 夜雨聆风
夜雨聆风我们擅长预测那些“普通”的涨水过程,但对于那些不常发生、却能造成巨大灾难的极端事件,我们的模型总是显得有些“笨拙” 。最近,我读到了一篇名为 《ReFine: Boosting Time Series Prediction of Extreme Events by Reweighting and Fine-tuning》 (ReFine:通过重新加权和微调提升极端事件的时间序列预测)的论文,其核心思想: 如何让我们的预测模型,在关键时刻,能看得更准、报得更快?
第一章:我们预测模型的“阿喀琉斯之踵”——为何总在极端事件上“失手”?
在聊新方法之前,我们得先搞清楚,为什么我们现有的很多模型,包括一些听起来很高大上的深度学习模型,在预测极端洪水、极端干旱时会“失手”?
原因其实很简单,也很无奈: 数据不平衡 。
想象一下,我们训练一个 AI 模型,就像教一个学生学习。我们给它一本厚厚的“历史教科书”,也就是过去几十年的水文数据。在这本书里,99% 的内容都是关于正常年份的平稳水情,只有不到 1% 的篇幅,零星地记载了几次特大洪水。
这个学生(AI模型)学完后,你考它普通的水情,它对答如流,因为见得多了。但你突然问它:“如果发生一次‘百年一遇’的特大暴雨,下游水位会涨到多少?” 它很可能就懵了。因为它在学习过程中,见过的“极端案例”太少了,根本没形成深刻的印象。模型会不自觉地认为那些“极端案例”是噪声或者不重要的信息,从而在学习中把它们忽略掉。
在学术上,这被称为 “长尾分布” (Long-tailed Distributions)问题。
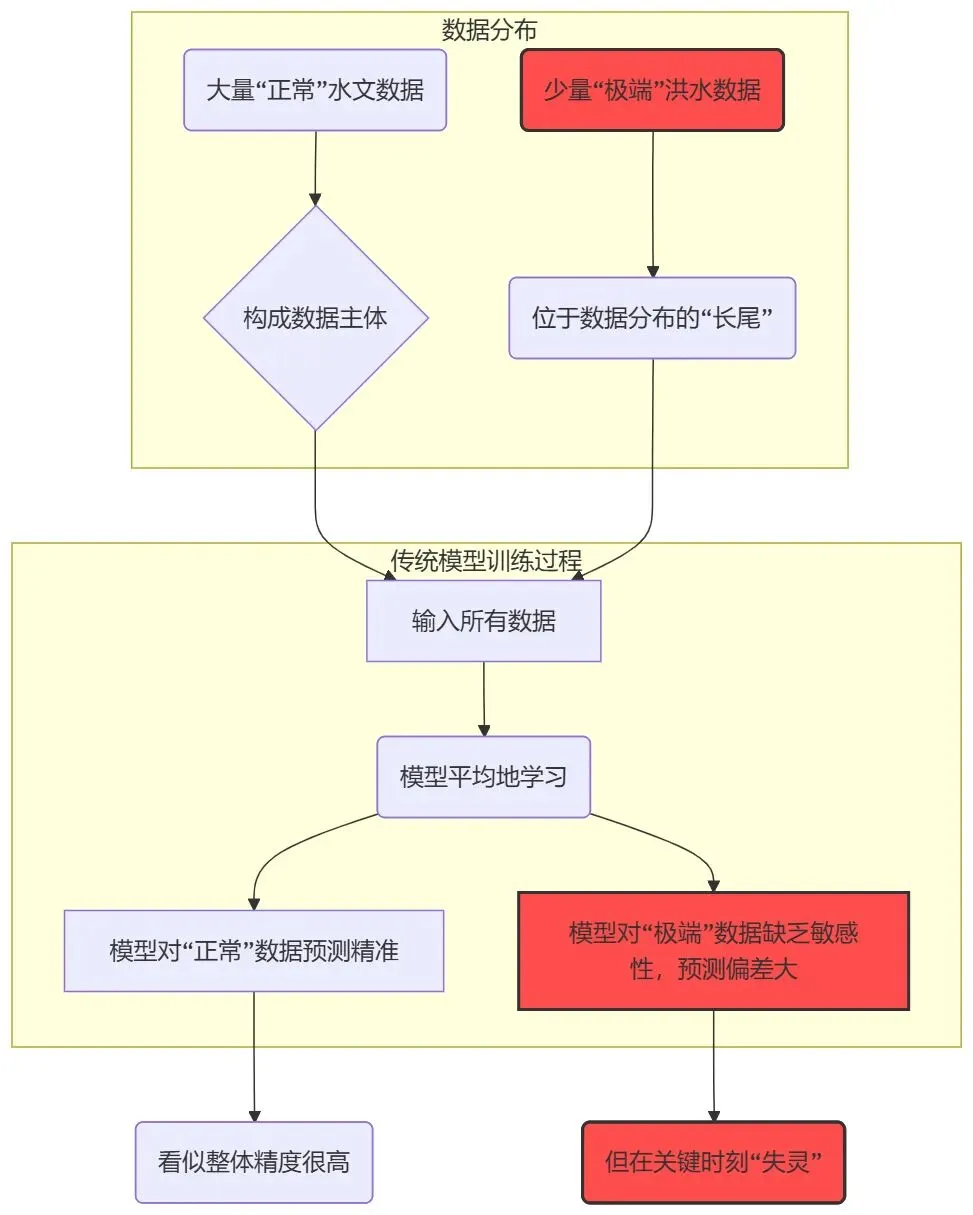
图1:传统模型在长尾数据分布下的困境示意图
这篇论文还提到了一个更专业的词: OOD (分布外问题,Out-of-Distribution) 。简单来说,就是模型在训练时看到的数据(大部分是正常情况),和它在测试时需要面对的数据(我们最关心的极端情况),它们的分布特征完全不同。这就好比一个一直在泳池里训练的游泳运动员,你突然让他去应对大海里的狂风巨浪,他肯定会水土不服。
这个问题,是我们水文预报,乃至整个气象、金融等领域都面临的共同挑战。
第二章:ReFine 的“组合拳”——如何让模型“看见”并“记住”极端事件?
