 夜雨聆风
夜雨聆风一、I/O核心子系统
知识总览
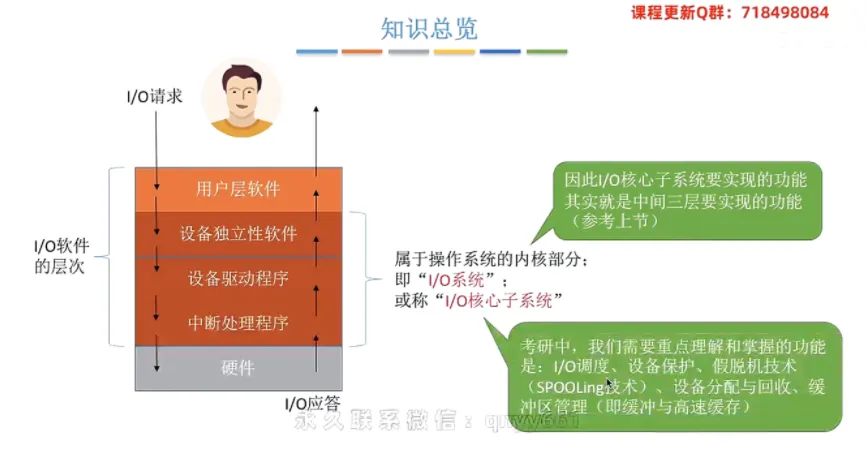
① I/O核心子系统的范畴
物理位置:
I/O核心子系统属于操作系统的内核部分。包含层级:主要由
I/O软件结构中的中间三层构成,即设备独立性软件、设备驱动程序和中断处理程序。
② 核心功能盘点
🔥 ⭐⭐⭐ 重点掌握的核心功能 ⭐⭐⭐
根据考研大纲要求,我们需要重点理解和掌握的
I/O核心功能主要有以下五项:I/O调度、设备保护、假脱机技术(即SPOOLing技术)、设备分配与回收、缓冲区管理(即缓冲与高速缓存管理)。
功能实现层次
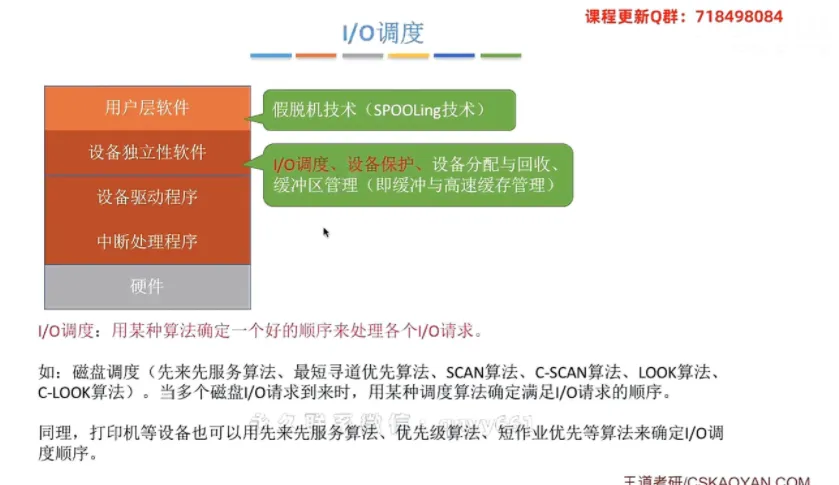
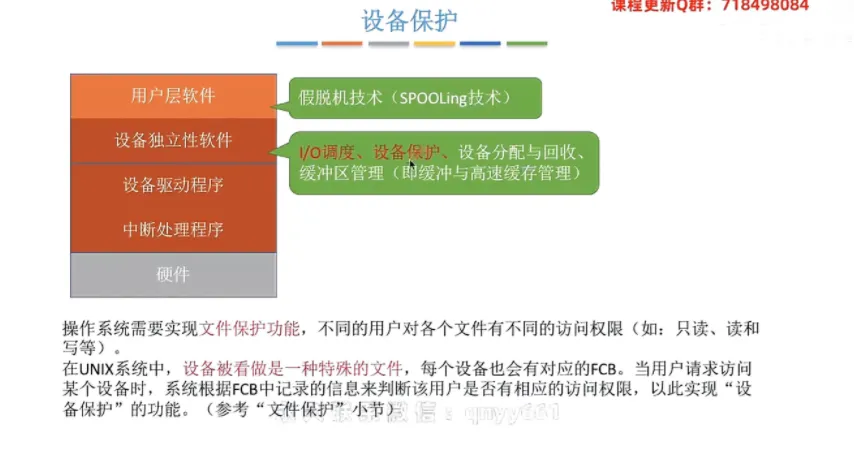
① 核心功能的归属层级
绝大多数与具体底层硬件细节无关的宏观管理功能,例如
I/O调度、设备保护、设备分配与回收、缓冲区管理以及假脱机技术等,都是在设备独立性软件这一层实现的。
② 关键功能原理解析
I/O调度:其核心思想是用某种特定的调度算法,确定一个良好的顺序来处理各个进程发来的I/O请求。例如:当多个磁盘
I/O请求到来时,系统会采用先来先服务算法、最短寻道优先算法或电梯算法来确定响应顺序;打印机等设备也可以采用优先级算法或短作业优先算法来进行调度。设备保护:在操作系统(如
UNIX)中,设备被看作是一种特殊的文件,每个设备在系统中都有对应的FCB(文件控制块)。当用户请求访问某个物理设备时,系统会根据其对应
FCB中记录的权限信息,来严格校验该用户是否有相应的访问权限(如只读、读写等),从而实现设备保护。
二、假脱机技术
什么是脱机技术
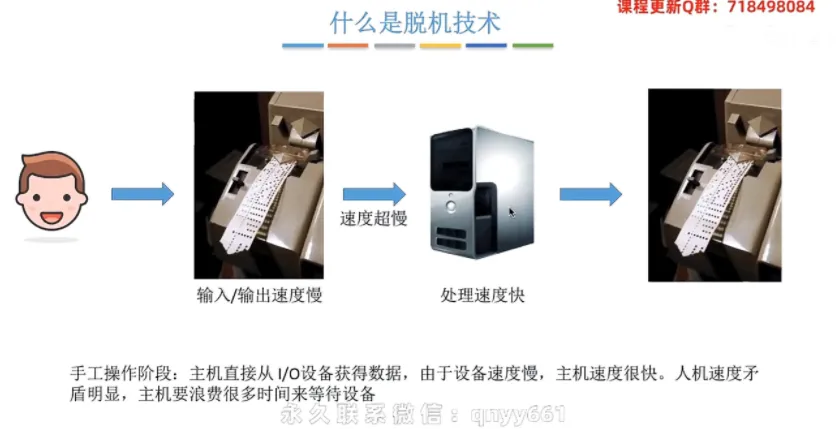
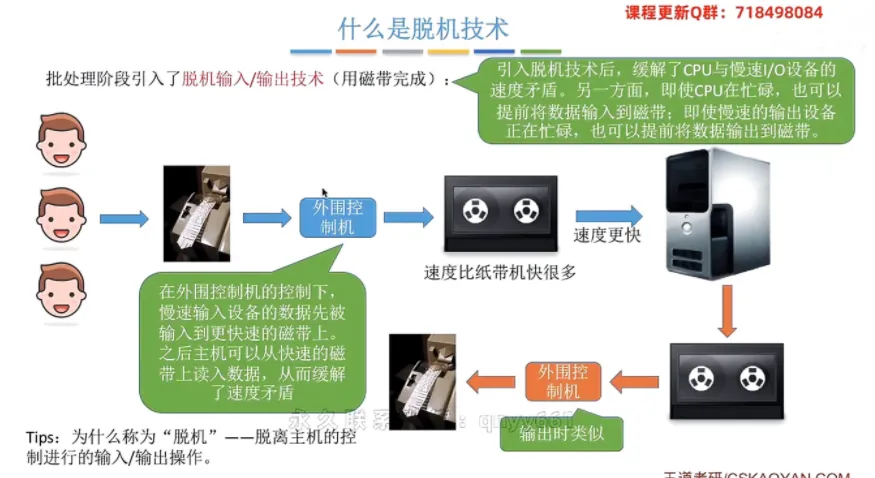
① 传统手工操作阶段的痛点
在早期计算机中,主机直接从外部
I/O设备获取或输出数据。核心矛盾:由于机械设备的速度极慢,而
CPU处理速度极快,导致了严重的人机速度矛盾。高速的CPU必须浪费大量宝贵的时间,处于“空等”状态来配合慢速设备。
② 批处理阶段的脱机输入/输出技术
为了解决上述矛盾,引入了以磁带为核心介质的脱机技术。
运行机制:在外围控制机(独立的辅助计算设备)的控制下,慢速输入设备产生的数据会被提前汇集并写入到速度更快的磁带上。当主机真正需要数据时,直接从高速磁带上读取即可;输出过程同理。
💡 生活化降维理解:
脱机技术就像是现在的快递驿站。以前快递员(慢速
I/O设备)送件,必须等你(CPU)在家才能交接,如果不在家大家就互相死等,效率极低。现在有了驿站(磁带),快递员只需把包裹统统扔进驿站就走,你下班后去驿站一次性高速取回所有包裹。整个过程脱离了主机的直接控制,所以被称为“脱机”。
