 夜雨聆风
夜雨聆风周日一天没休息,我是用 AI 做了一个自己超级喜欢的小片子。
话说我最近用 AI 生成图片、视频,真有点上瘾。就像写代码一样,看着自己一步步把一个作品构建出来,特别有成就感。这和赚钱没关系,就是单纯的好玩。
下个月有一部电影叫《青铜葵花》要上映,改编自曹文轩的同名小说。好几年前跟孩子一块读的,当时就觉得这本书挺有意思。
虽然是儿童文学,但对我来说,它给我最大的感触是让我意识到,人无论在什么情况下都有选择。
即便青铜一家很穷,但仍然可以在很多事情上选择善良,选择更有尊严的活着。这一点让我印象深刻。
上周看到电影要上映的消息,就一直在查资料。周五晚上都躺到床上了,突发奇想:我完全可以用 AI 复刻一下他们的预告片。
因为这个预告片还是非常唯美。我很喜欢其中的画面。
下面是我复刻的动漫风格版本。做这件事完全是因为喜欢这部电影,喜欢里面的画面。
而且在复刻的过程中,还能学到不少关于镜头、构图、配乐的东西。挺有意思的。
工具方面,我用的是 Vidu 的 Q3 模型。Q3 最突出的能力就是参考生视频能力很强。
简单说参考生就是让 AI 生成视频时能参考我们给它的图片。我给它一张人脸照,生成的视频里这个人就长这样。给它一个场景图,它就在这个场景里拍。角色、场景、道具都能指定。
这能力对做连续剧情的内容特别重要。以前 AI 生成视频,每条都是独立的,角色长相会飘,场景会变,根本没法串成故事。
有了参考生,角色和场景可以复用,才有可能做出一个完整的片子。