这篇论文的作者们,针对上述困境,提出了一套非常巧妙的“组合拳”。他们没有去发明一个全新的、结构复杂的模型,而是在现有的模型基础上,通过两种策略的优化,让模型变得更“聪明”。这两种策略就是 “重新加权”(Reweighting) 和 “微调”(Fine-tuning) 。
第一招:重新加权(Reweighting)——给“尖子生”开小灶
“重新加权”这个思路其实并不新鲜,核心思想就是: 在模型训练时,不能一视同仁,要给那些稀有的、重要的“极端”样本更大的“话语权” 。
这就像一个班主任带班。如果完全按照平均主义来教学,那最后的结果可能是大家都平平无奇。一个优秀的班主任,会特别关注那些有潜力但可能偏科的“尖子生”(极端样本),也会确保不让大多数“普通学生”(正常样本)掉队。
怎么实现呢?就是在计算模型预测误差的时候,给每个样本的误差前面乘上一个“权重系数”。
对于大量的 正常 样本,它们的预测误差,权重系数很小,比如 0.1。 对于稀有的 极端 样本,它们的预测误差,权重系数很大,比如 10。
这样一来,模型为了让总的误差最小化,就不得不拼尽全力去降低那些极端样本的预测误差,因为它犯错的“代价”太高了。
论文里对比了三种设置权重的方法:
反比例函数法(IPF):这是一种简单粗暴但有效的方法。把所有数据分个组,哪个组的样本数量少,这个组的权重就高。就像物以稀为贵。 极值理论法(EVT):这是一种更高级的统计学方法。它专门研究数据分布的“尾巴”,通过数学模型(如广义帕累托分布)来计算出一个事件发生的概率。事件越极端,概率越小,那它的权重就应该越高。 元学习法(Meta-learning):这是 ReFine 方法的精髓所在,也是它最高明的地方。前面两种方法,权重怎么设,多多少少都带点“拍脑袋”的成分,需要人的经验。而“元学习”则让模型 “自己学着去设置权重” 。
它的做法是,除了常规的训练数据外,再准备一小份“私藏”的、高质量的、 全部由极端事件组成的“模拟考卷” (论文里称为“评估集”)。
训练过程就像这样:

图2:元学习(Meta-learning)调整权重的过程示意图
不得不说,这个“元学习”的思路非常精妙。它不再依赖于我们对数据分布的先验知识,而是通过一个动态的、以最终目标(在极端事件上表现好)为导向的反馈循环,来自动寻找最优的“教学方案”。这让权重分配变得更加智能和自适应。
第二招:微调(Fine-tuning)——从“通才”到“专才”的最后冲刺
