 夜雨聆风
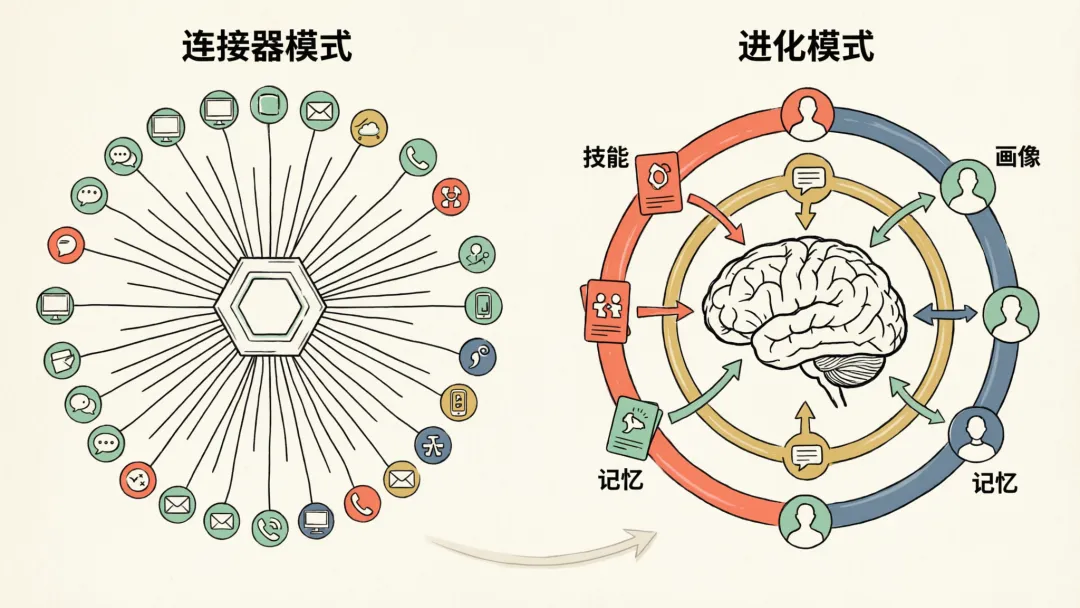
夜雨聆风OpenClaw 是目前最火的开源 AI 助手,35 万 Stars,130 多个扩展模块,社区贡献源源不断。想连什么平台、想加什么能力,基本都能找到现成的。
但不管用了多久,它对你的理解基本不会变。你的偏好要反复交代,纠正过的问题下次还犯。说到底,它是一个功能很强的工具箱——而工具箱不会因为你多用几次就更懂你。
Hermes Agent 走了另一条路。Nous Research 今年初开源,几周拿下 4.5 万 Stars。功能数量比不上 OpenClaw,但它在做一件不同的事:每次合作都在积累经验、更新记忆、琢磨你的习惯。用得越久,越顺手。
具体怎么做到的?一起看看。
第一层:自己学会新本事
大多数 Agent 的 Skill(技能)系统都是单行道——开发者写好、发布到生态、Agent 调用。OpenClaw 把这条路走得很成熟:130 多个 extension,社区源源不断地贡献新工具,模块化做得干干净净。但工具一旦发布就是固定的,不顺手也不会自己改。
Hermes 的技能不是别人塞给它的,是它自己干活干出来的。
触发条件挺明确:一次工作流只要涉及 5 次以上工具调用、出过错要重来、你纠正过它、或者撞出了非常规解法,系统就会自动把这次经验提炼成一个可复用的 Skill。下次碰到类似问题,直接套用,不用从头推理。
更新方式也聪明。它不会推翻重写,而是用 patch 操作——只改出问题的那部分,已验证的好做法保留。像一个搭档在老经验上做微调,不是每次从零开始。
这些 Skill 遵循 agentskills.io 标准,已经被 11 个主流工具采用——Claude Code、Cursor、GitHub Copilot、Gemini CLI、VS Code 都在用。搭档学到的东西不光自己受益,整个生态都能拿去用。
第二层:五层记忆,从"记住"到"懂你"
