 夜雨聆风
夜雨聆风
「如果AI能读懂生命40亿年的进化历程,那它就能学会生命的语法——然后用它来写新的故事。」
2026年3月4日,国际顶级学术期刊《Nature》正式发表了一项里程碑式研究:由Arc研究所、英伟达、斯坦福等机构联合发布的 Evo 2,成为迄今为止规模最大、能力最强的生物学AI基础模型。
这个基于超过12.8万个物种、9.3万亿个核苷酸训练而成的AI,不仅能以前所未有的精度解读遗传密码,更具备了主动「阅读」「书写」乃至「设计」基因序列的能力。
这意味着什么?
从精准预测疾病突变,到设计对抗超级细菌的合成噬菌体;从揭开基因调控的奥秘,到为未来农业提供精准的设计工具——AI驱动生物学时代的真正来临。
“大家好!这里是木申社,我是行业观察家——申社长,在这里,我们洞察科技与商业,畅聊生活与未来。”
为什么需要 Evo 2?

理解 Evo 2的意义,需要先理解它的前代 Evo 1
2024年,Arc研究所团队在《Science》发表 Evo 1,通过270万个原核生物和噬菌体基因组进行训练,证明深度学习可以无监督地学习DNA逻辑——就像大语言模型学习写文章一样。
但 Evo 1有一个致命局限:只能处理单细胞生物。
对于人类、动植物这类拥有复杂调控网络的真核生物,Evo 1完全无能为力。原因很简单:真核生物的基因组里,大部分区域是「非编码区」,这些区域没有蛋白质编码功能,却藏着基因调控的核心秘密——而它们的信息密度远低于细菌基因组,让模型训练难上加难。
Evo 2的出现,就是为了跨越这道鸿沟。
它不再满足于「读懂」某个物种或某类序列,而是要通晓整个生命之树在数十亿年进化中形成的「通用语言」与「语法规则」。
这堪比NLP领域从特定领域模型到ChatGPT的飞跃——只不过这次,AI学的不再是人类的语言,而是DNA的语言。
Evo 2 为什么能做到?
如果说AlphaFold破解了蛋白质折叠之谜,那么Evo 2则要回答一个更根本的问题:生命的底层代码究竟遵循怎样的语法规则?