如果说“重新加权”是在培养一个“德智体美劳”全面发展,但尤其擅长处理难题的“通才”学生,那么“微调”就是让这个已经很优秀的学生,再去做针对性的“奥赛集训”,让他成为解决特定难题的“专才”。
具体操作是:
第一阶段:使用前面提到的“重新加权”方法,在 全部 数据(包含正常和极端)上训练一个基础模型。这个模型已经具备了对水文过程的全面理解,并且对极端事件有了一定的敏感性。 第二阶段: “冻结” 基础模型的前几层网络。这几层网络学到的是一些比较基础和通用的水文特征,比如季节性变化、径流的基本形态等,这些是“通识教育”,不能丢。 第三阶段:只用那些稀有的 极端 样本数据,来重新训练模型的后几层网络。后几层网络学到的是更高级、更抽象的特征。这个过程,就是让模型把全部精力都集中在理解和模拟极端事件的特殊规律上。
这就像我们培养一个水利工程师。他先要学好数学、物理、水力学这些基础课(冻结的底层网络),然后才能去专门学习大坝设计、水库调度这些专业课(可训练的高层网络)。
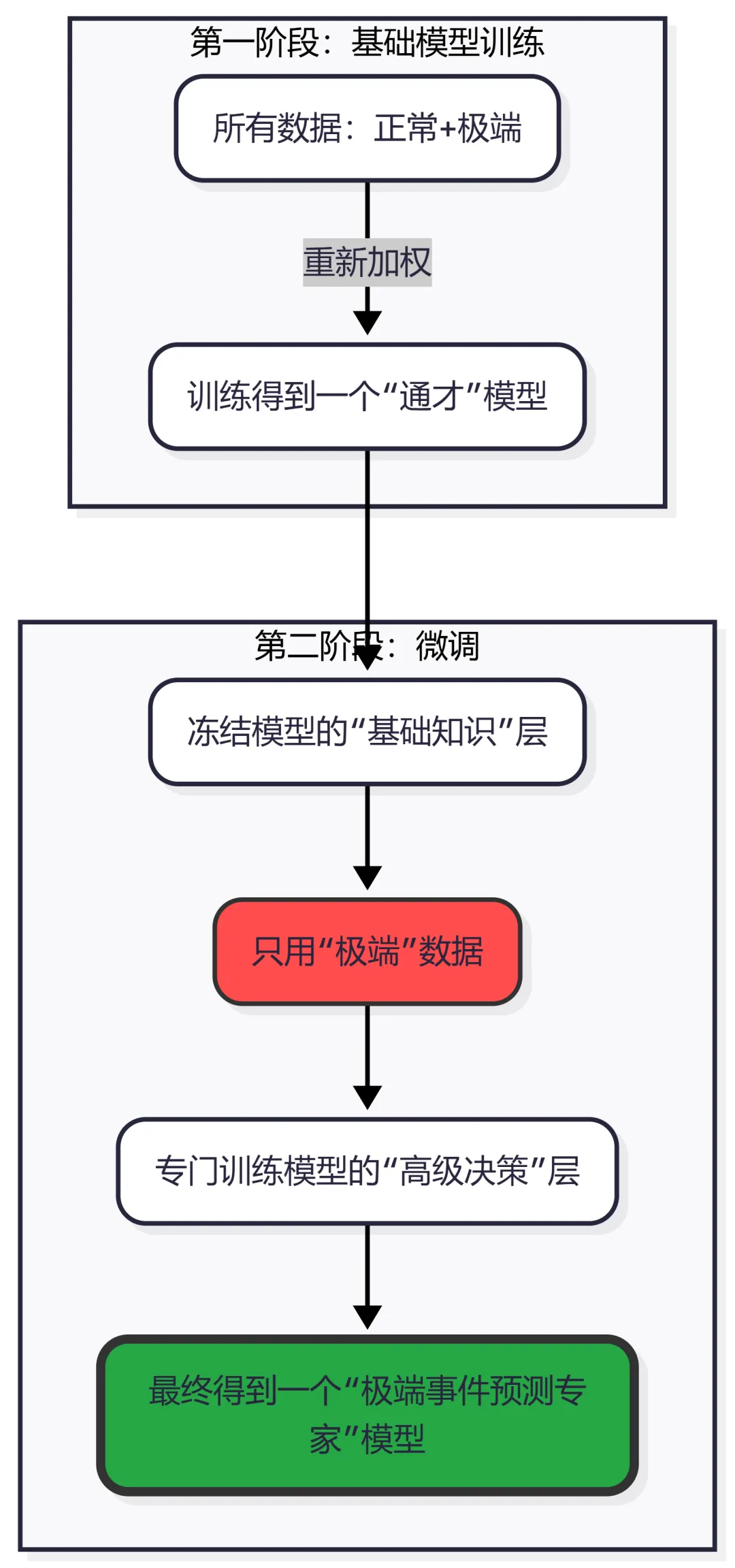
图3:ReFine 方法的“两步走”战略
通过 “重新加权”+“微调” 这套组合拳,ReFine 方法成功地让模型在不牺牲对正常事件预测能力的前提下,极大地提升了对极端事件的预测精度。论文中的大量实验数据也证明了这一点。
第三章:从论文到实践——ReFine 在我们水文工作中的应用场景
理论说完了,我们得回到现实。这个听起来很厉害的 ReFine 方法,对我们这些每天跟江河湖库打交道的水利人来说,到底能用在哪些地方?结合我的工作经验,我能想到以下几个非常契合的应用场景。
场景一:中小河流山洪预警——与“快”字赛跑
中小河流的洪水,尤其是山区性河流,特点就是“暴涨暴落”,预见期非常短。传统的模型往往因为山区水文站网稀疏,对短时强降雨的响应模拟不准,导致预警时间窗口很窄,甚至出现“马后炮”的情况。
痛点:山洪的致灾降雨往往是超常规的局部极端暴雨,这正是“长尾”数据的典型。 ReFine 的价值: 某南方省份水文局 在一次复盘中发现,他们现有的模型对于超过100毫米/小时的降雨强度,其产流计算的误差会指数级增大。这正是因为历史上这样的数据太少了。如果采用 ReFine 的 重新加权 策略,可以让模型在训练时就“重点关照”这些罕见的强降雨事件及其产流过程,从而学习到更准确的非线性关系。 某西南山区水文监测中心 正尝试建立基于雷达估测降雨的洪水预报模型。他们可以将历史上为数不多的几次导致了严重山洪的雷达回波图和对应的洪水过程,作为 微调 阶段的“金牌教材”,专门训练模型识别这种最危险的降雨模式。