Vidu 是最早做参考生的,Q3 这个版本又往前推了一步。以前主要是保角色一致性,现在是万物可参。人脸、场景、服装、道具,甚至音色,都可以作为参考输入。
除了参考生,Q3 还有一个让我惊喜的地方是特效和音效。
它内置了六类特效引擎,粒子、流体、光影、动力学这些都能做。虽然《青铜葵花》是个安静的故事,用不上爆炸和能量波,但像风吹芦苇、阳光穿过葵花田这种环境氛围,Q3 处理得很自然。
光影的变化、空气里的颗粒感,这些细节让画面更有电影质感。
音效也是直接生成的。以前 AI 视频要么没声音,要么只能后期配 BGM。Q3 能生成环境音、动作音效,甚至情绪氛围音。
我片子里有几个镜头,风声、脚步声都是模型自己加的,省了不少后期的事。
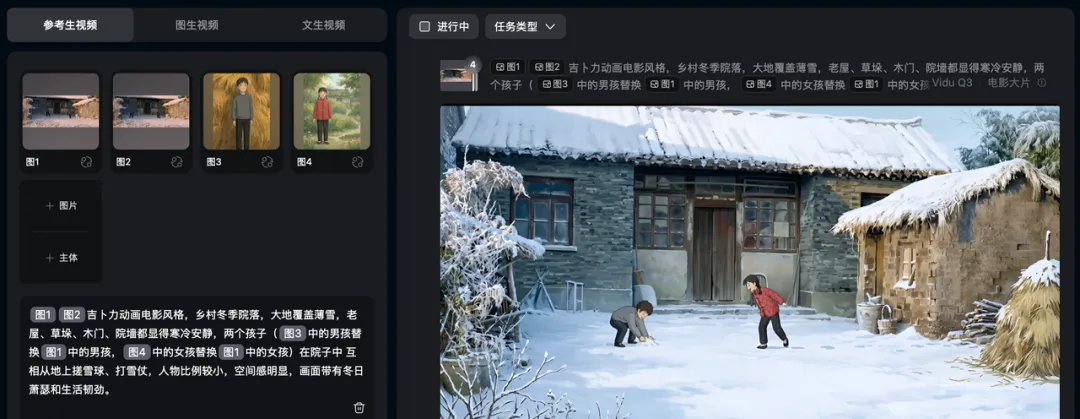
我复刻《青铜葵花》预告片的时候,先做了青铜和葵花的动漫角色图,又找了大麦地、葵花田这些场景图,然后一条一条生成。
角色在不同镜头里是同一个人,场景也能保持统一,这才能把片子串起来。
真的没想到,AI 视频已经发展到这个地步了。
创作过程
假期的一次尝试
Vidu 的地址在这里:
https://www.vidu.com/zh/home/recommend
输入专属邀请码:CPAY,注册就送500积分。
企业用户也可以登陆,体验最新功能:
https://platform.vidu.cn/
这里我要多一句嘴,Vidu 在动漫风格上依旧是王者。我选它还有一个原因:不想额外生成中间图片。
