 夜雨聆风
夜雨聆风一、引言:从AlphaGo到大型语言模型的轨迹对比
1.1 为什么自我对弈在游戏领域如此成功
在人工智能发展的历史长河中,自我对弈(Self-Play)技术堪称最令人惊叹的突破之一。这项技术让AI系统能够在没有任何人类专家指导的情况下,通过与自己对战来不断提升水平,最终达到甚至超越人类顶尖水平。Noam Brown在讲座开篇就指出了一个引人深思的现象:自我对弈技术在围棋、象棋、扑克等游戏领域取得了巨大成功,但在大型语言模型(LLM)领域,我们至今尚未看到类似的突破性进展。
这一现象引发了Noam Brown的深入思考:为什么在LLM中难以实现类似AlphaGo那样的自我提升?这个问题触及了当前AI研究的核心挑战,也是本次讲座要回答的核心问题。
 图1:讲座封面——Multi-Agent AI,这一主题探讨的是AI系统在多智能体环境下的学习、协作与竞争策略
图1:讲座封面——Multi-Agent AI,这一主题探讨的是AI系统在多智能体环境下的学习、协作与竞争策略
 图2:自我对弈的核心主题——AI通过与自身副本对战不断进化,这是AlphaGo等系统成功的关键
图2:自我对弈的核心主题——AI通过与自身副本对战不断进化,这是AlphaGo等系统成功的关键
回顾近年来AI在游戏领域取得的关键突破,我们可以清晰地看到自我对弈技术的威力:
围棋领域——AlphaGo系列是自我对弈技术的经典代表。2016年,AlphaGo击败了世界冠军李世石;2017年,更强大的AlphaGo Zero完全通过自我对弈从零开始训练,最终以100:0击败了之前版本的AlphaGo。这一成就震惊了整个AI界,因为AlphaGo Zero没有使用任何人类棋谱,仅通过自我对弈就达到了前所未有的高度。
即时战略游戏领域——DeepMind的AlphaStar在《星际争霸II》中达到了大师级水平,同样采用了大规模自我对弈作为核心训练方法。OpenAI的OpenAI Five在《DOTA2》中击败了世界冠军队伍,也依赖于团队成员之间的相互对战训练。
扑克领域——Noam Brown本人开发的Libratus在2017年击败了四位世界顶级扑克选手,Pluribus在2019年成为首个在六人无限注德州扑克中击败人类专家的AI系统。这些成就同样建立在巧妙的自我对弈算法之上。
然而,当我们把目光转向大型语言模型领域时,情况却大不相同。尽管LLM在近年来取得了飞速发展,从GPT-3到GPT-4再到如今的各类先进模型,这些进步主要来自于更大规模的数据训练、更大的模型参数和更精细的人类反馈强化学习(RLHF),而不是自我对弈带来的质变。这究竟是为什么呢?
 图3:AlphaGo类比——LLM的发展轨迹与AlphaGo惊人地相似,两者都遵循着三个相似的发展阶段
图3:AlphaGo类比——LLM的发展轨迹与AlphaGo惊人地相似,两者都遵循着三个相似的发展阶段
1.2 LLM与AlphaGo的惊人相似轨迹
Noam Brown在讲座中提出了一个深刻的洞察:LLM的发展轨迹与AlphaGo的发展轨迹呈现出惊人的相似性。两者都遵循着三个相似的发展阶段,理解这一对应关系对于把握AI发展的内在规律至关重要。
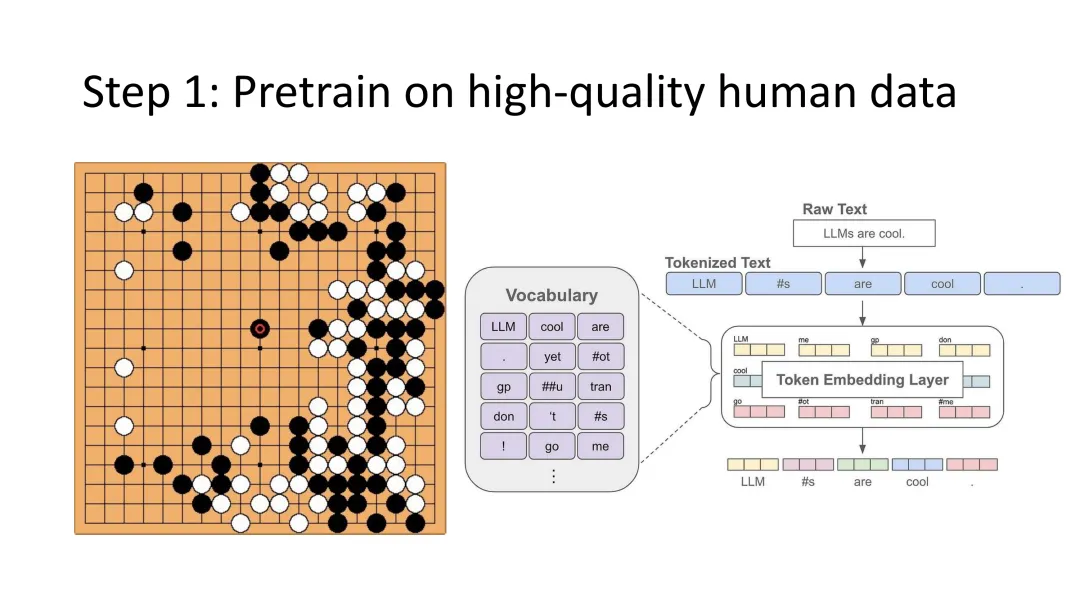 图4:第一步——高质量人类数据的预训练,这是AlphaGo和LLM共同的基础阶段
图4:第一步——高质量人类数据的预训练,这是AlphaGo和LLM共同的基础阶段
第一阶段:高质量人类数据的预训练
在AlphaGo的发展历程中,第一步是在大量人类围棋对局数据上进行监督学习。DeepMind团队收集了约3000万步来自人类职业棋手的走棋记录,让神经网络学习人类的下棋策略和模式。这种预训练为AlphaGo提供了基础的棋力,使其能够在没有自我对弈的情况下达到业余高手的水平。
在LLM领域,这一阶段对应的是在互联网海量文本数据上的预训练。通过“下一个token预测”任务,模型学会了语言的基本规律、语法结构、语义关系乃至世界知识。GPT系列、Claude、Llama等模型都经历了这一阶段,获得了处理各种语言任务的基础能力。
两种系统的共同点是:预训练阶段提供了坚实的基座能力,但仅仅是开始,远未达到最优。
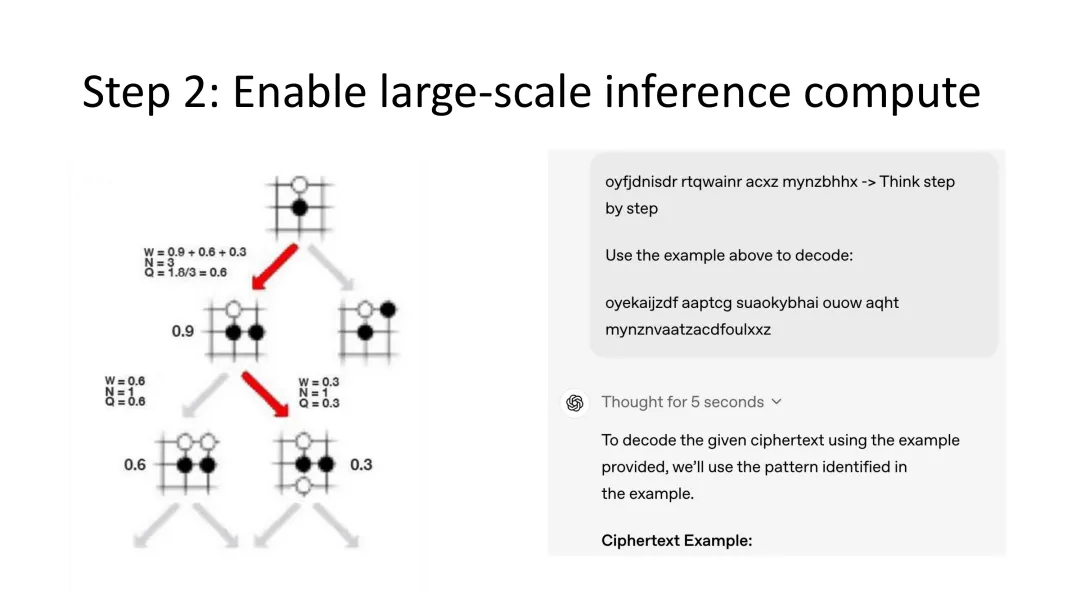 图5:第二步——大规模推理计算启用,这一阶段显著提升了两类系统的推理能力
图5:第二步——大规模推理计算启用,这一阶段显著提升了两类系统的推理能力
第二阶段:启用大规模推理计算
在AlphaGo中,第二步是引入蒙特卡洛树搜索(MCTS)作为推理引擎。MCTS允许AlphaGo在做出决策前进行前瞻搜索,通过模拟大量可能的走棋序列来评估每个决策的长期价值。这种“看得更远”的能力使AlphaGo能够发现人类棋手从未想到的创新走法。
在LLM领域,这一阶段对应的是Chain-of-Thought(思维链)推理技术的兴起。2022年以来,研究者发现当LLM被要求“先思考再回答”时,它们能够处理更复杂的推理任务。从最初的Few-shot CoT到如今的o1、o3等推理模型,LLM在测试时进行更深度计算的能力正在不断增强。
这一步骤显著提升了两类系统的推理能力,但仍然不是终点。真正的突破——也是两类系统目前差距最大的地方——在于第三步。
 图6:第三步——递归自我改进,AlphaGo通过自我对弈实现了质的飞跃,但LLM目前还缺乏这一环节
图6:第三步——递归自我改进,AlphaGo通过自我对弈实现了质的飞跃,但LLM目前还缺乏这一环节
第三步:递归自我改进(自我对弈)
在AlphaGo中,最关键的一步是引入自我对弈。AlphaGo Zero完全放弃了人类棋谱,仅通过自我对弈就达到了超越所有先前版本的水平。在数百万甚至数十亿局的对战中,AI不断发现新的策略、纠正旧的错误,最终超越了一切人类知识。
然而,在LLM中,我们目前还没有这个环节!这正是LLM与AlphaGo之间最大的差距所在。
这引出了一个核心问题:为什么在LLM中难以实现自我对弈? Noam Brown指出,很多人对自我对弈的直觉实际上过度拟合到了双人零和完美信息游戏(如围棋、国际象棋),当跳出这些特定游戏类型时,自我对弈的很多优良性质就会消失,难度也会大幅增加。
二、博弈论基础:理解“更好的玩家”
2.1 谁是更好的扑克玩家:一个深刻的问题
为了深入理解自我对弈的复杂性,Noam Brown从扑克游戏中的一个基本问题出发:谁是更好的扑克玩家?这个问题看似简单,却触及了博弈论的核心概念。
 图7:谁是更好的扑克玩家?——这个问题引出了两种不同定义的对比
图7:谁是更好的扑克玩家?——这个问题引出了两种不同定义的对比
Noam Brown向观众提出了两种可能的定义:
选项一:极小极大均衡(Minimax Equilibrium)
这是指在足够大的样本量下,能够击败任何其他玩家的选手。如果这个人与任何其他活着的人玩无数局扑克,从长远来看他们都会获胜。这是一种“无敌”的定义——无论对手是谁,长期来看都能保持优势。
选项二:基于人群的最佳应对(Population Best Response)
这是指在一定时期内,通过打牌赚取最多钱的选手。这种定义关注的是如何最大化利用对手的弱点——即使面对的是弱手,也能从中获取最大收益。
 图8:极小极大均衡与基于人群最佳应对的对比——在扑克中,这两种“最好”并不一定是同一个人
图8:极小极大均衡与基于人群最佳应对的对比——在扑克中,这两种“最好”并不一定是同一个人
关键洞察:在扑克这样的游戏中,这两种“最好”并不一定是同一个人。
想象一个极端的例子:一位职业扑克选手A,他非常擅长在对手犯错时加以利用,但面对另一位顶级选手B时只能勉强维持平衡。这位选手A符合“极小极大均衡”的定义——他能击败大多数人,但无法击败最强的对手。
另一方面,一位选手B可能技术平平,但极其擅长寻找并利用弱手的漏洞。他可能无法击败顶级选手A,但在与众多业余玩家的比赛中赚得盆满钵满。这位选手B符合“基于人群最佳应对”的定义。
这个差异在围棋或象棋中几乎不存在——如果某人能在长期对局中击败所有人,那他就是无可争议的世界第一。但在扑克这样的不完全信息游戏中,情况就复杂得多。
这一洞察对于理解自我对弈在LLM中的挑战至关重要:我们追求的究竟是哪一种“最优”?