实操注意事项:山洪预报的关键在于数据。要用好 ReFine,必须建立一个高质量的极端事件数据库,不仅要有水文数据,还应该包括气象、下垫面(土地利用、土壤湿度等)的综合数据。这个“模拟考卷”的质量,直接决定了最终模型的上限。
场景二:水库群联合调度——在“两难”中找最优解
大型江河的流域性大洪水,往往需要上游的水库群进行联合调度。调度决策(何时拦、拦多少、何时放)的依据,就是对未来洪峰流量和总量的精准预测。预测偏高,可能导致不必要的弃水,影响后期供水和发电;预测偏高,则可能导致水库被迫超汛限水位运行,甚至威胁大坝安全。
痛点:决定水库调度的,恰恰是那个几十年一遇的洪峰。对洪峰量级的丝毫偏差,都可能导致调度方案的天壤之别。 ReFine 的价值: 某大型流域管理机构 在进行调度规程修订时,一直苦于如何评估那些超标准(如“千年一遇”)洪水下的水库响应。利用 ReFine,他们可以训练一个对极端入库流量特别敏感的模型。这个模型不仅能报出洪峰,甚至可能对洪峰的形态(胖瘦高矮)有更精准的刻画,为调度方案的精细化提供依据。 记得有一次,某梯级水库群在面临一场罕见洪水时,上游水库的预报偏小,导致下游水库提前泄流不足,场面一度非常被动。如果当时有一个经过 微调 的、专门针对这种“列车效应”洪水的模型,或许就能更早地预警风险。
实操注意事项:水库调度模型不仅要准,还要有很好的可解释性。ReFine 作为一个深度学习优化方法,本身是个“黑箱”。因此,在应用时,不能完全依赖它,必须将其预测结果与传统的水文物理模型进行相互验证,并结合调度专家的经验,形成“人机结合”的决策闭环。
场景三:城市内涝预报——给“海绵城市”装上“智慧大脑”
随着城市化进程的加快,“逢雨看海”成了很多城市的顽疾。城市内涝的预报,比河流洪水更复杂,它涉及到降雨、管网、泵站、河道水位顶托等多个因素,而且响应极快。
