 夜雨聆风
夜雨聆风一句话讲清楚👉🏻 中国科学院软件研究所与快手科技联合发布 OmniBehavior ,首个基于真实工业日志构建的大语言模型行为模拟基准,揭示了 LLM 普遍存在"超活跃、人格同质化、乌托邦偏向"三大系统性偏差,最强模型 Claude-Opus-4.5 总分也只有 44.55 分。
用大语言模型来模拟真实用户的行为,这件事你真的觉得 LLM 做到了吗?
当 GPT-5 、 Claude-Opus 、 DeepSeek-V3 这些旗舰模型一个接一个涌现时,研究者们开始认真追问:这些模型能够真实复现一个活生生的用户在刷视频、看直播、逛电商时的那些细碎而真实的行为吗?
答案令人清醒。
来自中国科学院软件研究所和快手科技的研究团队,联手构建了 OmniBehavior——首个完全基于真实工业行为日志的 LLM 行为模拟基准。他们把当前最强的一批模型全部拉进来测试,结果发现:最好的模型总分只有 44.55 ,多数模型在二值行为任务上 F1 不超过 40%。更重要的是,他们发现了 LLM 行为模拟里一个被严重忽视的根本性缺陷——模型系统性地把所有用户都过滤成了一个"正向-平均人"。
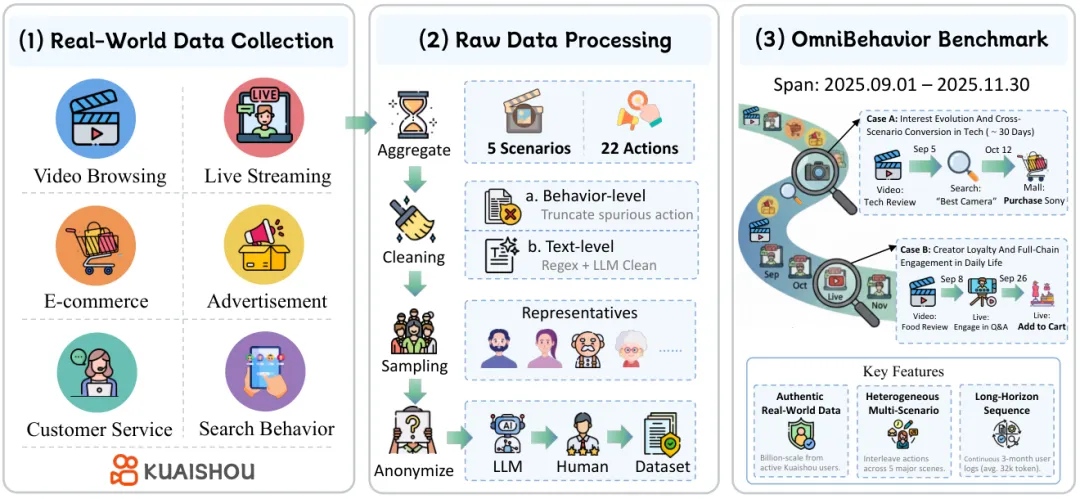
现有基准的"隧道视野"问题
在 OmniBehavior 之前, LLM 用户模拟的评测基准长期存在一个根本性的局限——只看到了用户行为的一个局部截面。
现有数据集要么局限于单一场景(只看推荐系统、或只看对话),要么使用合成数据(让 LLM 自己生成"用户"再来测试),要么行为类型过于单调(只有"点击/不点击"的二值标签)。这种"隧道视野"带来了一个严重后果:研究者在虚假的基准上优化出了虚假的能力。
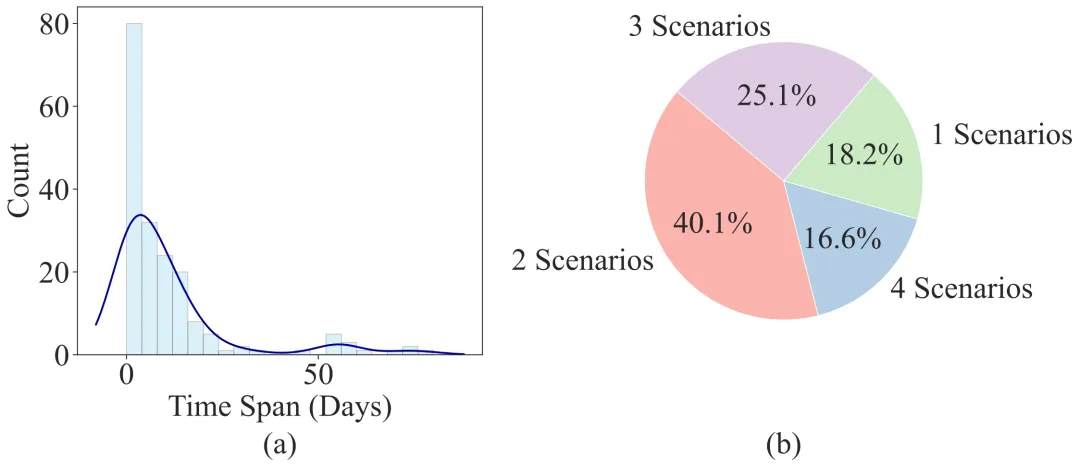
真实的用户不是这样的。一个真实用户在某天搜索了"小米发布会",随后连续几天在视频流里与相关内容互动,某天在直播间里加购,最终下单——这整条决策链跨越了 12 天、贯穿了搜索、视频浏览、直播、电商四个场景。你用哪个单一场景的数据集能捕捉到这条因果链?