2.2 极小极大均衡:双人零和博弈的核心概念
为了更深入地理解第一种定义,Noam Brown详细介绍了极小极大均衡这一博弈论核心概念。
 图9:极小极大均衡的定义——一组没有玩家能通过改变策略来提升收益的策略组合
图9:极小极大均衡的定义——一组没有玩家能通过改变策略来提升收益的策略组合
极小极大均衡的定义
Minimax Equilibrium(极小极大均衡)是一组策略,在这些策略下,没有任何玩家能够通过改变自己的策略来获得更好的收益。换句话说,每个玩家都已经找到了对当前环境的最佳应对,任何单方面的策略调整都不会带来更好的结果。
在双人零和游戏中,极小极大均衡具有一个非常重要的特性:遵循极小极大均衡策略保证你不会在期望值上输掉。无论对手采用什么策略,只要你坚持均衡策略,从长远来看你的收益不会为负。当然,如果对手犯错,你就能从中获利;如果对手采取最佳应对,你们会打成平手。
可利用性(Exploitability)
为了量化一个策略与均衡的差距,博弈论引入了“可利用性”的概念。
如果我们的策略恰好处于均衡状态,可利用性为0。偏离均衡越远,可利用性就越高,损失就越大。
 图10:石头剪刀布的直观理解——总是出石头会被对手的布完美克制
图10:石头剪刀布的直观理解——总是出石头会被对手的布完美克制
石头剪刀布的直观理解
让我们通过石头剪刀布来直观理解这些概念。
如果我们总是出“石头”: - 对手的最佳应对是总是出“布” - 每回合我们都会输 → 可利用性 = 1(最大程度的可被利用)
即使我们采用更复杂的策略,比如“前两轮出石头,第三轮根据对手之前的选择来调整”,对手只要知道我们的策略模式,仍能完美应对我们。可利用性仍然很高。
为什么对手能“看穿”我们的策略?
这就涉及到均衡理论中的一个关键假设:我们的策略是共同知识(Common Knowledge)——对手不仅知道我们现在用什么策略,还知道我们为什么会用这个策略、这个策略的概率分布是什么。
但随机过程的结果(如随机种子)不是共同知识。这意味着对手知道我们“30%出石头、40%出布、30%出剪刀”这样的概率分布,但无法预测我们具体哪一次会出什么。
 图11:关键假设——策略是共同知识,但随机结果不是
图11:关键假设——策略是共同知识,但随机结果不是
为什么要做这个假设?
Noam Brown解释道,如果我们要创建一个面向数十亿用户的AI系统,系统中如果存在弱点,最终人们会发现并利用它们。因此,极小极大均衡背后的思想是:假设对手完全了解我们的策略,测试我们能否在这种最坏情况下仍然保持鲁棒。
当然,这是一个很强的假设,我们完全可以质疑它。但在讨论理论问题时,这个假设提供了一个清晰的基准。
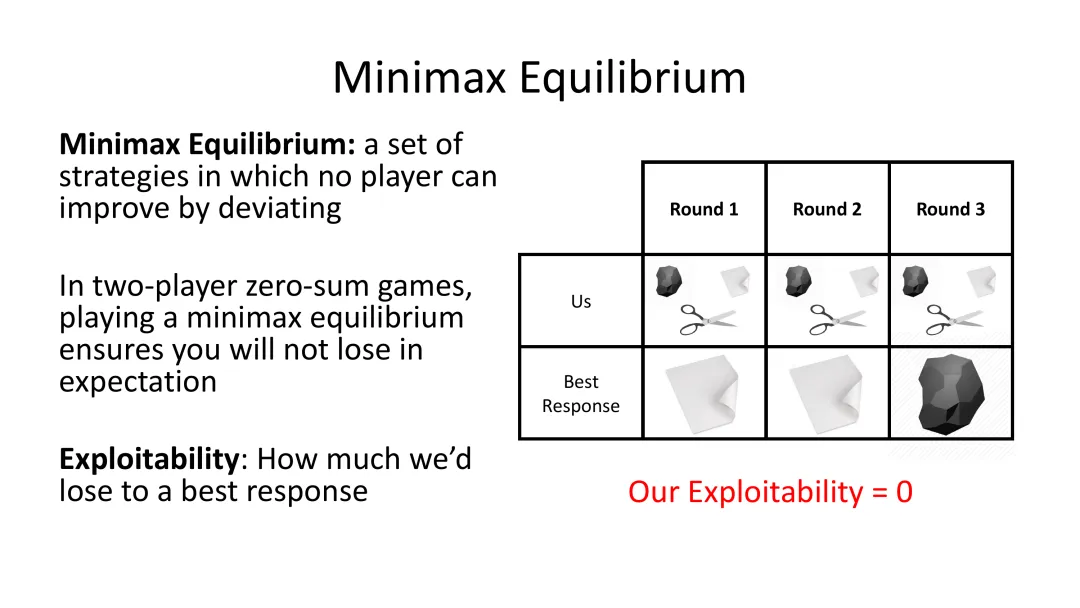 图12:石头剪刀布的均衡解——以相等概率随机选择三种手势,可利用性为零
图12:石头剪刀布的均衡解——以相等概率随机选择三种手势,可利用性为零
石头剪刀布的均衡解
在石头剪刀布游戏中,均衡策略非常简单:以相等的概率(各1/3)随机选择石头、布、剪刀。
•对手无法预测我们的具体行动
•无论对手采取什么策略,最佳应对也只能与我们打成平手
•可利用性 = 0
这就是极小极大均衡的核心思想:通过随机化来对抗对手的知识优势。
2.3 扑克策略的复杂性:为什么不同于石头剪刀布
与石头剪刀布这样的简单博弈不同,扑克等复杂游戏中的均衡策略要复杂得多。
 图13:扑克策略的复杂性——在均衡状态下,有些动作根本不应该被执行
图13:扑克策略的复杂性——在均衡状态下,有些动作根本不应该被执行
均衡策略的关键特征
在扑克游戏中,即使我们处于均衡状态,仍然存在一些重要特性:
第一,某些动作根本不应该被采用。在均衡状态下,有些动作的期望值为负——即使对手知道我们要用这个策略,执行它仍然会让我们损失。这意味着均衡策略不仅仅是选择概率,更关键的是知道不选择什么。
第二,对手会犯错。在实践中,没有人会完美地执行最佳应对策略。这正是你能从均衡策略中获利的来源——你不需要打败“完美对手”,你只需要在对手犯错时能够利用这些错误。
正如扑克策略指南所说:“扑克很简单——随着对手犯错,你就会获利。”
这一洞察引出了一个重要问题:我们如何让AI学会这种复杂的策略?答案就在于自我对弈。
三、双人零和游戏中的自我对弈
3.1 自我对弈的神奇特性
自我对弈技术有一个令人惊叹的特性,这也是其在游戏AI中取得成功的根本原因。
 图14:双人零和游戏中的自我对弈——任何有限的双人零和游戏都可以通过自我对弈来解决
图14:双人零和游戏中的自我对弈——任何有限的双人零和游戏都可以通过自我对弈来解决
核心定理
任何有限的双人零和游戏都可以通过自我对弈来解决,不需要任何人类数据!
这是一个非常强的结论。只要有足够的内存和计算能力,自我对弈算法可以: - 收敛到极小极大均衡 - 保证不会对任何对手(人类或其他AI)在期望值上输掉
Noam Brown强调:“我们把这当作理所当然,但我们能得到这个其实挺幸运的。”在双人零和博弈中,恰好存在这样的优良性质,使得自我对弈能够可靠地工作。
 图15:完美信息游戏中的自我对弈本质上就是独立的单智能体强化学习
图15:完美信息游戏中的自我对弈本质上就是独立的单智能体强化学习
完美信息游戏中的自我对弈
在完美信息游戏(如国际象棋、围棋)中,自我对弈本质上就是独立的单智能体强化学习。使用PPO等标准RL算法,只要进行充分的探索,理论上就能收敛到极小极大均衡。
以经典的Pong游戏为例:这是雅达利2600上的一款乒乓球游戏,也是强化学习的“Hello World”。AI通过与自己对战,学会了这个游戏,并达到了超越人类的水平。这个过程不需要任何人类玩家的数据——AI完全从零开始,通过反复试验学会了如何打球。
3.2 完美信息游戏的局限性:对抗性攻击
然而,即使是在理论上“已解决”的完美信息游戏中,也存在一个重要的局限性。
 图16:神经网络在近似极小极大均衡时可能存在漏洞,对抗性攻击是一个严峻挑战
图16:神经网络在近似极小极大均衡时可能存在漏洞,对抗性攻击是一个严峻挑战
关键问题
神经网络是有限的,它们在复杂博弈中可能无法完美近似极小极大均衡。更重要的是,发现漏洞比防御漏洞要容易得多。
这意味着什么?即使我们的AI在99%的对局中都能击败人类,只要对手找到那1%的漏洞并反复利用,AI就会遭受灾难性的失败。
 图17:2023年的研究发现,即使是最强的围棋AI也容易受到人类可发现的对抗性策略影响
图17:2023年的研究发现,即使是最强的围棋AI也容易受到人类可发现的对抗性策略影响
2023年的重要发现
2023年,Wang等人发表了一篇论文,揭示了一个令人震惊的事实:即使在围棋这样的完美信息游戏中,人类也能发现击败顶级AI的对抗性策略。
这项研究证明: - 顶级围棋AI虽然远超人类水平 - 但仍存在人类可以发现的对抗性策略 - 这暴露了自我对弈方法的局限性
这是一个重要的警示:在实际部署中,我们不能仅仅依赖“理论上收敛到均衡”来保证安全。理论与实践之间存在巨大鸿沟。
3.3 PPO在石头剪刀布中的失败:不完全信息的挑战
为了说明不完全信息游戏比完美信息游戏困难得多,Noam Brown展示了一个令人惊讶的实验结果。
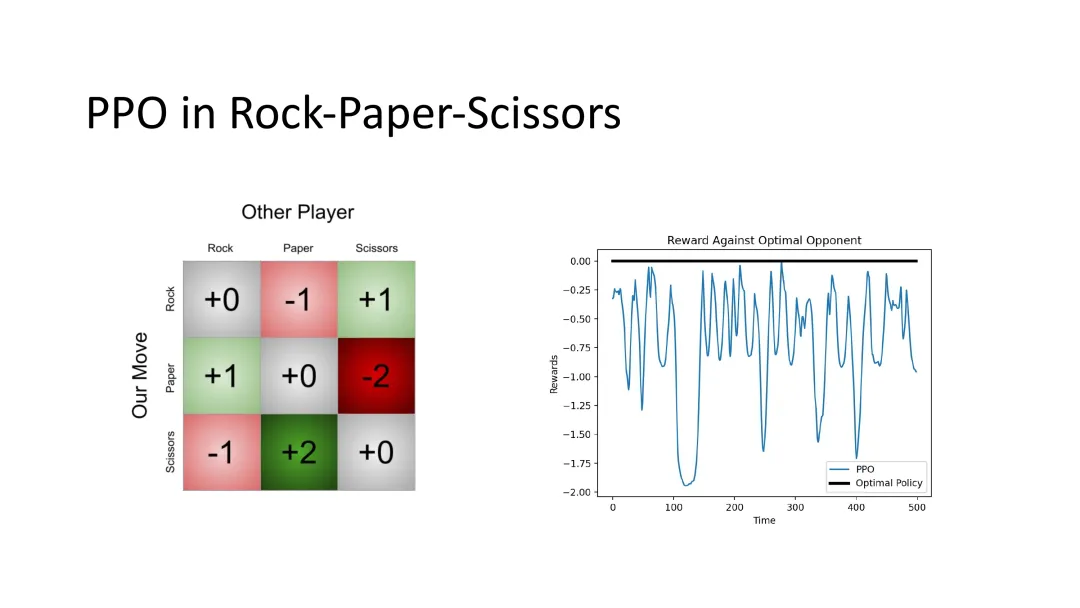 图18:令人惊讶的发现——标准的PPO算法在石头剪刀布游戏中无法收敛到均衡
图18:令人惊讶的发现——标准的PPO算法在石头剪刀布游戏中无法收敛到均衡
PPO的失败
标准的PPO(Proximal Policy Optimization)算法在石头剪刀布游戏中无法收敛到均衡!这是一个非常重要的发现,因为它说明即使是简单的博弈,标准RL算法也可能失效。
为什么会失败?