痛痛点:导致城市严重内涝的,往往是短时、局地、强度极大的“天漏式”暴雨。这种极端降雨事件在历史数据中同样是少数。 ReFine 的价值: 某沿海发达城市水务局 正在建设城市排水“数字孪生”系统。他们可以将历史上所有导致了严重积水(比如道路中断、地铁站倒灌)的降雨过程数据和对应的内涝点监测数据,整理成一份宝贵的“极端事件集”。 利用 ReFine 的思想,他们可以训练一个模型,当气象雷达监测到类似的高风险降雨云团时,模型就能比传统模型更早、更准确地预测出哪些区域将成为“汪洋”,从而为应急部门提前部署抢险力量、发布交通预警、预排管网腾出空间等措施,争取到宝贵的“黄金半小时”。 某北方省会城市 在一次特大暴雨后,发现很多排水模型在雨强超过设计标准后就“崩溃”了。这正是因为模型没“见过”这么大的雨。通过 ReFine 对模型进行“极限施压”训练,可以让模型在超标准工况下,也能给出一个相对合理的、有参考价值的预测结果,而不是直接输出一个错误值。
实操注意事项:城市内涝模型对数据的时空精度要求极高。分钟级的降雨数据、实时更新的管网液位数据、泵站运行状态数据等,都是喂给 ReFine 模型的“精饲料”。没有好的数据基础,再好的算法也只是空中楼阁。
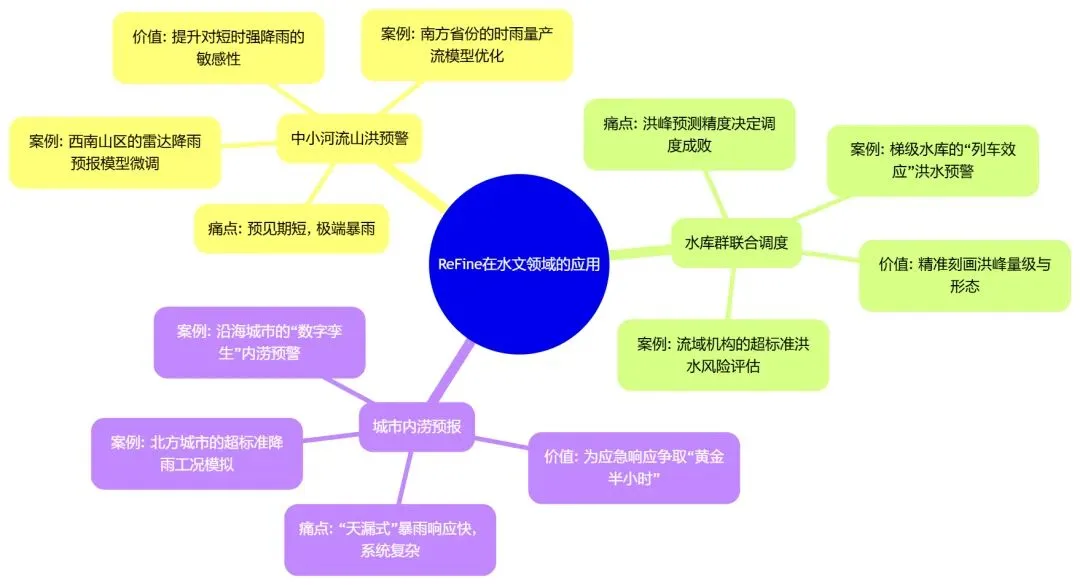
图4:ReFine 方法在水利水文领域的潜在应用场景
第四章:结语与展望——AI 不是“万灵药”,而是经验的“放大器”
聊到这里,我想大家对 ReFine 这个方法应该有了一个比较立体的认识。它通过一种非常聪明的方式,解决了我们长期以来在极端事件预测上的一个核心难题。
但是,作为一个在水利行业摸爬滚打了大半辈子的人,我必须强调一点: 任何先进的模型和算法,都不能替代我们水利人的经验和智慧 。AI 不是“万灵药”,它更像是一个强大的“经验放大器”。
它能从我们几十年积累的数据中,发现那些我们肉眼难以察觉的复杂规律。 它能在电光火石之间,完成我们大脑无法企及的海量计算,给出多种可能的预测情景。 它能把我们从繁琐的重复性劳动中解放出来,让我们有更多精力去思考更宏观的调度策略和风险应对方案。
ReFine 这样的技术,正是这座连接“历史数据”与“未来决策”的桥梁。它让我们有能力更好地“驯服”数据分布里的那条难以捉摸的“长尾”,在面对自然的极端考验时,能多一分从容,多一分胜算。
未来的水文预报,一定是 物理模型 + 数据驱动模型 + 专家知识 深度融合的时代。我们既要懂水文学、水力学,也要懂这些新的 AI 工具。
本文所提及的论文原文链接:https://arxiv.org/abs/2409.14232
