 夜雨聆风
夜雨聆风阅读时长:约 15 分钟
适合人群:想搞清楚 AI 为什么"忘事"、RAG 是什么东西的你
你有没有遇到过这种情况:
第一轮对话,你告诉 AI "我叫张三,是个 Python 开发者"。第二轮对话,你问它"你还记得我的情况吗?"——
它说:不知道你是谁。
明明就在刚才,它怎么就忘了?
今天这篇文章,我们就来聊两件事:AI 为什么会忘事,以及怎么让它不忘事、还能从你给的文档里找到答案。
先讲讲 AI 为什么"失忆"
大语言模型在设计上是无状态的。
什么意思?每一次 API 调用,对模型来说都是全新的开始。它不会自动记住上一次对话。你昨天告诉它的事,今天它一无所知。
这带来了几个实际问题:
• 个性化消失:AI 不记得你的偏好、习惯、背景 • 上下文断裂:长对话中,早期信息会因为窗口限制而"溢出" • 前后矛盾:多轮对话可能出现自相矛盾的回答
除了失忆,还有另一个问题:AI 的知识是静态的。
它的知识来自训练数据,有时间截止点。你问它昨天发生的新闻?不知道。你给它一份公司内部文档,让它回答具体问题?它根本没见过这份文档。
这两个根本局限,是这章要解决的核心问题:
• 记忆系统——让 AI 记住对话历史和用户信息 • RAG(检索增强生成)——让 AI 从你提供的文档里找答案
第一部分:记忆系统——给 AI 一个"大脑"
人类记忆系统给的启发
认知科学告诉我们,人类记忆分三层:
借鉴这个框架,AI 智能体的记忆系统也被设计成四种类型:
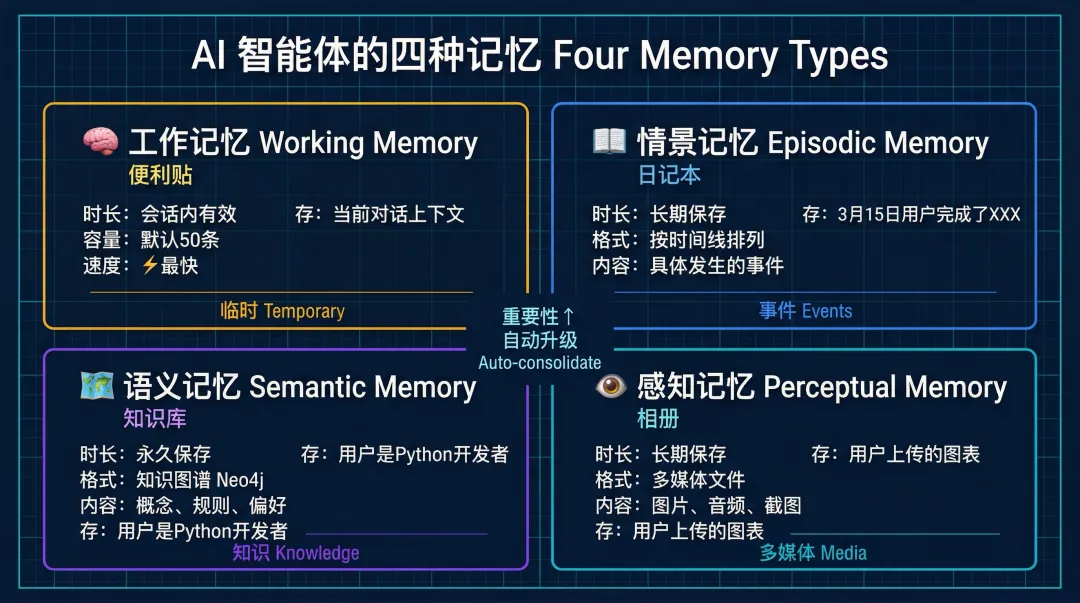
四种记忆,各司其职
🧠 工作记忆(Working Memory)
相当于 AI 的"便利贴"——存储当前对话的临时信息,会话结束后自动清除。容量有限(默认 50 条),访问速度最快。
适合存:刚才用户问了什么、本次对话的上下文。
📖 情景记忆(Episodic Memory)
相当于 AI 的"日记"——记录具体发生过的事件,按时间线排列。
适合存:用户在某月某日完成了某个任务、历史上问过哪些问题。
比如:"2024年3月15日,用户张三完成了第一个 Python 项目" → 这是一条情景记忆。
🗺️ 语义记忆(Semantic Memory)
相当于 AI 的"知识库"——存储抽象的概念、规则、用户偏好。
适合存:用户是 Python 开发者、用户喜欢简洁的回答风格、Python 是面向对象语言。
语义记忆还用了知识图谱(Neo4j)存储实体和关系——AI 不只知道"Python 是一门语言",还知道"Python 常用于机器学习"、"机器学习是 AI 的子领域",这些关联可以支持复杂的推理。
👁️ 感知记忆(Perceptual Memory)
相当于 AI 的"相册"——存储图片、音频等多媒体信息,支持跨模态检索。
适合存:用户上传的图表、截图、录音。
记忆的生命周期
记忆系统最有意思的地方,是它模拟了人类大脑的遗忘和整合机制:
遗忘(Forget)——三种策略:
• 删除重要性低的记忆(比如随口一说的话) • 删除太久没用的记忆(超过 30 天的旧内容) • 当存储快满时,删除最不重要的记忆腾出空间
整合(Consolidate)——类似人类睡眠时把短期记忆转化为长期记忆的过程:
重要性 > 0.7 的工作记忆 → 自动升级为情景记忆重要性 > 0.8 的情景记忆 → 自动升级为语义记忆(变成持久知识)
这样,真正重要的信息会被长期保留,而临时的、不重要的信息会被自动清理。
一句话总结记忆系统
AI 的记忆系统 = 工作台(工作记忆)+ 日记本(情景记忆)+ 知识库(语义记忆)+ 相册(感知记忆),还配了自动整理和遗忘机制。
第二部分:RAG——让 AI 读懂你的文档
什么是 RAG?
RAG = Retrieval-Augmented Generation,检索增强生成。
一句话解释:在 AI 生成回答之前,先去你的文档里搜相关内容,把搜到的内容塞进提示词,然后再回答。
这样,AI 回答的就不是它训练时见过的内容,而是你给它的文档里的内容。
RAG 解决的正是"AI 知识有截止日期"和"AI 不知道你的内部文档"这两个问题。
RAG 的三个时代
第一代:关键词搜索(2020-2021)
像百度一样,用 TF-IDF 等关键词匹配找文档。效果还行,但不理解语义——你搜"大语言模型",它找不到写着"LLM"的段落。
第二代:语义向量检索(2022-2023)
把文字转成高维向量,用相似度计算找相关内容。"大语言模型"和"LLM"在向量空间里距离很近,能被匹配到。这是目前主流方案。
第三代:模块化 RAG(2023至今)
加入了查询扩展、假设文档嵌入等高级技术,检索精度更高,还能结合知识图谱做多跳推理。
RAG 怎么处理你的文档?
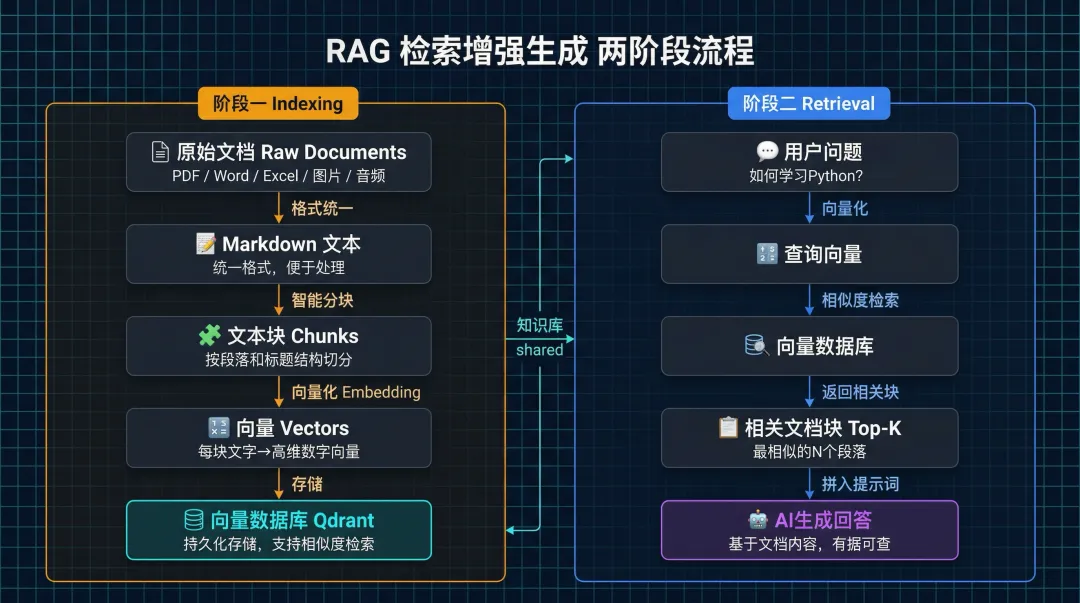
整个流程分两个阶段:
阶段一:建立知识库
你的文档(PDF/Word/Excel/图片/音频) ↓ 统一转成 Markdown 格式 ↓ 按段落和标题结构分成小块(分块) ↓ 每块文字转成向量(嵌入) ↓ 存进向量数据库(Qdrant)这里有个设计亮点:所有格式的文档都先统一转成 Markdown,这样无论是 PDF 的章节、Excel 的表格、还是图片里的文字(OCR),都用同一套分块逻辑处理。
两个让检索更准的黑科技
多查询扩展(MQE)
同一个问题,用不同的方式问,能找到更多相关内容。
比如你问"如何学习 Python",系统会自动扩展出:
• "Python 入门教程" • "Python 学习方法" • "Python 编程指南"
这三个查询并行检索,结果合并,召回率提升 30-50%。
假设文档嵌入(HyDE)
这个更有趣:先让 AI 编一个可能的答案,再用这个"假答案"去搜真答案。
为什么有效?因为问题(疑问句)和答案(陈述句)在语义空间里的分布不同——用"假答案"去搜,比直接用问题去搜更精准。
特别适合专业领域:AI 生成一段包含专业术语的假设答案,再用这段话搜索,能精准命中领域文档。
第三部分:两者结合——一个 PDF 问答助手
把记忆系统和 RAG 结合,能做什么?