1. 训练规模:数据量是 Evo 1的30倍
团队为Evo 2构建了一个堪称「数字生命宇宙图书馆」的训练数据集——OpenGenome2。
这个数据集包含:
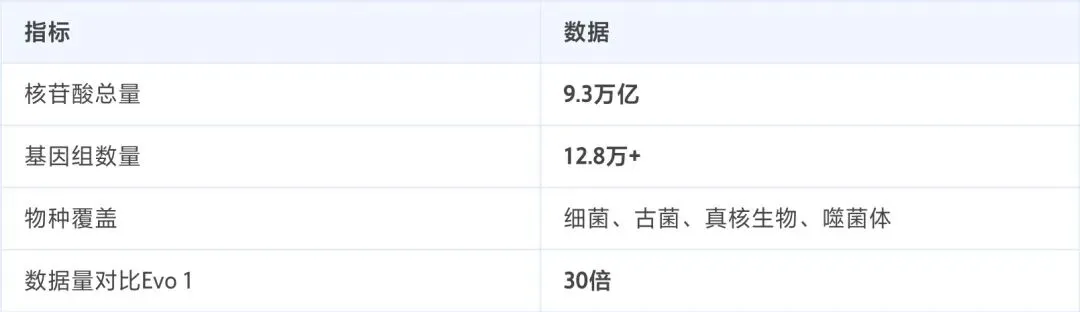
覆盖了所有已知生命领域,确保模型获得的是真正普遍、通用的「基因组语言学」知识。
当数据量突破某个临界点时,AI开始涌现出对生命本质的直觉理解——不是机械的记忆,而是某种类似于「生物直觉」的能力。
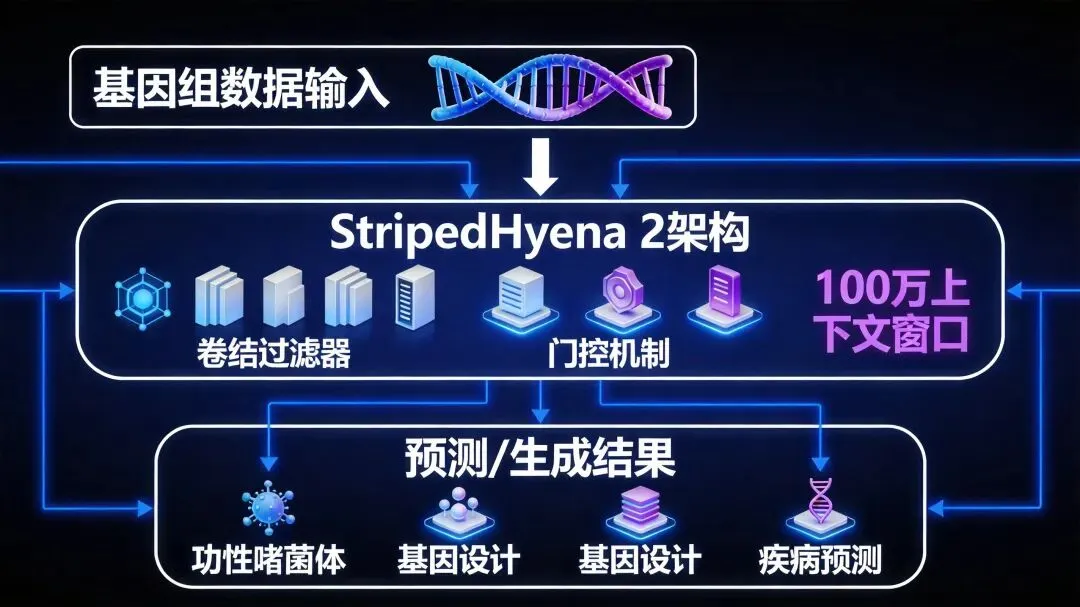
2. 架构革新:StripedHyena 2
处理如此浩瀚的遗传信息,传统Transformer架构在计算效率和长程建模上遇到了瓶颈。
Evo 2创新性地采用StripedHyena 2架构——由OpenAI联合创始人Greg Brockman在学术休假期间参与贡献。这个架构:
将卷积过滤器与门控机制结合
能够一次性处理100万个核苷酸(比 Evo 1长8倍)
在100万上下文长度下,吞吐量比高度优化的Transformer基线提升3倍
为什么「百万级上下文」如此重要?
因为基因组中的功能关系往往跨越极远距离:增强子-启动子环路、基因簇、重复元件、三维基因组结构……更大的上下文窗口意味着更完整的生物学推理能力。AI终于能够一次性审视完整的基因片段,而非支离破碎的碎片。
3. 训练算力:2000+颗H100 GPU
支撑这一宏伟训练的,是超过2000颗英伟达H100 GPU在AWS DGX Cloud平台上提供的澎湃算力。耗时数月的训练,不仅是为了获得更高的预测精度,更是为了让模型通过海量数据产生「进化」。
英伟达近乎奢侈的硬件投入,换来的是模型对生命进化规律的深度理解。
Evo 2 的真实能力
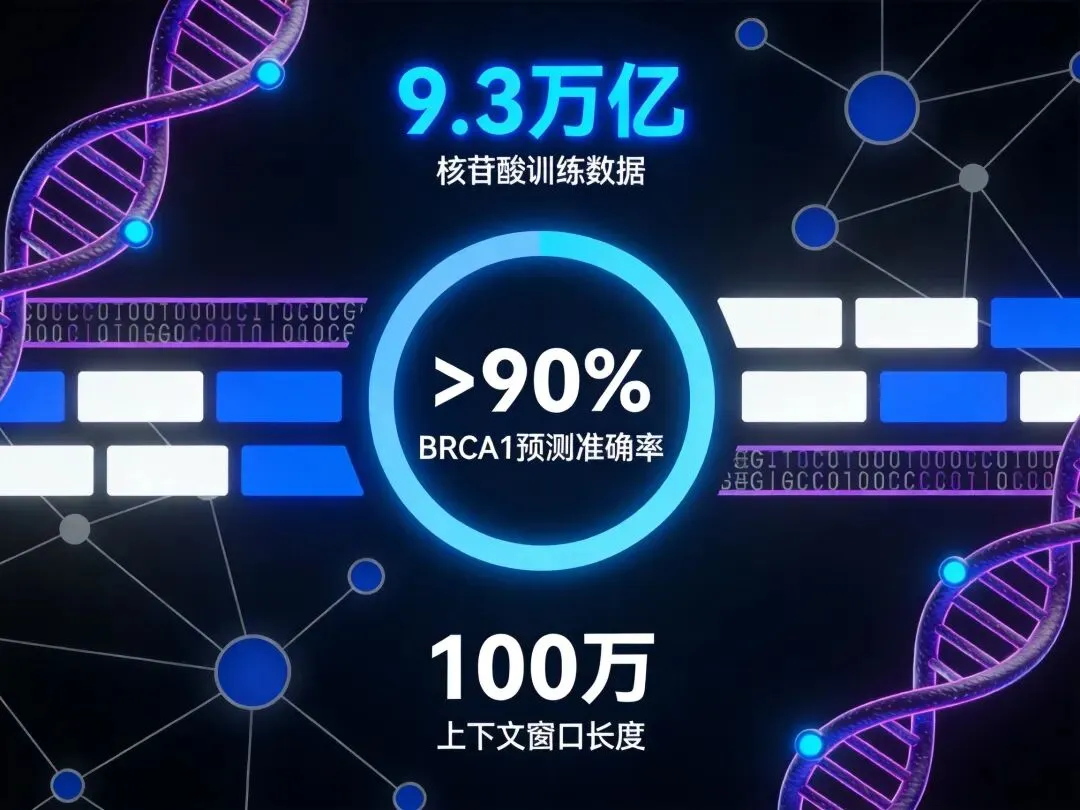
让我们用具体数据来看看 Evo 2 的真实能力
