 夜雨聆风
夜雨聆风
前段时间,一场有点“戏剧性”的意外,让本就热度高涨的 ClaudeCode,又一次上了热搜。
51.2 万行代码、1900 多个文件,因为一次近乎“离谱”的打包失误,被直接暴露在公开网络上。短短时间内,GitHub Fork 数突破 4 万,社区瞬间被点燃。有人逐行拆解它的架构逻辑,有人深挖权限控制的设计细节,甚至连一些尚未发布的功能也被顺藤摸瓜地翻了出来。
还有网友调侃:“Claude 这是觉醒了,自己决定开源 Claude Code。”
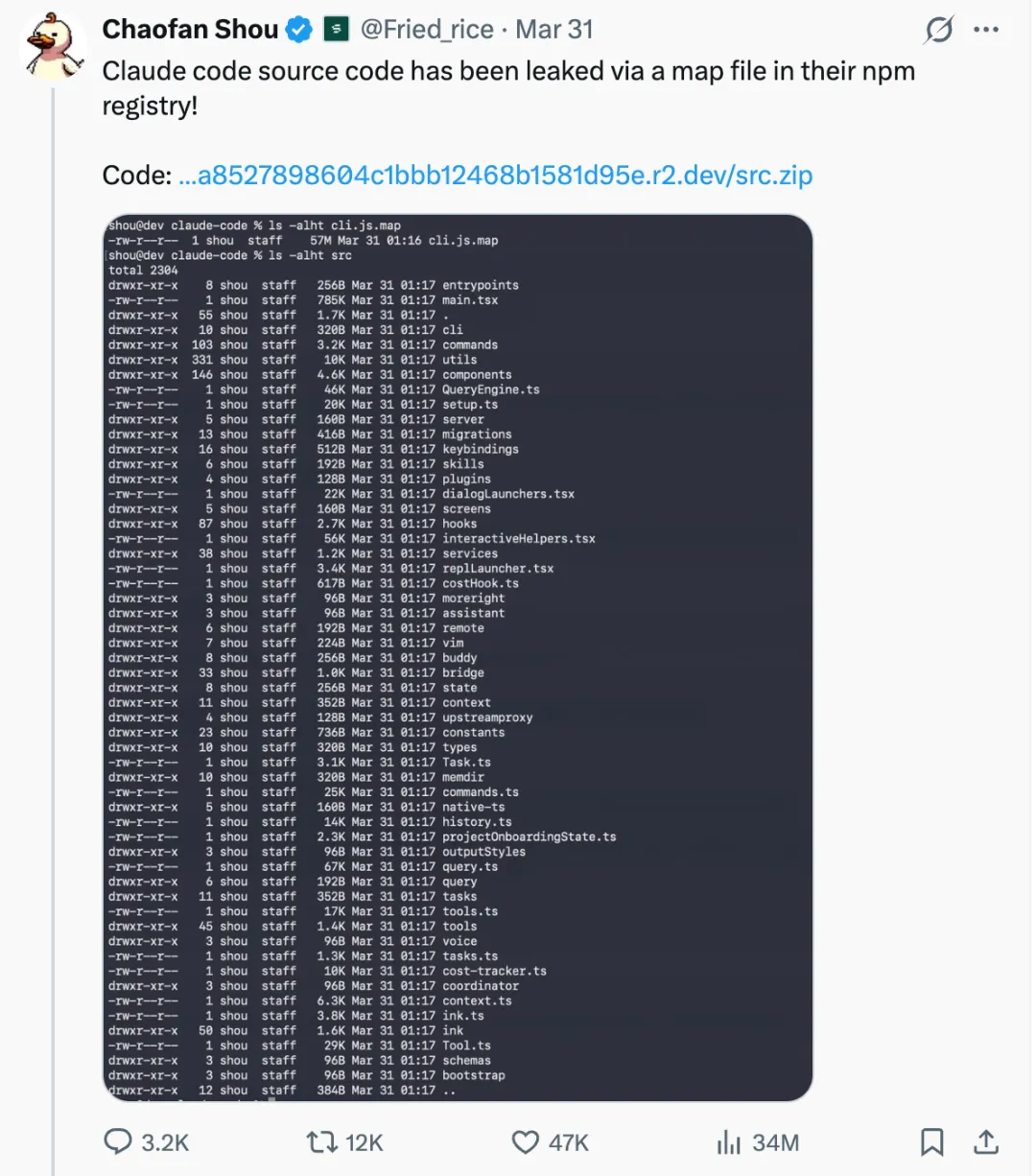
几乎是在同一时间,GitHub 上另一个仓库也悄悄爬上了热榜 —— claude-code-best-practice,Star 一路涨到 3 万+。从基础用法到进阶工作流,围绕 ClaudeCode 的各种实践被系统性地整理出来,甚至一度登上 Trending 日榜第一。
一边是“源码级围观”,一边是“玩法速成手册”。
这波热度,不只是围绕一个产品,更像是一场关于AI 编程到底能做到什么的集体讨论。而这场略带黑色幽默的事件,也意外带来了一个很有价值的结果:它让所有人都有机会,从隔着屏幕的外部使用者变成看透底层的内部观察者。
也正是在这轮密集的讨论中,一个微妙但真实的现象开始浮出水面:一边是行业内对其能力的高度认可,“这个方向没跑了,AI 编程就该是这样”;而另一边,则是越来越多一线使用者的实际反馈“看着确实惊艳,但自己上手用起来,总是差那么点意思”。
不是不会用,也不是完全跑不起来。而是总有某一步,会让流程停住。可能是中间断掉的一次执行,也可能是一个没有被接住的错误,又或者只是一次不稳定的输出。这些看似细碎的问题,叠在一起,就变成了一种越来越普遍的体验:
👉 演示很顺,实操有阻力。

