 夜雨聆风
夜雨聆风哈喽,大家好!这里是「AI 前沿每日报」,从今天开始,我们会每天为你整理全球 AI 领域的最新技术突破、产业动态,帮你用最短的时间,追上 AI 时代的脚步,不用再在海量信息里大海捞针。
今天是我们的第一期,就来盘点一下 2025 年 4 月,AI 领域刚刚爆出的几个重磅突破,每一个都在改写行业的规则:

大模型不再只会聊天,开始学会 “上班干活” 了
过去我们总说,大模型就是个 “聊天机器人”,能陪你唠嗑、帮你写点文案,但真要让它干正经的、复杂的工作,总差点意思。但这个月,这个情况彻底被打破了。
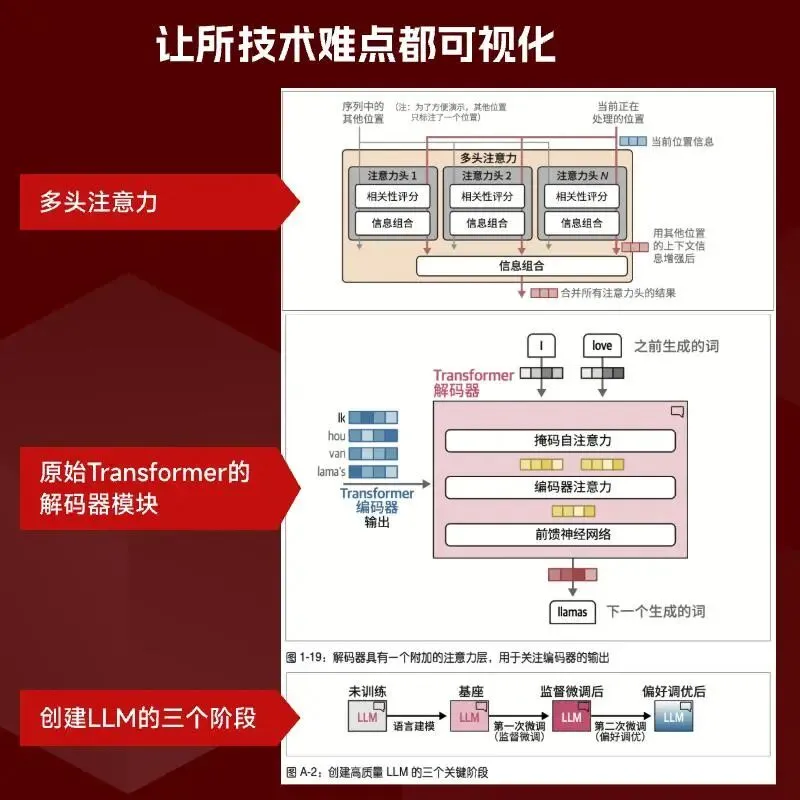
1. 国产大模型实现 “8 小时工作制”,自己当程序员
第一个突破,来自国内的智谱 AI,他们发布的 GLM-5.1,直接让大模型拥有了超长续航的工作能力。
过去的 AI 模型,都是 “一问一答” 的模式:你问一句,它答一句,稍微复杂点的任务,比如从零开发一个完整的软件,写着写着它就忘了前面的逻辑,或者写两行就停了,得你不断盯着、提醒、纠正,根本没法独立干活。
但 GLM-5.1 不一样,它可以自己独立、持续工作超过 8 小时! 就像一个真正的职场人一样,拿到任务之后,自己规划步骤、自己写代码、自己跑测试、自己发现性能瓶颈、自己修改优化,整个过程完全不用你插手。
实测里,我们给它一个任务:做一个能快速检索海量数据的系统。它连续做了 600 多次优化、6000 多次操作,最后把系统的速度做到了之前全球最好成绩的 6 倍! 而且在最贴近真实软件开发的专业测试里,它第一次实现了国产模型对海外顶级闭源模型的超越,国产开源模型,终于冲进了全球第一梯队。
2. Meta 的王炸:从开源布道者,到能 “动手做事” 的超级智能
沉寂了 9 个月之后,Meta 也甩出了自己的 AI 王炸 —— 全新的大模型 MuseSpark,代号 “牛油果”。
这个模型彻底跳出了 “大语言模型” 的框架,它不再是只会打字的聊天工具,而是一个能看、能想、能动手的 “行动大脑”。
比如:
你给它一张家电故障的照片,它不仅能认出零件,还能一步步分析故障原因,用动态标注教你怎么排查;
你给它一张复杂的科研图表,它能直接拆解数据逻辑,给你研究级的推理结论;
你对着它拍一段你健身的视频,它能实时分析你的肌肉激活状态,给你专业的动作指导。
它的性能也直接冲到了全球第四,在图表推理、医疗健康推理这些任务上,甚至超过了 GPT-5 和谷歌的 Gemini! 更重要的是,Meta 终于完成了商业觉醒:过去他们靠开源 Llama 系列赚足了口碑,却没赚到钱,这次他们转向闭源商业化,要把这个模型直接装进 Facebook、Instagram、WhatsApp 这些 30 亿用户的产品里,让所有人都能用上这个超级智能。
3. OpenAI 的新推理模型:AI 自己能拆 600 步任务解决问题
而 OpenAI 也没闲着,他们发布了全新的推理模型 o3 和 o4-mini,把 AI 的自主能力拉到了新高度。
