 夜雨聆风
夜雨聆风
你有没有这种体验。
每次新开一个对话,都要从头告诉 AI 你是谁。项目怎么跑。偏好什么风格。
它不记得你上周让它修过的那个 bug。不知道你在 Telegram 上聊过的那些需求。
关掉窗口。一切归零。
Hermes Agent[1] 试图解决的就是这件事。
Nous Research 开发。MIT 协议。GitHub 40K Star。v0.8.0。迭代极快,v0.7.0 到 v0.8.0 只隔了5天,合并了209个 PR。
它不是又一个 ChatGPT wrapper。是一个能长期驻留、持续学习、跨平台工作的个人 AI agent。
核心卖点一句话。它能记住你。
但「记住你」只是表面。底下是一个闭环的学习系统。
记忆、技能、定时任务、消息网关。四个核心能力。每一个都有设计意图。
先说清楚一个区分。记忆和技能不是一回事。
Memory 存的是「what」。事实。你的环境、偏好、项目位置、agent 学到的关于你的东西。
Skills 存的是「how」。流程。多步骤的操作手册、工具特定的指令、可复用的配方。
记忆回答「你是谁、项目是什么」。技能回答「遇到这种任务怎么做」。
先说记忆。
Hermes 的记忆不是「把聊天记录存下来」。是两个精心设计的文件。
MEMORY.md 是 agent 自己的笔记。环境信息、项目约定、踩过的坑。上限2200字符。
USER.md 是关于你的档案。偏好、沟通风格、技术水平。上限1375字符。
每次新会话启动时,这两个文件注入到 system prompt 里。agent 在对话中可以随时更新它们。但更新后的内容要到下一次会话才生效。
为什么不立即生效。想了想。是为了保持 LLM 前缀缓存的性能。如果每次更新记忆都重新构建 system prompt,缓存就失效了。
还有一个 nudge 机制。每隔 N 轮对话,系统会主动提醒 agent「想想有没有什么值得记住的」。不依赖 agent 自觉。
记忆快满时,agent 需要自己决定合并还是替换旧条目。好的记忆条目应该把多个相关事实压缩在一起。这是一个有意思的设计。让 AI 自己管理自己的记忆容量。
除了主动记忆,还有一个 session_search 工具。基于 SQLite FTS5 全文检索。你可以让它去翻过去的对话。「上周我让你写的那个部署脚本,帮我找出来。」
还有一个贯穿整个架构的性能考量。Prompt Cache。
大多数 LLM 提供商会缓存 system prompt 前缀。如果你保持 system prompt 稳定(同样的上下文文件、同样的记忆),后续消息会命中缓存,显著降低成本。
这就是为什么记忆更新延迟生效。为什么不要在会话中途换模型。为什么 SOUL.md 要控制长度。所有这些设计都是为了保持前缀缓存的命中率。
还有一个设计值得单独说。execute_code。
普通的「让 AI 跑命令」是一个个执行,每次结果都进入 LLM 上下文窗口。10个命令就是10轮对话。
execute_code 不一样。agent 写一段 Python 脚本,脚本内部通过 RPC 调用 Hermes 的工具。中间结果不进入上下文窗口。只有最终结果回来。
零上下文成本的批量操作。对数据处理、批量文件操作这类场景很实用。
再说技能。
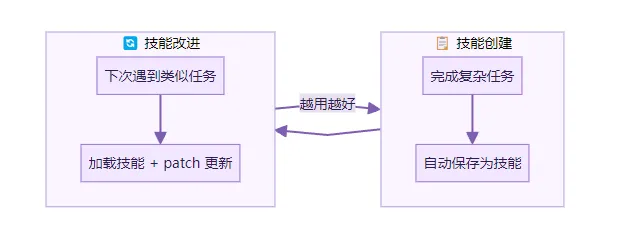
当 agent 完成一个复杂任务(比如用了5个以上工具调用),它会考虑把这个流程保存为技能。下次遇到类似任务,直接加载。不用重新摸索。
技能还能自我改进。每次使用时,如果发现新的坑或更好的做法,agent 可以 patch 更新已有的技能文件。
这是一个闭环。做任务 → 保存技能 → 下次加载 → 发现改进 → 更新技能。越用越好。
从 GitHub 上看到,技能加载用了三层渐进式机制。先读元数据(判断是否触发),再读完整技能(具体怎么做),最后才读参考文件(补充资料)。只在需要时才占用 token。
还有一个 Skills Hub(agentskills.io)。在线技能市场。可以搜索和安装社区贡献的技能。
消息网关是另一个让我觉得有意思的设计。
