 夜雨聆风
夜雨聆风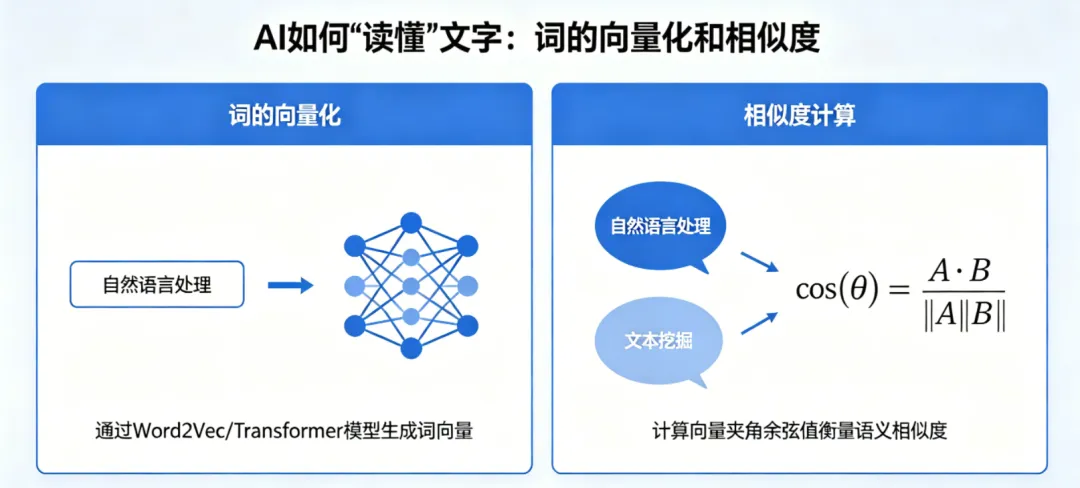
你是否曾好奇,像ChatGPT这样的AI,是如何理解人类语言的?
它真的明白“苹果”指的是水果还是科技公司吗?
本文将带你走进AI处理文字的世界,揭开其背后的原理,理解AI如何将文字转化为数字,并从中捕捉语义。
一、文字在计算机眼中的本质
首先,我们需要明确一点:计算机不认识文字。
当你输入“苹果”两个字时,电脑只是根据字符编码(如:Unicode编码)显示对应的图形,它并不知道这两个字代表什么意思。
要让AI处理文字,第一步和图片处理一样:将文字转化为数字。
但如何将抽象的文字变成有意义的数字呢?这正是AI理解语言的关键。
二、第一步:将文字切分成Token
AI处理文字时,并不是逐字逐句阅读,而是以Token为单位。
这里的切分token,其实类似搜索引擎的分词的做法,按照词汇库来对文章进行分词。不过token的拆分规则和搜索引擎的分词还是不一样的。
你可以把Token理解为AI阅读文字的“最小片段”。
例如:
英文句子 "Hello world" 可能被切分为 ["Hello", " world"](2个Token) 中文句子 "我爱学习" 可能被切分为 ["我", "爱", "学习"](3个Token)
Token可以是单个字、一个词,甚至是词的一部分。
常见的切分技术如BPE(字节对编码),通过统计文字中常见组合,将文字切分为有意义的片段。这种方式让AI无需记忆所有词汇,只需掌握常见片段,就能拼凑出各种表达。
三、第二步:将Token转化为词向量
Token切分后,每个Token只是一个编号(例如“Hello”对应编号1006)。
但编号本身没有意义,我们需要为每个Token赋予“含义”。
这就是词向量(Word Vector)的作用。
词向量可以理解为一串有序的数字,每个数字代表词的某个特征。
例如,假设我们用4个数字描述一个词:
[皇室, 性别, 年龄, 权力]
“国王”: [0.8, 0.7, 0.5, 0.8]“王后”: [0.8, -0.7, 0.5, 0.8]“男人”: [0.1, 0.7, 0.4, 0.2]“女人”: [0.1, -0.7, 0.4, 0.2]
通过观察这些数字,我们可以发现:
“国王”和“王后”的第一、第三和第四数字相同,只有第二个数字不同(正负相反),这可能代表“性别”维度。 “男人”和“女人”也有类似规律。
当然,真实的词向量更为复杂。例如,ChatGPT使用的词向量有768个维度,每个维度没有明确的标签,但通过大量文本训练,AI能自动学习到这些维度所代表的语义特征。
四、词向量的神奇之处
2013年,Google的研究团队发现,词向量可以捕捉语言中的逻辑关系。
例如,通过向量运算:
“国王” - “男人” + “女人” ≈ “王后”
这种运算在语义上成立,因为“国王”与“王后”的关系,类似于“男人”与“女人”的关系。
类似的例子还有:
“巴黎” - “法国” + “意大利” ≈ “罗马” “更大” - “大” + “小” ≈ “更小”
这些发现表明,AI并未被明确教授“性别”“首都”等概念,而是通过分析大量文本,自动发现了这些语义关系。
五、词向量是如何训练出来的?