OmniBehavior 团队对 180 个高价值转化事件(如"购买"行为)进行了系统性溯源,发现:
这两个数字,从根本上否定了"单场景、短时域"评测的有效性。
OmniBehavior 数据集:快手真实日志, 200 名用户, 8143 步行为序列
OmniBehavior 的数据来自全球日活超 4 亿的快手平台,采集时间段为 2025 年 9 月至 11 月,覆盖 5 个场景、 22 种行为类型。
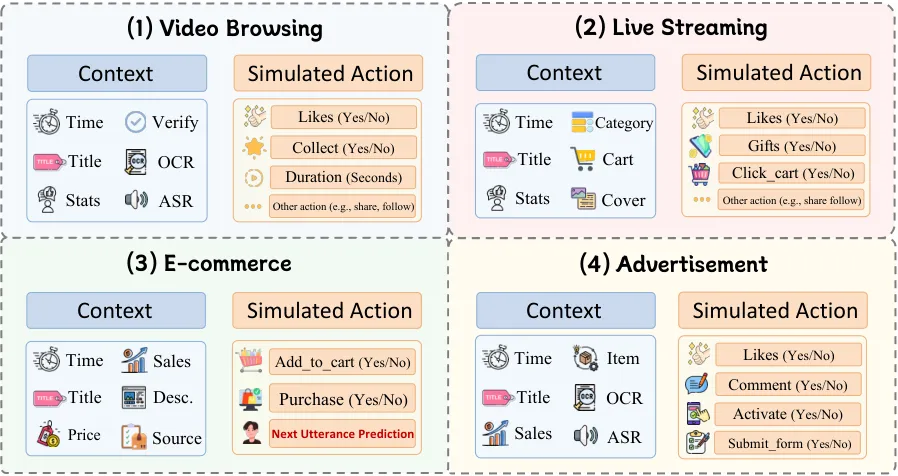
五个场景及对应行为的完整图景如下:
| 场景 | 行为类型(部分) |
|---|---|
| 视频浏览 | 观看、完播、点赞、收藏、分享、评论、关注、下载 |
| 直播 | 点赞、评论、送礼、举报、加购 |
| 广告 | 点击、表单提交、激活、购买 |
| 电商 | 加购、购买、多轮客服对话 |
| 搜索 | 用户主动查询 |
用户数据经过了严格的四步构建流程:
第一步:跨场景行为聚合。 将各场景的原始日志按时间戳交错排列,构建统一时序行为序列,每条记录附带富元数据——视频字幕、 OCR 文字、 ASR 语音转录、商品描述、互动统计等。
第二步:两级数据清洗。 行为级采用 99.9 百分位截断(视频观看上限 879 秒,直播上限 9601 秒);文本级先用正则处理结构噪声,再用 Qwen2.5-72B-Instruct 纠错。 OCR 文本压缩率 85.9%, ASR 文本压缩率 5.2%。
第三步:代表性用户采样。 将每个用户编码为涵盖人口属性、活跃度、兴趣分布、场景偏好四个维度的特征向量,经 K-Means 聚类后选取最近质心用户,最终筛选出 200 名代表性用户,平均行为序列长度 8143 步,最长超过 10 万步。
第四步:隐私匿名化。 使用本地部署的 Qwen3-235B 模型检测并替换姓名、电话、地址等敏感实体,同时过滤有害内容,经人工核查确保合规。
多场景数据揭示的两个核心事实
单场景数据画不出完整的用户
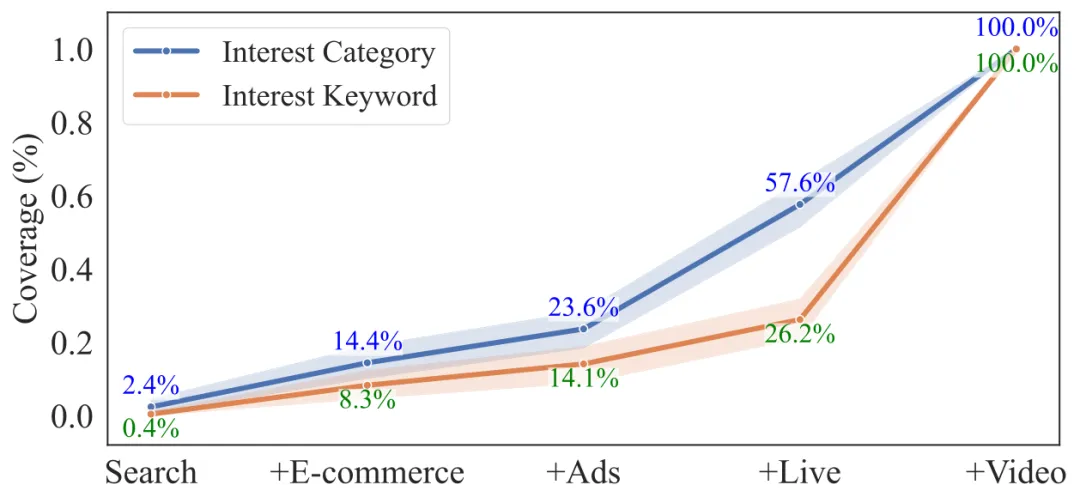