o3 模型第一次实现了用图像做思维链推理,而且它的工具调用能力直接拉满:单次任务里,它可以自己连续调用 600 次工具,自己拆分复杂任务、自己找对应的工具、一步步搞定,完全不用人指挥。
算力革命!中国团队突破了困扰 AI 几十年的 “内存墙”
大模型越来越强,背后的算力瓶颈却越来越突出:我们总在堆参数、堆显卡,但数据搬运的速度跟不上,算力根本用不上。而这个月,两个重磅的硬件突破,直接给这个问题拿出了颠覆性的答案。

1. 复旦团队的 “长缨” 芯片:比闪存快 100 万倍,打破存储壁垒
复旦大学的周鹏、刘春森团队,在《自然》杂志上发表了一项重磅成果:他们的 “长缨” 原型存储芯片,读写速度做到了 400 皮秒。
这是什么概念? 我们现在手机、电脑里用的传统闪存,读写速度是微秒级的,而这个新芯片,比它快了整整 100 万倍!
过去我们的计算机体系里,存储是个 “金字塔”:
塔尖的缓存,速度极快,但断电就丢数据,还贵;
中间的内存,速度还行,但也得不断供电刷新,断电就没;
塔底的硬盘 / 闪存,能存数据,但是速度慢得要死。
数据要在这些层级之间来回搬,这就是 AI 里著名的 “内存墙”—— 就算计算核心再快,也得等着数据搬过来,算力根本发挥不出来。
而长缨芯片,直接把这个墙拆了:它既有缓存一样的超快速度,又能像硬盘一样,断电了数据也不丢。 这意味着什么? 以后我们的普通手机,本地就能全速跑复杂的大模型,不用再把数据传到云端;数据中心也不用搞那么复杂的多层存储架构了,能效直接拉满。
更厉害的是,他们还搞定了最难的工程化问题:把只有原子级厚度的二维材料,完美无损伤地贴到硅芯片上,良率做到了 94.3%,这意味着这个技术离量产已经不远了!
2. OpenAI 自研 GPT-NPU:能效比 H100 翻 3 倍,重构算力架构
另一边,OpenAI 也发布了自己的首款自研 AI 芯片 GPT-NPU,直接把大模型的算力效率拉到了新高度。
这个芯片用了台积电 2nm 的制程,针对大模型做了专门的优化,能效比是英伟达 H100 的 3 倍! 处理 100B 参数的大模型,时延只有 50ms,显存带宽的需求直接降了 60%,相当于用更少的资源,就能跑更快的模型。
而且他们还把这个芯片用到了车载 AI 里,以后自动驾驶的模型更新,从过去的小时级,直接缩短到了分钟级,车的智能系统,随时都能更新到最新版本。
写在最后:AI 的进化,比我们想的更快
其实你看,这几个突破,已经不是小修小补的版本迭代了:
大模型从 “被动聊天的工具”,变成了能独立干活、持续工作的 “职场员工”;
算力硬件从 “堆参数堆算力” 的内卷,变成了底层架构的颠覆,直接打破了几十年的技术瓶颈。
AI 的进化速度,真的比我们所有人想象的都要快。
以后的每一天,我们都会在这里,帮你把这些最新的变化,整理成你能看懂的内容,让你不会错过这个时代的每一个关键节点。
如果你不想错过,记得关注我们,星标这个公众号,这样每天的更新,你就能第一时间收到啦。
我们明天见~
