 夜雨聆风
夜雨聆风见过不少人做完智能体 demo,信心满满地推上线,然后两周后开始疯狂打补丁。
不是模型不够强。是他们根本没意识到,demo 和 production 是两个完全不同的工程问题。
一、Demo 为什么总是成功
Demo 天生有四个生产环境不具备的优势:
输入是挑过的 路径是预设的 工具处于理想状态 边界情况根本不会被触发
所以 demo 验证的不是系统能力,而是在一组精心控制的前提下,这套系统能不能走通一次。
这有价值。但它很容易制造一种错觉:只要把当前能力再打磨一下,就能自然过渡到生产。
这个判断,是从 demo 到 production 最常见的认知陷阱。
二、Production 真正在考什么
Production(生产环境):智能体面向真实用户运行的线上状态。区别于 demo 的核心不是"规模大小",而是"是否暴露在不可控的真实输入和异常下"。
Production 难,不是系统突然变笨了,而是它终于要面对真实世界:
用户输入不规整,目标描述不完整 工具和外部接口会超时、会失败 业务规则有例外和冲突 时延和成本变成硬约束 错误不是"答得不太对",而是可能真的带来后果
Demo 时你在验证能力上限。Production 时你必须面对系统下限。
真正被放大的,不是"它最强时有多强",而是"它最差时会怎么崩"。
三、失控通常从哪里开始
场景边界没定义
我第一次把智能体推上生产时,最先崩的不是技术,而是这个:我们根本没想清楚它不该做什么。
Demo 阶段,大家更愿意展示"会做什么",没人认真定义"做到哪里该停""哪些情况该转人工""哪些场景压根不在支持范围内"。
结果系统上线后,用户输入只要稍微偏一点,它就开始:
自己脑补前提 试图回答不该回答的问题 在证据不足时依然坚持给出结论
当时我们把问题归因到"模型不稳",改了好几版 prompt,没用。后来才意识到——场景边界根本没定义清楚,prompt 再好也补不上这个洞。
Production 不是让系统显得万能,而是让系统知道哪里是它该工作的区域,哪里不是。
异常处理没成体系
Demo 只演示顺利路径。用户输入合理、工具调用成功、外部接口稳定——这些前提一旦成立,大部分智能体都能表现得不错。
但 production 的特点是:异常不是偶尔发生,而是持续发生。
工具返回超时、检索结果为空、中间状态互相矛盾、权限不足导致某步操作无法完成……
如果系统没有设计异常处理路径,表现通常有两种:
直接崩掉 不崩,但带着错误继续往下走
后者更危险。 它让问题不容易被察觉,直到最终结果完全失真才暴露出来。
工具链一旦不稳,连续失真
工具链:智能体完成任务时依次调用的一系列外部工具或 API,比如先查数据库、再调计算服务、再写回结果。
智能体通常不是只调用一次工具,而是多步依赖。前一步工具结果不稳定,很容易传导到后续步骤:
第一步信息查错 → 第二步基于错误信息规划 → 第三步调用了不该调用的工具 → 最终输出看起来完整,但整个链路已经偏得很远
这就是为什么工具链稳定性在生产里会被放大成系统问题,而不是单点问题。
没有返回校验和失败恢复机制,工具一旦出问题,智能体很难自己停在正确位置。
状态脆弱,错误被继承
多轮执行带来的代价,是状态管理变得极其关键。
状态管理:智能体在多轮执行过程中,如何保存、更新和清除中间结论、上下文信息的机制。
只要系统会记忆上下文、保留中间结论、沿着多步链路推进,就必须回答一个现实问题:当前保存的那些"状态",哪些是真实事实,哪些是临时假设,哪些已经过期?