研究团队用 Claude-3.5-Sonnet 从"点赞"行为中提取用户兴趣标签,分别在单场景和多场景条件下构建用户画像,发现:每新增一个场景,兴趣类别覆盖率持续增长约 20-30%。
单场景数据给出的用户画像是片面的、有偏的。多场景数据才能捕捉到用户稳定的核心特征。
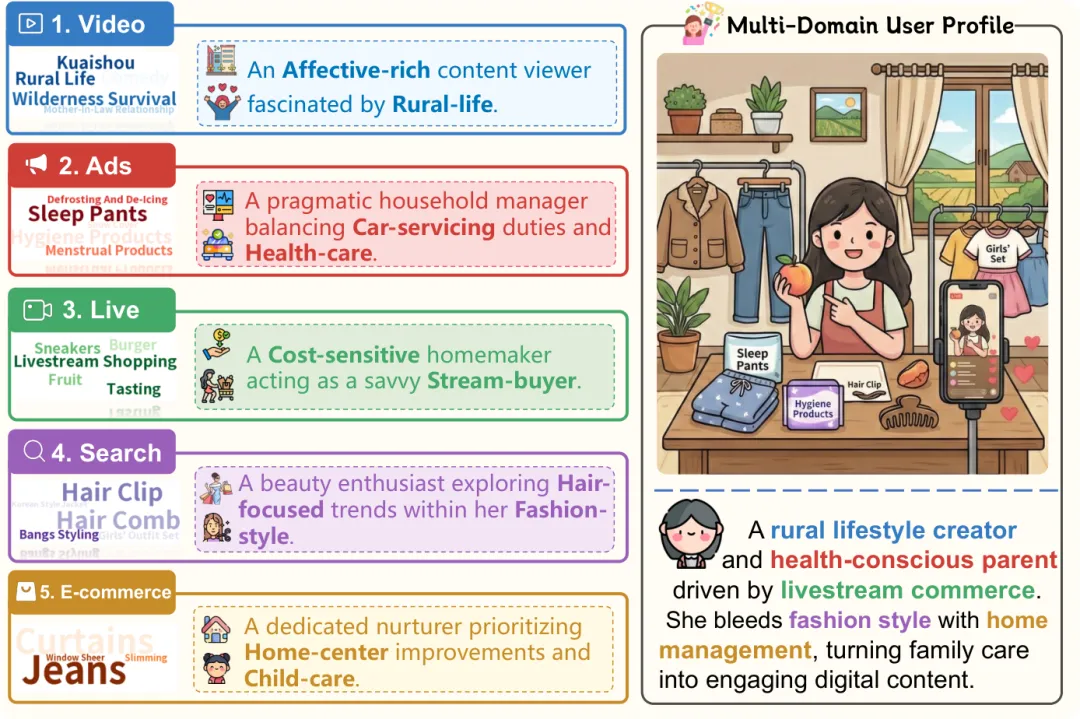
因果链横跨场景与时间
对 180 个高价值转化事件的溯源分析,配合跨场景因果链案例,清晰展示了人类决策的时空结构。
论文中有一个具体案例:用户在某天主动搜索"小米发布会",随后在视频流、直播间多次与相关内容互动,跨越 12 天后在直播间加购,最终完成购买。

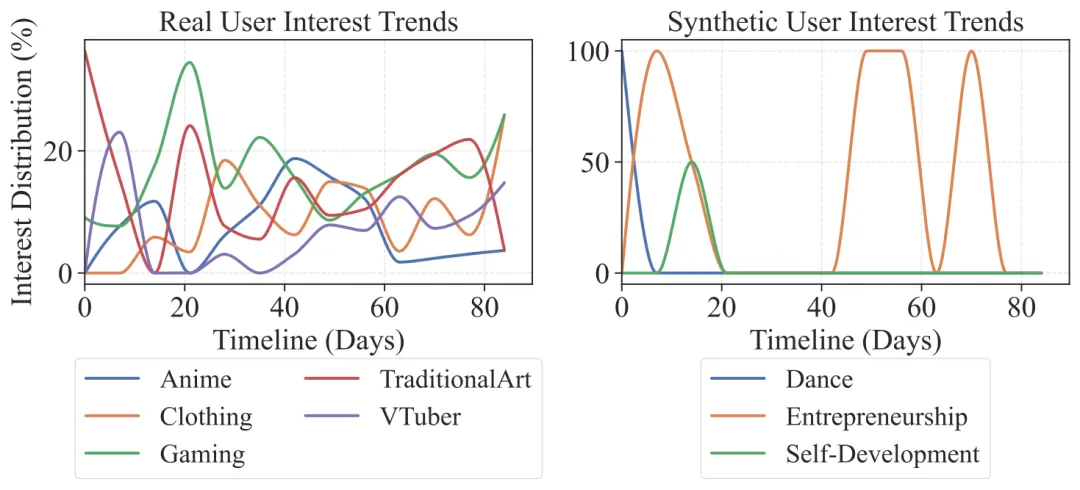
真实数据 vs. 合成数据:兴趣演化的根本差异
OmniBehavior 还与经典的合成长时域数据集 LoCoMo 进行了对比。
| 指标 | OmniBehavior (真实) | LoCoMo (合成) |
|---|---|---|
| 平均兴趣漂移率( 1−Jaccard ) | 0.6311 | 0.1698 |
| 演化特征 | 随机柔性,多维交织渐变 | 机械刚性,任务驱动式突变 |
真实兴趣的演化是渐进的、柔性的、多维交织的;合成数据的兴趣变化则是跳跃式的任务驱动突变。这种差异,让基于合成数据训练和评测的模型,根本无法习得真实用户偏好演化的内在规律。
评测框架:三类任务,全面覆盖行为类型
OmniBehavior 的评测任务遵循一个统一的预测范式:给定用户画像 p_u 、历史行为序列 H_u 和当前场景上下文 c_t ,预测用户在当前时刻的行为 y_t 。形式化表示为:
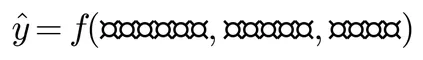
根据行为类型,评测分为三类:
总评测任务数:6000 个,保证时间均衡、场景均衡、价值分布均衡。
主实验:最强模型总分 44.55 ,二值行为 F1 普遍低于 40%
参与评测的模型涵盖当前最强的闭源与开源阵营:
闭源模型: Claude-Opus-4.5 、 Claude-Sonnet-4.5 、 Claude-Haiku-4.5 、 Claude-Sonnet-4 、 Gemini-3-Flash 、 GPT-5.2 、 GPT-4o
开源模型: GLM-4.7 、 DeepSeek-V3 、 Kimi-K2-Instruct-0905 、 Qwen3-235B-A22B-Instruct
实验统一采用 32K token 上下文窗口,温度设为 0.1 ,推理框架使用 LangChain 。
完整结果:
| 模型 | 视频-二值 | 视频-连续 | 直播-二值 | 广告-二值 | 电商-二值 | 电商-文本 | 总分 |
|---|---|---|---|---|---|---|---|
| Claude-Opus-4.5 | 33.05 | 64.19 | 31.70 | 51.16 | 29.98 | 57.21 | 44.55 |
| Claude-Sonnet-4.5 | 18.85 | 65.95 | 25.00 | 42.77 | 36.13 | 54.26 | 40.49 |
| Claude-Haiku-4.5 | 22.84 | 63.26 | 26.11 | 30.00 | 26.37 | 50.29 | 36.48 |
| Claude-Sonnet-4 | 25.29 | 64.62 | 28.86 | 36.81 | 16.50 | 49.13 | 36.87 |
| Gemini-3-Flash | 22.09 | 53.79 | 25.61 | 24.64 | 19.65 | 49.80 | 32.60 |
| GPT-5.2 | 31.54 | 65.01 | 28.63 | 33.60 | 29.32 | 46.29 | 39.07 |
| GPT-4o | 27.88 | 62.75 | 28.15 | 25.24 | 28.66 | 44.92 | 36.27 |
| GLM-4.7 | 26.86 | 64.43 | 28.97 | 40.34 | 32.90 | 55.25 | 41.46 |