原因在于:石头剪刀布要求玩家在三种动作之间维持精确的平衡概率(各1/3)。PPO算法中没有任何机制来强制维持这种平衡——它可能会收敛到任何概率分布,只要这个分布在某种意义上“不差”就行。
例如,PPO可能收敛到“60%出石头、30%出布、10%出剪刀”这样的分布——这虽然不会太差,但离真正的均衡还差得很远。这预示着不完全信息游戏比完美信息游戏要困难得多。
四、不完全信息游戏的本质困难
4.1 核心原因:动作的价值取决于其执行的概率
不完全信息游戏为什么如此困难?Noam Brown通过一个精心设计的例子揭示了根本原因。
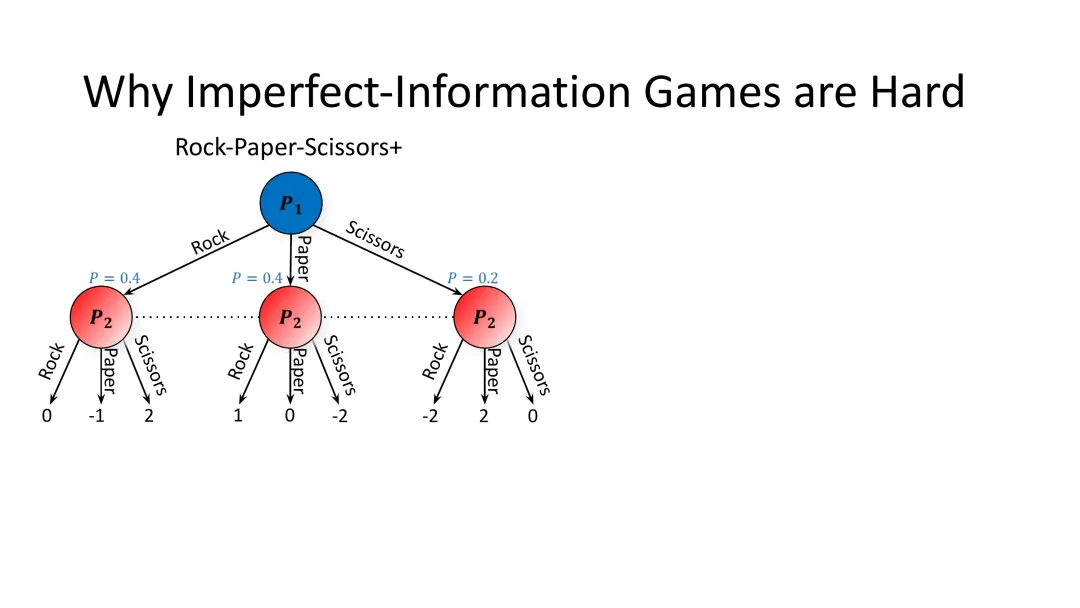 图19:核心原因——在不完全信息游戏中,动作的价值取决于其被执行的概率
图19:核心原因——在不完全信息游戏中,动作的价值取决于其被执行的概率
完美信息游戏中的情况
在国际象棋这样的完美信息游戏中,动作的价值不依赖于你执行它的频率。无论你10%还是90%的时间使用西西里防御,期望值基本不变。因为你的对手每次都能看到你走什么,然后做出最佳应对。动作的价值只取决于“哪个动作更好”,而不是“你有多经常用它”。
不完全信息游戏中的情况
在扑克这样的不完全信息游戏中,情况截然不同。动作的价值高度依赖于你执行它的概率。
想象你在玩扑克时想要虚张声势(bluff): - 如果你总是虚张声势,对手会注意到并更频繁地跟注 - 虚张声势的价值就会下降 - 但如果你从不振臂,对手就知道你没有强牌,从不跟注 - 虚张声势的价值也会归零
这意味着你需要找到一个微妙的平衡点:虚张声势的频率必须精心调校,既不能多到被利用,也不能少到失去价值。
核心洞察:在不完全信息游戏中,算法不仅需要决定采取什么动作,还需要找出以什么概率采取每个动作。这是一个本质性的困难。
4.2 石头剪刀布Plus:打破对称性的演示
为了更直观地展示不完全信息游戏的复杂性,Noam Brown引入了“石头剪刀布Plus”这个修改版游戏。
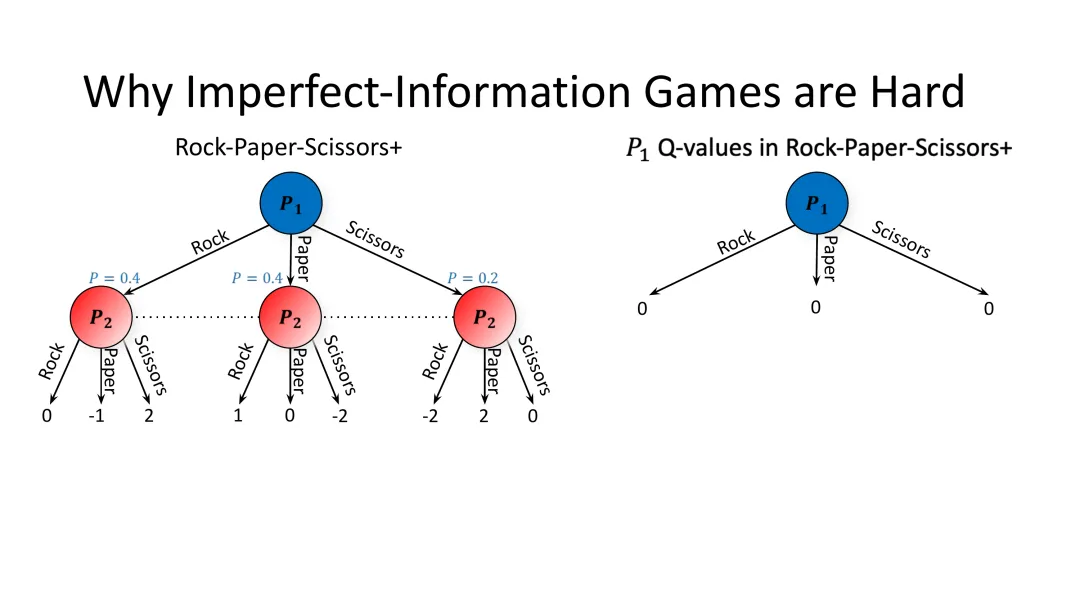 图20:石头剪刀布Plus——一个修改版的石头剪刀布,用于展示不完全信息博弈的复杂性
图20:石头剪刀布Plus——一个修改版的石头剪刀布,用于展示不完全信息博弈的复杂性
游戏规则
石头剪刀布Plus的关键修改是: 1. 玩家1先行动 2. 玩家2在不知道玩家1做了什么的情况下行动 3. 收益矩阵经过调整以打破对称性
在这种设置下,如果玩家1选择石头并获胜,他得到+2分;如果选择布并获胜,得到+1分;如果选择剪刀并获胜,得到-1分。这种不对称的收益打破了游戏的原始对称性。
均衡策略
修改后的均衡策略是: - 石头:40%概率 - 布:40%概率
- 剪刀:20%概率
偏离均衡的影响
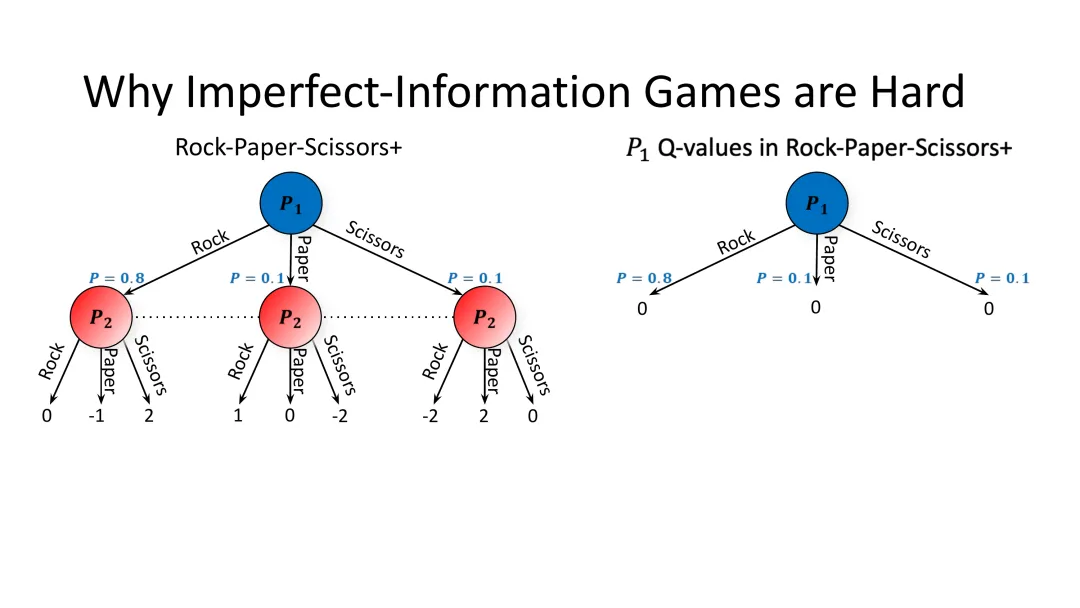 图21:偏离均衡的策略分布——如果玩家1采用80%出石头、10%出布、10%出剪刀的策略,博弈树结构发生变化
图21:偏离均衡的策略分布——如果玩家1采用80%出石头、10%出布、10%出剪刀的策略,博弈树结构发生变化
如果玩家1偏离均衡(80%出石头、10%出布、10%出剪刀),右侧的Q值图展示了这种情况下各动作的价值变化。
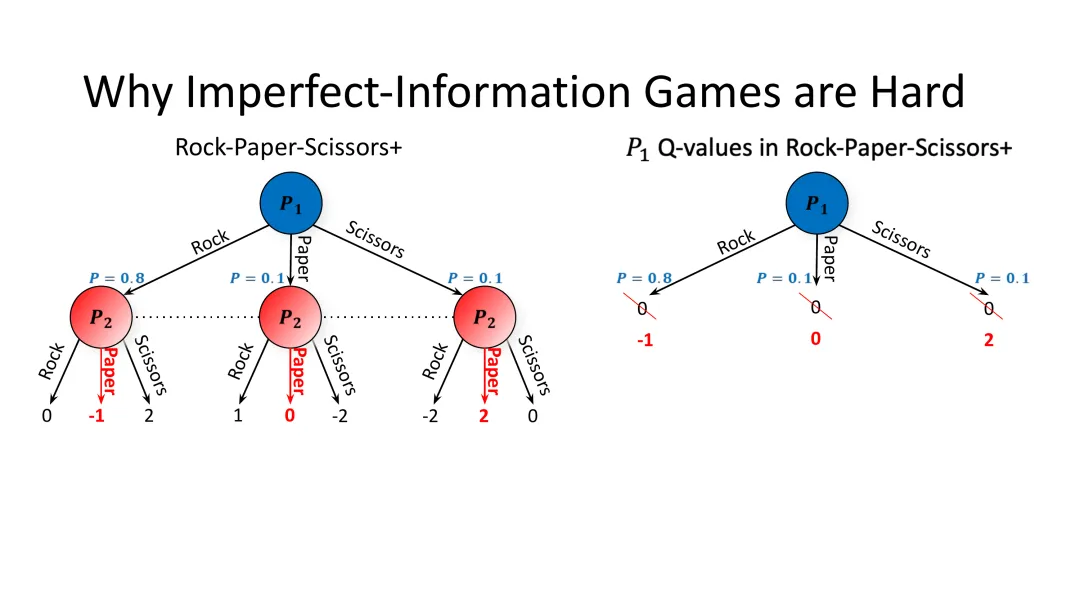 图22:Q值的关键变化——出石头的价值从均衡时的0变为-1,说明偏离均衡会导致确定性损失
图22:Q值的关键变化——出石头的价值从均衡时的0变为-1,说明偏离均衡会导致确定性损失
关键洞察
如果玩家1偏离均衡(例如80%出石头),玩家2会察觉到这一点并调整策略(更多出布)。结果,玩家1出石头的价值会从0变为负数。
这揭示了不完全信息博弈的深层困难:前瞻搜索不再有效。在完美信息游戏中,我们可以假设对手会“玩均衡”,然后基于这个假设做最优决策。但在不完全信息游戏中,如果玩家1偏离均衡,玩家的行为就不再是均衡的——我们的假设就失效了。
4.3 收敛算法:从虚构游戏到现代方法
既然PPO等标准RL算法无法可靠地收敛到不完全信息游戏的均衡,研究者们开发了专门的算法来解决这个问题。
 图23:虚构游戏——最简单但收敛速度很慢的均衡求解算法
图23:虚构游戏——最简单但收敛速度很慢的均衡求解算法
虚构游戏(Fictitious Play)
虚构游戏是最经典的均衡求解算法,其步骤如下:
1.任意初始化所有玩家的策略
2.每次迭代中,每位玩家对对手在所有之前迭代中的平均策略执行最佳应对
3.所有玩家的平均策略收敛到极小极大均衡
以石头剪刀布为例,假设我们从“总是出石头”开始: - 第2次迭代:对手会出“布”(最佳应对)→ 平均策略变为50%石头,50%布 - 第3次迭代:对手仍会出“布” → 平均策略变为33%石头,67%布 - 第4次迭代:对手会出“剪刀” → 平均策略变为25%石头,50%布,25%剪刀 - ……逐渐收敛到33%/33%/33%
