 夜雨聆风
夜雨聆风前段时间在做一个中文长文档的分析任务。大概三万字的行业报告,我把 PDF 原文直接丢给 AI,让它提取核心论点、整理成结构化摘要。
跑出来的结果不太满意——摘要抓的重点有偏差,有些明显是报告里最关键的结论被略过了,反而把一些边角数据拎出来说了一大段。我以为是提示词写得不好,调了两三轮措辞,还是差点意思。

后来鬼使神差地试了一件事:把同一份报告的核心段落翻译成英文,用英文提示词重新跑了一遍。
结果明显好了一截。不是”稍好一点”,是摘要的逻辑层次、重点捕捉、表述的精准度都上了一个台阶。同一个模型,同一个任务,唯一的区别就是语言换了。
这件事让我开始认真地去查资料和做实验——中文和英文之间的回答质量差异,到底是心理错觉,还是有结构性的原因。结论比我预想的要严重得多。
AI 的脑子里在用英语思考
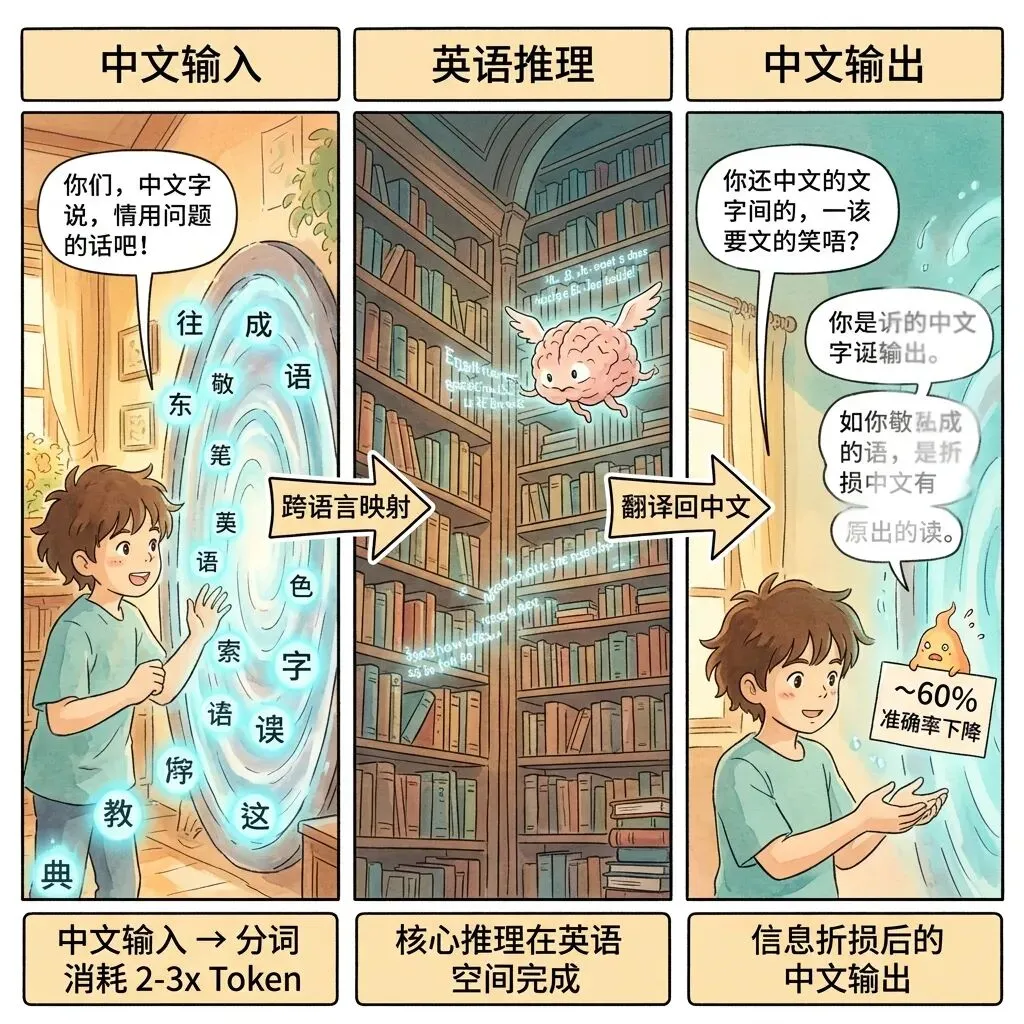
往下查之后发现,这不是什么小众发现,学术界已经研究得很清楚了。有一个说法叫”Thinking in English”——当你用中文向 AI 提问的时候,模型并没有在中文的语义体系里寻找答案。它的处理过程分三步走:先理解你的中文输入,把它投射到一个最接近英语的内部表征空间里;然后在这个英语空间里完成核心推理和事实检索;最后把结论”翻译”回中文输出给你。
换句话说,不管你问的是中文还是日文还是韩文,模型在中间那个最关键的”想问题”环节,用的都是英语。
这不是某一家模型的特例,是当前几乎所有主流大模型的共同特征。根本原因在于预训练数据的分布——前沿模型的训练数据里,英语内容的比例高得离谱,有的甚至超过 90%。剩下的空间被几十种语言瓜分,中文即使排第二,占比也只有百分之十几。模型在海量英语数据上建立了最强的逻辑推理路径,其他语言只能通过”映射”来蹭这条路径。
这种映射不是免费的。每一次从中文映射到英语、再从英语映射回中文,都会产生信息损耗。研究数据显示,在多轮对话的推理任务中,模型处理中文等非英语语言时的准确率平均下降接近 60%。这个数字远超我最初的预期,而且超过七成的性能下降可以归因于分词器低效和”以英语为中心的推理”带来的系统性误差。
我之前做的那个长文档分析任务,大概率就是撞上了这个机制。模型拿到三万字的中文输入,先在底层翻译了一遍,推理了一遍,再翻译回来。中间的信息折损累积下来,重点偏移就很正常了。
中文比英文多花一倍的”算力成本”
除了推理层面的损耗,还有一个更底层的问题:分词。
AI 处理文本的第一步是把连续的文字切分成一个个 Token。分词器决定了同样一段话需要消耗多少 Token——而 Token 是模型的”弹药”,用完就没了。
现在主流模型的分词器都是基于英语语料训练出来的,对英语单词的压缩效率极高。一个英文单词平均只消耗大约 1.3 个 Token。但中文的情况完全不一样——中文是表意文字,字符结构密集,没有明显的词边界。在同样的分词器下,一个中文字符通常需要 1.5 到 2.5 个 Token,有时候更多。