| DeepSeek-V3 | 21.42 | 63.98 | 27.92 | 25.74 | 33.31 | 52.13 | 37.42 |
| Kimi-K2-Instruct | 23.30 | 64.80 | 28.60 | 31.19 | 29.94 | 47.83 | 37.61 |
| Qwen3-235B | 18.26 | 62.38 | 23.84 | 23.19 | 19.22 | 45.74 | 32.11 |
几个值得关注的发现:
第一,总体表现触目惊心地低。 最强模型 Claude-Opus-4.5 总分仅 44.55 ,多数模型在视频、直播场景的二值行为 F1 集中在 20-35 区间,处于远低于实用阈值的水平。
第二,开源不弱于闭源。 GLM-4.7 以 41.46 的总分位居第二,超越了 GPT-5.2 ( 39.07 )、 Claude-Sonnet-4.5 ( 40.49 )等多个闭源强模型。 DeepSeek-V3 在电商二值任务( 33.31 )上超越了 Claude-Opus-4.5 ( 29.98 )。
第三,连续行为(观看时长)是相对容易的子任务。 多数模型在视频连续行为上得分集中在 62-66 区间,但这一维度更多反映全局统计分布的拟合,不代表真实的个体行为建模能力。
长上下文:扩大窗口并不持续有效
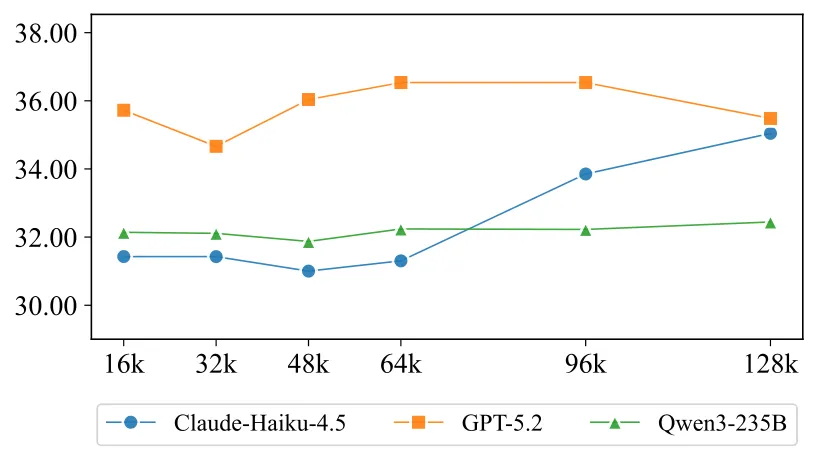
给 LLM 喂更多历史信息,模拟能力就会提升吗?团队用 66 名历史超过 128K token 的用户进行了专项测试,上下文窗口从 16K 依次扩展到 128K 。
结果:增加序列长度不能持续改善性能,表现出明显的平台效应( performance plateauing )。
这说明仅靠扩大上下文窗口是不够的——LLM 在处理真实用户的超长行为序列时,面临的不只是"看不到"的问题,更是"理解不了"的问题。
记忆管理策略的效果
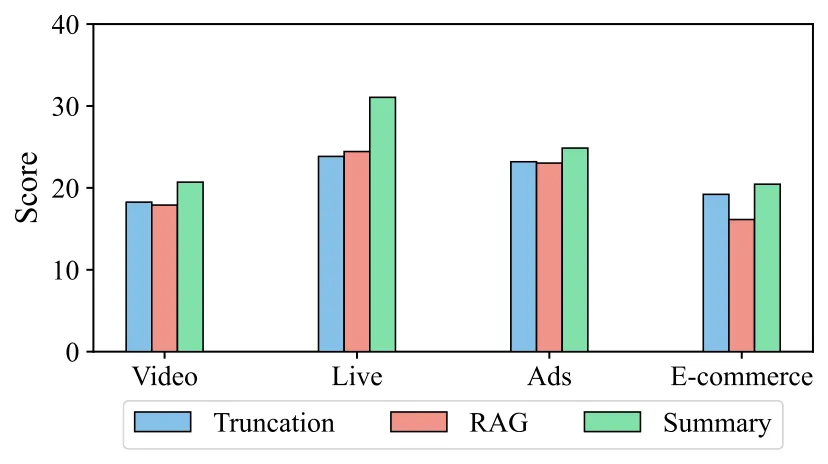
团队在 Qwen3-235B 上对比了三种记忆管理策略:
| 策略 | 视频 | 直播 | 广告 | 电商 | 平均 |
