 diff 块来提供更改内容:

在这里,<<<<<<< SEARCH 和 ======= 之间的代码是当前程序版本中要精确匹配的片段;======= 和 >>>>>>> REPLACE 之间的代码则是将替换原始代码的新片段。这样可以针对代码的特定部分进行针对性的更新。
在被进化的代码非常简短,或者相比小幅修改更适合完全重写时,AlphaEvolve 也可以配置为指示 LLM 直接输出整个代码块,而不是使用 diff 格式。
2.4 评估机制
为了在进化过程中筛选优质解,AlphaEvolve对每一个由语言模型生成的候选程序都会进行自动评估。理论上,这一过程可以看作是对用户定义的评价函数 的直接调用,即通过执行程序并计算其性能指标来衡量优劣。在实际实现中,为了提升评估效率与灵活性,系统引入了多种优化机制。
分阶段评估策略:通过构建难度逐步提升的测试集,对候选程序进行分层筛选。只有在较简单测试中表现良好的程序,才会进入更复杂的评估阶段,从而避免在低质量解上浪费大量计算资源。同时,新生成的程序通常会先在小规模任务上进行测试,以快速剔除明显错误的候选解。
LLM辅助评估:例如,对于程序的简洁性或可读性等难以通过传统指标衡量的特征,可以通过额外的LLM调用进行评分,并将结果纳入整体评价体系中,从而引导进化方向。
并行化评估:在许多应用场景中,例如多次随机初始化下的算法运行,评估任务可以在多个计算节点上同时执行。AlphaEvolve通过异步调用计算集群,实现了大规模并行评估,从而在保证搜索质量的同时,提高整体效率。
最后,系统支持多指标联合优化。即在进化过程中同时考虑多个评价标准,而非仅关注单一目标。实践表明,这种方式不仅有助于获得在多个维度上表现均衡的解,还能够通过引入多样化的“优秀样本”,提升搜索空间的探索能力,从而更容易发现新的高质量算法。
2.5 进化
在持续迭代过程中,AlphaEvolve会不断生成新的候选程序,并将其与对应的评估结果一起存储在进化数据库中。该数据库的核心作用在于记录历史探索路径,并在后续迭代中为生成新解提供参考。
在这一过程中,一个关键问题是如何在“探索”与“利用”之间取得平衡。一方面,需要不断改进当前最优解;另一方面,也必须保持一定的多样性,以避免陷入局部最优。为此,AlphaEvolve采用了一种融合MAP-Elites算法与岛屿模型思想的策略,通过维护多样化的候选解集合,实现对整个搜索空间的有效覆盖。