虚构游戏虽然理论上保证收敛,但速度非常非常慢,在实际应用中几乎不可行。
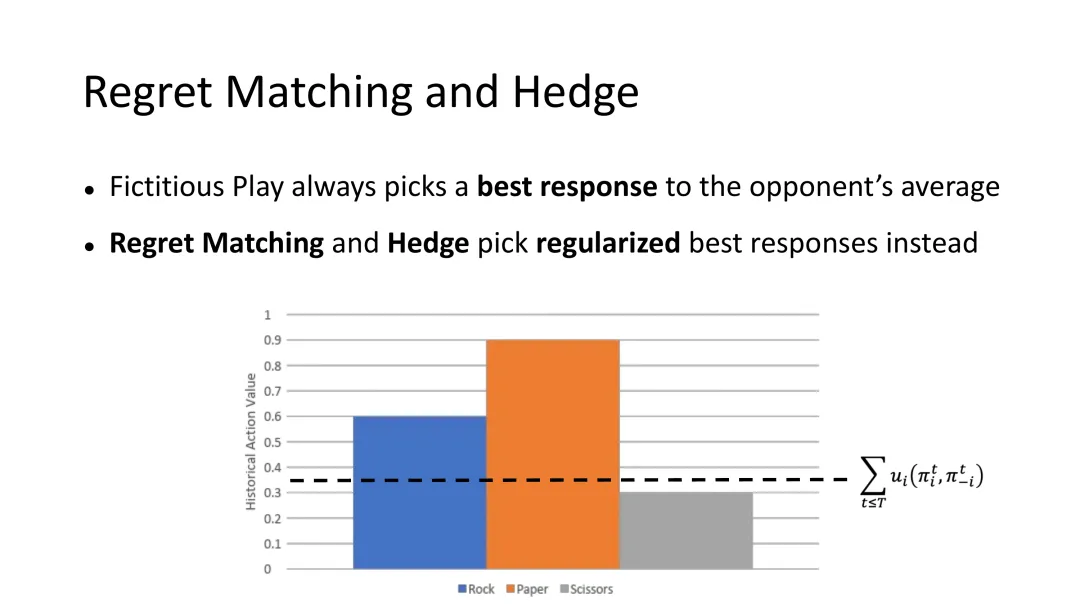 图24:遗憾匹配与Hedge算法——通过正则化最佳应对来加速收敛
图24:遗憾匹配与Hedge算法——通过正则化最佳应对来加速收敛
遗憾匹配与Hedge算法
为了加速收敛,研究者开发了更先进的算法:遗憾匹配(Regret Matching)和Hedge算法。
这些算法的核心思想是:不总是选择精确的最佳应对,而是根据历史遗憾选择接近最佳应对的策略。通过额外的“正则化”机制来保持策略的平衡。
具体来说,每次迭代中算法会: 1. 计算每个动作相对于当前策略的“遗憾值”——如果过去选择了这个动作,会多获得多少收益? 2. 根据遗憾值决定下次选择每个动作的概率 3. 遗憾越大的动作,被选中的概率越高
这种方法的收敛速度比虚构游戏快得多,是扑克AI成功的关键。
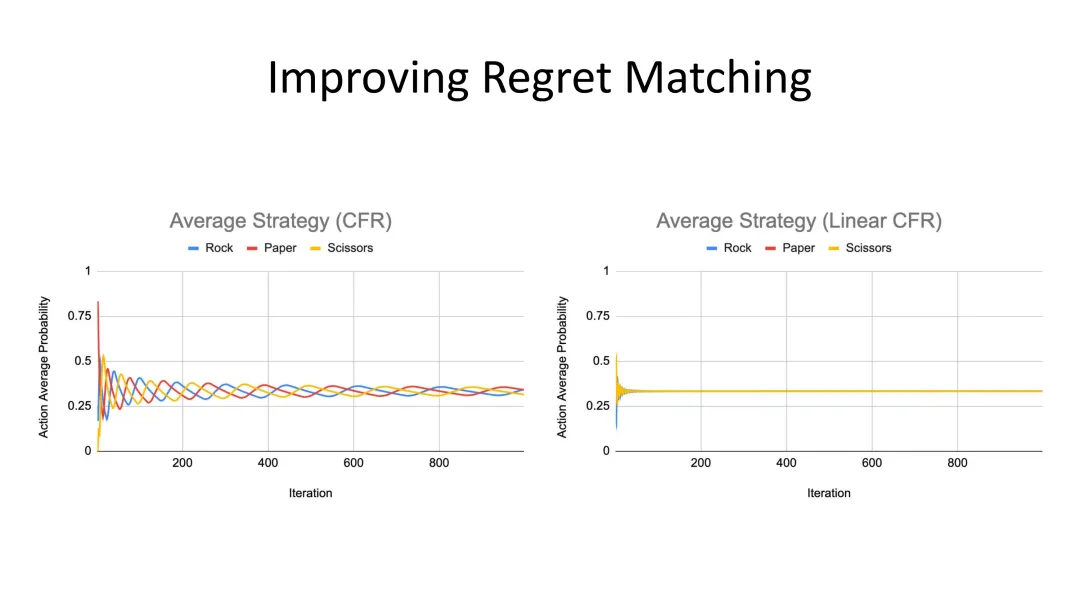 图25:线性CFR——显著加速收敛的改进算法
图25:线性CFR——显著加速收敛的改进算法
Linear CFR:更快的收敛
线性CFR(Counterfactual Regret Minimization)是CFR算法的一个重要改进。实验表明: - 标准CFR需要800+次迭代才能收敛 - Linear CFR几乎立即收敛
这种数量级的提升对于复杂游戏(如扑克)的求解至关重要。没有Linear CFR,Libratus这样的系统可能需要运行数年才能达到可接受的水平。
五、扑克AI:Libratus的历史性突破
5.1 2017 Brains vs AI比赛
Noam Brown在博士期间开发的Libratus是扑克AI领域的一个里程碑。
 图26:Libratus与人类选手的历史性对决——这是AI在不完全信息游戏中首次战胜人类顶级选手
图26:Libratus与人类选手的历史性对决——这是AI在不完全信息游戏中首次战胜人类顶级选手
比赛详情
•时间:2017年1月,持续20天
•对手:四位世界顶级无限注德州扑克职业选手
•牌局数:120,000手
•奖金:$200,000(按表现分配给职业选手)
惊人结果
•以99.98%的统计显著性获胜
•每位人类选手都单独输给了Libratus
这是AI在不完全信息游戏中首次战胜人类顶级选手,具有历史性意义。
 图27:Libratus成功的关键创新——完全基于自我对弈训练,不依赖任何人类数据
图27:Libratus成功的关键创新——完全基于自我对弈训练,不依赖任何人类数据
关键创新
Libratus的成功有三大关键创新:
1.不依赖神经网络——与后来的很多AI不同,Libratus使用的是传统的博弈论算法,而非深度学习
2.完全从自我对弈训练——没有任何人类玩家的数据,完全从零开始学习
3.使用遗憾匹配等博弈论算法——借鉴了前文讨论的先进均衡求解技术
这证明了在双人零和不完全信息游戏中,自我对弈可以产生超越人类的策略。
5.2 算法的演进:突破单智能体与多智能体的壁垒
尽管遗憾匹配等算法在扑克领域取得了巨大成功,但它们也存在明显的局限性。
 图28:虚构游戏、遗憾匹配和Hedge的共同局限性——在单智能体强化学习中表现不佳
图28:虚构游戏、遗憾匹配和Hedge的共同局限性——在单智能体强化学习中表现不佳
传统算法的局限性
这些传统算法有一个共同的弱点:在单智能体强化学习中表现不佳。
这是什么意思? - 第一次迭代总是随机的,策略改进速度很慢 - 这些算法无法利用单智能体RL中发展成熟的许多技术
这是一个长期存在的问题:有大量优秀的单智能体RL算法(如PPO、SAC等),但它们不适用于不完全信息游戏;而那些适用于不完全信息游戏的算法,又在单智能体设置中表现糟糕。
 图29:突破性的新算法——Regularized Nash Dynamics和Magnetic Mirror Descent
图29:突破性的新算法——Regularized Nash Dynamics和Magnetic Mirror Descent
突破性进展
最近几年,研究者终于找到了突破这一壁垒的方法:
•Regularized Nash Dynamics (R-NaD)[Perolat et al., Science-22]
•Magnetic Mirror Descent [Sokota et al., ICLR-23]
这些新算法的特点是: - 在单智能体RL中表现良好 - 在多智能体设置中快速收敛到均衡 - 代表了算法的未来方向
Noam Brown认为,这很可能就是未来统一单智能体和多智能体学习的关键突破。
六、超越双人零和游戏:关键转折点
6.1 为什么还没提到LLM:一个充分的理由
讲座进行到这里,Noam Brown突然提出了一个看似突兀的问题:为什么还没提到LLM?