来看一个真实案例:基于 PDF 的智能学习助手。
它能做什么?
1. 上传 PDF 文档(比如一本技术书的 PDF) 2. 用自然语言提问:AI 从书里找相关段落,再给出有据可查的回答 3. 记学习笔记:笔记存到语义记忆,下次可以检索 4. 回顾学习历程:从情景记忆里查"我上周学了哪些内容" 5. 生成学习报告:整合所有学习数据,输出 JSON 格式报告
记忆和检索怎么配合?
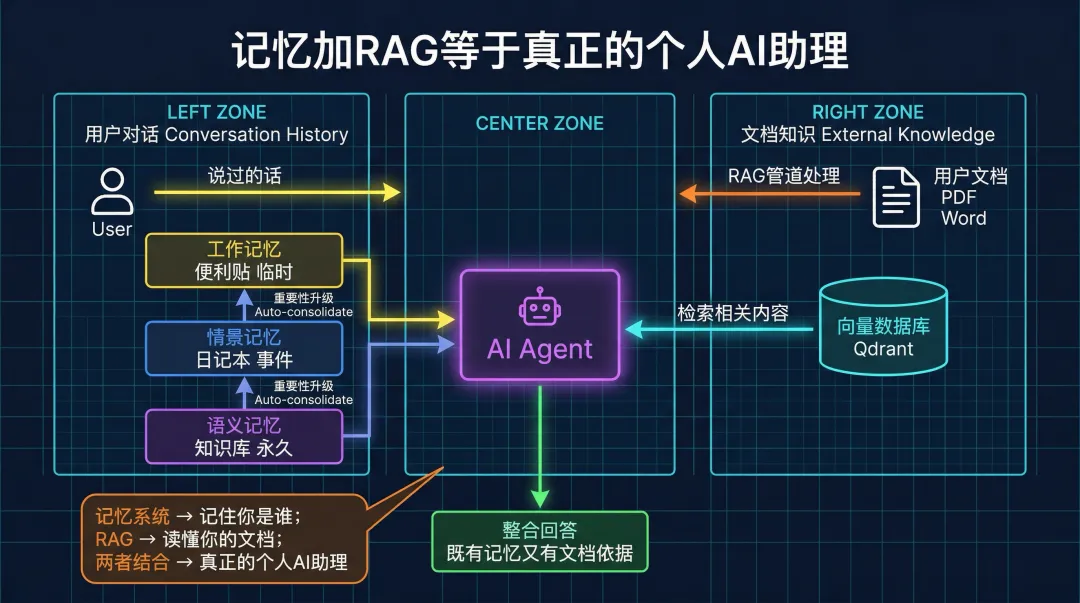
两者的分工很清晰:
• RAG 负责"外部知识"——你给它的文档 • 记忆系统负责"交互历史"——你说过的话、做过的事
一张图看懂这章
写在最后
AI 的"失忆"问题,从技术上早有解法——只是大多数产品还没完全把这些能力开放给普通用户。
记忆系统让 AI 真正"认识你";RAG 让 AI 真正"读懂你的资料"。两者结合,才是真正意义上的个人 AI 助理。
这不是遥远的未来,而是已经可以用代码实现的今天。
*本文内容整理自 Datawhale《Hello Agents》
觉得有收获?点个赞告诉我 👇