什么意思呢?我的思路是直接拿预告片的分镜截图当参考图,加上提示词,喂给 Vidu Q3 模型。这样最省事。
但这个思路能跑通,有两个前提:一是动漫风格的呈现要好,二是模型对参考图的理解要足够深,能读懂整张图在讲什么,而不是只抓到局部细节。
Q3 在这两点上都还不错,所以整个流程很顺:截图、写提示词、生成、挑选。没有太多中间环节。
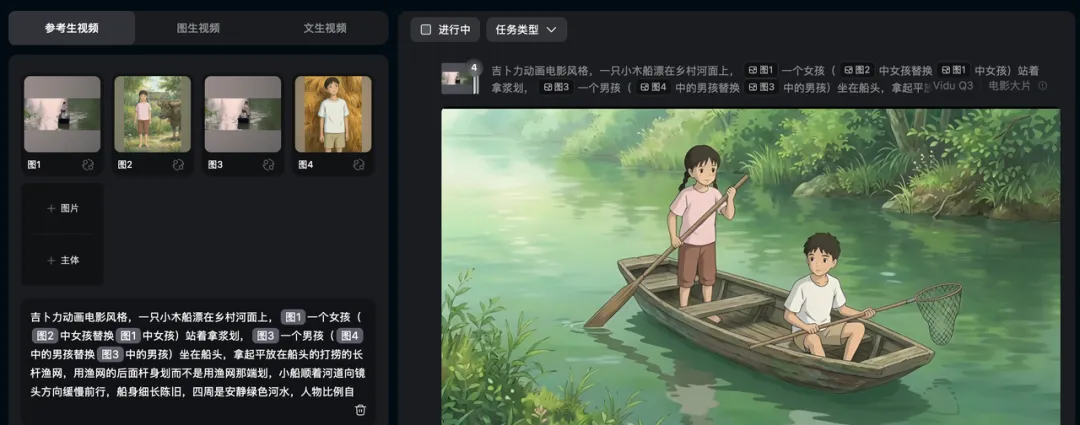
所以我的工作流就非常简单。大家看下面这张截图:
先说个我最开始就踩的坑。
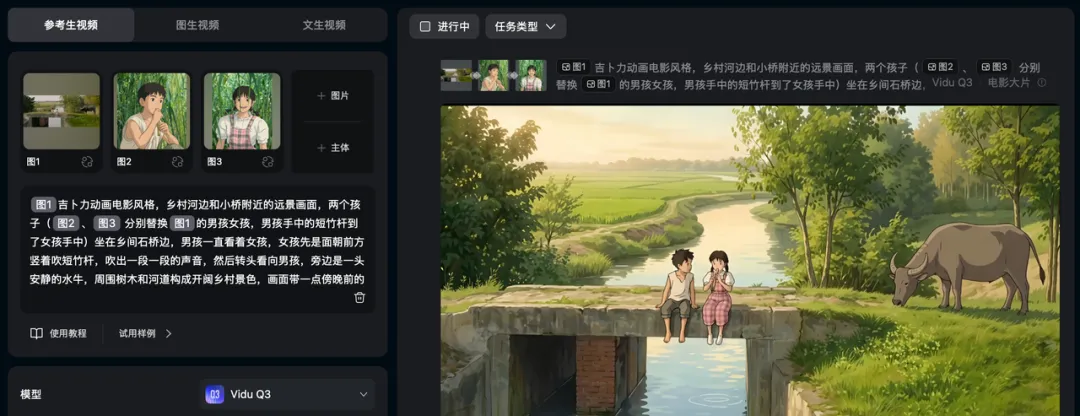
第一个镜头是河边大树加水面的空镜开场。原片里其实是有人的,只不过特别小,很容易被模型忽略。
这里如果提示词里不写清楚,Vidu Q3 可能会直接去掉人物,生成出来一个纯风景的空镜开场。所以这里得加一句:画面中人物保留,不要去掉。
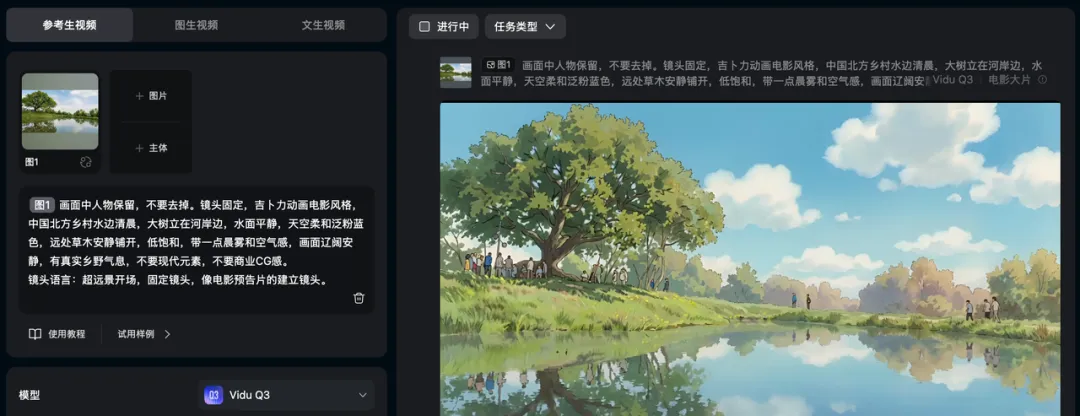
参考生视频相较于首尾帧生视频对提示词的要求还是要细一些。所以效果不好,不是一定是模型做不到,而是我们没说清楚。
第二个镜头,男孩在芦苇中的近景,这个挺难抽的。因为有段时间没有细致的写提示词了,所以一开始我以为是模型不行,但后来结合第一个镜头的经验,意识到不是能力问题,是可控范围的问题。