 图30:廉价交谈——在双人零和极小极大均衡中,交流从来无用
图30:廉价交谈——在双人零和极小极大均衡中,交流从来无用
答案:因为你一直在双人零和游戏中
这有一个非常充分的理由:我们一直在讨论双人零和游戏。
在双人零和游戏中,如果你计算的是极小极大均衡,沟通从来都没用。这可以严格证明。
“廉价交谈”无用性的直觉证明
考虑双人零和博弈中的两个玩家。假设有一个玩家1可以“说点什么”来影响游戏结果(但说的内容本身对游戏规则没有直接影响,称为“廉价交谈”)。
此时有三种可能: 1. 交谈增加v₁:如果交谈能让玩家1获得更多收益,玩家2会直接忽略它(因为这会损害他们的收益) 2. 交谈减少v₁:如果交谈会让玩家1获得更少收益,玩家1根本不该说 3. 交谈无效果:唯一可能的结果
因此,在极小极大均衡中,交流从来没用。
这就是为什么在扑克等双人零和游戏中,我们看到的更多是“演戏”(如虚张声势)而不是真正的交流——因为你说什么对手都不会当真。
6.2 核心主张:人类数据是必不可少的
现在,Noam Brown终于转向了讲座的核心观点。
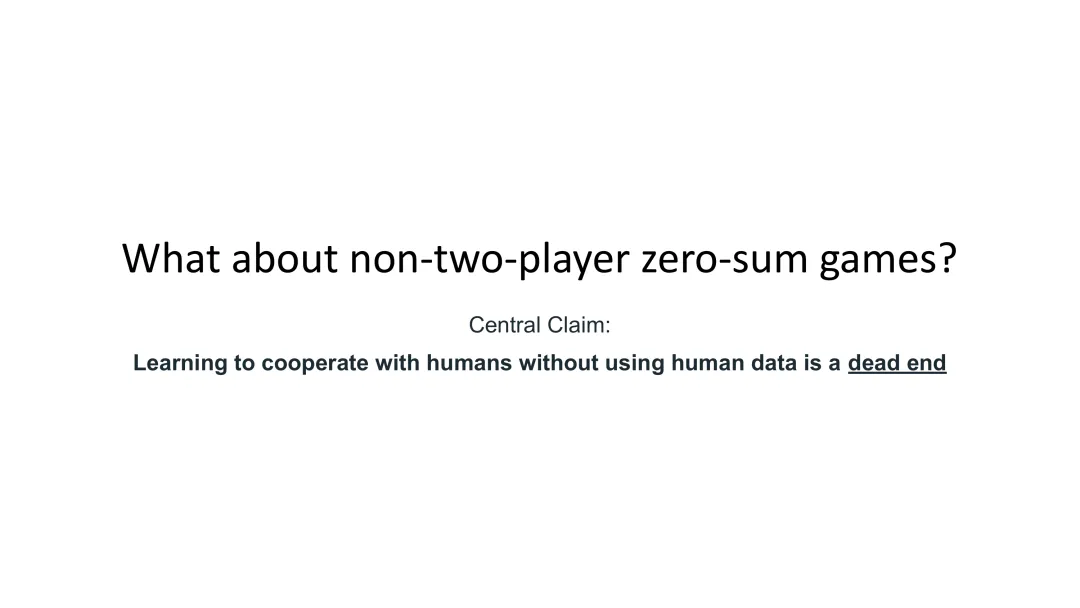 图31:核心主张——如果目标是学会与人类合作,避免使用人类数据是一条死胡同
图31:核心主张——如果目标是学会与人类合作,避免使用人类数据是一条死胡同
如果你的目标是学会与人类合作,那么避免使用人类数据是一条死胡同。
这是本次讲座中最重要的观点,Noam Brown强调了很多遍。在Noam Brown看来: - 在双人零和游戏中,自我对弈可以产生无敌策略,不需要人类数据 - 但在非双人零和游戏中,你最终需要人类数据
这不是一个技术问题,而是一个根本性的限制。
6.3 最后通牒游戏:一个令人信服的演示
为了证明这一观点,Noam Brown用最后通牒游戏进行了演示。
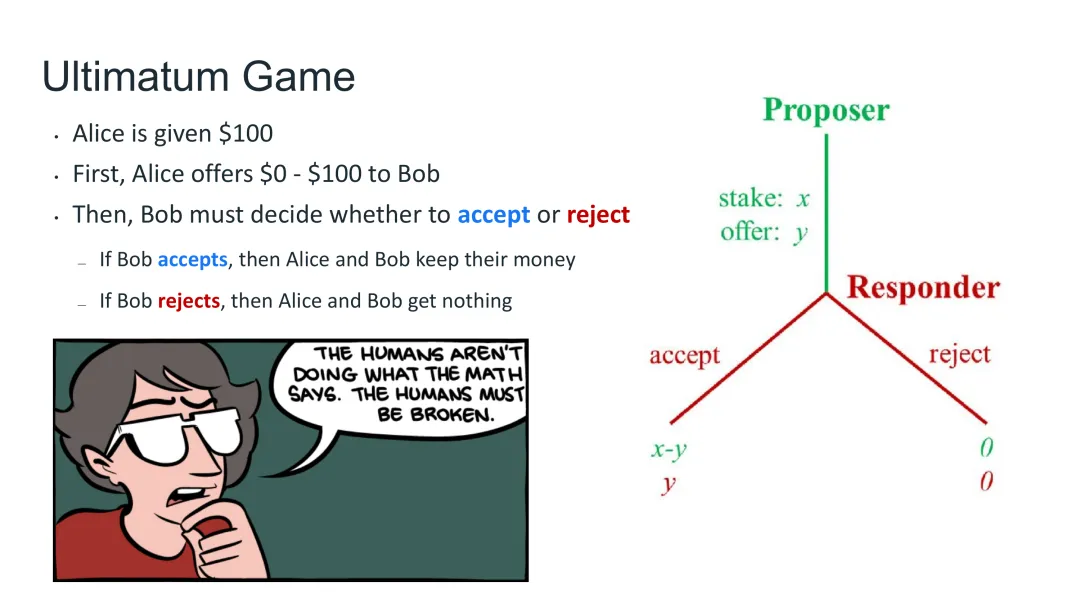 图32:最后通牒游戏——一个经典的经济学博弈,揭示了自我对弈与人类行为的巨大鸿沟
图32:最后通牒游戏——一个经典的经济学博弈,揭示了自我对弈与人类行为的巨大鸿沟
游戏规则
最后通牒游戏是一种经典的经济学博弈: 1. Alice获得$100 2. Alice向Bob提出分成方案(例如$30/$70) 3. Bob选择接受或拒绝 4. 如果Bob接受,按方案分配;如果Bob拒绝,两人都得$0
数学上的最优策略
从纯粹的博弈论角度来看: - Alice应该提供最小金额($1) - Bob应该接受(因为$1 > $0) - Alice最终获得$99
这是一个典型的“理性人”解决方案。
但现实呢?
Noam Brown在讲座现场做了一个调查: - 问观众愿意接受的最低金额 - 结果显示:大多数人期望获得20%-30% - 如果提供太少,会被拒绝
人类行为与数学预测的巨大差异
这反映了人性与文化差异: - 人类有公平感——$1/$99的分法被认为是不公平的 - 不同文化有不同的公平标准——有些文化甚至期望50/50平分 - 纯粹追求收益最大化的策略在实际中会失败
Noam Brown特别指出:最后通牒游戏实际上是非常文化依赖的。有些文化的人们很容易接受20%,但有些文化如果你的出价低于50/50就会拒绝。
自我对弈会学到什么?
如果用自我对弈RL来训练AI: - AI会学到Alice提供$1、Bob接受 - 这在数学上是“最优”的 - 但对于人类来说,这是一个糟糕的策略——很少有人会接受这么低的出价
核心问题
如果你的目标是与人类合作(而不是击败人类),自我对弈RL找到的策略与人类实际行为完全不同。这导致: - 在与人类对战时表现糟糕 - 无法理解人类的心理和期望 - 缺乏必要的“人情味”
七、外交游戏:从双人零和到多人博弈
7.1 外交游戏介绍:七人自然语言谈判游戏
接下来,Noam Brown用外交游戏作为案例研究,展示了在非双人零和游戏中如何处理人类合作问题。
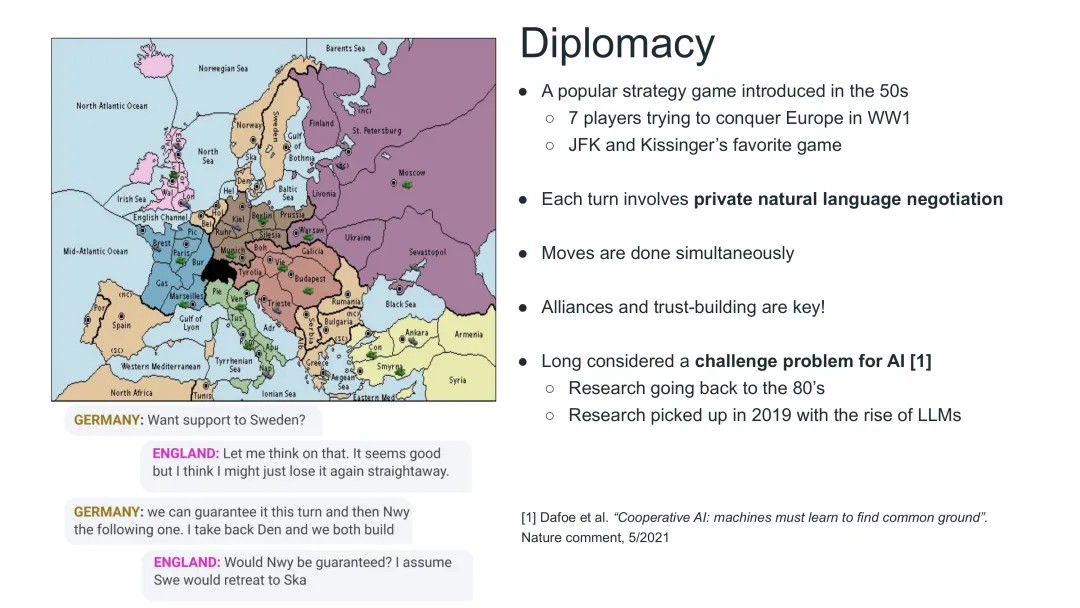 图33:外交游戏——1950年代推出的七人策略游戏,是JFK和基辛格的最爱
图33:外交游戏——1950年代推出的七人策略游戏,是JFK和基辛格的最爱
游戏背景
外交游戏(Diplomacy)是一款1950年代推出的经典策略游戏,至今仍被广泛使用。它的一些有趣背景: - JFK和基辛格的最爱 - 目标是控制欧洲地图的大部分区域 - 每回合包含私密的自然语言谈判 - 所有行动同时执行
AI挑战
外交游戏是一个极具挑战性的AI问题: - 7人游戏,复杂度远超双人博弈 - 核心在于自然语言谈判 - 联盟建立与信任是游戏的关键 - 充满了“背叛”——盟友可能说谎
这类问题的研究可追溯到1980年代,但2019年随着LLM的兴起才真正快速发展。
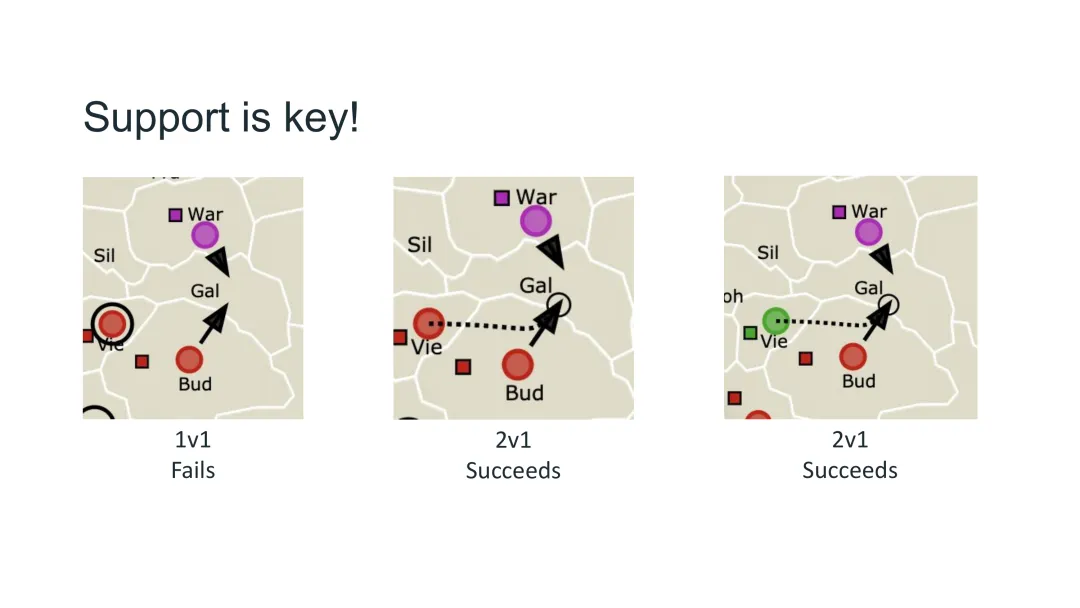 图34:支援是关键——外交游戏中可以借助其他玩家的单位来增强攻击力
图34:支援是关键——外交游戏中可以借助其他玩家的单位来增强攻击力
支援机制
外交游戏有一个独特的机制——支援(Support): - 一个玩家的单位可以支援另一个玩家的单位进入某区域 - 2对1的情况下,有支援的一方获胜 - 关键是支援可以来自其他玩家
这意味着外交游戏中存在真正的跨玩家协调。你可以与另一个玩家谈判:“你支援我进入这个区域,我下次帮你。”
这种需要协调和信任的机制,是外交游戏复杂性的核心来源。
7.2 DORA:无外交沟通外交游戏
Noam Brown首先介绍了团队早期的工作——DORA,这是一个通过纯自我对弈学习外交游戏的AI。
 图35:DORA——通过纯自我对弈从零学习外交游戏,类似于AlphaZero的方法