假脱机技术——输入井和输出井
① 概念解析
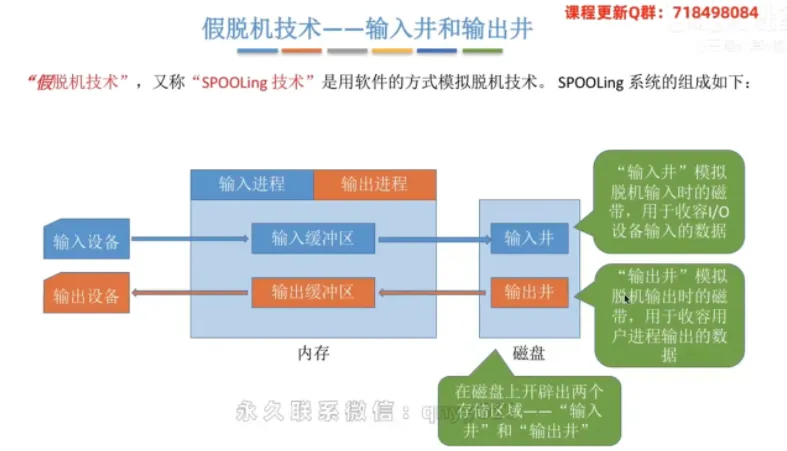
“假脱机技术”又被称为
SPOOLing技术。它并不是真的外挂了一台独立的控制机,而是利用纯软件的方式,在操作系统内部模拟出脱机技术的效果。
② SPOOLing 系统的微观核心组件
输入井和输出井(位于磁盘):在高速大容量的磁盘上专门开辟出的两个巨大存储区域。
输入井:模拟脱机输入时的磁带,用于长期收容外部
I/O设备传入的数据。输出井:模拟脱机输出时的磁带,用于暂存各个用户进程请求输出的数据。
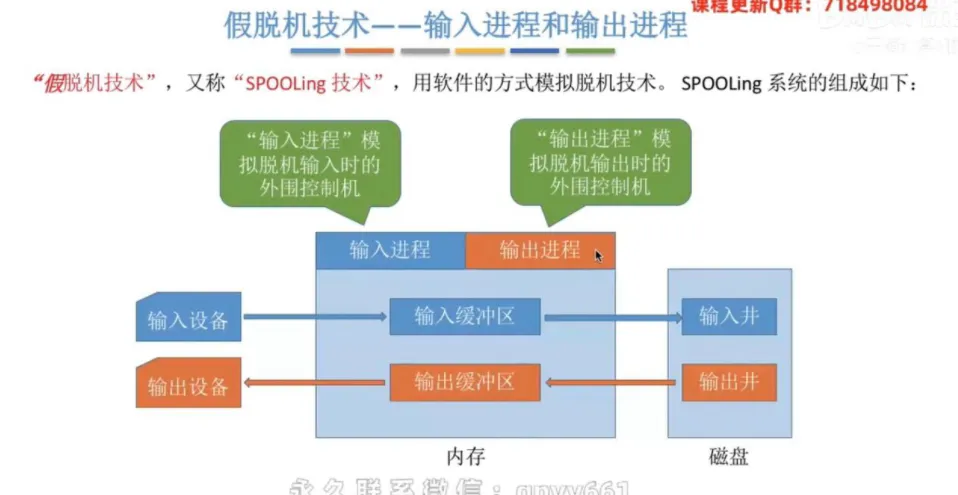
输入进程和输出进程(位于内存):在内存中运行的专门负责调度的系统进程。输入进程模拟脱机输入时的外围控制机;输出进程模拟脱机输出时的外围控制机。
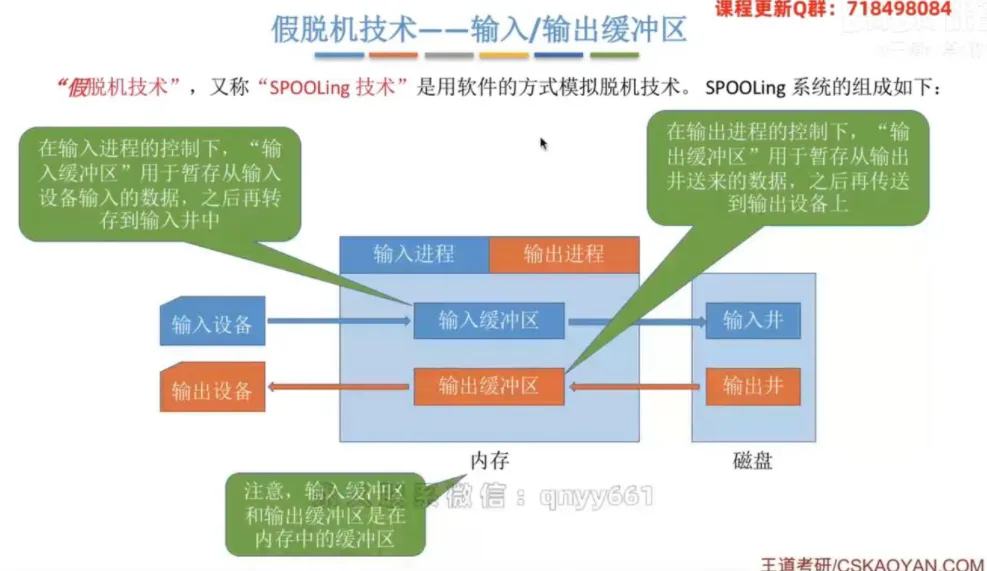
输入缓冲区和输出缓冲区(位于内存):在内存中开辟的临时数据周转站。用于在慢速设备与磁盘(井)之间传输数据时进行暂存缓冲。
共享打印机原理分析
① 设备属性的分类

独占式设备:一段时间内只允许各个进程串行使用的设备(传统的物理打印机就是典型的独占设备)。若进程1正在打印,进程2的打印请求必然会被阻塞。
共享设备:允许多个进程**“同时”使用**的设备(宏观上看起来是同时,微观上是高速交替使用),能极大提升系统并发度。
② 假脱机打印的具体工作流程
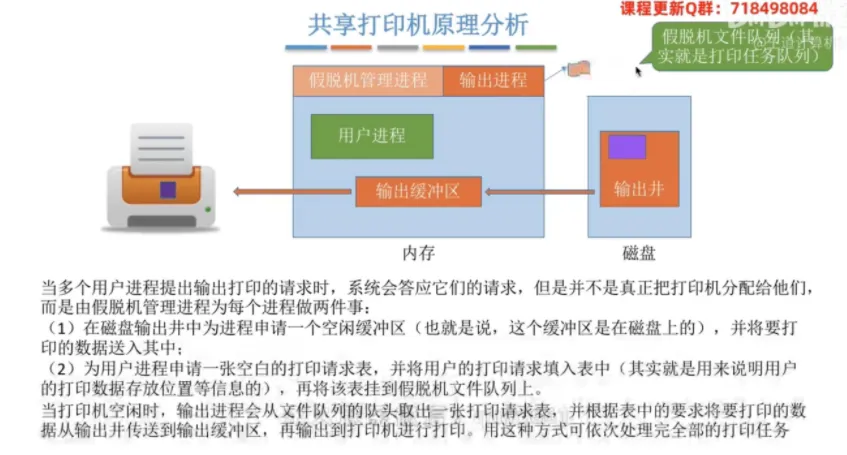
当系统中多个用户进程同时提出打印请求时,系统并不会直接把物理打印机分配给某个进程,而是由内部的假脱机管理进程按以下步骤进行代办操作:
首先,在磁盘的输出井中为当前申请打印的进程分配一个空闲缓冲区,并将该进程需要打印的所有数据拦截并送入该井中暂存。
然后,为该用户进程申请一张空白的打印请求表,并将用户数据的存放位置、打印格式等元信息详细填入表中。
接着,将这张填写完整的请求表,按照排队规则挂载到后台的假脱机文件队列(即打印任务队列)上。此时,该用户进程的打印请求在逻辑上已经宣告“完成”,进程可以无阻塞地继续执行后续代码。
最后,当底层的物理打印机处于空闲状态时,驻留的输出进程会自主从任务队列的队头取出一张请求表,根据表中的位置要求,将数据从磁盘输出井搬运到内存输出缓冲区,最终传送给物理打印机进行实际的喷墨打印。
🛠️ 考点补充与避坑指南
🔥 ⭐⭐⭐ 假脱机技术的核心价值:可将独占设备改造为共享设备 ⭐⭐⭐
这是历年考研的绝对高频结论!在使用