把细节往提示词里塞,比如,水面波纹、微风吹动、芦苇晃动、远处鸟鸣、竹竿碰水的声音,人物表情先怎么样,后怎么样,这些东西它是能接住的,而且接得还挺稳。
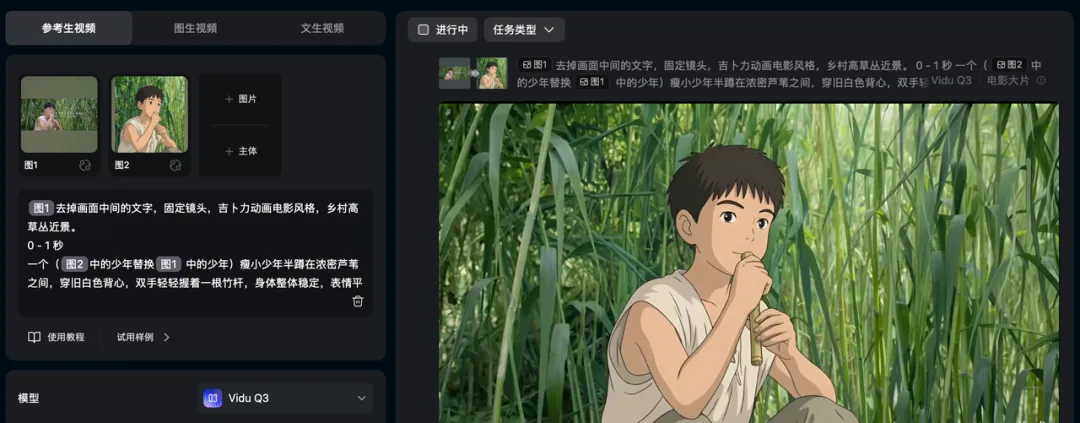
这里我要多一句嘴,就是我们上传的图片是可以复用的,输入“@”符号就可以选择要复用的图片了。
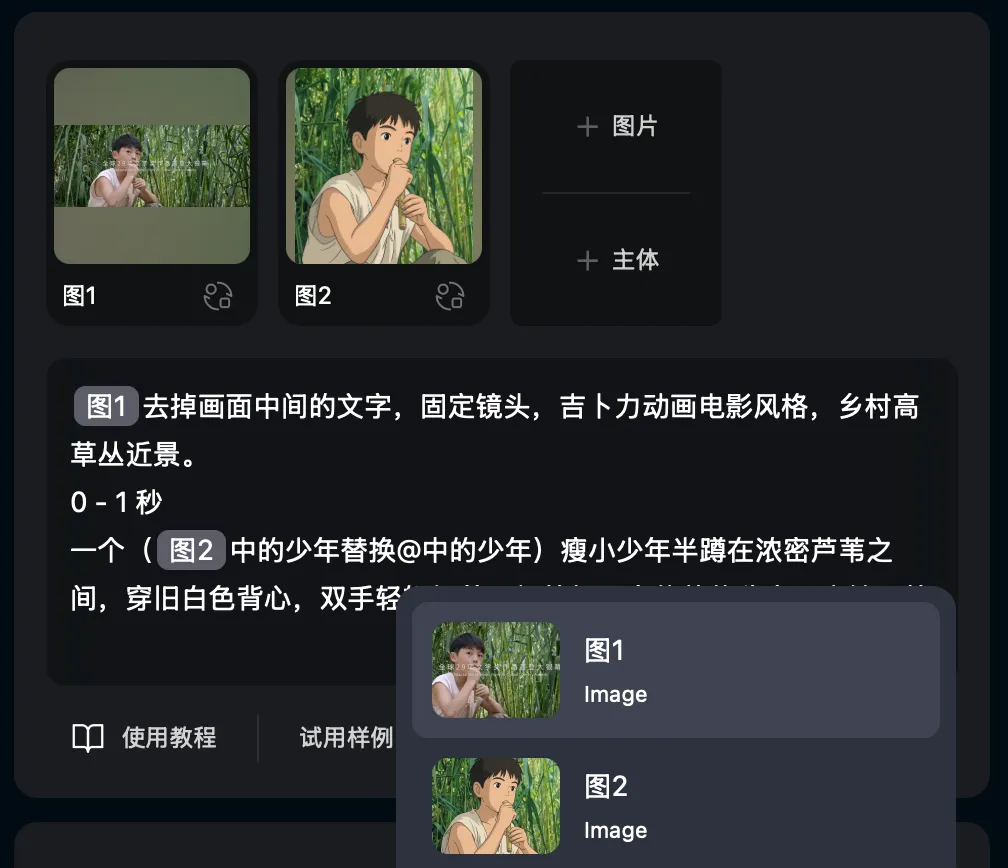
这一代模型让我改观的地方是,它生成出来的东西不那么假了。
比如我做葵花在芦苇荡里跑的那个镜头。以前AI生成这种画面,人在跑,但周围的芦苇纹丝不动,光也不变,人物和环境像是两层皮,一眼就穿帮。
Q3不一样,人跑过去,芦苇会晃,光线会跟着变,整个环境跟人物是一体的。
音效也是。那个镜头里风吹芦苇的沙沙声、脚步踩地的声音,都是模型自己生成的,跟画面是配套的,不是后期硬贴上去的感觉。
这些东西单拎出来都是细节,但加在一起,感觉就对了。风声、光影、环境的晃动,其实都在帮你讲情绪。
还有一个发现是,提示词写得越具体,出来的效果越好。不是那种玄学的你要懂它,就是老老实实把你想要的画面描述清楚。
模型能力是够的,就看你能不能把脑子里的画面翻译成它能懂的话。
第三个镜头,女孩首次亮相就很简单了,几乎是送分题,两次就出了。
Vidu Q3 模型上限很高,但还是有点小毛病存在的。
拿接下来的这第四到第六个镜头来说,这一段我抽卡的时候,提示词中写人物向右转头,它可能给你来个向左,写固定镜头,它可能自己开始运镜。