图35:DORA——通过纯自我对弈从零学习外交游戏,类似于AlphaZero的方法
DORA的核心方法
DORA [Bakhtin et al., NeurIPS 2021] 采用了与AlphaZero类似的方法: - 纯自我对弈从零学习外交游戏 - 不使用任何人类数据 - 完全通过与自己的副本对战来提升
表现
•2人无外交沟通模式:86.5%胜率 vs 人类专家
•7人模式:表现不佳
在双人模式下,DORA表现惊人——它学到的策略远超过人类专家水平。但当扩展到7人游戏并与使用人类数据训练的AI对战时,问题就出现了。
关键发现:自我对弈学到的是不同的“均衡”
这里有一个非常有趣的现象: - DORA学到的策略与使用人类数据训练的AI完全不同 - 当DORA与同类对战时,它是无敌的 - 但当DORA进入“人类风格”的AI群体时,它表现糟糕
这说明非双人零和游戏没有“最优”策略——一切都取决于你想与谁合作。
7.3 DORA vs SearchBot:一个发人深省的实验
Noam Brown详细介绍了DORA与SearchBot(一个基于人类数据训练的AI)的对战结果。
 图36:在非双人零和游戏中,极小极大均衡没有意义,不同训练方法产生不同的均衡
图36:在非双人零和游戏中,极小极大均衡没有意义,不同训练方法产生不同的均衡
实验设置
•SearchBot:使用大量人类外交游戏数据训练的AI
•DORA:纯自我对弈训练的AI
惊人结果
对战组合 | 胜者 | 胜率 |
1个DORA vs 6个SearchBot | DORA | 11% |
1个SearchBot vs 6个DORA | SearchBot | 1% |
这是一个发人深省的结果: - 当SearchBot进入DORA群体时,只赢了1%的游戏 - 当DORA进入SearchBot群体时,只赢了11%的游戏 - 两者都远低于“应该”获胜的比例(14%,因为是7人游戏)
深层含义
DORA和SearchBot各自学会了不同的均衡: - DORA学到了在“自恋者”世界中的最优策略 - SearchBot学到了在“人类”世界中的最优策略
但当两者相遇时,它们都无法适应对方——因为对方的行为超出了它们的“经验范围”。
这揭示了非双人零和游戏的根本问题:极小极大均衡不再有意义。在一个有很多不同玩家的世界中,“最优”取决于你的对手是谁。
 图37:极小极大均衡在一般游戏中没有意义,需要人类数据来理解人群的最佳应对
图37:极小极大均衡在一般游戏中没有意义,需要人类数据来理解人群的最佳应对
7.4 解决方案:把人类作为环境的一部分
那么,面对非双人零和游戏,我们应该怎么做?Noam Brown给出了明确的答案。
 图38:解决方案——将人类作为环境的一部分,通过三步走战略实现与人类的有效合作
图38:解决方案——将人类作为环境的一部分,通过三步走战略实现与人类的有效合作
三步走战略
1.收集大量人类数据,训练人类模仿模型
–理解人类实际上是如何行为的
–这是理解人类行为的基础
2.扩大推理时计算
–更好地模拟人类实际上会做什么
–不一定要超越人类,而是要准确建模人类
3.使用RL进行扩展
–将人类模仿模型作为环境的一部分
–在这个环境中进行自我对弈
关键洞察是:不是用RL取代人类数据,而是用人类数据来定义“成功”。我们仍然使用自我对弈来优化,但优化的目标不再是“击败一切”,而是“在人类世界中表现良好”。
八、成功案例:外交与Hanabi
8.1 Diplodocus:无外交沟通比赛冠军
基于上述方法,Noam Brown的团队开发了Diplodocus,在200局真人锦标赛中取得了第一名。
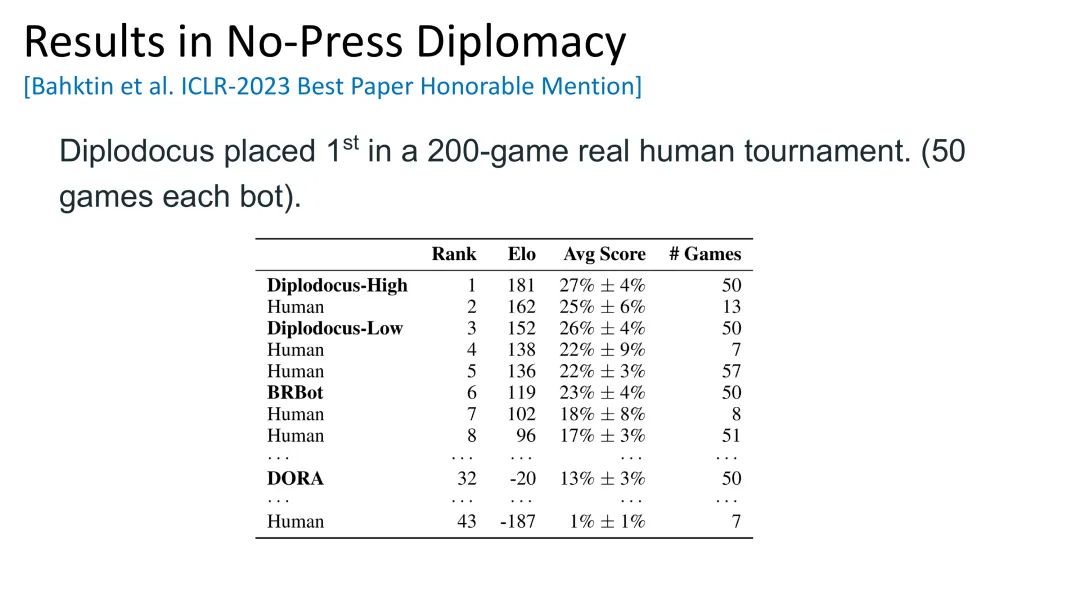 图39:Diplodocus在200局真人锦标赛中夺冠——纯自我对弈的DORA排名第32(接近垫底)
图39:Diplodocus在200局真人锦标赛中夺冠——纯自我对弈的DORA排名第32(接近垫底)
比赛结果
排名 | 选手/AI | Elo | 平均得分 |
1 | Diplodocus-High | 181 | 27% |
2 | Human | 162 | 25% |
3 | Diplodocus-Low | 152 | 26% |
… | … | … | … |
32 | DORA | -20 | 13% |
关键发现
•Diplodocus获得第一名,超过所有人奖人类选手
•纯自我对弈的DORA排名第32(接近垫底)
•人类数据的重要性得到了强有力的证明
这与之前的DORA vs SearchBot实验形成了鲜明对比:使用人类数据训练的SearchBot在与DORA对战时表现糟糕,但在与真人玩家对战时,Diplodocus却能脱颖而出。
8.2 CICERO:自然语言外交的突破
在无外交沟通版本取得成功后,Noam Brown的团队将方法扩展到了完整的自然语言外交游戏,开发了CICERO。
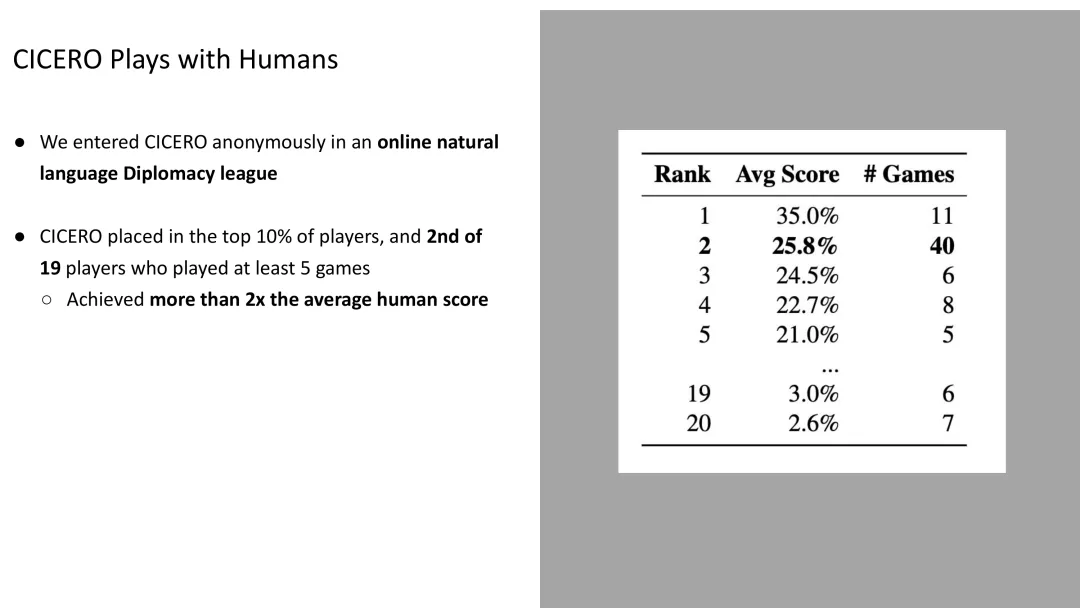 图40:CICERO——在完整的自然语言外交游戏中与真实人类对战,表现远超人类平均水平
图40:CICERO——在完整的自然语言外交游戏中与真实人类对战,表现远超人类平均水平
CICERO的成就
CICERO [Meta AI, 2022] 是首个在完整自然语言外交游戏中与真实人类对战的AI系统: - 匿名参加了在线自然语言外交联盟 - 参加至少5局游戏的19名玩家中排名第2 - 进入前10% - 平均得分是人类平均水平的2倍以上
这是一个惊人的结果——AI不仅学会了玩游戏,还学会了与人沟通、建立信任、协商合作。
局限性
Noam Brown坦诚地指出,CICERO是在2022年底训练的,当是的LLM质量远不如今天。如果用今天的先进模型重新训练,表现应该会更好。