疾病突变预测:BRCA1准确率超90%
在区分乳腺癌相关基因BRCA1的有害突变与良性多态性时:
Evo 2 40B模型零样本预测:准确率超过90%
基于Evo 2嵌入训练的岭回归分类器:AUROC达到0.95,AUPRC达到0.88
这意味着什么?
临床上大量「意义未明变异(VUS)」是遗传诊断师的噩梦。传统方法对BRCA1基因突变的临床验证往往需要数月时间。现在,AI可以在数小时内完成初步筛查,为医生提供决策参考。
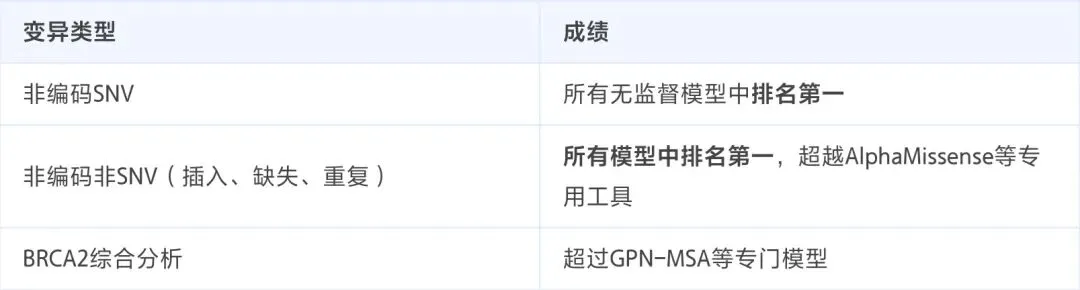
2. 非编码变异预测:全面领先
3. 基因组生成:已验证功能性
Evo 2 不仅仅能预测,更能设计
研究团队进行了一系列验证实验。他们让AI设计简化基因组序列,包括生殖支原体和人类线粒体的精简版本。AI生成的序列被导入活细胞后,不仅存活下来,还正常执行了预设的生物学功能。
更惊人的是:
功能性噬菌体:AI设计的序列被合成后,导入大肠杆菌竟然真的产出了活病毒——这些病毒虽然经过人工设计,但具有真实的感染能力
人类线粒体基因组:生成序列的pLDDT得分达到0.67-0.83(与天然蛋白高度相似)
引导式基因组设计:在染色质可及性区域设计中实现Morse code编码,实验验证AUROC 0.92-0.95
这已经不是“模拟”或“预测”了,而是真正的“创造”。当AI设计的DNA能够在现实世界中执行预设功能时,合成生物学的研究范式正在发生根本性转变。
合成生物学的万亿风口
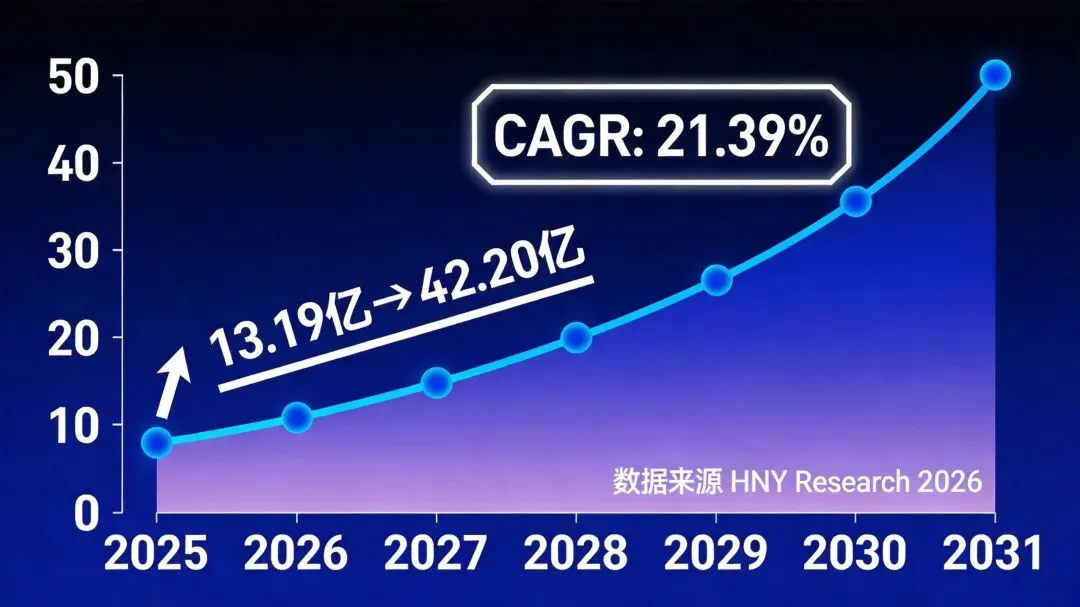
任何一项技术的价值,最终都要在市场中得到检验。合成生物学赛道正在高速增长。
根据HNY Research 2026年2月发布的报告,2025年全球合成生物学市场规模已达13.19亿美元,预计到2031年将增长至42.20亿美元,年复合增长率高达21.39%。