OpenClaw 有跨会话的持久记忆和偏好配置——你告诉它,它就记住。你不说,它就不知道。这是便签式的记忆,被动、显式,全靠你主动配置。
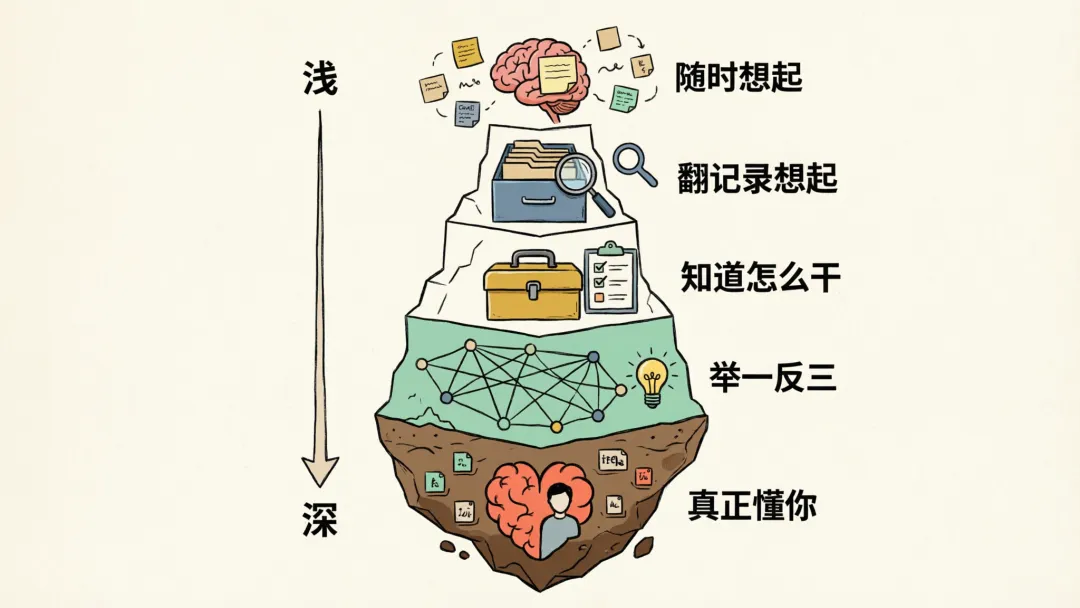
Hermes 的记忆不在便签上,在脑子里。它有五层认知,从表层到深层——像一个搭档从"记得你说的话"慢慢变成"真正懂你这个人"。
第一层:张口就来的事。 MEMORY.md、USER.md、SOUL.md 三个文件每次对话自动加载。容量故意做小,只给 3,575 字符——逼它只记最核心的那几条。
第二层:翻翻记录能想起的事。 每次会话写进 SQLite,用 FTS5 全文索引。不会自动灌进上下文,但需要时能检索,还会让 LLM 先摘要再用。三个月前的对话,你一提,关键细节很快回来了。
第三层:知道怎么干活。 Skill 系统本身就是一种记忆——"这类问题该怎么处理"。默认只记要点,真用的时候才展开完整步骤。
第四层:举一反三。 所有技能和文档都做了向量化语义索引。你描述一个新问题,哪怕用词完全不同,Agent 也能联想到最相关的老经验。
第五层:真正懂你。 最深的一层。Hermes 集成的 Honcho 框架是一套辩证推理系统——每次对话后自动分析,跨 12 个维度琢磨你的偏好、习惯和目标。它提供四个工具:honcho_search(搜历史)、honcho_context(辩证查询)、honcho_profile(画像)、honcho_conclude(沉淀结论)。写入是异步的,完全不卡主对话。
结果就是:你是资深后端工程师?它不会多嘴解释 REST API。你是第一次碰 React 的 Go 开发者?它会自然地拿后端概念类比前端。这种默契不是你教出来的,是它自己悟出来的。
一个小细节:记忆召回时用 XML fence(<memory-context>)包着,防止模型把回忆内容误读成当前指令。小地方,大讲究。
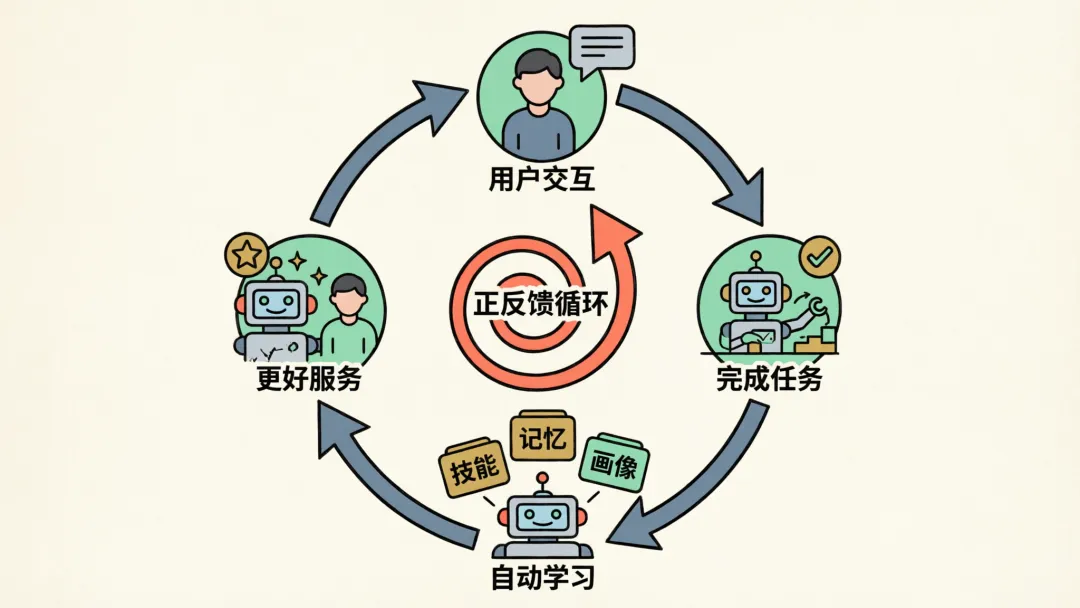