词向量的训练依赖于一个简单的思想:一个词的含义可以通过它周围的词来定义。 例如,在句子“今天天气晴朗,我们去公园散步”中,“公园”常与“散步”“天气”等词一同出现。通过反复训练,AI会调整“公园”对应的向量,使其与“花园”“户外”等词在向量空间中更接近,而与“电视”“电脑”等词远离。
这种方法让AI学会了词语的“语义距离”:经常在相似上下文中出现的词,其向量会更接近。
六、如何比较词向量的相似性?
判断两个词的语义是否接近,不能简单比较向量数值的大小,而应比较它们的方向是否一致。
余弦相似度是常用的衡量方法,它计算两个向量之间的夹角:夹角越小,语义越接近。
例如:
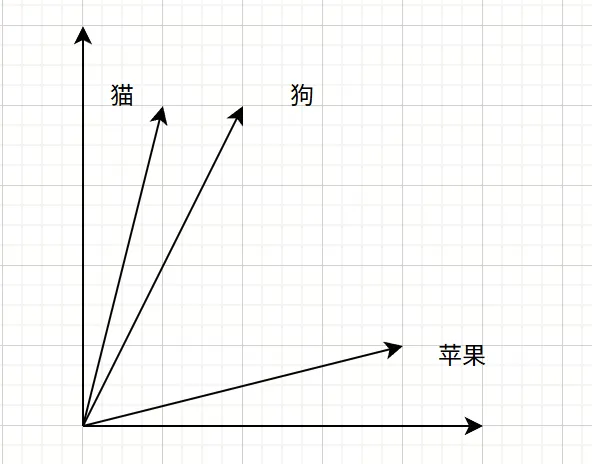
“猫”和“狗”的向量方向可能非常接近(余弦值接近1),因为它们都是宠物。 “猫”和“苹果”的向量方向相隔较远,因为它们是不同的类别,特征相差较大。
七、词向量如何改变我们的生活?
在词向量技术出现之前,搜索引擎只能进行关键词匹配。例如,搜索“苹果手机”,结果中可能包含大量与水果相关的页面。 而有了词向量,AI能够理解“苹果”在不同语境下的含义:
在“我吃了一个苹果”中,“苹果”的向量更接近“水果”“橘子”。 在“我买了苹果手机”中,“苹果”的向量更接近“iPhone”“科技”。
这种语义理解能力,让搜索引擎、智能助手和ChatGPT能够更准确地响应用户的需求。
八、从低维到高维:AI的“语义地图”
真实的词向量通常有几百甚至上千个维度。虽然人类无法直观想象高维空间,但可以理解为:每个维度代表词的一个特征,维度越多,对词义的描述越精细。 例如,768维的词向量就像是给每个词标注了768个特征,这些特征共同构成了一张精细的“语义地图”,AI通过计算词与词之间的距离来理解它们的关系。
九、总结
AI如何“读懂”文字:
- Token化
将文字切分为有意义的片段。 - 词向量化
将每个Token转化为一串数字,编码其语义。 - 语义计算
通过向量运算和相似度比较,理解词与词之间的关系。
AI并不真正“理解”文字,而是通过数学运算在语义空间中定位词语的位置。正是这种能力,让AI能够处理复杂的语言任务,从简单的搜索到智能对话。
词向量技术为现代AI语言模型(如ChatGPT、Claude等)奠定了基础。尽管这项技术早在2012年之前就已存在,但直到深度学习和大规模数据的结合,AI才真正展现出强大的语言理解能力。