2.6 分布式流水线
在系统实现层面,AlphaEvolve采用了基于Python asyncio库的异步计算框架,使多个计算任务可以并发执行。当某个任务依赖其他未完成任务的结果时,会进入等待状态,从而实现高效的资源调度。
整个系统主要由三个部分组成:控制器、LLM采样模块以及评估节点。其中,控制器负责协调整个流程;LLM采样模块用于生成新的候选程序;评估节点则负责执行程序并返回结果。与传统系统侧重单次计算速度不同,AlphaEvolve更加关注整体吞吐量,即在给定计算预算下尽可能多地生成和评估候选方案,从而提高发现优质解的概率。
03
实验结果与应用分析
为了验证AlphaEvolve在不同问题类型上的有效性,论文从算法设计、数学问题以及工程系统优化三个层面进行了系统实验,结果表明该方法不仅能够复现已有最优解,还能够在多个任务上取得突破性改进。
在算法设计方面,论文重点研究了矩阵乘法这一基础问题。矩阵乘法可以被表示为张量分解问题,其核心目标是降低计算所需的标量乘法次数。实验结果如图5所示,在多个不同规模的矩阵乘法任务中,AlphaEvolve均能够达到甚至超越当前最优水平。例如,在经典的4×4矩阵乘法问题中,AlphaEvolve成功将所需乘法次数从49次降低至48次,这是对Strassen算法提出56年以来的首次改进,说明该方法具备发现新算法结构的能力。
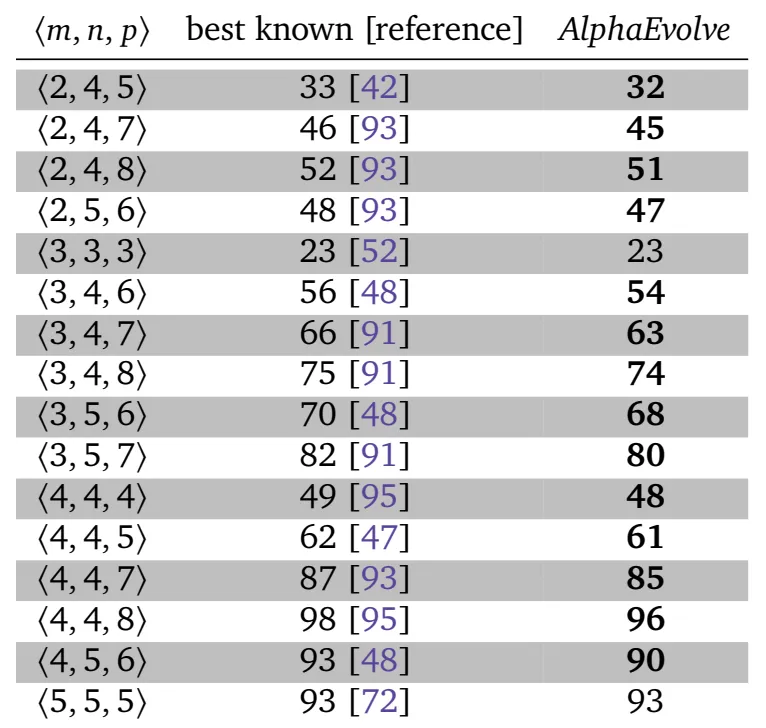
图 5 AlphaEvolve在矩阵乘法问题上的性能提升
在数学问题方面,AlphaEvolve在超过50个开放问题上进行了测试,涵盖组合数学、几何、数论等多个领域。实验结果显示,在约75%的问题上,该方法能够达到当前最优水平,而在约20%的问题上成功发现了更优解。例如,在Erdős最小重叠问题和11维Kissing Number问题中,AlphaEvolve均取得了新的最优结果。这表明该方法不仅适用于工程优化问题,也能够在理论性较强的数学问题中发挥作用。
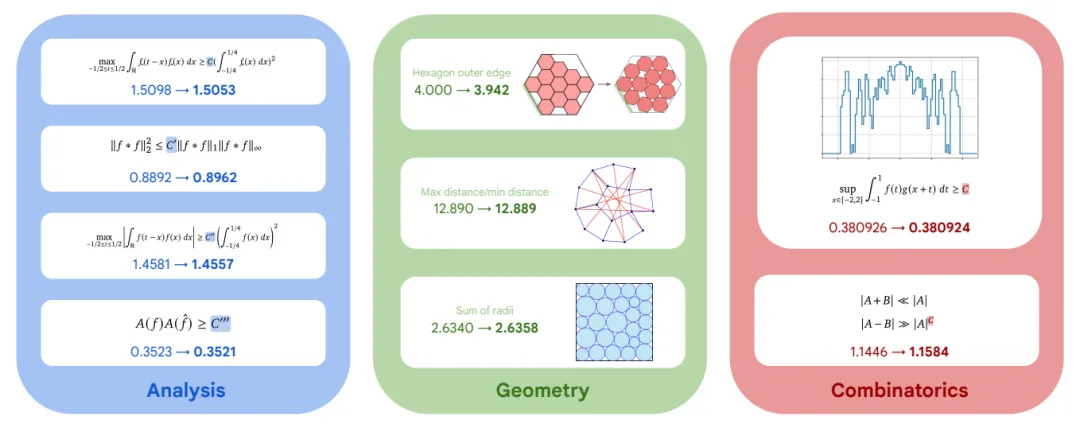
图 6 AlphaEvolve在不同数学问题上的性能提升示例