五层叠加,构成一个正反馈循环:
你交代任务 → 搭档完成 → 自动总结经验 + 记住要点 + 更新对你的理解 → 下次更默契
这一切都不用重训模型。纯粹靠积累经验和理解你来变强。
第三层:下班后还在练
前面说的五层记忆和 Skill 积累,是 Hermes 在工作中的日常成长——每天变强一点,但"大脑"本身没变。而 RL 训练飞轮(Reinforcement Learning,强化学习——简单说就是让 AI 从自己的工作经历中"练级")是另一回事:不光积累经验,还真的让模型变聪明。
打个比方:日常成长像一个员工攒了越来越多的笔记和模板,干活越来越熟练;RL 飞轮像这个员工回去读了个在职研究生——脑子本身升级了。OpenClaw 在这个维度上是空白。
每次干活都是素材
Hermes 会把每次干活的完整过程录下来——你说了什么、它怎么想的、调了哪些工具、结果是什么——全部按标准格式存好。不是随便记的流水账,是结构化的"教学案例":
用户指令 → 模型推理(含 <think> 标签)→ 工具调用 → 工具结果 → 最终回复每一条都是一次完整的"做对了什么、做错了什么"的案例,可以直接拿来训练下一代模型。
会剪辑的轨迹压缩器
但原始记录太长了——一个复杂任务动辄几万字。trajectory_compressor.py 负责"剪辑":把冗余部分去掉,只留关键决策点、出错怎么救回来的、为什么中途换了方向。就像写复盘报告——不记流水账,只提炼最值钱的经验。
Atropos + Tinker:双引擎
真正干"练级"这件事的是两个组件:Atropos 负责出题和评分(管训练环境和评估,能协调上千个 worker 同时干活);Tinker 负责"改大脑"(更新模型权重,用的是 GRPO 算法 + LoRA 微调,最多 2,048 路并行训练)。
Hermes 4 的训练中,Atropos 出了约 1,000 种不同类型的考题,只有答得好的案例才会被选中用来"练级"——质量把关很严。