不过有意思的地方也在这儿。它有时候自己加一点景别变化、镜头移动,或者光线的起伏,画面反而更好看了。
接下来,第七个镜头向日葵空镜就不说了,很简单。
第八个镜头,男孩穿行在向日葵田找女孩,这个镜头有点玄学,也许是运气好。我当时抽的时候完全没底,光想想就觉得难。
我预想肯定会碰到这些问题:人物比例不对,比向日葵矮一截。或者节奏不对,像在散步旅行,一点找人的焦急感没有。还有那种低级错误,比如穿行方向反了。
这些问题碰上就头大。没想到没抽几次就出了还不错的效果。
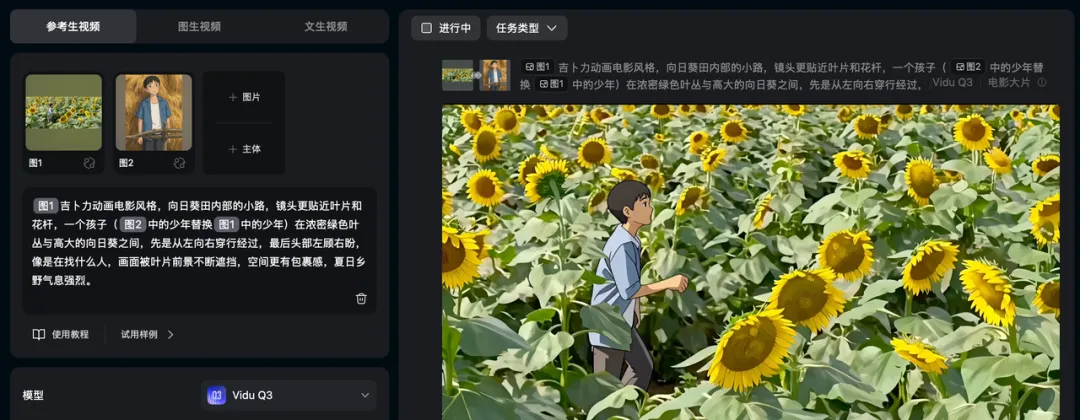
你看这个镜头,向日葵挡住人,人又从后面钻出来,阳光在叶子和脸上一闪一闪,镜头还跟着人在动。这些东西加在一起,找人那种着急劲儿就出来了。
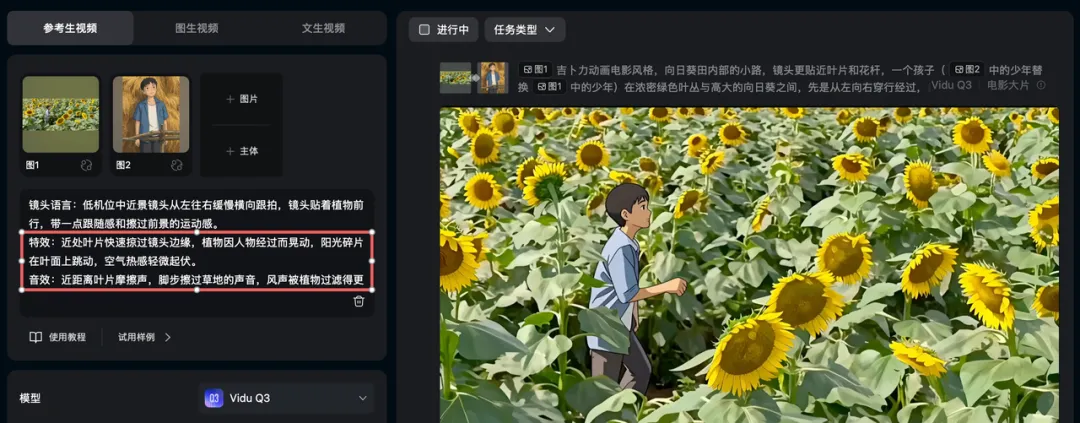
下面是我加的特效和音效,模型能够理解到。就是这些小细节自然地配合在一起,画面就开始讲故事了。
第九到第十一个镜头又轻松回来了,属于那种你让它干嘛它就干嘛的阶段,基本没什么阻力。
第十二个镜头稍微有点意思,难点不在动作,而在情绪。
男孩找到离家出走的女孩,那种松一口气的感觉,这种很微妙。你很难用一句提示词说清楚,但又必须让它表现出来。
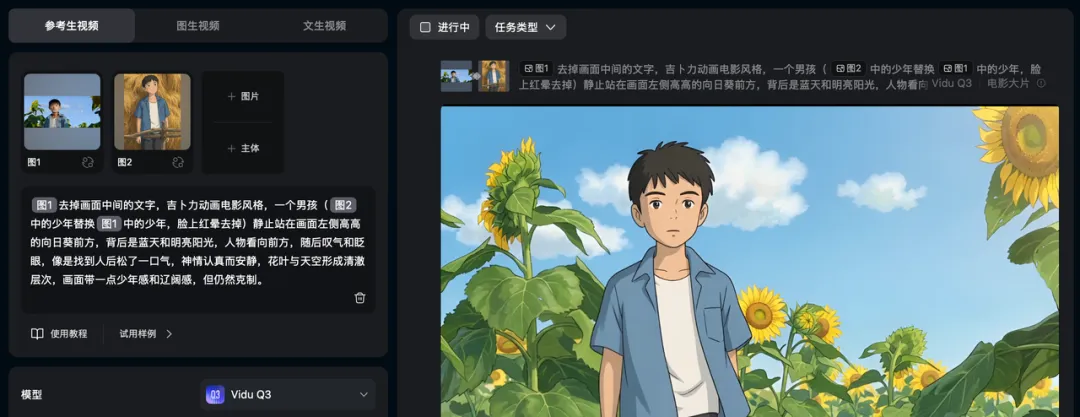
第十四个镜头就又简单了,基本一两次搞定。
然后到第十五、第十六个镜头,两个孩子在河面上的动作镜头,直接地狱模式,不一定是最难的,但一定是最复杂的。
