 夜雨聆风
夜雨聆风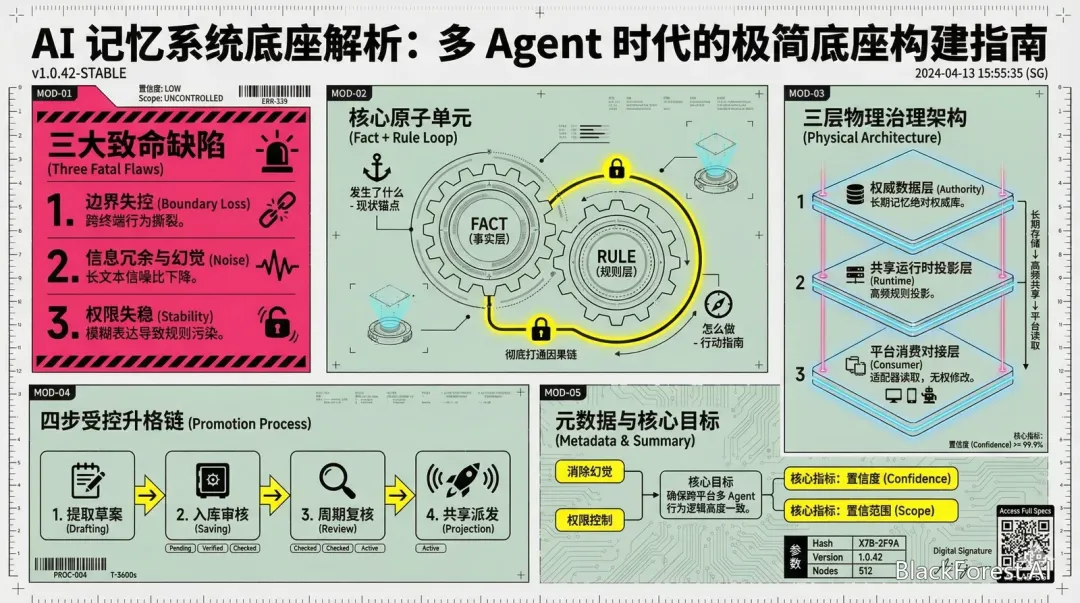
引言
你是否遇到过这样的情况:拥有多个AI助手(Agent),但它们各自为战,行为决策经常自相矛盾?或者给AI喂了大量历史对话,它不仅没变聪明,反而开始产生严重的“幻觉”?甚至有时候,你随口的一句“以后注意”,竟然让AI擅自修改了你的核心系统规则?
如果你在搭建AI知识库或第二大脑时也踩过这些坑,那么今天这篇文章,就是为你准备的。
作为系列解析的第 1 篇,今天我们将深度拆解:多 Agent 环境下的高内聚极简记忆底座。
(注:本记忆系统由 OpenCode 和 Gemini CLI 双端共用,统一治理同一份 Obsidian 知识库,确保跨平台 AI 行为逻辑绝对一致。)
🚨 01. 传统大模型记忆的“三大致命缺陷”

在多 Agent(编排脑中心 + 领域特化子节点)且跨平台的环境中,传统记忆方式面临着严峻挑战:
❌ 边界失控:各个客户端独立存储记忆记录,导致不同终端的 AI 行为决策出现撕裂,无法保持一致。 ❌ 信息冗余与幻觉:直接把历史上下文(History)像滚雪球一样追加存储。长文本的信噪比急剧下降,极易诱发大模型捏造事实。 ❌ 权限失稳(最隐蔽的坑):模型常常因为用户一句模糊的表达(如“总结一下”、“记一下”、“别再犯”),就直接越权写入长期约束,导致核心规则库被严重污染。
⚠️ 破局核心:
本系统在设计之初,就将这类模糊表达列入“授权解释红线”——默认只输出只读摘要。除非用户给出极其明确的写入指令,否则绝不修改核心规则。为了彻底根治这些问题,我们重新设计了一个具备强权限隔离验证与数据概念极致合一的工程底座。
🧩 02. 记忆的最小单元:Fact + Rule 的绝对收敛
摒弃传统碎片化的记录方式,我们将记忆的最小单元重新定义为 Memory。每条 Memory 都强制将“事实(Fact)”与“规则(Rule)”锁死,形成不可分割的闭环:
📍 发生了什么(事实层 - Fact):精准记录事件触发的具体场景与问题现状,提供不可或缺的上下文锚点。 🎯 怎么做(规则层 - Rule):针对该事实提炼出的确定性指导动作与例外边界,提供清晰的行动指南。