Demo 里这个问题不明显,因为任务短、状态简单、流程受控。但任务一长、轮次一多,脆弱的状态结构就会迅速失控。
很多智能体不是死在"不会规划",而是死在"前面的错误没被隔离,后面还在引用它"。
出了问题只能靠猜
这一点几乎是 production 和 demo 最本质的区别。
Demo 可以容忍过程不透明,只要最终结果像样就行。但 production 一旦出问题,你必须能回答:
它为什么这样规划? 从哪一步开始偏的? 这是偶发问题还是系统性问题?
如果没有日志、链路追踪、回放能力,团队就只能靠猜。
而 production 最大的成本之一,就是"猜问题"。 每次猜错,都会拖慢修复节奏,降低团队对系统的信心。
四、根本原因:思维没切换
把这些问题合起来看,会发现一个规律:大部分智能体不是死在某个具体技术点上,而是死在还在用 demo 思维设计一个本该进入 production 的系统。
如果这套思维没有切换,系统即便在某些样本上表现很好,也很难进入长期可维护的生产状态。
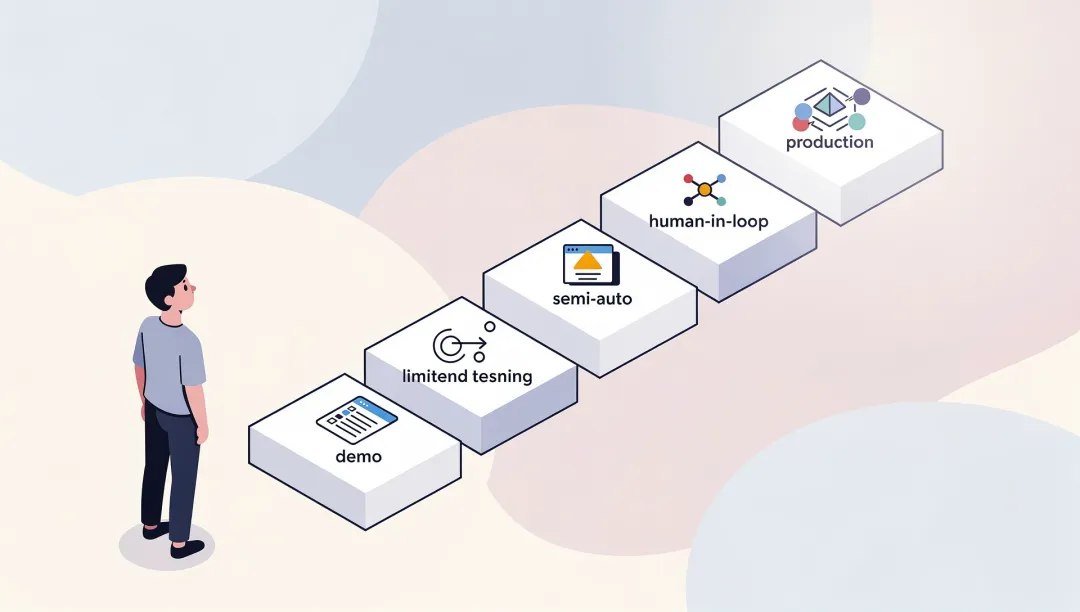
五、一个更现实的迁移路径
不建议把路径设计成"demo 成功 → 直接全面上线 → 完全自治"。这条路跨过了太多还没验证的东西。
更现实的路径:
这条路看起来慢,但它的价值在于:你能逐步把 production 需要的能力补上,而不是一次性把所有风险压到线上。
六、这篇文章没讲到的
说清楚了:几类死法、思维切换、迁移路径。
没讲清楚的:具体技术怎么做——比如状态管理用什么方案、工具链怎么加熔断、日志链路怎么设计。这些每个单独展开都是一篇文章,放这里只会变成堆砌。
另外,这篇的视角是"从 demo 往 production 推"的团队。如果你是从零开始设计生产级系统,顺序不同,很多判断也不一样。
从 demo 到 production,最容易死的不是能力,而是用"证明它能工作"的方式,去应对一个必须"保证它持续可靠工作"的系统。
这是两种完全不同的工程问题。