这是一个典型的加速增长市场——技术成熟度提升、应用场景拓展、成本持续下降,三个飞轮正在同时转动。
在这场盛宴中,英伟达的野心显而易见。凭借在GPU领域的绝对主导地位和对BioNeMo平台的持续投入,英伟达目前占据合成生物学AI市场11.90%的份额,位列第三,仅次于IBM和微软。
但这并不意味着英伟达处于劣势——当整个行业都需要算力支撑时,手握H100的王牌供应商正在悄然占据价值链的核心位置。
让我们看看英伟达最新的财务数据。2026财年(2025年2月至2026年1月),其数据中心业务收入高达1937亿美元,同比增长68%,毛利率维持在75%的高位,业务占比达89.8%。
这些数字背后,是一个简单的商业逻辑:市场在扩张,而英伟达占据了技术制高点。
合成生物学的研发流程正在重构
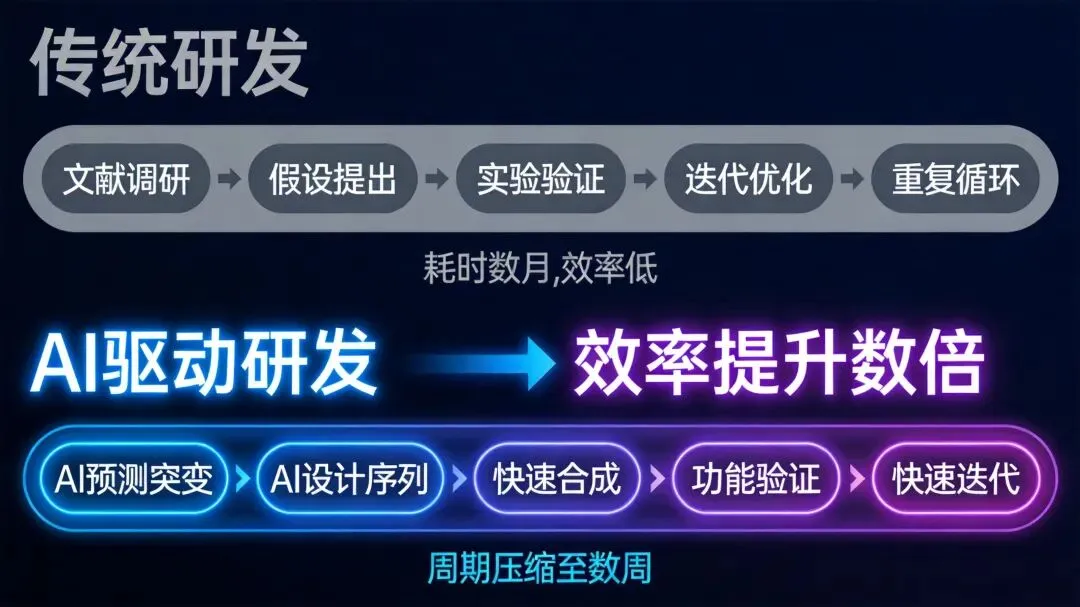
从「预测」到「设计」的闭环
传统合成生物学研发路径是:文献调研→假设→实验验证→迭代。每个环节都耗时耗力。
以噬菌体设计为例:传统方法需要筛选数百万候选序列,湿实验成本可达数百万美元。
Evo 2展示了一种全新的范式:AI预测突变效应 → AI设计候选序列 → 合成验证 → 功能确认
理论上可将研发周期从「数月」压缩到「数周」。
通过计算机完成初筛,将需要实验验证的候选序列数量降低几个数量级。
应用场景全面扩展

给从业者的行动建议
1️⃣ 技术栈升级
对于希望在合成生物学领域建立竞争力的从业者而言,技术栈的升级已经不再是“要不要做”的问题,而是“如何做好”的问题。
在算力层面,你需要认真评估云端GPU与本地算力的平衡点。云端的优势在于弹性扩展,对于初期投入有限的小团队尤其友好,通过API调用可以大幅降低入门门槛。但如果你有持续稳定的大规模计算需求,本地部署可能是更经济的选择。
数据的标准化同样关键。生物数据格式繁多、来源各异,如果不能在预处理阶段实现统一,后续很难高效接入大模型。建议从FASTA文件格式标准化开始,逐步建立规范的数据清洗流程。
最后,验证实验的自动化不可或缺。传统的手工实验模式正在被“设计-合成-测试”的闭环流程所取代。
2️⃣ 研发流程重构
AI时代的研发流程需要彻底重构
传统模式是:提出假设→设计实验→手工执行→等待结果→分析数据→提出新假设。这是一个以“周”为单位计算的漫长循环。
AI驱动的新模式则完全不同。你可以在同一时间评估数千个基因变体组合,实验结果自动结构化存储并反馈给AI系统,AI再基于数据进行下一轮优化。这意味着实验迭代从“周”压缩到“小时”级别。
这要求从业者打破生物学、AI、自动化三个学科之间的知识壁垒。未来的明星人才,是那些既能理解生物系统复杂性,又能与AI协同工作,还能设计自动化实验流程的跨学科复合型选手。
3️⃣ 商业化价值表达
技术价值最终需要转化为商业价值。在与客户沟通时,学会量化你的价值主张远比描述技术原理更有效。
你可以这样表达:引入AI辅助设计后,客户可以减少50%的实验迭代次数;候选分子的发现周期从18个月压缩到6个月;AI预测的毒性风险和脱靶效应准确率大幅提升。
这些具体的数字,比任何技术术语都更有说服力。
冷静看待 Evo 2
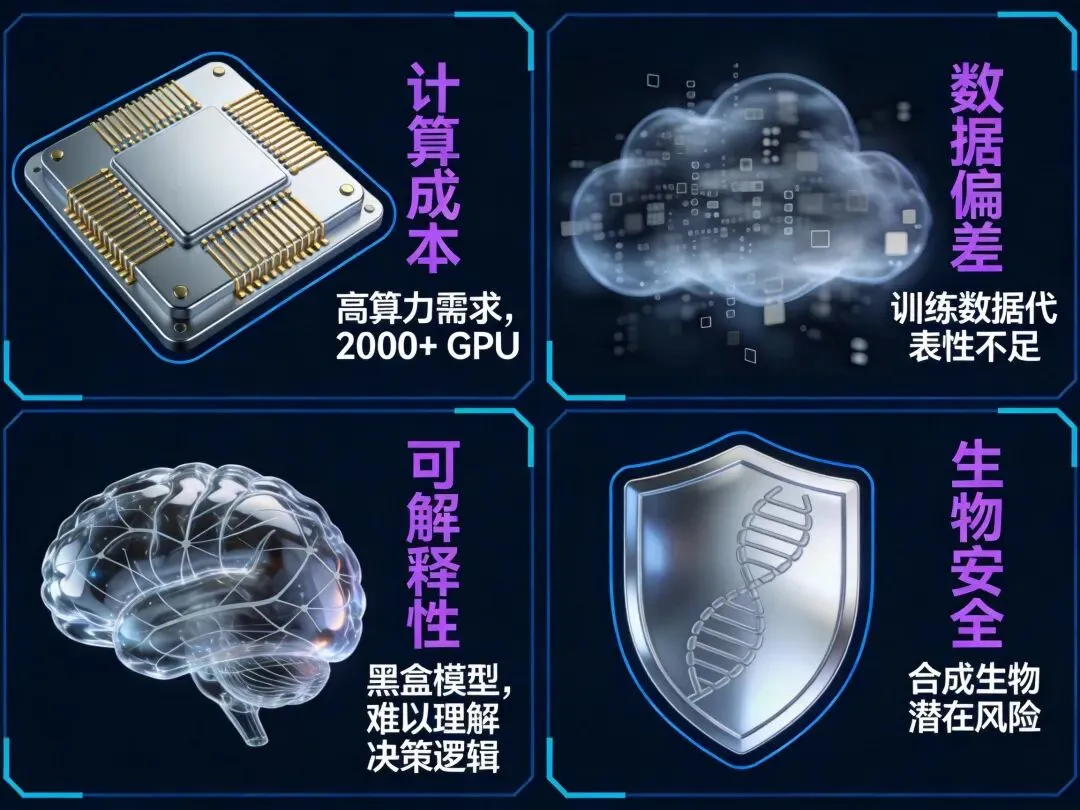
当然,Evo 2 并非万能
在蛋白质DMS基准测试上性能开始饱和,在最大模型规模上可能下降
生成的基因组序列尚缺乏一些必需基因
细胞类型特异性染色质设计仍有挑战(仅17%的差异设计实现超过2倍特异性)
从实验室设计到大规模实际应用,仍面临合成成本和验证周期挑战
理解局限,才能更好地应用。
写在最后
Evo 2 的诞生,是人工智能与生命科学深度交汇的一座里程碑。
它通过吸收整个生命之树的进化印记,获得了理解基因组「通用语法」的能力——就像一个学会了所有语言的人,终于能够听懂生命在40亿年里写下的这部无标点的天书。
而现在,它不只是读者,更是作者。