Hermes 不只是一个 CLI 工具。通过 gateway,你可以从 Telegram、Discord、Slack、WhatsApp、Signal、飞书、钉钉、企业微信等14个以上的平台跟它对话。
在手机上用 Telegram 给它发一条消息。它就能在你的云服务器上执行命令、查日志、跑部署。出门在外也能远程操作。
安全模型上有一个设计让我印象深。DM 配对码。未知用户给 bot 发消息时会收到一个一次性配对码。你在终端批准。配对码1小时过期,密码学随机数生成。不需要提前知道用户的 platform ID。
定时任务用自然语言创建。
/cron add "every 2h""检查服务器状态,如果有异常发 Telegram 通知"
任务在独立的 agent session 里运行。不影响主对话。结果投递到任何已配置的消息平台。
终端后端是六种。Local、Docker、SSH、Modal、Daytona、Singularity。
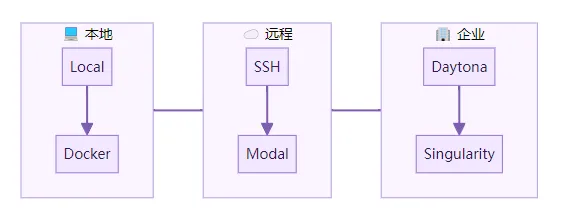
Modal 和 Daytona 是无服务器方案。空闲时不计费。用时自动拉起。这对「agent 常驻但不总是在干活」的场景很实用。
想了想。Hermes 和 OpenClaw 的关系很有意思。
两者定位高度重叠。都是开源 AI Agent。都支持多平台消息网关。都有记忆和技能系统。Hermes 甚至内置了从 OpenClaw 迁移的工具。hermes claw migrate 一键导入。
但 Hermes 在几个地方做了差异化。
记忆的 nudge 机制。不依赖 agent 自觉,系统主动提醒。
技能的自动创建和自我改进。不只是静态配置,是运行时的动态行为。
Smart Model Routing。简单问题自动走便宜模型,复杂任务走主力模型。
六种终端后端。从本地到 HPC 集群。
Pluggable Memory Provider。v0.7.0 引入了插件化记忆后端。Honcho、Mem0 等第三方方案可以接入。
从 GitHub 上看到,项目结构很清晰。agent/、gateway/、cron/、skills/、tools/、plugins/ 各司其职。3537 commits。迭代速度很快。
Hermes 的本质是什么。
不是一个聊天工具。是一个能「住下来」的 AI。
住下来的意思是。它记得你。它从经验中学习。它在你不盯着的时候也能干活。它不绑定在你的终端里,你在任何平台都能找到它。
大多数 AI 工具是「用完就走」的。你打开,用,关掉。下次再打开,从零开始。
Hermes 想做的是「住下来」。每次对话都在上一次的基础上。技能越用越好。记忆越来越完整。
这和 Karpathy 的 LLM Wiki 思路一样。知识不蒸发,而是持续积累。
Karpathy 悄悄发了个文件,指出了所有 AI 知识库的同一个 Bug
只不过 LLM Wiki 积累的是文档知识。Hermes 积累的是关于你的一切。
开源地址:github.com/NousResearch/hermes-agent[2]
文档:hermes-agent.nousresearch.com/docs[3]
Skills Hub:agentskills.io[4]
Hermes Agent: https://github.com/NousResearch/hermes-agent
[2]github.com/NousResearch/hermes-agent: https://github.com/NousResearch/hermes-agent
[3]hermes-agent.nousresearch.com/docs: https://hermes-agent.nousresearch.com/docs/
[4]agentskills.io: https://agentskills.io
下方是赋能君的AI学习交流永久免费星球,想学习更多内容,欢迎扫码加入。

🙌 如果你阅读到这里,说明我们对信息的认可区域是有一定交集的,可以说我们是同道中人,所以如果你有自认为不错的信息获取渠道,欢迎留言或者私聊我,谢谢。
都看到这里了,就给个关注吧👀:
喜欢我的文章,可以请你右下角顺手来一波点赞&在看&分享三连么👉