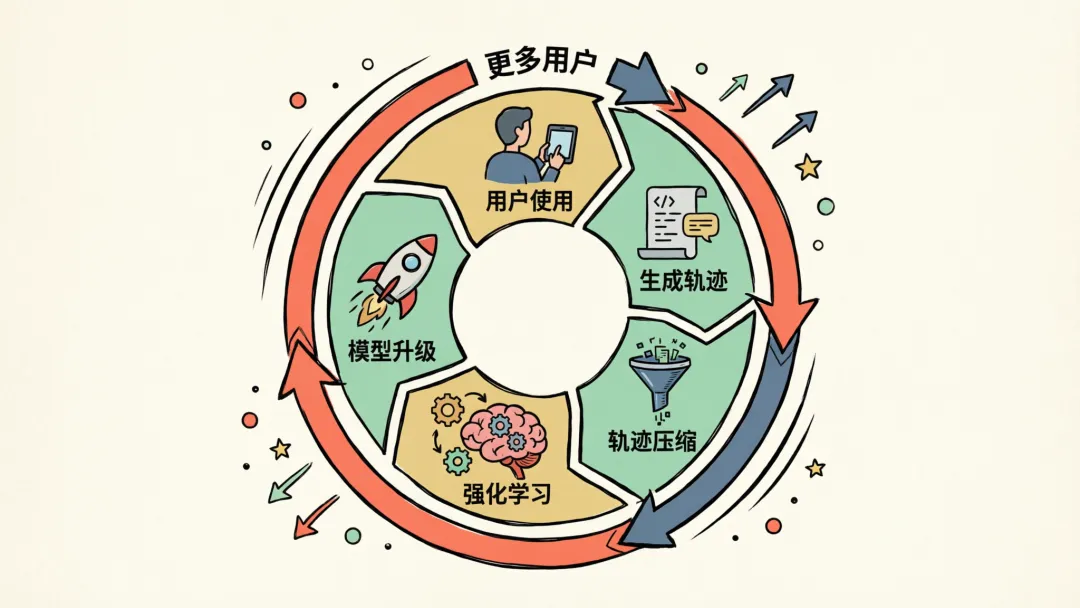
整条链路就是"干活 → 复盘 → 变强"的循环:
用户使用 → 产生工作记录 → 压缩后喂 RL 训练 → 训出更强的模型 → 干活更好 → 更多人用 → 更多素材
这就是飞轮。干得越多转得越快。
第三条进化路径:GEPA
Hermes 还有一个独立进化项目叫 hermes-agent-self-evolution,用 GEPA 算法(你可以理解为"让 AI 自己找自己的 bug,然后自己修")自动优化 Agent。不只是发现哪里做错了,而是分析为什么做错,然后提出针对性改进。每次改进要过严格门禁——测试全过、大小合规、语义不变、人工审核——全过了才算数。
最实惠的是成本——跑一轮优化只要 $2-10,不用 GPU。小团队也玩得起。
飞轮的硬前提
这套打法不新鲜。Tesla 用自动驾驶数据做的是这事,GitHub Copilot 用代码补全历史做的也是这事——产品即工位,用户即导师。这也是 Nous Research 开源 Hermes 的真正原因:把搭档放到活最多的地方去。
但飞轮有个硬前提。Hermes 的轨迹记录默认是关着的,飞轮的威力完全取决于有多少用户主动开启。如果大多数人选择不贡献数据,飞轮转不起来。这个问题,Nous Research 得持续作答。
第四层:能分工,能出差,还会省钱
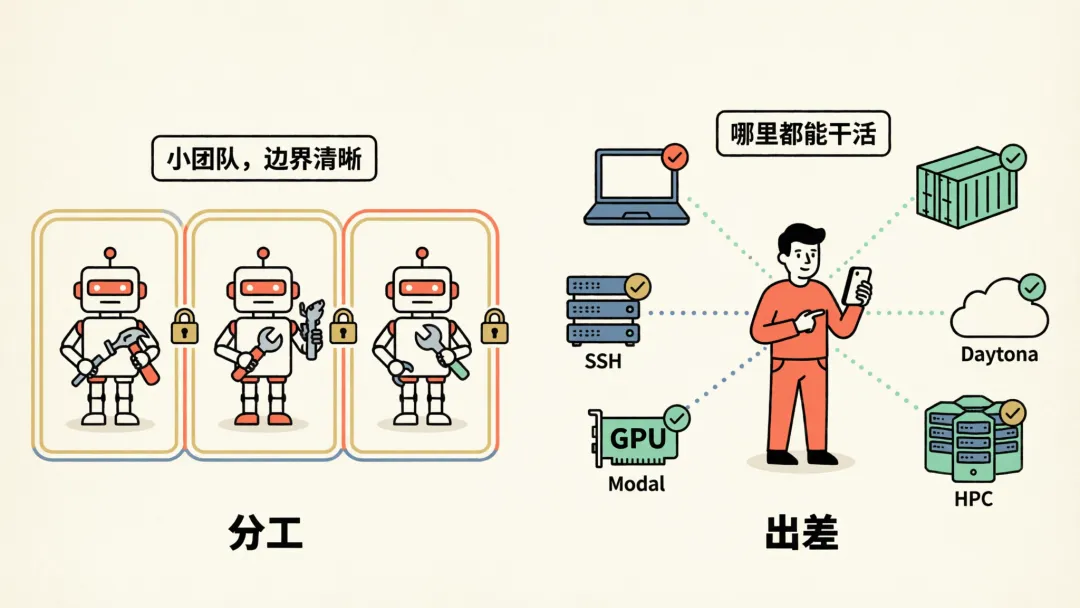
分工
OpenClaw 的多 Agent 协同是它的强项之一——多个 Agent 各司其职,Agent 编排层跟 Skill 框架深度绑定,可以搭出挺复杂的自动化流水线。但 Agent 之间通信链路越多,安全面也越大。
Hermes 走小分队路线:每个子 Agent 独立上下文、独立工具集、独立终端会话。禁止递归委派、禁止写共享记忆、禁止发消息到外部。最多 3 个并发,最多嵌套 2 层。人少,但每个人职责边界清清楚楚——能力隔离 + 预算约束,自主干活又不越界。
