 夜雨聆风
夜雨聆风
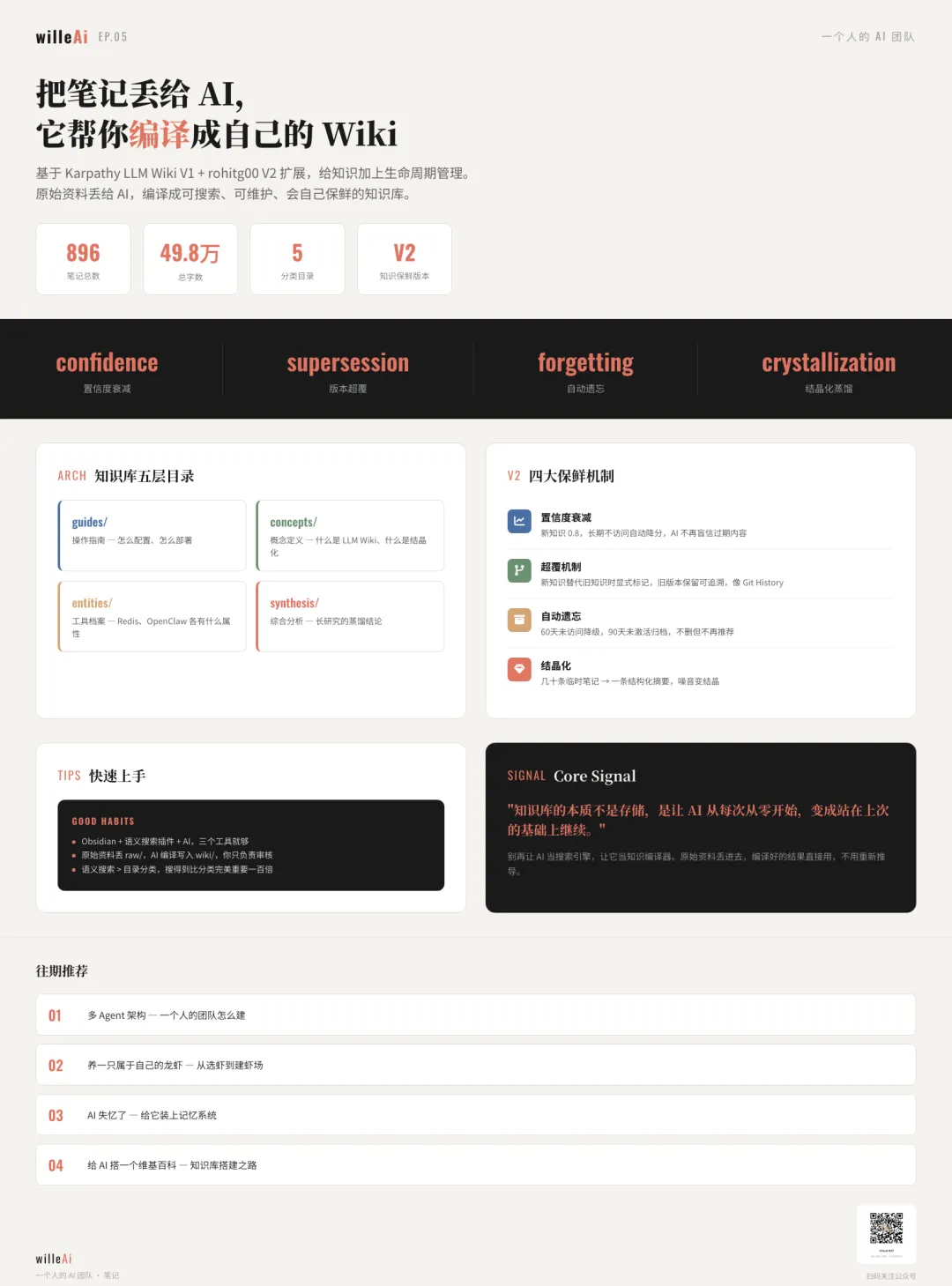
核心思路:别再让 AI 当搜索引擎,让它当知识编译器。
原始资料丢 raw/,AI 读完后提炼核心结论写入 wiki/,下次直接用编译好的结果,不用重新推导。
搭完之后用了一周,效果确实好。但我也发现 V1 有几个没覆盖的问题——知识会过时、会重复、会冲突。
正好看到 rohitg00 做了 V2 扩展,他把这些盲区都补齐了。我落地之后用着非常爽,推荐你也试试。
◆rohitg00 是谁
他是 agentmemory 的作者——一个专门给 AI Agent 做持久记忆的开源项目。
跑了几千次 Agent 会话之后,他发现 Karpathy 的 V1 有一个根本问题:知识会腐烂。
V1 把所有知识视为永远等权有效。但实际上,三个月前的配置教程和昨天的排障结论,可靠程度完全不同。如果 AI 不区分地使用它们,迟早翻车。
所以 V2 的核心思路就是:给每条知识加上生命周期管理。
◆V2 加了什么
四个机制。我一个个说。
1. 置信度(Confidence)
每篇笔记加两个字段:
---confidence: 0.9last_confirmed: 2026-04-12status: active---
- confidence:0-1,新知识默认 0.8
- last_confirmed:最后一次被确认的时间
- status:active / draft / archived
简单粗暴但有效。AI 搜到 0.3 的知识,知道这玩意可能过时了,不会盲信。
2. 超覆(Supersession)
新知识替代旧知识时,旧版本不删,显式标记:
---supersedes: wiki/entities/旧方案.mdconfidence: 0.9last_confirmed: 2026-04-12---
旧条目还在,但 AI 搜到它时会看到提示:"此知识已被替代"。
本质上就是知识的版本控制。不丢历史,只标方向。
3. 遗忘(Forgetting)
设个规则,过期知识自动降级:
- active 超 60 天没被访问 → 降到 draft
- draft 超 90 天没被重新激活 → 移到 _archive/
不删,搜索引擎不再推荐。
理想方案是 Ebbinghaus 遗忘曲线,但计算成本太高,先固定天数顶着。能用。
4. 结晶化(Crystallization)
这个我最喜欢。
调试一个问题可能产生几十条临时笔记——报错截图、排查步骤、中间结论。调试结束后,让 AI 把这些笔记蒸馏成一条结构化摘要。
几十条噪音 → 一条结晶体。
写在 wiki/synthesis/ 目录下。以后搜结论直接搜到,不用翻几十条过程。
◆我现在的数据
896 篇是怎么来的?V1 重建时从 561 篇砍到 232 篇,然后这几周不断编译新资料进去,慢慢涨上来的。不是堆的,是 AI 一篇一篇编译的。
◆怎么落地(教程)
1.目录结构
知识库├── raw/ # 原始资料,只读,不改├── wiki/ # 核心知识层│ ├── guides/ 操作指南│ ├── concepts/ 概念定义│ ├── entities/ 工具/项目档案│ ├── synthesis/ 综合分析(结晶化产物)│ └── comparisons/ 对比评测├── _archive/ # 归档,搜索引擎不索引└── log.md # 变更日志,只追加
2.写笔记的标准格式---title: 页面标题created: 2026-04-12updated: 2026-04-12confidence: 0.8last_confirmed: 2026-04-12status: activetags: [标签1, 标签2]---正文内容...