而这种从“惊艳”到“卡顿”的落差,也逐渐被更多人意识到——它不是个例,而是一个正在被反复验证的共性问题。
从“惊艳演示”到“真实使用”,
中间到底发生了什么?
ClaudeCode 的火,当然不是偶然,它真正打破了大家对AI编程的固有认知:AI 不再只是帮你写一段函数、补全几行逻辑的辅助工具,而是开始真正可以帮你把一整件事跑完。
过去,我们用 AI 编程,更多的是“人写框架,AI 填细节”;现在,有了 ClaudeCode 这类工具,逻辑变成了“人提目标,AI 跑全程”。这种从片段辅助到全流程接管的变化,是质变级的突破。而这次代码泄露,也从侧面印证了它的硬实力——完整的工具链、严谨的权限控制、成熟的多智能体协作逻辑,绝非简单的功能拼接,背后是一套系统化的技术沉淀。
但问题也恰恰出在这里:ClaudeCode 向我们展示的,是能力成立的理想状态,而大多数人面对的,多数是充满不确定性的真实使用环境。
一旦离开理想环境,体验就开始分叉
不少人第一次接触到 ClaudeCode 这类工具,都是在博主演示或各类技术分享的场景里:模型能力拉满,上下文完整无断层,执行链路顺畅丝滑。那一刻的体验,很容易让人产生一种错觉:只要说出目标,就能坐享其成。
可当你再把它拉回自己的电脑和开发场景里,一切就变得不那么丝滑了:或许是你的笔记本性能有限,跑不起动辄几十 GB 的大模型;又或许是你习惯用开源模型替换官方模型,导致功能衔接出现断层;还可能是开发环境配置特殊,工具无法适配;但其实更常见的是,执行过程中一旦出现一点小错误,工具就无法自动衔接,只能中断等待人工介入。
被低估的核心难点:把一整件事“跑完”
在 AI 编程的讨论热潮中,大家一开始都在盯着生成能力,谁能写出更精准的代码,谁能处理更复杂的逻辑,谁的上下文更长。但用得越多,越能发现一个被忽略的真相:真正难的,从来不是生成代码,而是把整件事完整跑完。
这背后,藏着一套看不见的能力要求:任务能不能被合理拆解成可执行的步骤?每一步之间能不能无缝衔接?出错之后能不能自动诊断、修复?中断之后能不能续上进度、继续推进?
如果这些环节都需要频繁的人工介入,那所谓的“AI 辅助”,就会变成 AI 帮你做一半,你自己补一半。这也是为什么很多人会有这样的感受:ClaudeCode 已经很强了,但还不够“省心”——它能帮你减轻负担,却无法让你真正脱手。
AI 编程的“第二阶段”,已经来了
如果我们简单梳理一下这一轮 AI 编程的发展脉络,就能清晰地看到一个关键转折:AI 编程正在从“第一阶段”,正式迈入“第二阶段”。
第一阶段,是“能力展示期”。大家比拼的核心,是谁更强——谁能处理更复杂的需求,谁能写出更优质的代码,谁的技术参数更惊艳。这个阶段,解决的是“AI 能不能做编程”的问题。
而现在,行业正在进入第二阶段——“工程落地期”。比拼的核心,已经从“谁更强”变成了“谁更好用”:谁能在普通人的设备上稳定运行,谁能在复杂的真实场景中把事情做完,谁能真正降低用户的使用门槛。这个阶段,解决的是“AI 编程能不能落地到每个人手里”的问题。
很明显,行业讨论的重心,正在悄悄转移:从“这个模型有多强”,变成“这个东西我能不能用起来”。而围绕这个重心,一些新的行业趋势,已经开始浮现。
不堆模型,只补“落地能力”
为了弥合“演示效果”与“真实体验”之间的差距,越来越多的团队开始跳出“堆模型、拼参数”的内卷,转而往工程层补充能力——毕竟,再强的模型,落不了地,也只是空中楼阁。
目前,几个清晰的趋势已经显现:
一,更贴近真实环境的模型策略。不再执着于单一的强模型,而是支持多种模型组合,包括各类开源模型,让工具能够适配普通人的笔记本、办公电脑,实现本地运行,摆脱对高端设备和云端算力的依赖。
二,从“生成结果”走向“执行过程”。不再只关注最终输出的代码质量,而是聚焦整个执行流程:从任务拆解、步骤执行,到结果校验、错误修复,再到中断续跑,每一个环节都追求稳定可靠。
三,把“稳定性”当成核心能力。那些看似不“惊艳”,却能提升使用体验的细节,正在成为竞争的关键——比如输出格式的自动约束与修复、多轮执行中的偏差控制、中间错误的诊断与恢复。这些能力,直接决定了一款 AI 编程工具,能不能被用户长期使用。
从“工具”到“执行系统”,AI 编程的评价标准变了
而回头看这几年 AI 编程的发展,能发现一个很有意思的转变:AI 正在从写代码的工具,逐渐变成参与全流程执行的系统。这种转变,直接重塑了大家对 AI 编程工具的评价标准。过去我们评价一款 AI 编程工具,问的是“它能写多少代码?”“写得够不够好?”;而现在,大家更关心的是“它能不能把事情做完?”“用起来够不够省心?”。
这两者之间,差的可不是一点点模型能力,而是一整层系统级的设计。它需要兼顾兼容性、稳定性、易用性,需要真正站在用户的真实场景里,解决那些“卡壳”的小问题,弥合演示与现实的落差。
4.18 AtomCode 开源发布
& 线下 Developer Day 来袭
正是看到了这种行业趋势,也希望解决普通人使用 AI 编程工具的“卡壳”困境,聚焦真实工程场景的 AI 编程工具AtomCode 将于 4 月 18 日正式开源,并同步举办线下 Developer Day。
项目基于 Rust 构建,支持包括 DeepSeek、Qwen、智谱在内的多种主流大模型,以端侧 & 本地化算力最优解为核心设计,更强调“执行过程”的稳定性:通过任务规划、执行链路控制以及对异常情况的处理机制(如结构修复、诊断压缩等),让模型不仅能生成结果,也能尽可能把流程走完。彻底摆脱对高端设备与云端算力的依赖,普通开发者仅通过本地部署 DeepSeek/ Qwen 或边缘算力,即可流畅完成复杂工程开发,让 AI 编码真正轻量化、私有化、可落地。
⚡️AtomCode 与 Claude Code 对比
相同模型基准测试 基于真实编程任务测量