为什么这么做?
通过这种结构,大模型在调用记忆时,不仅知道“过去发生过什么”,更能瞬间明白“未来我该怎么做”,彻底打通因果链!
📊 元数据(Metadata)骨架赋能:
记忆不能只是“死文本”,必须是“可计算的数据”。每条 Memory 都遵循统一的 memory-template.md 模板:
type & scope(类型与作用域):让系统精确判断何时加载哪条记忆(例如编程时加载 execution-rule,聊天时加载 global 偏好)。status(状态):赋予记忆生命周期。从 candidate(候选)到 reviewed(已复核)再到 projected(已投影),确保只有验证过的规则才能进入核心。confidence(置信度):量化信任。根据来源(如用户直接纠正 vs 单词执行失败)动态调整权重,防范劣质数据污染。
🏛️ 03. 三层物理治理架构

为了实现严格的主权管控和跨平台一致性,我们的存储路径被划分为职责极其分明的三层物理架构:
- 🛡️ Layer 1: 权威数据层 (Learning Authority)
- 定位:长期记忆的绝对权威库。无论是常识积累还是报错总结,所有系统经验的初始落盘必须且只能存在于此(
memories/)。 - ⚙️ Layer 2: 共享运行时投影层 (Runtime Projection)
- 定位:高频高价值规则的“索引与投影”。这里不存原始记录。只有经过反复验证、任务启动必须加载的准则(如操作红线、默认路由),才有资格从 Layer 1 投影至此(
RuntimeMemory/)。 - 🔌 Layer 3: 平台消费对接层 (Adapter / Consumer)
- 定位:前端入口层(如 OpenCode / Gemini CLI)。它们只能通过专属适配器向 Layer 2 请求数据并应用,绝对无权在自己的沙箱里建立平行的基础价值观。
⛓️ 04. 四步受控升格机制 (Promotion Chain)
记忆绝不是一次性生成的消耗品。我们设计了一条极其严格的“升格链”:
- 📝 提取草案 (Drafting):任务完成后,AI 以只读形式输出经验总结草案。
- 🔒 入库审核 (Saving):通过专属 /save-memory 命令,系统生成完整的 Dry-run 预览(包含路径、摘要、影响范围)。只有在获取操作者的“强授权”后,才正式写入 Layer 1。
- 🔎 周期复核 (Review):通过 /review-memory命令在实战中检验其稳定性,汰换低效逻辑,将状态从 candidate 升格为 reviewed。
- 🚀 共享派发 (Projection):当规则具备全局价值时,经 /project-memory 发布到 Layer 2,作为跨 Agent 协作的底层标尺。

🤖 05. 进阶:底座与“数字分身”的自我蒸馏
今天讲的极简记忆底座,是整个 AI 系统的基础设施层。而在这个底座之上,我们还架设了一条特种生产线——自我蒸馏系统(专属库位:memories/self-model/)。
它完全遵从上述的底座治理规则(授权红线、Dry-run 壁垒、升格链),但拥有独立的解析管线。当前端平台启动时,适配器会按需加载自我蒸馏产出的 Self-model 记忆(包含你的判断模式、表达风格、协作偏好)。
随着记忆的不断沉淀与投影,AI 将不再是一个冷冰冰的工具,它的输出风格与决策逻辑会无限趋同于你本人,最终孵化出一个高保真的数字分身(Digital Twin)!
下期预告:我们将深度拆解《动态自我蒸馏体系解析》,敬请期待。