3.目前我的笔记架构~/.openclaw/workspace/ ← Obsidian 知识库根目录(893 页,50 万字)│├── 📌 四核心层│ ├── raw/ (6) ← 原始资料,只读│ │ ├── articles/ ← 文章│ │ ├── papers/ ← 论文│ │ ├── repos/ ← 代码仓库│ │ ├── datasets/ ← 数据集│ │ └── llm-wiki-v2.md ← 本次新增的参考资料│ ││ ├── wiki/ (91) ← 核心知识层(LLM 维护)│ │ ├── _scratch/ (1) ← 🆕 工作记忆区(未验证内容暂存)│ │ ├── concepts/ ← 概念、经验教训、分析结论│ │ ├── entities/ ← 实体(工具、产品、系统)│ │ ├── guides/ ← 操作指南、技术文档│ │ ├── synthesis/ ← 🆕 结晶化摘要(研究过程蒸馏)│ │ ├── comparisons/ ← 对比分析与选型│ │ └── index.md ← 内容索引入口│ ││ ├── schema/ (3) ← 维护规则│ │ ├── SCHEMA.md ← 🆕 升级后含 P0+P1+P2 全部规范│ │ ├── MEMORY.md ← 团队共享长期记忆│ │ └── README.md│ ││ └── log.md ← append-only 变更时间线│├── 📁 辅助层│ ├── projects/ (93) ← 项目档案(7 个活跃项目)│ │ ├── openclaw/ ← OpenClaw 相关│ │ ├── willeai/ ← WilleAI 公众号│ │ ├── mac-mini-agent/ ← Mac mini Agent│ │ └── ...│ ├── content/ (39) ← 内容生产管道│ │ ├── blog/ published/ drafts/ ideas/│ │ └── visual-references/│ ├── ops/ (18) ← 运维记录│ │ ├── incidents/ ← 故障报告│ │ ├── changelogs/ ← 变更日志│ │ └── reports/│ ├── journal/ (5) ← 日报复盘│ └── 08-日报复盘/ ← 旧目录(待清理)│└── _archive/ (638) ← 归档(历史淘汰内容)
这是最好玩的部分。你不需要手动整理。
把资料丢进 raw/,然后告诉 AI:
读一下 raw/ 里新加的资料,提炼核心结论,编译写入 wiki/ 对应目录。
AI 会自动:
1. 读原始资料
2. 提炼关键结论
3. 加上 frontmatter(confidence、时间戳、标签)
4. 写入对应分类
你只负责审核。
5.搜索
Obsidian 装一个语义搜索插件(Arrowhead 或 Omnisearch),配置好之后直接搜。
语义搜索比目录分类重要一百倍。你不需要完美的文件夹结构,需要的是搜得到。
◆适合谁?
1. 用 AI 做事的人——不限于程序员,运营、设计、写作都行
2. 笔记很多但从来不翻的人——编译之后存了就能搜到
3. 有多个 AI 协作的人——共享知识比各自为政强太多
不需要复杂工具。Obsidian + 语义搜索插件 + 一个能帮你写笔记的 AI,就够。
◆局限性
维护成本高。 知识库不是建完就完事,需要 AI 持续编译更新。
编译质量依赖 LLM。 简单知识没问题,复杂推理偶尔编译出错误结论。
衰减用固定阈值。 没上 Ebbinghaus 曲线,粗暴。但能用,比没有强。
◆原文链接
强烈建议读原文,都是 GitHub Gist,直接复制丢agent读:
- Karpathy V1:
git@gist.github.com:442a6bf555914893e9891c11519de94f.git- rohitg00 V2:
git@gist.github.com:2067ab416f7bbe447c1977edaaa681e2.git到这里,AI 团队有了记忆、有了知识库,知识库还会自己保鲜。
一张图总结:
往期推荐:
