 夜雨聆风
夜雨聆风由于电控原件的限制,电脑最初只认识0和1,而我们想让电脑“读懂”自然语言,本质上是 在解决一个映射问题:如何将人类离散、模糊、高维的符号系统,转换为机器可以计算 的连续、稠密、低维的数值表示。从这个角度,一场持续几十年的NLP(Nautral Langurage Processing)发展拉开帷幕
wordvector
最开始人们做的数据化尝试是词向量(wordvector)——让词语拥有“语义空间”中的坐标
最朴素的做法是独热编码,这种方式把每个词当作孤立的点,只在一个维度
(0,0,0,……0,1,0,……,0)
上展示出每个词“特有”的属性,词与词之间没有任何相似性可言,独热编码相当于字典,能同时精准表示每一个词的意思,但是也同时陷入了内存占用过大的问题
当人们尝试着优化独热向量时,Word2Vec诞生了,Word2Vec的贡献在于提出了一种基于分布的假设:一个词的含义由它的上下文决定。如果我们把一个词的向量表示记作,把它的上下文词的向量记作,那么我们希望点积能反映出共现强度。把这个点积放进Softmax里,就得到了条件概率的形式:
P(o∣c)=exp(uoTvc)∑w∈Vexp(uwTvc)P(o∣c)=∑w∈Vexp(uwTvc)exp(uoTvc)
当我们对求导时,结果恰好是“模型预测的分布减去真实分布”,在代码层面,一个简单的跳字模型训练循环大致如下:遍历文本中的每个中心词,在其窗口内采样上下文词,然后对每一对(center, context)计算损失并反向传播。负采样版本的改动在于把多分类退化为二分类,正样本是真实的上下文对,负样本则是随机抽取的无关词对——这种做法极大地降低了Softmax的分母计算开销
下面是一种实现w2v的方法
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
# 训练Word2Vec模型
sentences = [['我', '喜欢', '编程'], ['Python', '很', '强大'], ['自然语言', '处理', '有趣']]
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
# 获取词向量
vector = model.wv['编程']
# 查找相似词
similar_words = model.wv.most_similar('编程', topn=5)
# 保存和加载模型
model.save("word2vec.model")
model = Word2Vec.load("word2vec.model")
词向量的进步极大地推动了NLP的发展,像相似度比较之类的技术如雨后春笋般出现
然而,词向量是静态的,但语言是动态的。一个词在不同的句子里可能有完全不同的含义,因此我们需要一个能“看到上下文”的模型。
RNN
最简单的想法是固定窗口神经网络:把当前词前后若干个词的向量拼成一个长向量,再送入一个全连接层进行分类或预测。这种方法的优点是简单、可并行,但窗口大小限制了它能看到的范围,而且不同位置的参数是完全独立的,没有共享。
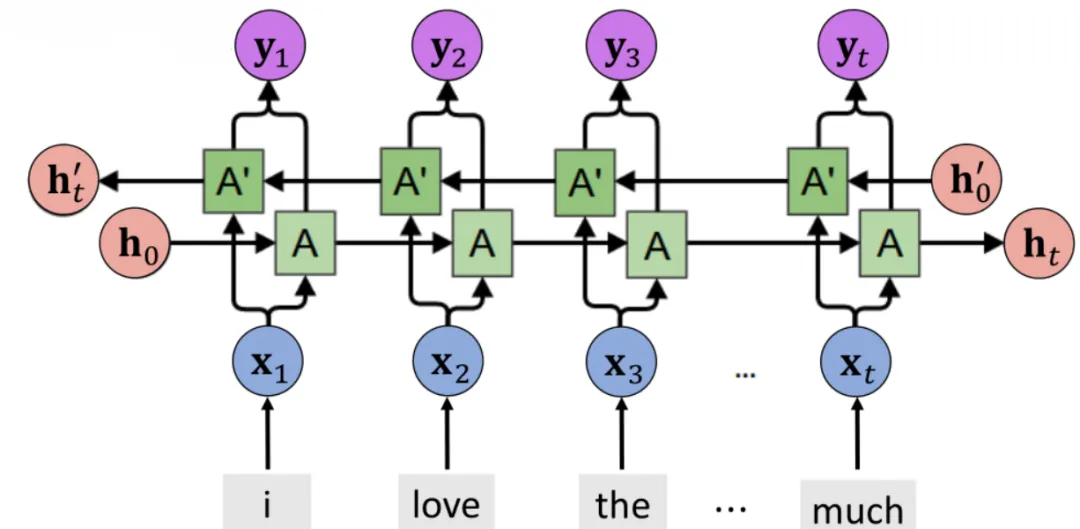
RNN的出现解决了这两个问题。它的核心是一个循环单元:隐藏状态。这个公式意味着当前时刻的状态不仅依赖当前输入,还依赖上一时刻的状态。从反向传播的角度看,损失对的梯度会经过次矩阵的连乘。如果的特征值大于1,梯度就会爆炸;如果小于1,梯度就会消失。这是RNN最核心的技术难点。
在PyTorch代码中,我们可以手动实现一个简单的RNN cell:在forward里写一个循环,依次更新隐藏状态,然后在每个时间步输出。训练时通常会使用torch.nn.utils.clip_grad_norm_来裁剪梯度,防止爆炸。
我们可以看到RNN的处理和CNN很像,都是采用了窗口遍历的方式
import torch
import torch.nn as nn
classRNNModel(nn.Module):
def__init__(self, input_size, hidden_size, output_size, num_layers=1):
super(RNNModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