SPOOLing技术的系统中,虽然底层物理上仍然只有一台独占的打印机,但在众多用户进程的宏观感知中,它们只要把数据丢进磁盘的“输出井”就能立刻获得成功反馈,根本不需要排队阻塞。因此,SPOOLing技术在逻辑上把物理设备虚拟化了,成功地将独占设备转化为了共享设备。
三、设备的分配与回收
设备分配时应考虑的因素
① 设备的固有属性
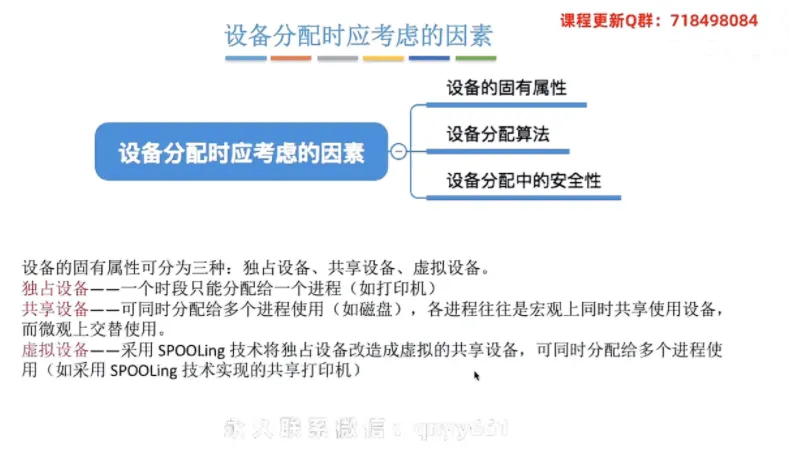
独占设备:一个时段只能分配给一个进程(如打印机)。
共享设备:可同时分配给多个进程使用(如磁盘),各进程在宏观上是同时共享使用设备,微观上则是交替使用。
虚拟设备:采用
SPOOLing技术将独占设备改造成虚拟的共享设备,从而可同时分配给多个进程使用(如共享打印机)。
② 设备分配算法
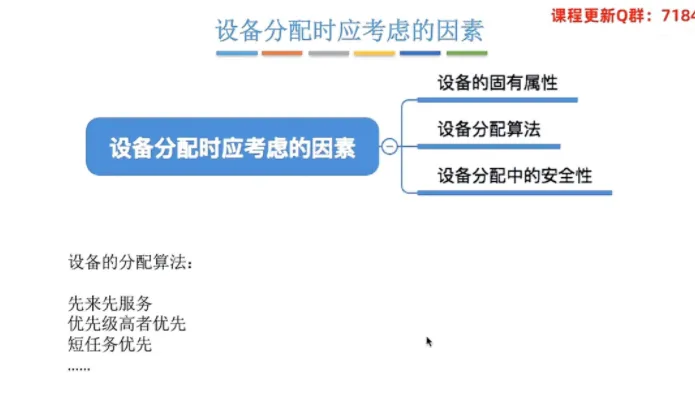
先来先服务:根据进程发出请求的先后顺序进行分配。
优先级高者优先:优先分配给优先级更高的进程。
短任务优先:优先分配给预计 I/O 执行时间短的进程。
③ 设备分配中的安全性

安全分配方式:为进程分配一个设备后就将进程阻塞,本次
I/O完成后才将进程唤醒。优点:一个时段内每个进程只能使用一个设备,破坏了“请求和保持”条件,不会发生死锁。
缺点:对于单个进程来说,
CPU和I/O设备只能串行工作,效率较低。不安全分配方式:进程发出
I/O请求后,系统为其分配设备,进程可继续执行,并可发出新的请求。仅当某个请求得不到满足时才阻塞进程。优点:进程的计算任务和
I/O任务可以并行处理,使进程迅速推进。缺点:一个进程可以同时使用多个设备,有可能发生死锁(系统需要额外引入死锁避免、检测和解除机制)。
静态分配和动态分配

① 资源分配方式对比
静态分配:进程运行前为其分配全部所需资源,运行结束后归还资源。此方式破坏了“请求和保持”条件,不会发生死锁。
动态分配:进程在运行过程中,根据实际需要动态地申请设备资源。
设备分配管理中的数据结构
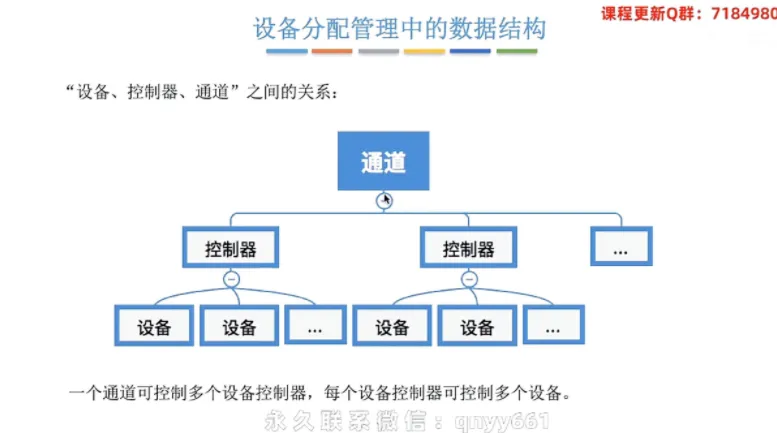
① 管理控制表层级与包含要素
设备控制表(
DCT):系统为每个设备配置一张,用于记录物理设备情况。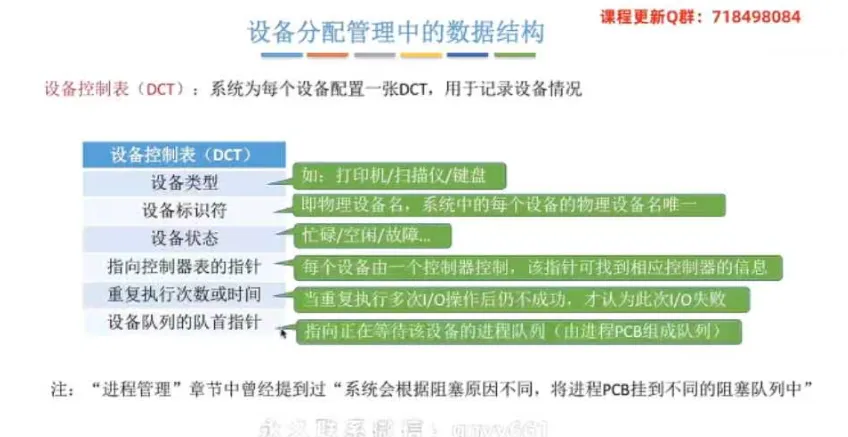
核心要素:设备类型、设备标识符(物理设备名)、设备状态、指向控制器表的指针、设备队列的队首指针(指向等待该设备的
PCB队列)。控制器控制表(
COCT):
每个设备控制器对应一张,供操作系统操作和管理控制器。
核心要素:控制器标识符、控制器状态、指向通道表的指针、控制器队列的队首/队尾指针。
通道控制表(
CHCT):每个通道对应一张,供操作系统操作和管理通道。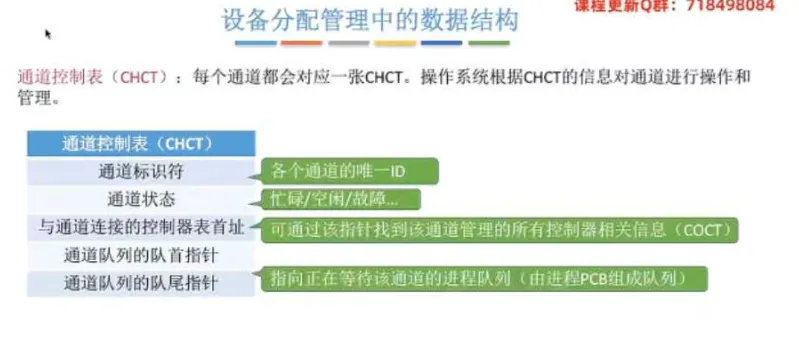