这一段不只是单个镜头难,而是它前后镜头是连着的,动作、情绪、场景、远景人物穿搭和细节都要接得上,而且不能穿帮和出现很违和的动作。
后面的镜头就不一一展开了,大体就是在类似上面的这个循环里反复横跳。
整体感受是,Vidu Q3 确实能支撑起一个完整短片的制作。从角色设定到场景搭建,从镜头生成到音效合成,一个工具基本能覆盖。
当然也有不完美的地方。有些镜头的动作还是不够自然,生成多条之后挑一条效果最好的用。但对于我这种纯粹出于兴趣做着玩的人来说,已经足够了。
写在最后
这种感觉很难描述。就是你脑子里有一个画面,然后你真的把它做出来了。不是想想而已,是真的做出来了。
这事放在以前,我想都不敢想。短时间做出这样一个作品?怎么可能。我又不是专业做动画的,又不会画画,又没有团队。
但现在不一样了。周末当个 Side Project 玩一玩,就能把东西做出来。
图片模型、视频模型、音频模型、大语言模型……这些工具就摆在那里,谁都能用。门槛已经低到这个程度了,剩下的就是我们愿不愿意动手。
我这个片子当然不完美,但这不重要。关注我比较久的朋友应该能看出来,我做的东西在慢慢变好。
每做一个,就比上一个强一点。审美在积累,手感在养成,工具在迭代。这些东西会在某一刻串起来。
所以我现在越来越觉得,这个时代最重要的事就是成为 AI Maker,而不是只当一个 Consumer。
工具已经在这了,门槛已经够低了。剩下的就是动手。做得不好?没关系,下一个会更好。