8.3 Hanabi:合作型纸牌游戏
同样的方法也被应用到了Hanabi游戏中。
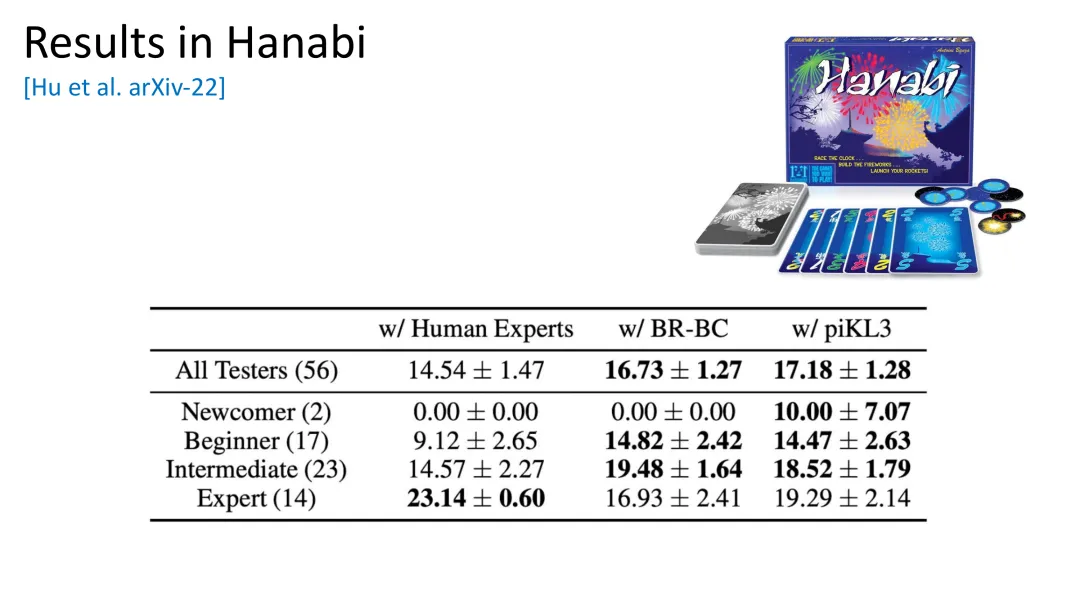 图41:Hanabi——合作型纸牌游戏,AI与不同水平的人类玩家合作都超过了专家表现
图41:Hanabi——合作型纸牌游戏,AI与不同水平的人类玩家合作都超过了专家表现
Hanabi游戏规则
Hanabi是一种合作性质的纸牌游戏: - 玩家看不到自己的手牌 - 只能通过暗示告诉队友牌的信息 - 需要紧密配合才能成功
惊人结果
测试者类型 | AI表现 vs 专家人类 |
所有测试者 | 超过专家人类 |
新手 | 显著超过 |
初级 | 显著超过 |
中级 | 显著超过 |
专家 | 显著超过 |
在所有测试条件下,与各种水平的人类玩家合作时,AI都超过了专家人类的表现。这再次验证了“将人类作为环境一部分”方法的有效性。
8.4 最终思考:双人零和游戏的特殊性
 图42:最终思考——双人零和游戏是特例,非双人零和游戏中需要人类数据,但前景乐观
图42:最终思考——双人零和游戏是特例,非双人零和游戏中需要人类数据,但前景乐观
核心总结
1.双人零和游戏是一个特例
–自我对弈可以产生无敌策略
–不需要人类数据
2.一般情况下,AlphaGo风格的自我对弈不会收敛到“最优”策略
–在非双人零和游戏中
–“最优”取决于你想与谁互动
3.但我对替代方案的研究持乐观态度
–结合人类数据的混合方法已经显示出巨大潜力
–新算法的发展正在快速推进
九、AI Agent之间的LLM合作
9.1 转向AI-Agent合作
在讨论完与人类合作的问题后,Noam Brown转向了一个不同的主题:AI Agent之间的合作。
 图43:AI Agent之间的LLM合作——不需要人类数据的领域
图43:AI Agent之间的LLM合作——不需要人类数据的领域
新视角
到目前为止,我们一直在讨论与人类的合作。但如果我们只想要AI之间相互合作呢?
这种情况下,不需要人类数据——AI可以完全通过自我对弈或协作学习来学会相互配合。
9.2 测试时计算扩展:OpenAI o系列的革命
Noam Brown首先回顾了推动AI能力快速提升的关键技术——测试时计算扩展。
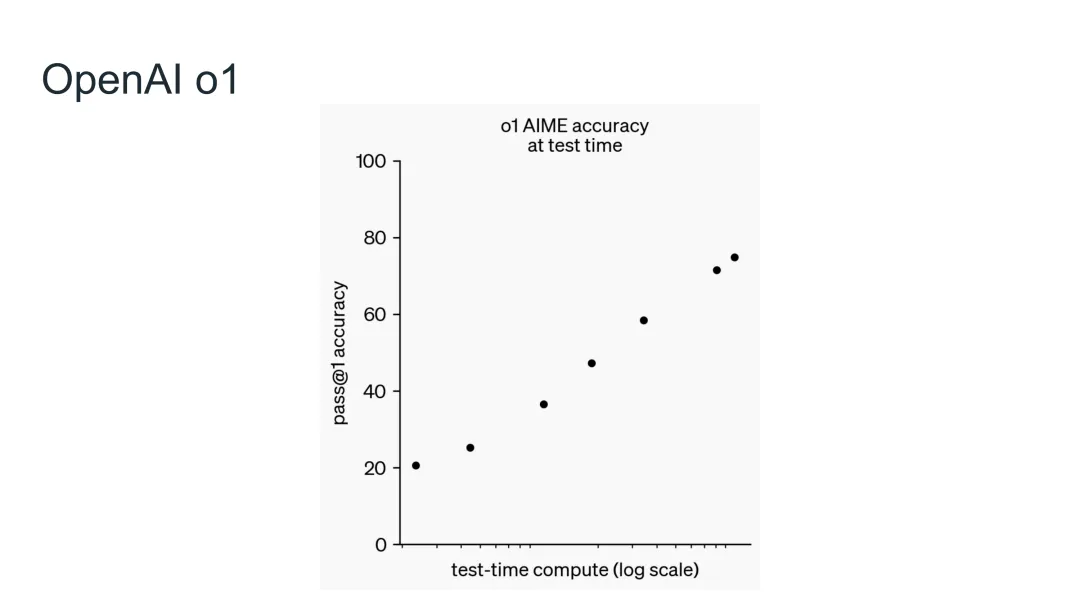 图44:OpenAI o1的测试时计算扩展——模型思考时间越长,性能越好
图44:OpenAI o1的测试时计算扩展——模型思考时间越长,性能越好
OpenAI o系列的革命
近年来,OpenAI的o系列模型展示了一种新的范式: - 模型思考时间越长,性能越好 - 测试时计算扩展正在取得惊人的进展
这种“推理时扩展”与传统的“训练时扩展”相辅相成,代表了AI能力提升的新方向。
性能提升的惊人轨迹
模型 | 时间 | Codeforces评分 | 百分位 |
GPT-3.5 | 2022.1 | ~250 | <10% |
GPT-4 | 2023.1 | ~400 | <10% |
GPT-4o | 2024 | ~800 | ~10% |
o1-preview | 2024.9 | ~1250 | ~50% |
o1 | 2024.12 | ~1900 | ~90% |
o3 | 2025.4 | ~2700 | ~99% |
从2022年到2025年,AI在Codeforces编程竞赛上的表现经历了惊人的提升: - 从无法达到竞赛水平 - 到超越50%的参赛者 - 再到超越99%的参赛者 - 最终在2025年,OpenAI在ICPC(国际大学生程序设计竞赛)中获得第一名
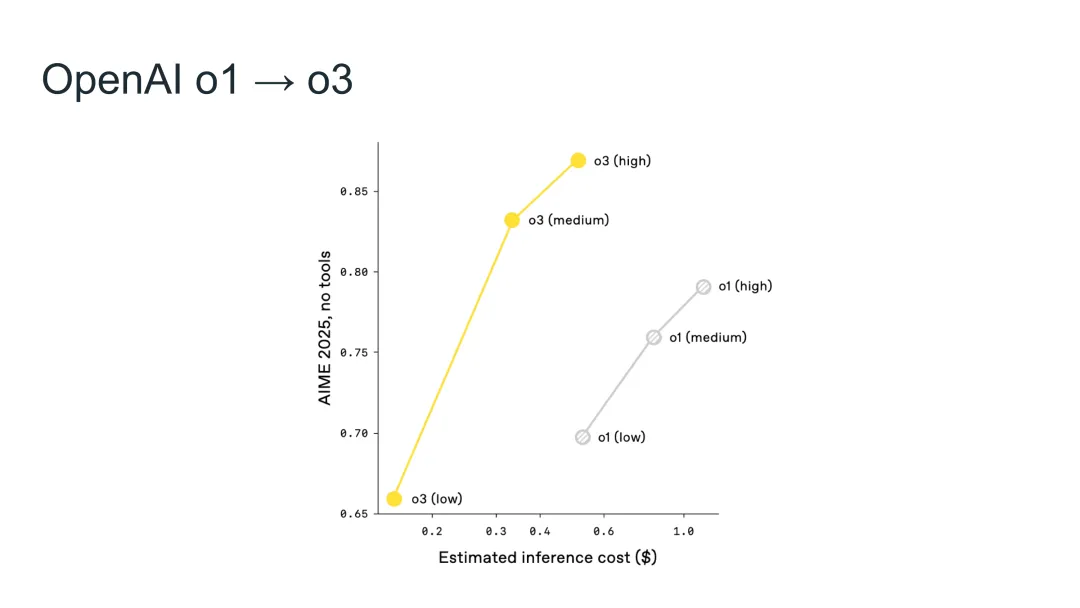 图45:o3比o1更高效——在相同或更低的推理成本下达到更高的准确率
图45:o3比o1更高效——在相同或更低的推理成本下达到更高的准确率
o3比o1更高效
除了绝对性能的提升,还有一个重要发现: - 在相同或更低的推理成本下 - o3达到比o1更高的准确率 - 这意味着效率也在快速提升
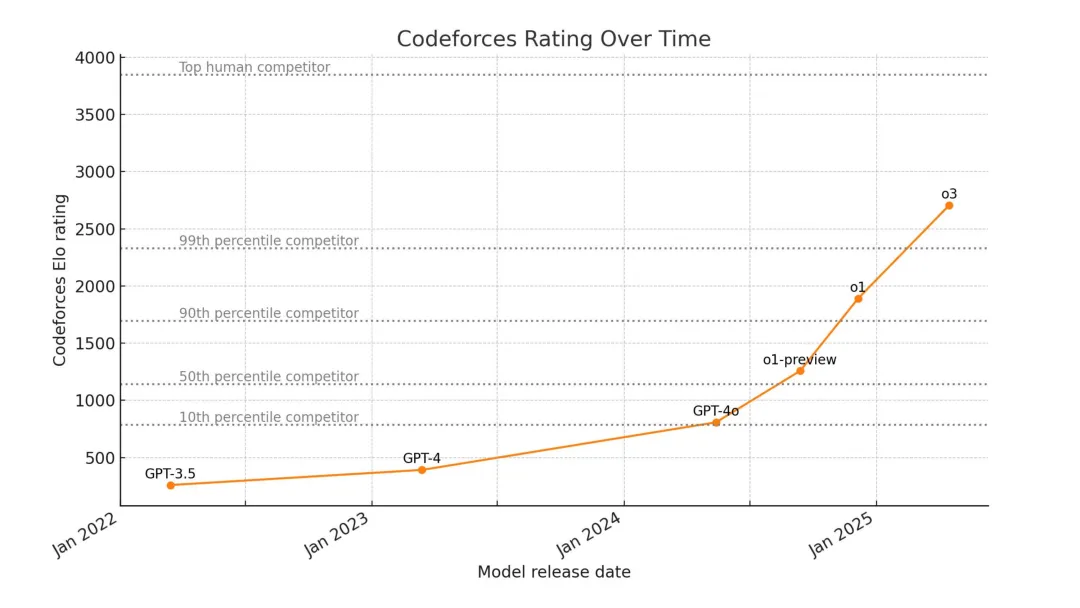 图46:Codeforces评分随时间的变化——从2022年到2025年呈现陡峭的上升趋势
图46:Codeforces评分随时间的变化——从2022年到2025年呈现陡峭的上升趋势
9.3 多智能体AI:延迟问题
虽然o系列展示了测试时计算的力量,但也揭示了一个根本性问题。
 图47:多智能体AI的延迟问题——Chain-of-Thought是串行的,延迟最终成为瓶颈
图47:多智能体AI的延迟问题——Chain-of-Thought是串行的,延迟最终成为瓶颈
延迟瓶颈
问题在于:Chain-of-Thought本质上是串行的。
•模型必须一步一步地思考
•每一步都依赖于前一步的结果
•无法并行化
随着模型变得越来越强,人们希望它们思考更长时间: - GPT-5 Pro可以思考15-20分钟 - 但用户不愿意等待3周
延迟最终会成为瓶颈——你不能无限增加思考时间,因为用户需要等待。
并行测试时扩展技术
为了解决这个问题,研究者开始探索并行的测试时扩展技术: - Best-of-N:从LLM采样N个不同的响应,用评分函数评估,选择最好的 - Consensus(共识):选择最常见的答案
这些方法的共同特点是低延迟——可以并行采样,而不必等待串行计算完成。
9.4 Best-of-N在数学基准上的表现
Noam Brown展示了Best-of-N方法的实验结果。
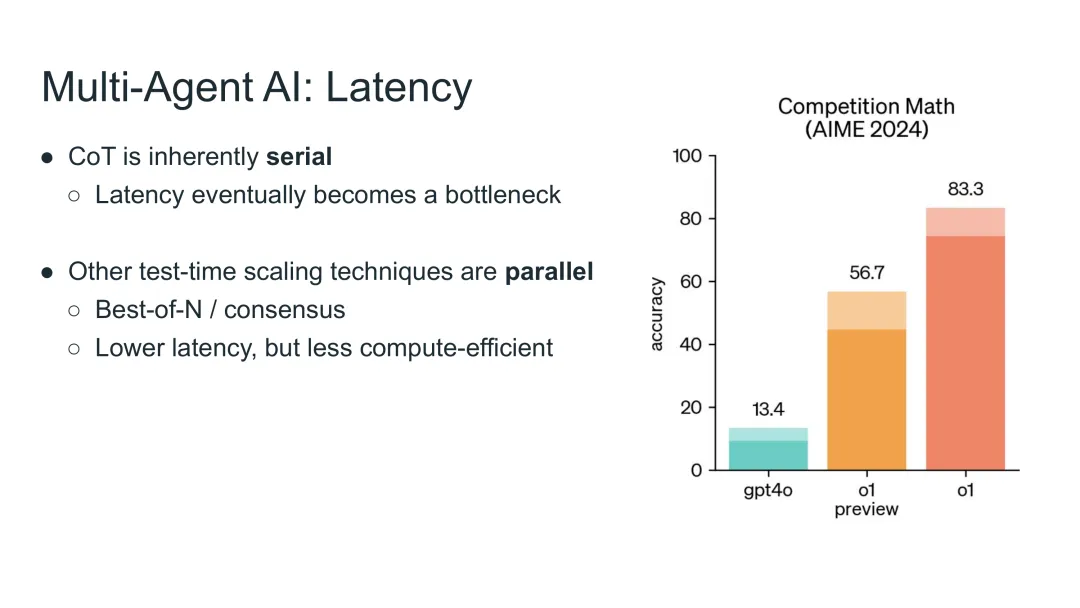 图48:Best-of-N实验结果——简单的并行化就能带来巨大提升
图48:Best-of-N实验结果——简单的并行化就能带来巨大提升
