 夜雨聆风
夜雨聆风前几天,谷歌正式发布了Apache 2.0 完全开源协议的Gemma 4。Gemma 4是一个 31B 参数的模型,数学竞赛基准从上一代的 20.8% 直接打到 89.2%,编程能力 LiveCodeBench 从 29.1% 飙到 80%,在开源模型排行榜上一亮相就拿下全球第三。这个大模型更令人兴奋的是,它可以跑在手机上,跑在本地电脑上。觉得使用OpenClaw龙虾token贵的朋友可以考虑了,本地装上Gemma 4地,从此不再担心账单爆炸。
Gemma 4 有好几个版本,从手机到服务器都有对应:
🍃 E2B — 极轻量·端侧版
有效参数 2.3B · 128K 上下文 · 支持图片 + 音频 · 可跑在手机 / 树莓派 · 量化后不到 3GB
💻 E4B — 轻量·笔记本版
有效参数 4.5B · 128K 上下文 · 多模态 · Ollama 量化约 9.6GB · 16GB 内存笔记本可运行
⚡ 26B MoE — 性价比之王(最推荐)
总参数 252亿,推理时只激活 38亿 · 256K 超长上下文 · 量化约 14–18GB · 速度接近 4B 模型,质量接近 31B
🏆 31B Dense — 旗舰·工作站版
全量 307亿参数 · 256K 上下文 · Arena AI 开源榜 #3 · 量化约 20GB · 建议 2x RTX 4090 或 A100 80G
普通开发者和个人用户,首选 E4B 或 26B MoE。E4B 几乎任何 16GB 内存的电脑都能跑,26B MoE 需要 16–24GB 显存的独立显卡。我下面就将Gemma 4安装在16G内存的个人Windows电脑上,并让OpenClaw 接入Gemma 4。
一、安装Ollama
Ollama 是目前最便捷的本地模型运行方案,安装完毕后一条命令即可拉起 Gemma 4,就可直接对接OpenClaw。