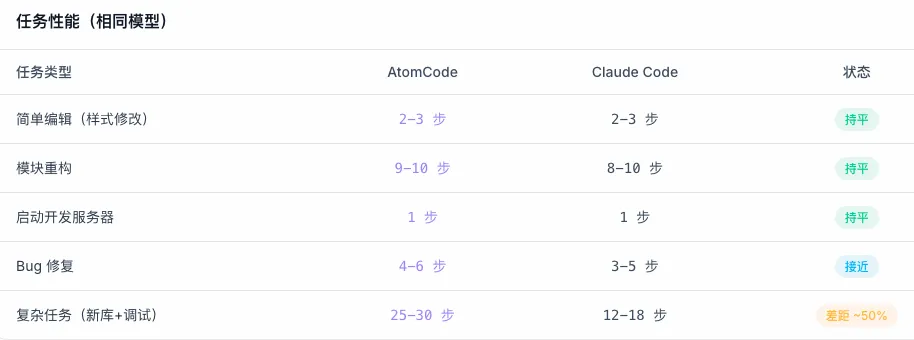




这次,我们想看看在有限算力、本地环境下,AI 能不能把一件开发任务稳定推进下去?活动将基于真实场景进行验证与交流。现场模型厂商、开发者与技术博主将齐聚一堂, 一起讨论 AI 编程在工程落地中的边界与可能性。欢迎感兴趣的开发者们来线下面基。

现在报名成为 AtomCode 首批内测体验官
即可解锁三大专属权益:
✅ V0.1 版本优先体验:抢先获取内测专属通道,第一时间上手核心功能,同步解锁多重活动福利。
✅ 专属硬核算力支持:首批开发者将获得高配 NPU 算力扶持,AI 编程无需等待、灵感极速落地,彻底告别算力焦虑。
✅ 限量「赛博极客」定制周边:完成首次深度体验并提交有效反馈,即可领取 AtomGit 限定周边礼包,数量有限,先到先得。
诚邀硬核开发者们一同参与,共同打磨真正工程级的 AI 编码工具。

想第一时间上手?加代码君备注AtomCode体验官
互动讨论:
你用 AI 编程时,最在意什么?
最后,想问问正在使用 AI 编程工具的你:一款好用的 AI 编程工具,更应该具备超强的生成能力,还是更稳定的执行过程?
这些看似细碎的体验,或许正是 AI 编程第二阶段,我们需要共同解决的核心问题。欢迎在评论区留下你的经历与观点,一起探讨 AI 编程的未来方向。

推荐阅读

4.18 AtomCode 开源!让小模型,也能写出“大工程”