|---|---|---|---|---|---|
| Truncation (截断) | 18.26 | 23.84 | 23.19 | 19.22 | 21.13 |
| RAG ( top-100 检索) | 17.9 | 24.44 | 23.03 | 16.14 | 20.38 (↓3.6%) |
| Summary (周期摘要) | 20.7 | 31.06 | 24.86 | 20.45 | 24.27 (↑14.9%) |
周期摘要策略效果最好,平均提升 14.9%。但绝对表现依然有限,说明现有记忆管理方案远未解决长时域建模问题。 RAG 策略反而带来了轻微的性能下滑,可能是因为检索引入了无关噪声。
三大系统性偏差: LLM 把所有用户都变成了"正向平均人"
这是本文最有意思的部分。研究团队从三个维度,拆解了 LLM 行为模拟器内置的结构性偏见。
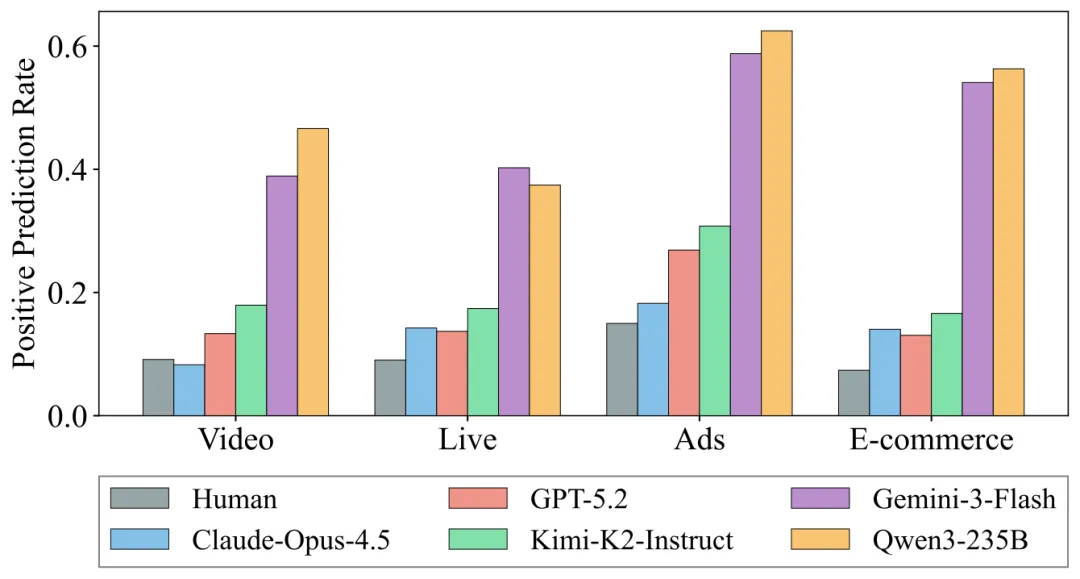
偏差一:超活跃偏差( Hyper-activity Bias )
真实人类在各场景下的正向交互率(点赞、购买、关注等)低于 10%。
而 LLM 仿真器的正向预测率呢? Qwen3-235B 和 Gemini-3-Flash 将正向预测率过估计了 40-60 个百分点。
换句话说, LLM 眼中的用户,对什么都感兴趣、对什么都点赞——一个永不疲倦的理想消费者。
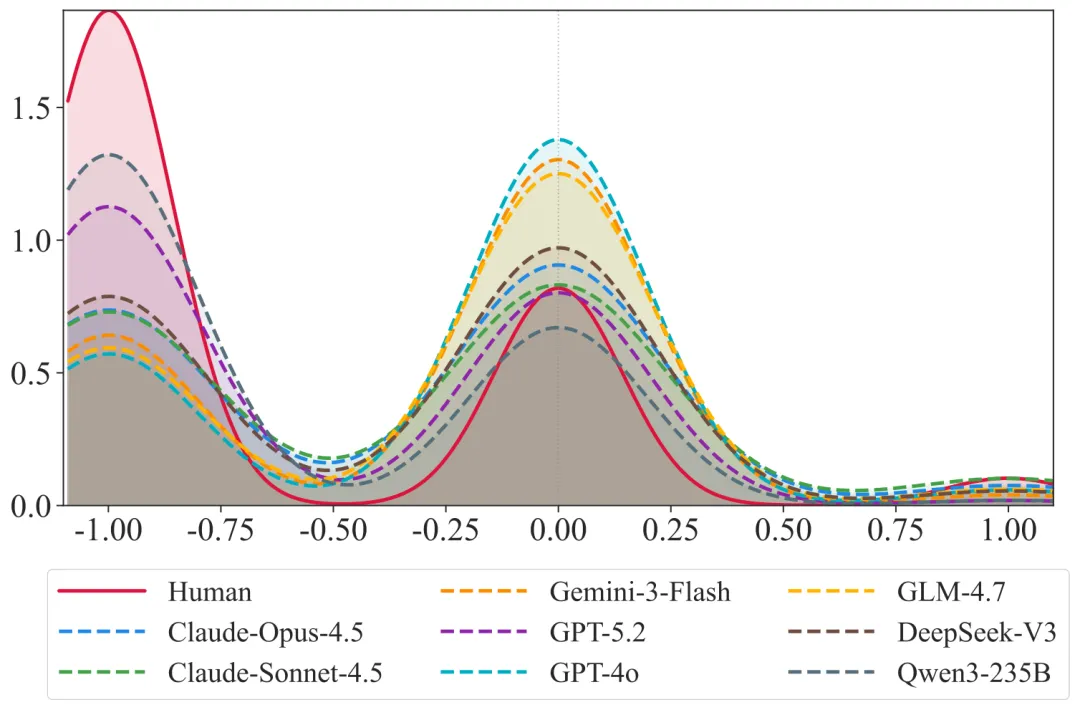
偏差二:乌托邦倾向( Utopian Tendency )
团队用 Claude-Sonnet-4.5 对电商客服对话做了情感标注(-1 负面 / 0 中性 / +1 正面),结果是:
语言风格的差异更加具体。团队从礼貌标记、模糊语言、规避指责、情绪控制、面子保护五个维度进行评分:
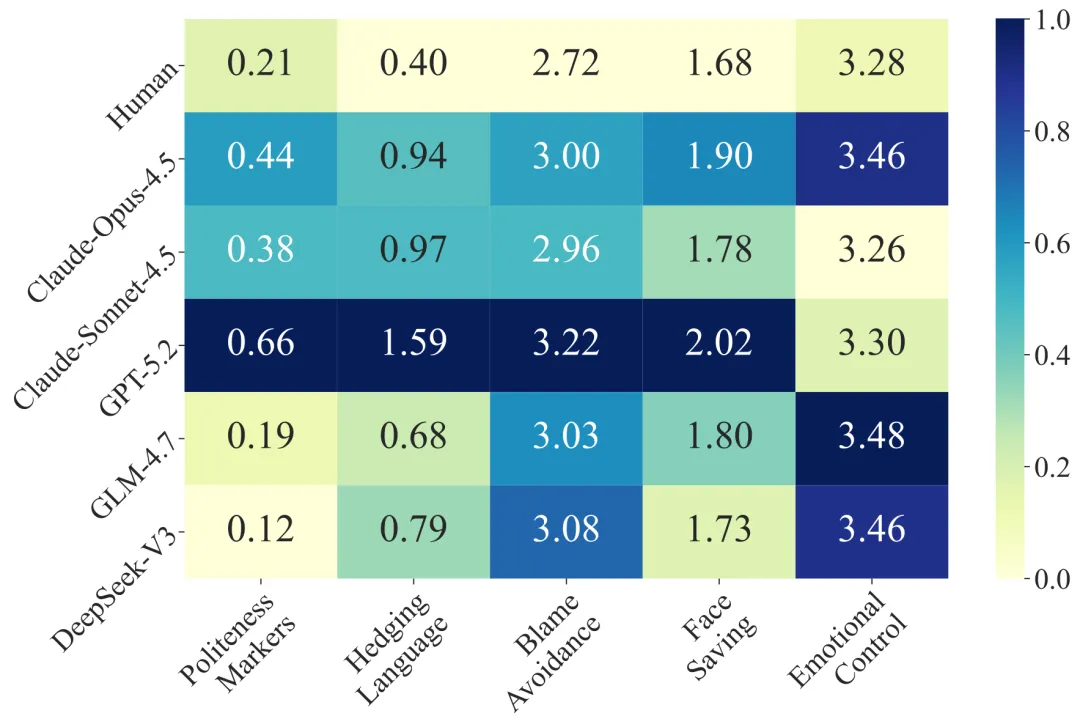
LLM 用户说话方式:"Could you please help me with this?" / "I would like to inquire about..."
真实用户说话方式:退款、缺货、假货、破损、催促、拦截。
词云对比,一目了然:

这个偏差的根源很清楚: RLHF 训练过程把 LLM 打磨成了永远礼貌、永远建设性的对话机器,这恰恰与真实用户在购物纠纷场景下的情绪化、对抗性行为完全相反。
偏差三:人格同质化( Personality Homogenization )
这是三个偏差中最难察觉、也最根本的一个。
研究团队为每个用户构建一个 17 维特征向量(各行为类型的正向率),分别计算:
- 用户内距离:同一用户历史前半段与后半段特征向量的距离(反映个体行为一致性)
- 用户间距离:不同用户特征向量之间的距离(反映群体多样性)
这两个距离的比值( Ratio ),反映了"用户内差异"相对于"用户间差异"的大小。
| 群体 | 用户内/用户间距离比 | 含义 |
|---|---|---|
| 真实用户 | ≈ 0.29 | 用户间差异远大于用户内差异 |
| LLM 仿真用户 | ≈ 0.70–0.87 | 用户内外分布高度重叠 |
真实用户群体是高度多元的——不同人之间的行为差异,远大于同一个人随时间的行为变化。
而 LLM 仿真的用户群体,则趋向于收敛到同一个"中心点":每个"人"的行为看起来都大同小异,个体差异消失了,长尾行为丢失了。
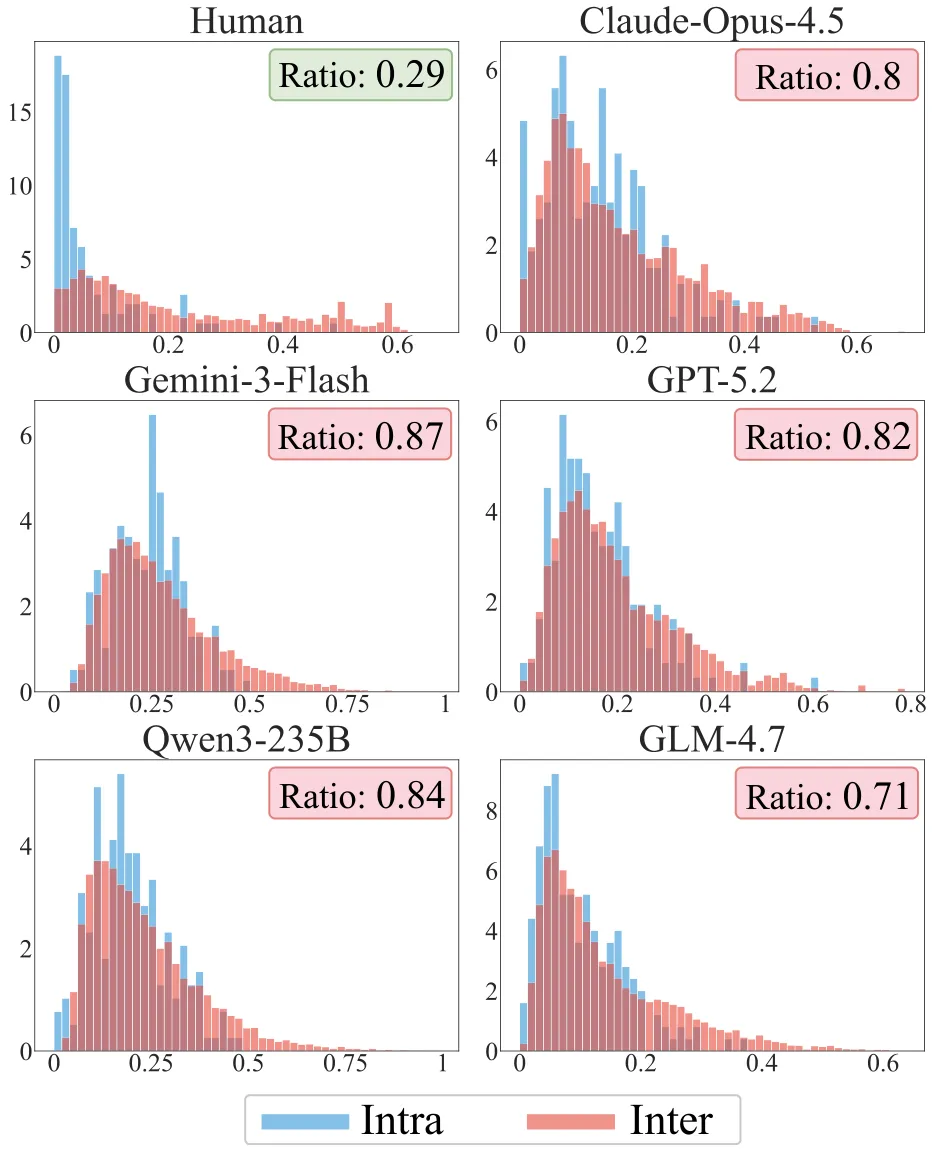
所有测试模型都展示了类似的同质化特征:
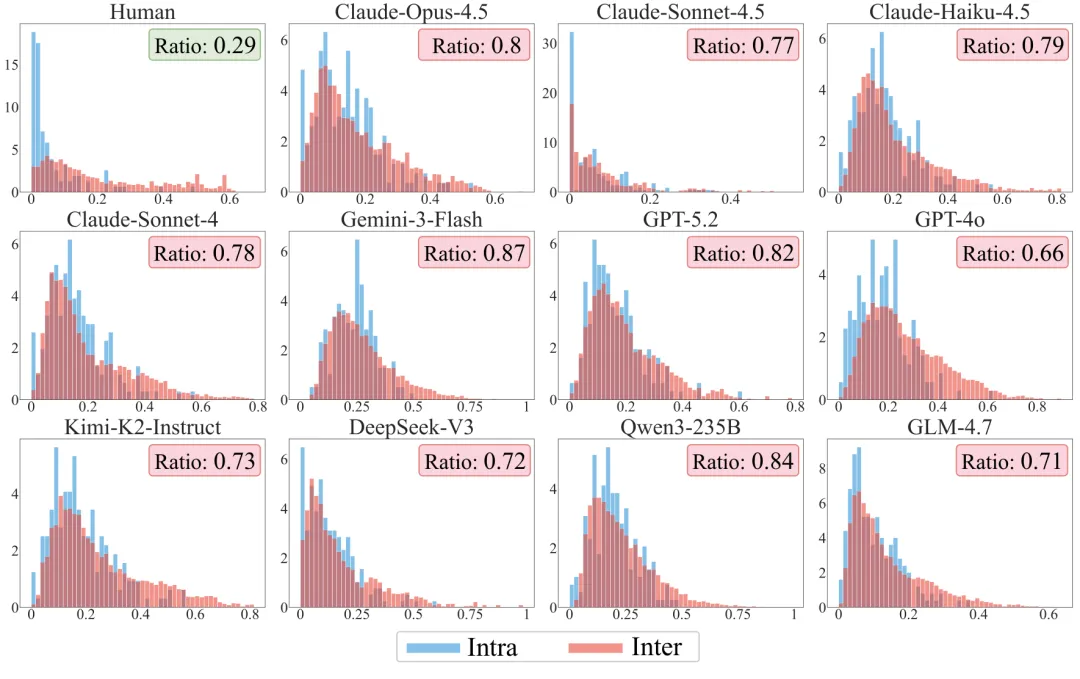