实验结果
模型 | 准确率 |
gpt-4o | 13.4% |
o1-preview | 56.7% |
o1 + consensus (64样本) | 83.3% |
关键洞察
•即使没有新技术,简单的并行化就能带来巨大提升
•o1-preview通过consensus从56.7%提升到83.3%
•多智能体AI可以显著降低延迟
这是多智能体AI在延迟优化方面的首个成功应用。
9.5 多智能体AI:多样性是优势
除了延迟问题,多智能体AI还有一个重要动机:多样性是优势。
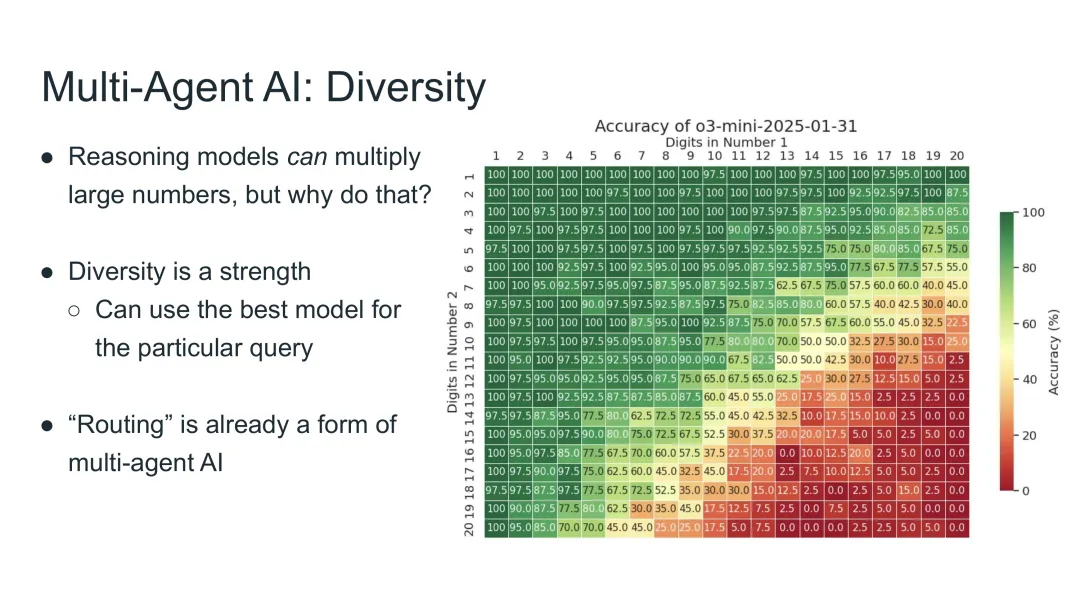 图49:多智能体AI的多样性——不同模型擅长不同任务,让专业模型做专业事
图49:多智能体AI的多样性——不同模型擅长不同任务,让专业模型做专业事
思考这个问题
当o3发布时,很多人抱怨它无法计算20位数的乘法。但Noam Brown认为这种批评有失偏颇: - 有多少人类能可靠地徒手计算20位乘法? - 我们不期望人类这样做——我们会给他们计算器
同样道理
不同模型在不同任务上有各自的优势: - 有些模型擅长数学推理 - 有些模型擅长创意写作 - 有些模型擅长代码生成 - 让模型使用“计算器”(其他模型)可能更高效
路由(Routing)已经是一种多智能体AI
现代AI系统已经在使用路由机制: - 将查询路由到最适合的模型 - 使用最佳模型完成特定任务
这本质上就是多智能体协作——只不过协作的方式是“委派”而非“讨论”。
9.6 多智能体协作的现状
Noam Brown总结了当前多智能体AI的发展状态。
 图50:当前的多智能体协作脚手架——在某些任务上可靠,但需要大量工程工作且脆弱
图50:当前的多智能体协作脚手架——在某些任务上可靠,但需要大量工程工作且脆弱
现有系统的特点
当前的多智能体系统(如各种Agent框架): - 在某些任务上可靠 - 但需要大量工程工作 - 非常脆弱,容易出错
典型的架构包括: - 主智能体分解任务 - 子智能体处理子任务 - 上下文压缩LLM - 记忆和检索系统
这些系统虽然有效,但远未达到“即插即用”的水平。
 图51:Cognition的观点——当前Agent还无法可靠地参与长上下文主动对话,但技术正在快速进步
图51:Cognition的观点——当前Agent还无法可靠地参与长上下文主动对话,但技术正在快速进步
Cognition的洞察
Cognition的一篇博客指出了当前的局限性: > “当前的智能体还无法可靠地参与这种长上下文主动对话的方式。”
但Noam Brown对此持乐观态度: - 感觉我们正处于能够实现这些能力的临界点 - 未来的智能体将能够相互沟通、协调、达成共识
为什么现在是特殊的时刻
对于多智能体AI来说,这是一个激动人心的时刻: - AI模型正在接近能够有效协作的水平 - LLM提供了天然的语言作为通信媒介 - 过去几十年的多智能体研究积累了大量知识 -最大的障碍——让AI相互理解——已经基本解决
自然语言通信的革命
过去,让AI相互通信是一个巨大的挑战: - 有整条研究线专门研究如何让AI发展出自己的“语言” - 整个PhD项目都花费在这个问题上
但现在,有了LLM,这已经成为一个已解决的问题: - 你可以直接让AI用自然语言相互交流 - 它们能理解彼此
十、总结与展望
核心要点
通过这次深度讲座,Noam Brown为我们揭示了多智能体AI领域的核心洞见:
1.自我对弈的力量与局限
在双人零和游戏中,自我对弈具有神奇的特性——不需要任何人类数据就能收敛到最优策略。AlphaGo、Libratus等系统的成功都建立在这一基础之上。然而,当我们跳出双人零和游戏的范畴时,这些优良性质就消失了。
2.人类数据的重要性
如果目标是与人类合作,人类数据是不可或缺的。自我对弈RL学到的策略可能与人类行为完全不同,导致在实际部署中表现糟糕。“将人类作为环境一部分”的方法——收集人类数据、训练人类模仿模型、在人类世界中进行RL——在外交游戏、Hanabi等场景中取得了巨大成功。
3.非双人零和游戏没有“最优”策略
在非双人零和游戏中,“最优”取决于你想与谁互动。DORA vs SearchBot的实验深刻揭示了这一点——不同的训练方法会产生不同的均衡,没有哪个能“通吃”所有对手。
4.多智能体AI的机遇
对于AI-Agent合作,多智能体AI提供了两大机遇: - 延迟优化:并行化可以显著加速推理 - 多样性利用:让专业模型做专业事
5.算法融合的趋势
传统的单智能体RL算法(如PPO)和多智能体均衡求解算法(如CFR)之间存在巨大鸿沟。但最新研究正在弥合这一鸿沟——R-NaD、Magnetic Mirror Descent等新算法在两种设置中都表现良好,代表了算法的未来方向。
未来展望
多智能体AI正处于一个激动人心的时刻: - 技术正在快速进步 - LLM为Agent间的通信提供了天然接口 - 结合人类数据的混合方法展现出巨大潜力 - 算法正在融合,单一框架适用多种场景
我们有理由相信,未来的AI系统将能够: - 与人类进行自然、有效的合作 - Agent之间相互协调解决复杂问题 - 在各种游戏中达到或超越人类水平 - 在现实世界的协作任务中发挥作用
参考论文
论文 | 发表场所 | 核心贡献 |
Libratus (Brown & Sandholm) | Science-17 | 双人无限注扑克AI,击败人类顶级选手 |
DORA (Bakhtin et al.) | NeurIPS-21 | 纯自我对弈学习外交游戏 |
CICERO (Meta AI) | 2022 | 自然语言外交游戏AI |
Diplodocus (Bakhtin et al.) | ICLR-23 | 人类数据训练的外 |