这意味着什么?同样一篇文章,中文版本的 Token 消耗量大概是英文版本的两到三倍。
后果很直接。第一,模型的上下文窗口就那么大,塞进去同等信息量的中文,能容纳的内容比英文少了一大截。处理中文长文档更容易触及上下文上限,模型对全局信息的注意力分配开始出问题。第二,一个完整的中文词汇被强行拆成好几个无意义的字节级 Token,模型得在浅层网络里额外花精力把这些碎片重新拼起来理解语义。这些额外开销累积下来,留给深层逻辑推理的计算资源就少了。
我做了一个简单的验证。同一段技术文档,中文版大概 5000 字,英文版大概 3000 词。中文版消耗了接近 8000 个 Token,英文版只用了不到 4000。差了整整一倍。而且中文版跑出来的摘要质量确实不如英文版——不是每次都差很多,但平均下来能感知到。
不同的模型在这方面表现也有差异。有些模型在多语言分词上做了专门优化,整体 Token 消耗量能比没优化的低三成左右。这个差距直接反映在使用成本和上下文利用效率上。对于经常需要处理大量中文内容的人来说,选模型的时候看一眼它对中文的分词效率,是一个很实际的考量。
推理、编程、翻译——各个领域的差异长什么样
说完底层机制,来看看在具体的应用场景里,这种中英文差异到底有多大。
先说推理。在覆盖物理、化学、生物、数学等学科的高难度基准测试里,绝大多数模型在英文题目上的准确率显著高于中文题目。这不仅是因为训练数据分布的差异,也因为中文学术题目的语言表述本身往往更复杂、更容易设置理解陷阱。有意思的是,在多语言数学测试中——就是用包括中文在内的各种语言来表述数学应用题——部分模型反而表现出了出色的跨语言理解能力。这说明不同模型在”桥接语言理解和逻辑推理”这件事上的能力参差不齐。
再说编程。代码本身是通用的结构化语言,但开发者在和 AI 交互时用的是自然语言。我用中文和英文分别下达过同样的编程指令,观察到一些有意思的倾向性差异。
用中文下达指令的时候,有些模型会表现出极度的”详尽性”——你让它改某个函数,它非要把整个文件重写一遍,还在代码里插满中文注释。对新手友好没错,但对有经验的开发者来说,这种冗长的输出完全是在浪费 Token 和时间。另一些模型则能更精准地理解意图,只给你需要的代码片段,生成的代码架构也更干净。我之前在用中文描述一个 Node.js 重构需求的时候就碰到过这种情况——一个模型精准地给了我要改的三个函数,另一个把整个 200 行的文件重新输出了一遍。
一个更深的发现:语言会重构 AI 的”价值观”
这是我在查资料过程中最没想到的一个结论。
AI 不是拥有一个固定不变的世界观。心理学层面的研究表明,同一个模型面对不同语言的提示,会展现出截然不同的文化倾向。