在工程系统优化方面,AlphaEvolve被应用于Google实际生产环境中的多个关键问题。其中最具有代表性的是数据中心调度问题。该问题可以被建模为一个多资源约束下的装箱(bin-packing)问题,其目标是在CPU和内存等资源限制下,将任务分配到合适的机器上,从而减少资源浪费。
AlphaEvolve通过进化调度策略函数,自动发现了一种新的启发式规则。实验结果表明,该方法在实际部署后,平均可以回收约0.7%的计算资源。这一提升虽然在数值上看似不大,但由于数据中心规模极大,其带来的实际收益非常可观。
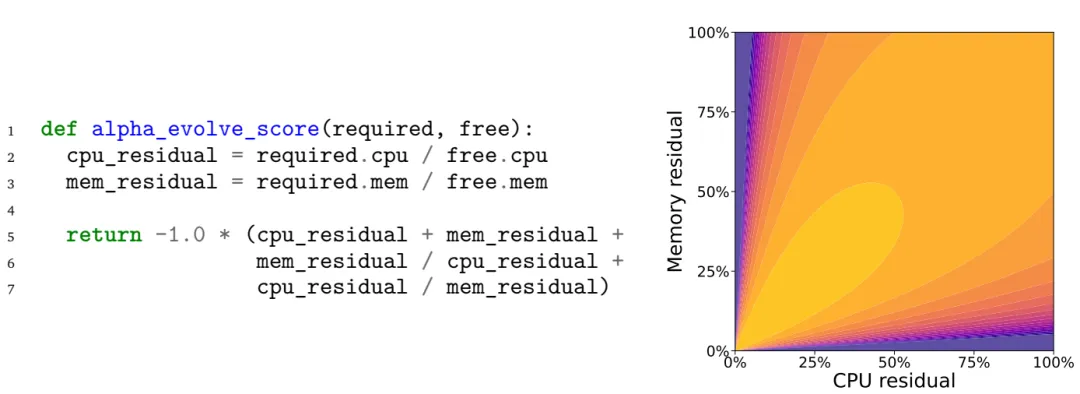
图 7 AlphaEvolve发现的数据中心调度启发式函数
04
方法本质
从方法本质上看,AlphaEvolve可以理解为一种“将算法设计问题转化为搜索问题”的通用框架。其核心在于两个前提条件:一是问题必须能够通过程序自动评估,二是候选解可以用代码形式表示。在满足这两个条件的情况下,系统可以通过不断试错与反馈,逐步逼近最优解。
与传统算法设计依赖专家经验不同,AlphaEvolve通过大规模搜索与自动评估,实现了一种数据驱动的算法发现方式。这种方法在一定程度上降低了对人工经验的依赖,使得算法设计过程更加自动化与系统化。
对于运筹优化与工业工程领域而言,这一方法具有较强的潜在应用价值。例如在调度优化、路径规划等问题中,只要能够构建合理的评价函数,就可以利用类似框架进行自动搜索,从而减少人工设计启发式算法的工作量。
05
总结
AlphaEvolve通过结合大语言模型与进化算法,构建了一个自动化算法发现系统。该系统以代码作为基本表示形式,通过自动评估机制实现闭环优化,并在多个领域取得了优于现有方法的结果。实验表明,该方法不仅能够复现已有算法,还能够发现新的、更优的算法结构。
总体而言,AlphaEvolve展示了一种新的人工智能应用范式,即通过自动化搜索与优化实现算法创新。这一研究为未来AI参与科学发现提供了新的思路,也为算法设计领域带来了重要启示。
关于我们
【南开物流】是南开大学现代物流研究中心创建和运营的公众号。旨在关注国内外物流产业发展新动态、新趋势与新问题,解读国家重大物流政策和行业发展状况,推介国内外高水平研究成果与研究方法,发布物流领域权威专家观点和南开物流学科动态,搭建产学研交流与合作平台。欢迎广大读者关注并转发本公众号内容!

更多内容 请长按二维码识别关注
声明:推文仅代表文章作者观点及译者评论观点,不代表南开物流公众号平台观点