直接上Ollama官网(https://www.ollama.com/download/windows)下载Ollama安装程序,Ollama需要Windows 10以上操作系统。
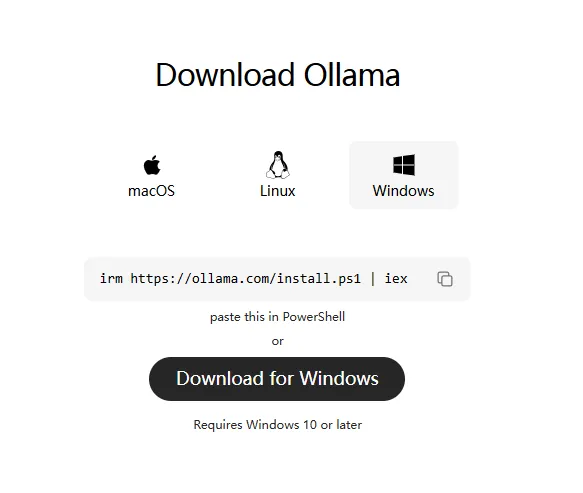
下载好安装好之后,Ollama会打开一个对话界面,并且要求登录。如下图:
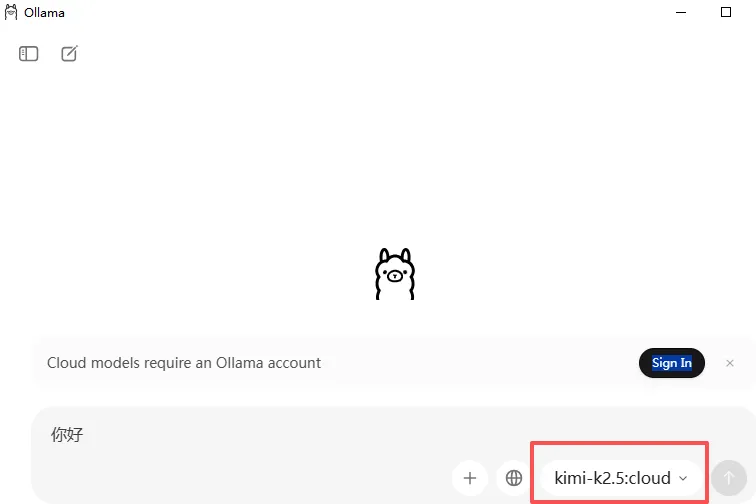
这时候选择右下角的大模型选择框,拉到下面,选择本地大模型(没有cloud结尾的),就不需要登录了。我这里选择gemma4:e2b,选择好之后,随便发几个字,如果该大模型本地还没有安装,Ollama会自动下载安装该大模型。
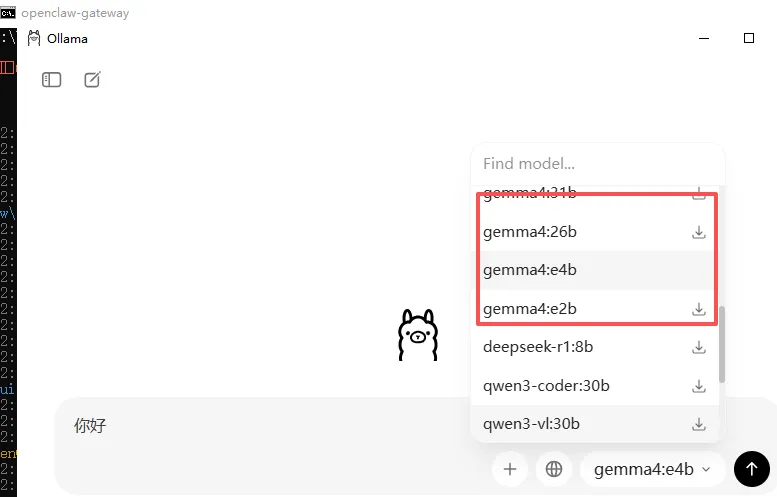
gemma4:e2b大概有8.9G大小,如果网络情况不是很好,下载到一定程度,有可能下载进程会卡住,可以关掉再重新下载,Ollama有断点续传的,重新下载不会从头开始。
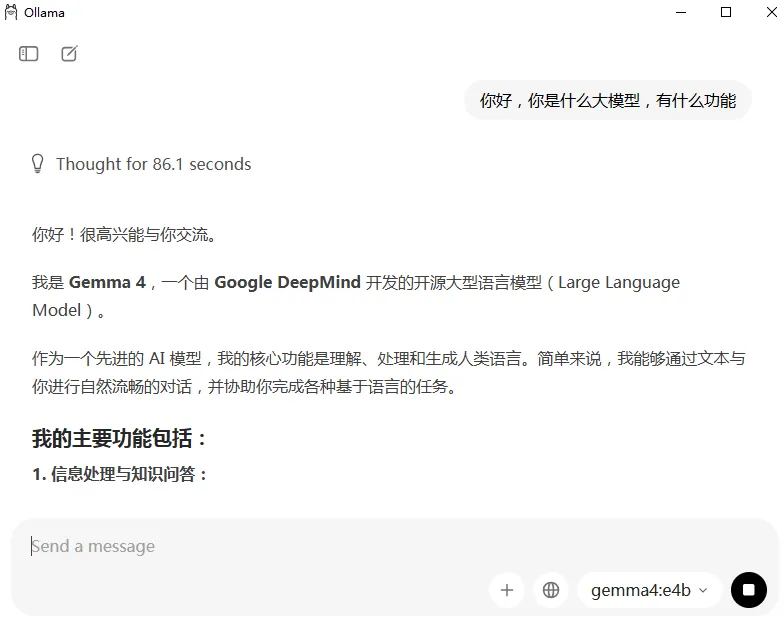
下载完成之后,在Ollama对话框,就可以和gemma 4聊天了。我电脑配置有点低,速度还是有点慢。
二、OpenClaw对接Gemma 4
命令行窗口CMD输入以下命令:
openclaw config选择models配置,然后选择Ollama。
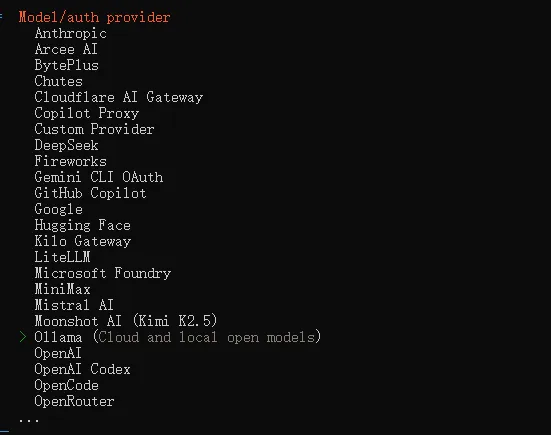
然后一直默认回车,Ollama mode 选择Local(本地大模型)
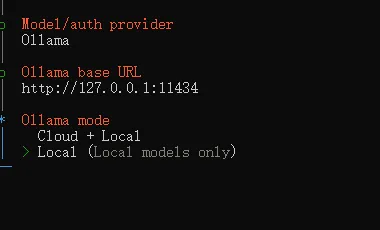
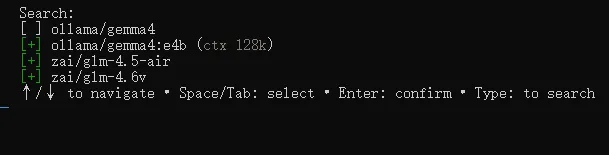
配置好之后, 重启openclaw gateway,现在OpenClaw对接的就是本地大模型Gemma了。从此,不用担心Token的问题了!