用中文提问的时候,模型更倾向于采用集体主义视角。它会更多地做”情境归因”——认为事物是可变的、处于发展关系中的,这和传统的东亚文化思维高度契合。但同样的问题翻译成英文再问一遍,模型会立刻切换到个体主义的逻辑框架,更强调个人能动性、固定属性和直接因果关系。
这有点像:语言不只是一个界面,它是一条隐形的轨道,会影响模型选择哪条推理路径。你用中文问”这个项目为什么失败了”,模型可能更倾向于分析团队协作和外部环境因素;同样的问题用英文问,它可能更聚焦于项目负责人的个人决策失误。
说实话,看到这个研究结论的时候我有点发愣。以前总觉得 AI 就是一个冷冰冰的计算器,给什么数据吐什么结果。但实际上,语言作为预训练数据的载体,已经把不同文化体系的思维方式编码进了模型的权重里。你选择用什么语言和它对话,就是在选择激活哪一套思维方式。
幻觉:中文比英文更容易”编”
还有一个很实际的问题——幻觉,也就是 AI 编造看起来合理但实际上完全错误的内容。
在处理英语常识和主流知识时,主流模型的幻觉率已经控制得相当好,某些任务下降到了 5% 以下。但涉及到中文的长尾知识——比如中国历史典故、地方风俗、特定行业术语——幻觉率会明显上升。
原因不难理解。模型的英语训练数据是海量的,关于莎士比亚、美国独立战争、硅谷创业史的内容,它见过无数遍,很难编错。但关于中国某个朝代的具体典故、某句古诗的出处和背景,训练数据里的高质量中文内容可能就那么几条。模型为了”满足用户需求”,在没有足够依据的情况下强行推演,编造的概率就上去了。
有一个专门测试中文幻觉的基准叫 HalluQA,里面设计了大量针对中国历史、风俗和网络现象的对抗性问题。测试结果显示,很多模型在这些复杂的中文对抗性问题上失效率超过 50%。
面对这种情况,不同模型的策略分化很有意思。有的模型更倾向于坦诚地说”我不知道”或”文献中未提供相关信息”。用户可能会觉得它不够”聪明”,但它没说的时候,说出来的东西可信度极高。另一些模型则很少拒绝回答,总是尽力给出一个看上去完整的答案——这让它在回答数量上占优,但在碰到中文长尾知识时,捏造史料或编造解释的概率明显更大。
我个人在做严肃的信息检索时更偏好前者。宁可它告诉我”不确定”,也不要给我一个看似有理实则编造的答案。编造的内容你如果没有独立验证的能力,会当真的——这比不知道更危险。
医疗领域:中文的最大软肋在传统中医
顺着幻觉这个话题,延伸到一个更极端的垂直领域——医疗。
在现代医学领域,主流模型交出了不错的成绩单。面对中文的执业医师资格考试,某些模型的准确率超过了 85%,远超及格线。在复杂的临床病例分析上也表现出了相当的实力。
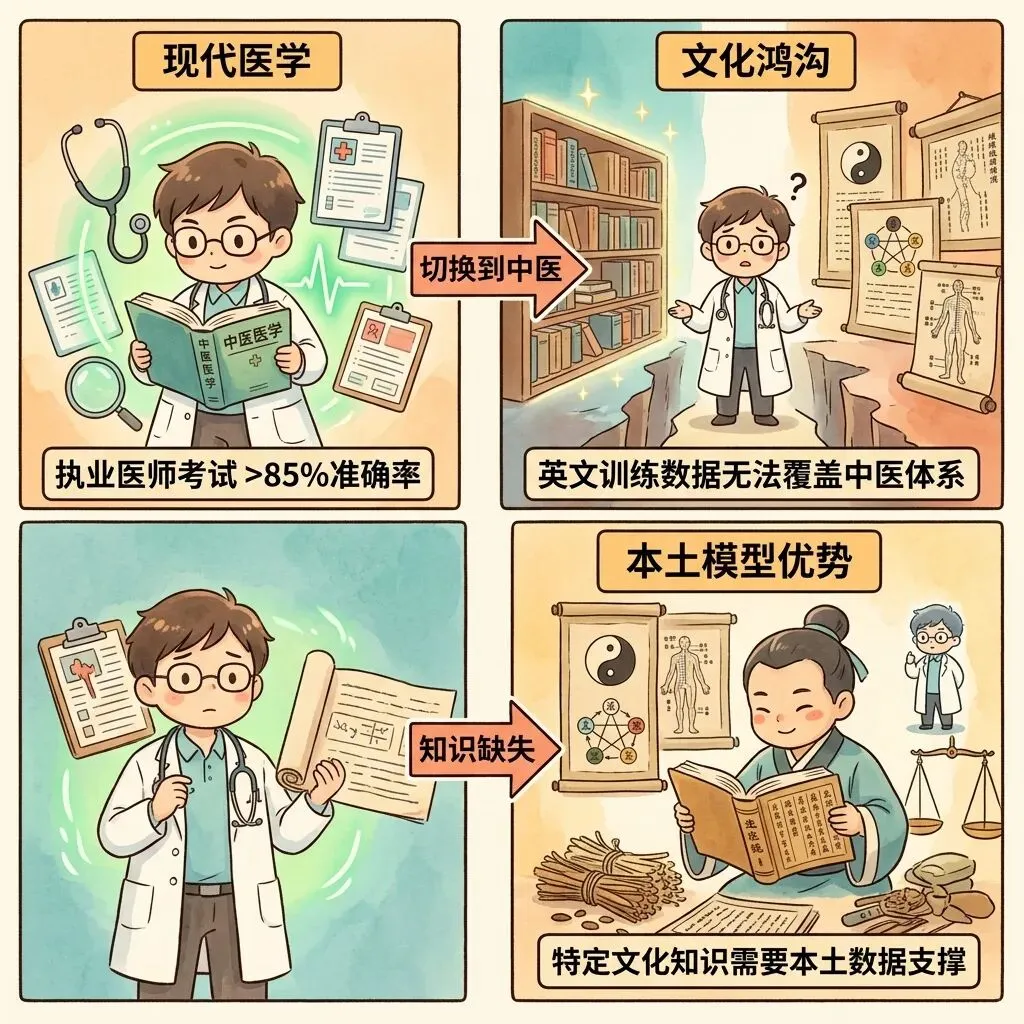
但传统中医是一个完全不同的故事。中医根植于中国古典哲学,核心概念——阴阳、五行、经络、气血——在英文中没有完全对等的医学翻译。相关的高质量英文训练语料几乎为零。这就意味着,那些以英语为核心训练的模型,在中医诊断上的表现会显著落后于中国本土开发的大语言模型。