当AI能够以超过90%的准确率预测基因功能,并设计出在现实世界中真正可用的生物序列时,我们不得不重新思考"生命设计"的边界在哪里。
对于从业者而言,核心挑战已经不再是"能否用AI",而是"如何最有效地将AI融入研发全流程"。那些率先掌握AI+自动化工具的团队,将在未来的竞争中占据先机。
Evo 2完全开源(模型权重、训练代码、推理代码、数据集),这是迄今为止所有模态中最大的完全开源模型之一。开放的生态将加速合成生物学工具的民主化。
英伟达数字生物学总监Anthony Costa表示:「通过开源这些能力,我们为全球科学家提供了一个解决人类健康挑战的新伙伴。」
未来十年,最大的生物技术突破可能不是来自某个实验室的偶然发现,而是来自某个团队精心设计的计算蓝图。
生命,正在变成一门可以被工程化的语言。
📚 数据来源
Brixi, G., et al. (2026). Genome modeling and design across all domains of life with Evo 2. Nature. DOI: 10.1038/s41586-026-10176-5
Arc Institute官方发布 (https://arcinstitute.org)
HNY Research市场报告(2026年2月)
NVIDIA 2026财年Q4及全年财报
NVIDIA BioNeMo Framework文档
📕 推荐阅读
[Arc Institute GitHub - Evo 2]
(https://github.com/arcinstitute/evo2)
[Evo Designer在线体验]
(https://evo-designer.arc.com)
[Nature论文全文]
(https://www.nature.com/articles/s41586-026-10176-5)
💬 互动话题
你在工作中是否接触过AI辅助基因分析?
在使用过程中遇到过哪些挑战?欢迎评论区分享!
本文部分图片与文字由AI生成