出差
Hermes 支持 6 种执行后端:本地、Docker(生产级隔离)、SSH(跨会话持久远程环境)、Daytona(无服务器开发环境)、Singularity(HPC 集群)、Modal(无服务器生产,支持休眠/唤醒)。统一实现 BaseEnvironment 接口,切换零改动。
你在手机上用 Telegram 发消息,Agent 在云端 VM 上干活——哪里都能办公,闲时零成本休眠,要用秒级上线。OpenClaw 主要在本地环境或 Plugin 调外部 API,灵活性差一截。
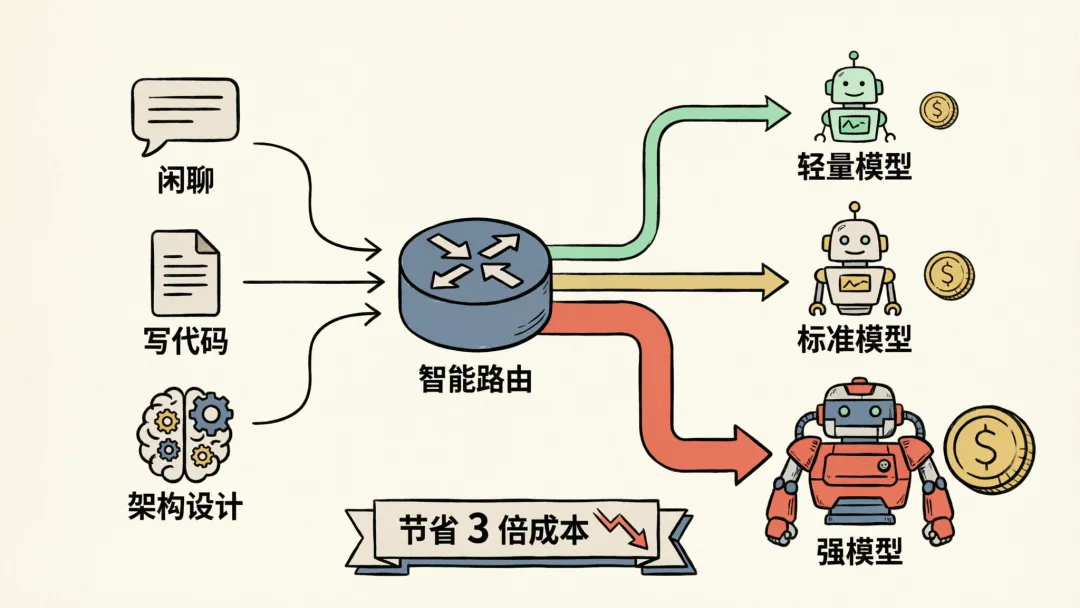
省钱
smart_model_routing.py 根据任务复杂度路由——闲聊丢给便宜模型,debug、refactor、架构这类重活才用强模型。每月 API 成本能省约 3 倍。OpenClaw 有 model failover,但没有基于任务复杂度的智能路由。
拆完了,怎么看?
总结一下 Hermes 的四层成长机制:
1. Skill 自生长——干活中自动提炼经验,patch 更新,还能跨工具共享
2. 五层记忆——从肌肉记忆到深层理解,越用越懂你
3. RL 数据飞轮——把工作记录变成训练素材,系统性地升级模型本身
4. 执行层设计——安全隔离的子 Agent、6 种远程后端、智能省钱路由
OpenClaw 在工具丰富度和社区生态上依然领先,这一点毫无疑问。但 Hermes 切入的角度不一样——它赌的不是"谁的工具更多",而是"谁能越用越强"。
这个赌注能不能成立,取决于飞轮能不能转起来。轨迹记录默认关闭,数据全靠用户 opt-in。如果大多数人不开,飞轮就是停着的。
但如果转起来了,这种优势很难被追上。工具可以被更好的工具替代,但磨合出来的默契没有捷径。
瑞士军刀再好,用一百次还是同一把刀。一个好搭档,合作一百次之后,已经是一个完全不同的人了。