defforward(self, x):
# 初始化隐藏状态
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size)
# 前向传播
out, _ = self.rnn(x, h0)
# 取最后一个时间步的输出
out = self.fc(out[:, -1, :])
return out
# 使用示例
model = RNNModel(input_size=10, hidden_size=20, output_size=2)
x = torch.randn(32, 5, 10) # (batch_size, sequence_length, input_size)
output = model(x)
LSTM(长短期记忆模型)
LSTM的解决方案很漂亮:它引入了一条叫做“细胞状态”的独立通路,更新规则是。这里的是遗忘门,是输入门,是候选记忆。关键的技术洞察在于:当接近1且接近0时,,这意味着梯度可以几乎无损地沿着细胞状态传播很远的距离。在代码层面,一个标准的LSTM单元的实现包含四个仿射变换,分别对应遗忘门、输入门、输出门和候选记忆,然后通过Sigmoid和Tanh的组合来控制信息流动。双向LSTM则是在序列的正反两个方向上各跑一遍LSTM,然后把两个方向的最终隐藏状态拼接起来——这在命名实体识别等需要利用“未来上下文”的任务中效果显著。
Seq2Seq架构把整个源序列压缩成一个固定长度的上下文向量,这显然不适合长句子。注意力机制的解决方案是:解码器在每一步生成时,不再依赖单一的上下文向量,而是去“查阅”编码器的所有隐藏状态,并计算一个加权和。具体来说,对于解码器的当前状态和编码器的每个隐藏状态,我们先计算一个得分(这是最简单的点积形式),然后用Softmax归一化成权重,最后加权求和得到上下文向量。这个再和拼接,送入输出层。下面是代码实现
import torch
import torch.nn as nn
classLSTMModel(nn.Module):
def__init__(self, input_size, hidden_size, output_size, num_layers=1, dropout=0.1):
super(LSTMModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers,
batch_first=True, dropout=dropout)
self.fc = nn.Linear(hidden_size, output_size)
defforward(self, x):
# 初始化隐藏状态和细胞状态
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size)
# LSTM前向传播
out, (hn, cn) = self.lstm(x, (h0, c0))
# 取最后一个时间步的输出
out = self.fc(out[:, -1, :])
return out
# 双向LSTM示例
classBiLSTMModel(nn.Module):
def__init__(self, input_size, hidden_size, output_size):
super(BiLSTMModel, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size,
bidirectional=True, batch_first=True)
self.fc = nn.Linear(hidden_size * 2, output_size)
defforward(self, x):
out, _ = self.lstm(x)
out = self.fc(out[:, -1, :])
return out
# 使用示例
model = LSTMModel(input_size=10, hidden_size=20, output_size=2)
x = torch.randn(32, 5, 10)
output = model(x)
但是有直觉的开发者一看就能知道这种架构的问题——我们要在一个区域内遍历我们的视觉框架,这种算法的复杂度是O(n^2)
所以,我们亟待一场在复杂度上的革命,于是乎,2016年,一篇跨时代的论文《Attention is All You Need》带来了一套全新的架构——Transformer
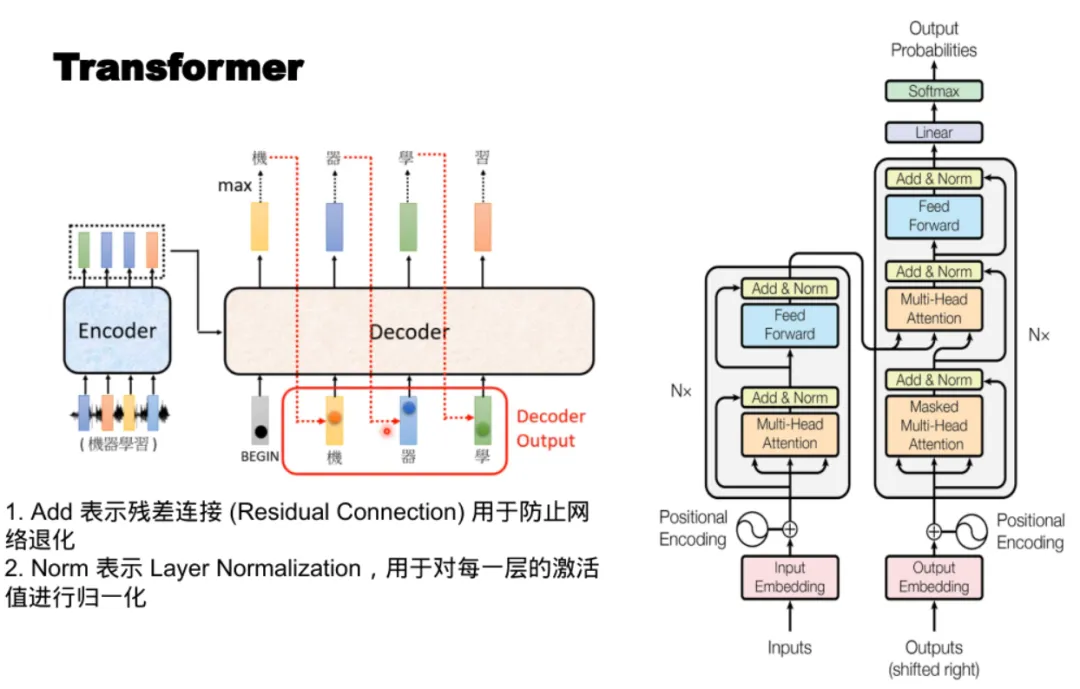
Transformer
在代码层面,实现一个点积注意力只需要几行PyTorch:
import torch
import torch.nn as nn
import math
classTransformerModel(nn.Module):
def__init__(self, vocab_size, d_model=512, nhead=8, num_layers=6, dim_feedforward=2048, dropout=0.1):
super(TransformerModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoder = PositionalEncoding(d_model, dropout)
encoder_layer = nn.TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout, batch_first=True)
self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers)
self.fc = nn.Linear(d_model, vocab_size)
self.d_model = d_model
defforward(self, src):
# 嵌入 + 位置编码
src = self.embedding(src) * math.sqrt(self.d_model)
src = self.pos_encoder(src)
# Transformer编码
output = self.transformer_encoder(src)
# 输出层
output = self.fc(output)
return output
classPositionalEncoding(nn.Module):
def__init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
defforward(self, x):
x = x + self.pe[:, :x.size(1)]
return self.dropout(x)
# 使用Hugging Face的预训练Transformer
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
model = AutoModel.from_pretrained("bert-base-chinese")
text = "这是一个测试句子"
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs)
这里除以的缩放操作是为了防止点积过大把Softmax推入梯度饱和区。这段代码看起来简单,但它背后的信息流发生了根本性的变化:梯度可以直接从解码器流向编码器的任意位置,不受距离限制。
Transformer的核心创新在于:它用自注意力替代了循环连接。对于一个序列的每个位置,我们把它映射成三个向量:查询、键、值。然后计算得到注意力矩阵,再与相乘。这个操作可以在一步内完成所有位置之间的信息交互。位置编码的加入解决了“词袋”问题:因为自注意力本身对位置不敏感,我们需要在输入嵌入上叠加一个正弦/余弦编码,或者使用可学习的位置嵌入。
在PyTorch中,一个简化版的多头注意力实现大致是:把输入的嵌入分别线性投影到组不同的空间,每组独立计算缩放点积注意力,然后把个头的输出拼接起来,再通过一个线性层。相比RNN的,Transformer的复杂度是,虽然项在长序列上显得吓人,但因为整个矩阵乘法可以被高度并行化,实际在GPU上的吞吐量远超RNN。这也是为什么现代大模型几乎全部采用Transformer架构。
多模态
让电脑“读懂”我们,不限于文本。图像、语音、视频都属于“我们的表达方式”。多模态模型的核心思想是:把不同模态的数据映射到同一个向量空间里。早期的VSE模型用一个线性变换把图像特征投影到词向量空间,通过排序损失让匹配的图文对距离更近。后来的CLIP采用了双塔结构,各自用Transformer编码图文,然后用对比学习拉近匹配对、推远不匹配对。在代码层面,这种对比损失的计算很简单:对于batch内的个图文对,我们得到图像特征矩阵和文本特征矩阵,计算相似度矩阵,然后让对角线上的个正样本的Softmax概率最大化。
一种图像识别的架构是YOLO(you only look once)
# 使用Ultralytics YOLOv8
from ultralytics import YOLO
# 加载预训练模型
model = YOLO('yolov8n.pt') # 可选: yolov8n, yolov8s, yolov8m, yolov8l, yolov8x
# 训练模型
model.train(data='coco128.yaml', epochs=100, imgsz=640)
# 推理检测
results = model('image.jpg')
# 显示结果
for result in results:
boxes = result.boxes # 边界框
result.show() # 显示带标注的图像
result.save('output.jpg') # 保存结果
# 视频检测
results = model('video.mp4', stream=True)
for result in results:
result.show()
# 实时摄像头检测
model.predict(source=0, show=True) # 0表示默认摄像头
# 自定义YOLO检测函数
import cv2
defdetect_objects(image_path, model_path='yolov8n.pt'):
model = YOLO(model_path)
results = model(image_path)
for r in results:
im_array = r.plot() # 绘制检测结果
cv2.imshow('Detection', im_array)
cv2.waitKey(0)
cv2.destroyAllWindows()
return results
# YOLO模型配置示例
from ultralytics import YOLO
# 自定义训练配置
model = YOLO('yolov8n.yaml') # 从配置文件构建新模型
# 训练参数设置
results = model.train(
data='custom_dataset.yaml',
epochs=100,
imgsz=640,
batch=16,
device='cuda', # 使用GPU
workers=8,
lr0=0.01,
augment=True
)
# 模型评估
metrics = model.val()
# 导出模型到不同格式
model.export(format='onnx') # 导出ONNX格式
model.export(format='torchscript') # 导出TorchScript格式
YOLO的核心创新在于将目标检测重构为单一的回归问题,通过一次前向传播直接从图像像素预测边界框和类别概率,彻底摒弃了传统方法中耗时的“区域提议+分类”两阶段流水线。这种端到端的设计使其检测速度达到实时级别(45-155 FPS),同时通过全局推理有效降低了背景误检率。
更精细的控制来自FiLM:它用文本特征生成一组缩放和平移参数,然后对图像特征做逐通道的仿射变换。这个操作的代码不过一两行,但它赋予了文本“指导”图像特征提取过程的强大能力。
回顾整个NLP的进化史,一个有趣的视角浮现出来:所谓“读懂”,本质上是在训练一个越来越好的预测器。Word2Vec在预测上下文,RNN在预测下一个词,Seq2Seq在预测翻译后的句子,而Transformer的自注意力机制则是在预测每个位置与其他位置的相关性。每一次架构的迭代,都在让这个预测器变得更精准、更高效、更能捕捉语言的深层结构。
当我们最终能训练出一个模型,它能根据一段文字生成逼真的图像,或者根据一幅图像写出准确的描述时,虽然那只是重复计算后的最优解问题,但是当神经网络不断加深,联系不断加强,也许我们可以说:电脑真的“读懂”了我们。