这个案例其实揭示了一个更普遍的道理:当跨文化知识缺乏足够的训练数据支撑时,单纯依赖底层逻辑推理能力并不能弥补特定文化知识的鸿沟。你不能指望一个在英语世界里学会了”怎么想”的模型,自动就能理解一个完全不同知识体系里的概念。
实操建议:怎么绕过这些坑
搞清楚了中英文差异的底层原因之后,有几个日常使用中可以直接落地的策略。
第一个,也是我自己验证过效果最明显的:在处理复杂的逻辑分析、代码架构设计或深度学术研究时,用英文写核心指令,但要求模型用中文输出。比如我现在做复杂任务的提示词会这么写:“Analyze the underlying architectural flaws in this codebase step-by-step. Think in English to maintain strict logical coherence, but generate the final technical report entirely in professional Simplified Chinese.” 这种策略能绕过中文分词的效率损耗,激活模型在英语数据上习得的最强逻辑推理链条,同时拿到符合中文阅读习惯的输出。
我自己试下来,这种”英文指令 + 中文输出”的混合模式,在代码分析和技术文档整理上的效果比纯中文提示词好了一截。不是每次都有质的飞跃,但平均质量稳定提升了。
第二个,处理超长的中文文档时,要注意上下文窗口的实际承载力。前面说了,同等信息量的中文 Token 消耗是英文的两到三倍。如果你有一份十万字的中文报告要分析,不要一股脑全扔进去——分块处理,每次喂最相关的部分,效果会好很多。有条件的话,选择上下文窗口更大的模型来处理中文长文本。
第三个,在涉及中国特有的文化知识、历史典故、行业术语的场景里,对模型的输出保持更高的警惕。这些是幻觉的高发区。如果条件允许,对同一个问题用两个不同的模型跑一遍,看答案是否一致。不一致的地方大概率就是需要人工验证的地方。
第四个,如果你的工作场景经常需要中英双语切换,建议在项目级别的规则文件里——比如 CLAUDE.md 或 AGENTS.md——明确写上语言偏好和输出格式要求。这样每次新建 session 不用重新交代,模型一进来就知道该怎么处理语言。
最后
从那个不太满意的中文长文档摘要开始,到查完一大堆文献资料、跑了不少对比实验,我现在对一件事有了清晰的认识:语言不只是你和 AI 交流的界面,它是决定模型内部走哪条推理路径的隐形轨道。
这不是一个”中文不好用”的结论。中文当然好用,而且随着各家模型在多语言训练上的持续投入,中英文之间的差距正在缩小。但在当下这个阶段,了解这种差异的存在,知道在什么场景下切换语言、怎么组合使用能拿到更好的结果——这就是一种实实在在的效率优势。
不了解的人用中文问完就完了,了解的人会在关键任务上多做一步。同样一个模型,输出质量差一截,原因可能就在这里。