核心要素:通道标识符、通道状态、与通道连接的控制器表首址、通道队列的队首/队尾指针。
系统设备表(
SDT):记录系统中全部设备的情况,每个设备对应一个表目。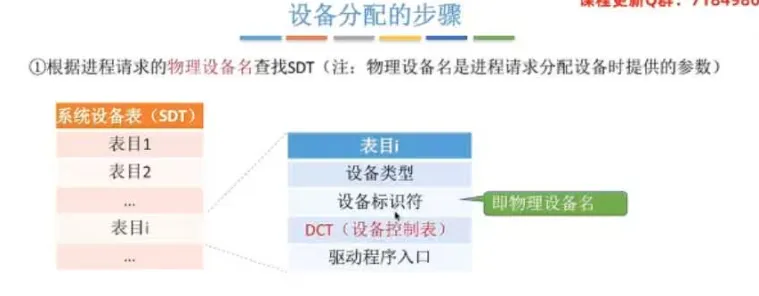
核心要素:设备类型、设备标识符、指向对应
DCT的指针、驱动程序入口。
🛠️ 避坑指南:注意理清“设备 → 控制器 → 通道”的树状控制关系。虽然通常一个设备由一个特定的控制器控制,但一个通道可以控制多个设备控制器,每个设备控制器也可以控制多个物理设备。千万不要在做选择题时把它们的对应关系记成绝对的一对一。
设备分配的步骤
① 整体大流程
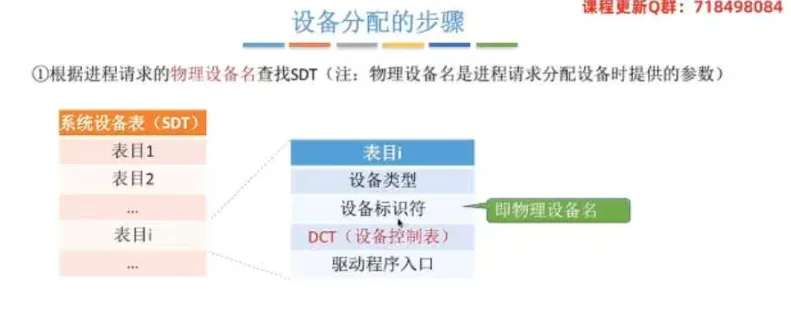
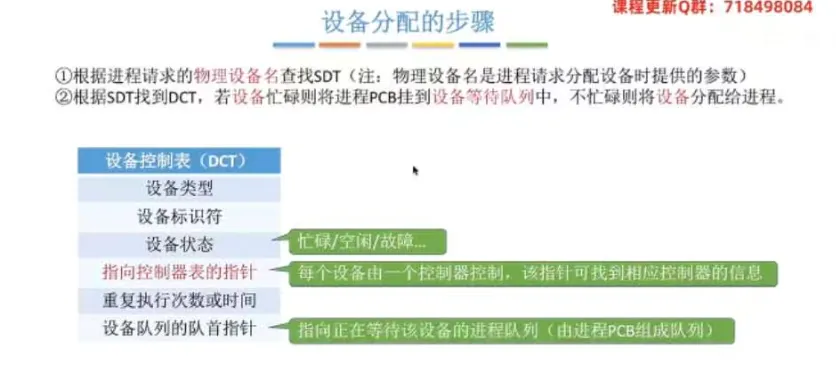


首先,根据进程请求的物理设备名查找系统设备表
SDT。然后,根据
SDT找到对应的设备控制表DCT。若设备忙碌,则将进程PCB挂到设备等待队列中;若不忙碌,则将设备分配给该进程。接着,根据
DCT找到对应的控制器控制表COCT。若控制器忙碌,则将进程PCB挂到控制器等待队列中;若不忙碌,则将控制器分配给该进程。最后,根据
COCT找到对应的通道控制表CHCT。若通道忙碌,则将进程PCB挂到通道等待队列中;若不忙碌,则将通道分配给该进程。
(注:只有设备、控制器、通道三者都分配成功时,这次设备分配才算彻底成功,之后便可启动 I/O 设备进行数据传送。)
② 微观流程与生活化理解
我们可以把上述层层分配的过程,想象成餐厅点餐与后厨做菜的协作系统:
查找 SDT(确认菜单):首先,顾客(进程)点了一道“红烧肉”(物理设备名),前台接待员(
SDT)确认菜单上有这道菜,并找到负责这道菜的厨师信息。分配 DCT(指派厨师):然后,找到负责红烧肉的王大厨(
DCT)。如果王大厨正在炒别的菜(设备忙碌),顾客的订单只能排在王大厨的等待单上;如果他刚好空闲,就把任务交给他(设备分配)。分配 COCT(抢占灶台):接着,王大厨需要使用灶台(
COCT)。如果厨房里所有的灶台都在被占用(控制器忙碌),王大厨只能端着锅干等;如果有空闲灶台,他就可以占用其中一个(控制器分配)。分配 CHCT(接通燃气):最后,灶台点火需要天然气(
CHCT)。如果当前天然气管道压力不足或被其他高优先级区域占用(通道忙碌),还是得等;气压正常且可用(不忙碌),才能真正打火炒菜(通道分配)。
💡 考点补充:在现代操作系统的实际考题中,进程往往不直接使用物理设备名,而是使用逻辑设备名进行请求。此时,系统首先需要建立一张逻辑设备表(
LUT),将逻辑设备名映射为物理设备名,然后再去查找SDT。这是为了实现设备独立性,允许用户程序不受具体物理设备变更的影响。
设备分配步骤的改进
① 引入逻辑设备表(LUT)
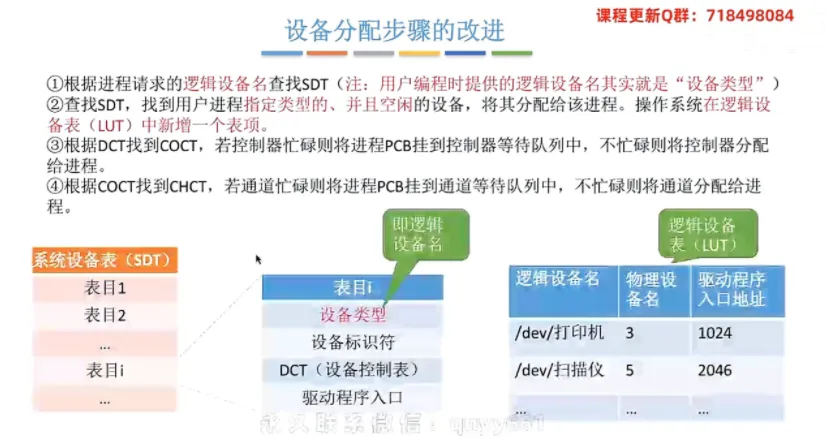

核心概念:为了解决直接使用物理设备名带来的不便,系统引入了
LUT(逻辑设备表),用于建立逻辑设备名与物理设备名之间的映射关系。表项结构:通常包含逻辑设备名、物理设备名、驱动程序入口地址。
LUT 的设置方式:
单用户操作系统:整个系统只有一张
LUT,因此各用户所用的逻辑设备名不允许重复。多用户操作系统:每个用户拥有一张属于自己的
LUT,因此不同用户的逻辑设备名可以重复。
② 改进后的整体大流程(进程第一次使用设备)
首先,根据进程请求的逻辑设备名查找系统设备表
SDT。(注:用户编程时提供的逻辑设备名,其实质就是指明了“设备类型”,如 /dev/printer)。然后,操作系统在
SDT中查找用户进程指定类型的、并且空闲的物理设备,将其分配给该进程。并且,操作系统会在逻辑设备表LUT中新增一个对应的表项。接着,根据分配到的物理设备的
DCT找到对应的COCT。若控制器忙碌则将进程PCB挂到控制器等待队列中,不忙碌则将控制器分配给进程。最后,根据
COCT找到对应的CHCT。若通道忙碌则将进程PCB挂到通道等待队列中,不忙碌则将通道分配给进程。
③ 改进后的内部微观流程(进程后续再次使用设备)
如果之后用户进程再次通过相同的逻辑设备名请求使用该设备,操作系统无需再次遍历查找
SDT。系统会直接查询
LUT表,即可迅速知道用户进程实际要使用的是哪个物理设备,并且能直接获取该设备的驱动程序入口地址。
④ 生活化降维理解
我们可以把“逻辑设备与物理设备”的分配机制,想象成公司老板招募员工的场景:
第一次要人(查总表并建通讯录):首先,老板(用户进程)提出需求:“我需要一个打字员(逻辑设备名/设备类型)”。HR(操作系统)去翻看全公司的员工总花名册
SDT。然后,HR 找到刚好闲着的员工“张三”(物理设备名),把张三分配给老板。为了方便,HR 在老板的私人专属通讯录LUT上新增一行记录:“打字员 → 张三,工位号1024(驱动程序入口)”。接着和最后,就是去申请办公桌(控制器)和电脑网络(通道)等配套资源。后续要人(直接看通讯录):以后老板再喊“让打字员过来”,HR 就不需要再去翻全公司的总花名册
SDT了,直接看老板的通讯录LUT,马上就能精准叫来“张三”。
💡 考点补充:引入逻辑设备名和
LUT的根本目的是为了实现设备的独立性(设备无关性) ⭐⭐⭐。这使得用户程序独立于具体的物理设备,即便某台打印机坏了,系统只要能找到另一台同类型的空闲打印机分给它,程序依然能正常运行,极大提升了系统的灵活性和程序的可移植性。
四、缓冲区管理
什么是缓冲区?有何作用?

① 缓冲区的基本概念
硬件缓冲区:由专门的硬件寄存器组成。成本较高、容量较小,仅用于对速度要求极高的场合(如联想寄存器存放页表项副本)。
内存缓冲区:利用内存作为缓冲区。这是操作系统“设备独立性软件”主要负责组织管理的对象(本节探讨的核心)。
② 缓冲区的核心作用
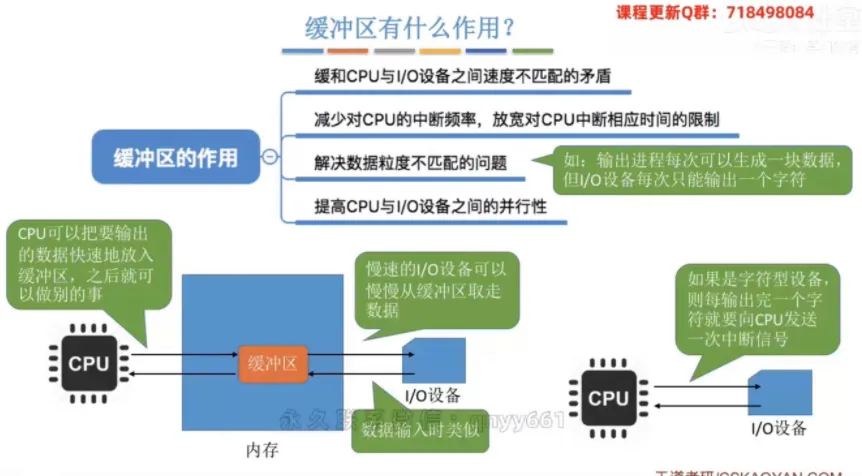
缓和矛盾:缓和
CPU与I/O设备之间速度不匹配的矛盾。减少中断:减少对
CPU的中断频率,放宽对CPU中断响应时间的限制(如:字符型设备每输出一个字符就要发中断,有了缓冲区可以等充满后再发中断)。解决粒度问题:解决数据粒度不匹配的问题(如:输出进程每次生成一块数据,但
I/O设备每次只能输出一个字符)。提升并行性:提高
CPU与I/O设备之间的并行处理能力。
单缓冲
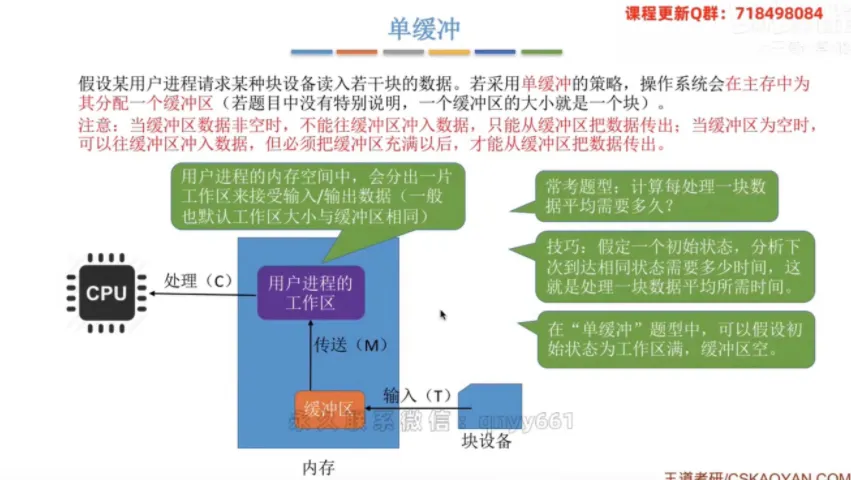
① 整体分配策略与工作规则
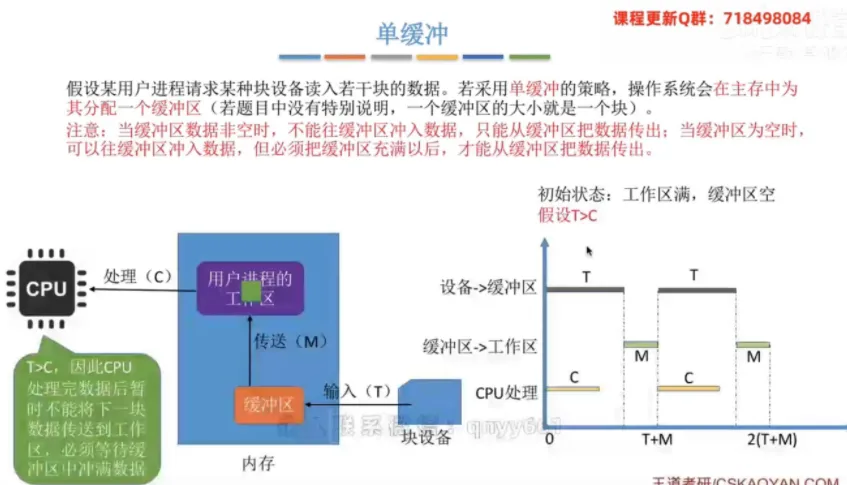
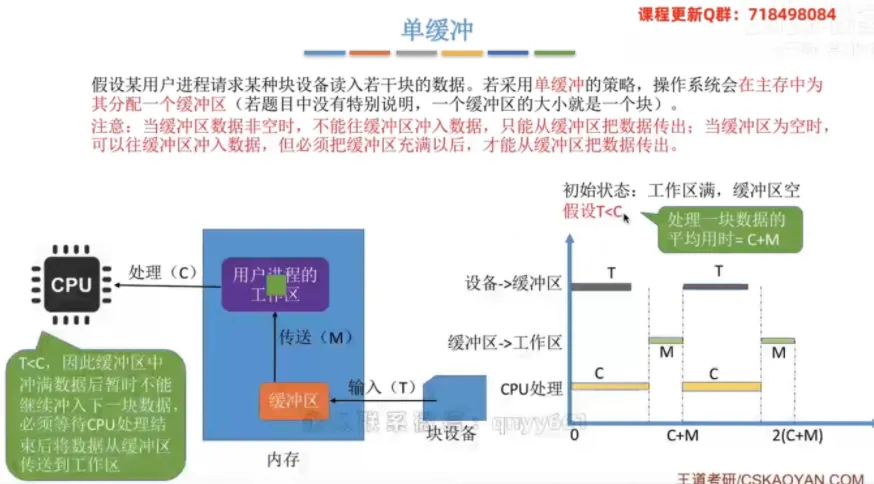
分配策略:操作系统会在主存中为进程分配一个缓冲区(若无特别说明,一个缓冲区的大小就是一个数据块)。
核心规则:当缓冲区非空时,不能往里冲入数据,只能传出;当缓冲区为空时,可以往里冲入数据,但必须充满以后才能把数据传出。
② ⭐⭐⭐常考题型与解题技巧⭐⭐⭐
常考题型:计算每处理一块数据平均需要多久?
核心技巧:假定一个初始状态,分析下次到达相同状态需要多少时间,这个时间就是处理一块数据的平均用时。
初始假设:在“单缓冲”题型中,通常假设初始状态为工作区满,缓冲区空。
③ 耗时计算分析
变量定义:
T为设备输入到缓冲区的耗时,M为缓冲区传送到工作区的耗时,C为CPU处理数据的耗时。当 T > C 时:
CPU处理完数据后,必须等待缓冲区再次充满。此时处理一块数据的平均用时为 T + M。当 T < C 时:缓冲区充满后,必须等待
CPU处理结束才能继续冲入下一块。此时处理一块数据的平均用时为 C + M。
💡 考点补充:综合上述两种情况,单缓冲环境下处理一块数据的平均耗时公式可以精炼为:MAX(C, T) + M。
双缓冲
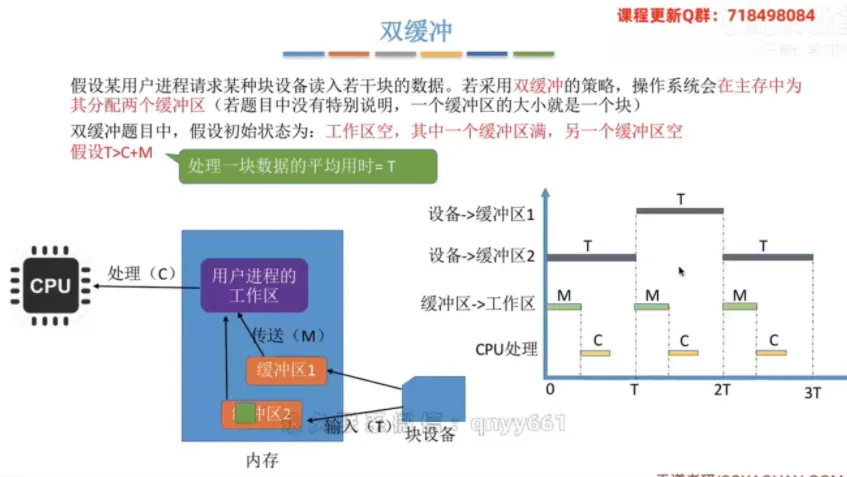
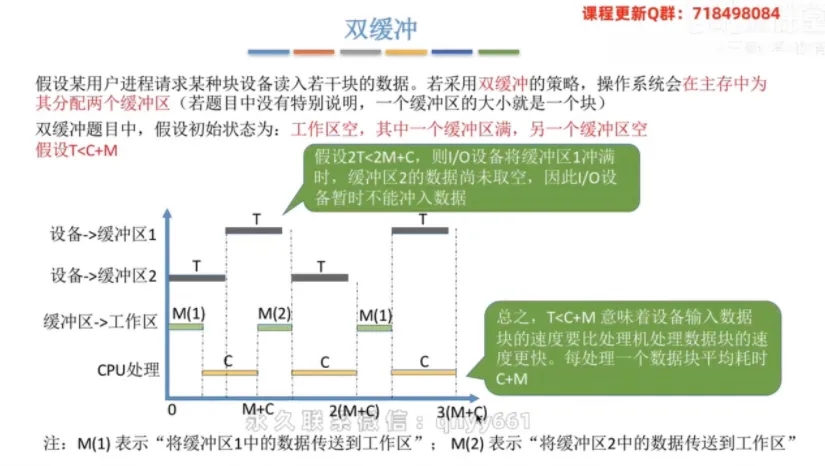
① 整体分配策略
分配策略:操作系统在主存中为进程分配两个缓冲区。
② 耗时计算分析
初始假设:双缓冲题型中,通常假设初始状态为工作区空,其中一个缓冲区满,另一个缓冲区空。
当 T > C + M 时:设备输入速度慢,
CPU总是要等设备。平均用时为 T。当 T < C + M 时:设备输入速度快,设备总是要等
CPU处理完。平均用时为 C + M。
💡 考点补充:双缓冲环境下处理一块数据的平均耗时公式可以精炼为:MAX(T, C + M)。
③ 微观流程与生活化理解
我们可以把数据传输想象成工地搬砖的场景:
单缓冲(只有一辆小推车):砖厂装满车(
T),工人把车推到工地卸砖(M),然后砌墙(C)。在工人推车和砌墙期间,砖厂只能干等,因为车不在。双缓冲(有两辆小推车):砖厂给一号车装砖(
T)的同时,工人推着二号车去卸砖和砌墙(M和C)。两者完全并行,极大消除了相互等待的“摸鱼”时间。
使用单/双缓冲在通信时的区别
① 单缓冲通信(半双工)
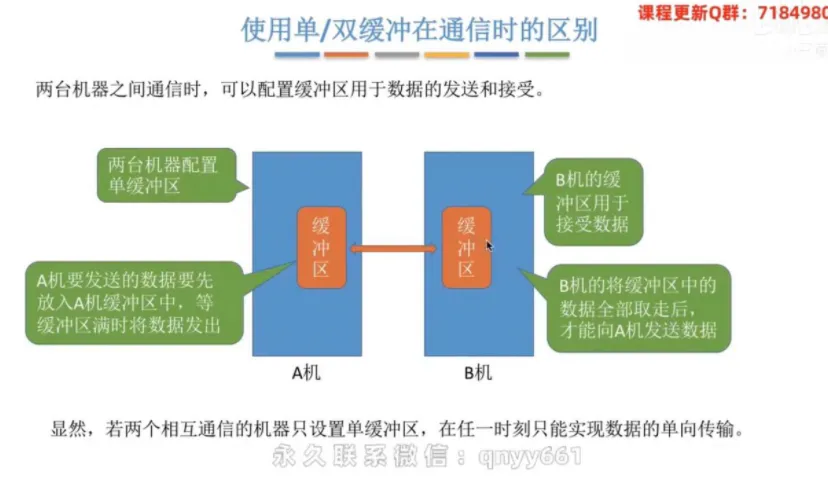
若两台相互通信的机器只配置单缓冲,在任一时刻只能实现数据的单向传输(例如:A机发送数据装满缓冲区后发给B机,此时A机不能接收数据)。
② 双缓冲通信(全双工)
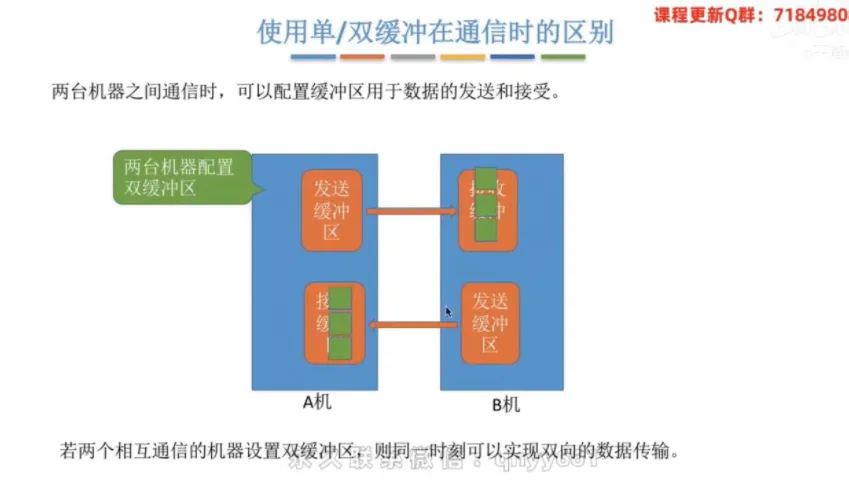
若两台相互通信的机器配置双缓冲(一个用于发送,一个用于接收),则同一时刻可以实现双向的数据传输。
循环缓冲区
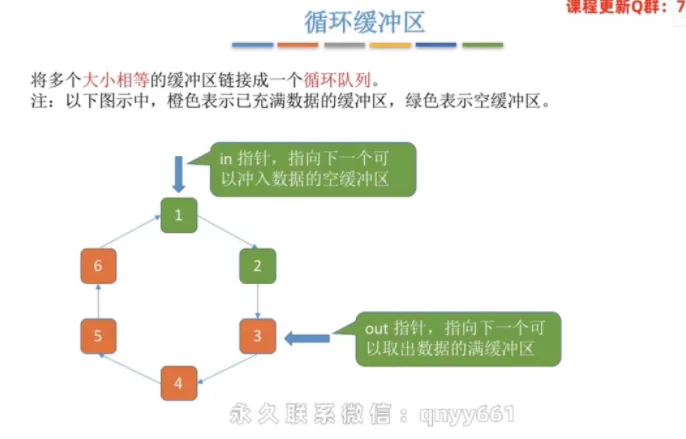
① 核心结构与指针机制
核心结构:将多个大小相等的缓冲区链接成一个循环队列。
in 指针:指向下一个可以冲入数据的空缓冲区。
out 指针:指向下一个可以取出数据的满缓冲区。
缓冲池
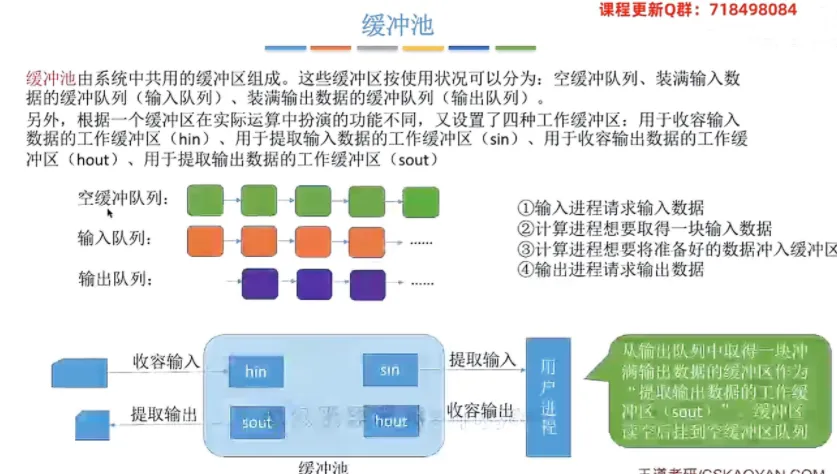
① 缓冲池的组成要素
三大队列:空缓冲队列(绿色)、装满输入数据的输入队列(橙色)、装满输出数据的输出队列(紫色)。
四种工作缓冲区:
hin:用于收容输入数据。sin:用于提取输入数据。hout:用于收容输出数据。sout:用于提取输出数据。
② 整体大流程(以输入进程获取数据为例)
首先,输入进程请求输入数据时,从空缓冲队列队首取下一个空缓冲区,将其作为“收容输入的工作缓冲区
hin”。然后,将外部设备的数据冲入
hin中,装满后,将其挂到输入队列的队尾。接着,当计算进程想要取得数据时,从输入队列的队首取下一个满缓冲区,将其作为“提取输入的工作缓冲区
sin”。最后,用户进程将
sin中的数据全部读空后,将这个重新变空的缓冲区挂回到空缓冲队列的队尾,循环利用。
🛠️ 避坑指南:不要把“循环缓冲区”和“缓冲池”搞混。循环缓冲区通常是专属于某一个特定的高频 I/O 进程的;而缓冲池是系统中共用的缓冲区资源,由操作系统统一管理,按需分配给各种不同的进程使用。