这三个偏差并非独立存在——它们是同一个机制的三个侧面: RLHF 训练过的 LLM 内置了一套"正向-平均过滤器",把所有个体差异、负面情绪、长尾行为系统性地抹平,输出一个永远积极、永远礼貌、行为趋同的"理想用户"。
这个"理想用户"在真实世界里根本不存在。
用户多样性与数据集统计
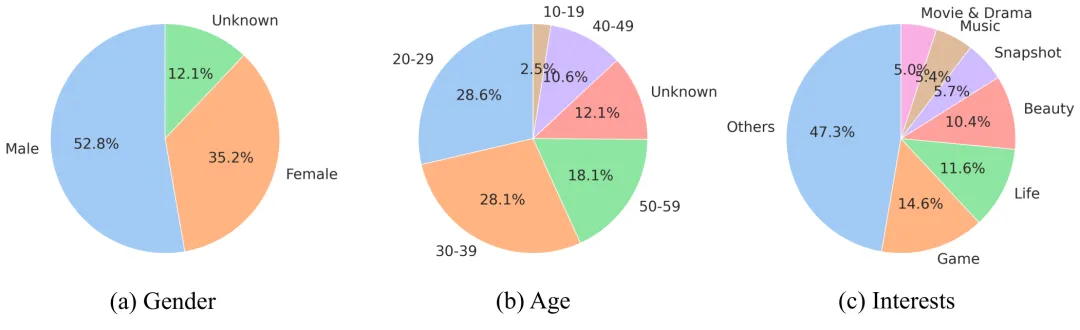
OmniBehavior 的 200 名代表性用户在人口属性和行为特征上有意保持了覆盖均衡:
对未来研究的启示
这些发现指向了几个具体的研究方向。
跨场景记忆。用户的购买决策可能埋线在 12 天前的一条搜索记录里,现有模型无论是截断策略还是 RAG ,对这种跨场景、长时序的因果链都处理不好。
个性化建模。指令微调把 LLM 打磨得越来越"平均",但真实用户群体的价值恰恰在于差异性。怎么让模型在面对不同用户画像时输出真正有区分度的行为,是个硬问题。
负向情感表达。 RLHF 让模型变得礼貌、积极,但真实的退款纠纷、差评投诉、愤怒催促,也是平台需要准确捕捉的信号。目前 LLM 几乎完全丧失了这部分表达能力。
更扎实的评测基准。用合成数据评测,等于用 LLM 生成的"用户"测试 LLM 的用户理解能力——这个循环从根本上就是歪的。 OmniBehavior 把基准搬到了真实工业日志上,是正确的方向。
资源链接
📄 论文链接
https://arxiv.org/abs/2604.08362
💻 代码仓库
https://github.com/icip-cas/OmniBehavior
🌐 项目主页
https://OmniBehavior.github.io
