 夜雨聆风
夜雨聆风一、研究背景
这篇论文由NVIDIA团队提出,核心目标是打造面向物理世界的多模态大模型,让AI不仅能看懂视频画面,还能理解真实世界的物理规律,并且为机器人、自动驾驶车辆等具身智能体做出符合物理规则的决策。
当前主流的大语言模型和多模态模型,在数学、代码、文本推理上表现优秀,但存在一个核心缺陷:缺乏真实物理世界的落地能力。它们能背诵物理知识,却无法把知识和视频里的物体运动、空间关系、时间顺序结合起来,更无法指导智能体在现实中完成动作。
而物理AI需要完成两件核心事:第一,具备人类一样的物理常识,知道重力、物体永存性、时间不可逆这些基础规律;第二,具备具身推理能力,能根据环境感知、预测动作后果、遵守物理约束。这篇论文就是围绕这两个能力,构建模型、数据、评测体系,最终提出Cosmos-Reason1系列模型。
二、物理AI推理的核心能力定义
论文先明确了物理AI必须具备的两类核心推理能力,并且用本体论(可以理解为标准化的能力分类框架)把能力拆解清楚,为后续建模、数据、评测提供统一标准。
(一)物理常识推理
物理常识是和具体智能体无关的、对物理世界的基础认知,是所有具身智能的基础。论文把它分成三大维度、16个细分子类:
- 空间维度
:判断物体的空间位置关系、某个空间摆放是否合理、物体能用来做什么、场景环境特征。 - 时间维度
:理解动作内容、事件发生的先后顺序、因果关系、相机运动、基于观察做未来规划。 - 基础物理维度
:识别物体属性(质量、材质、温度)、物体状态变化(生鸡蛋变熟鸡蛋)、物体永存性(被挡住的物体依然存在)、力学/电磁学/热力学规律,以及识别反物理现象(反重力、时间倒流)。
简单来说,物理常识就是让AI知道“苹果会往下掉、杯子倒了水会流出来、视频倒着放不符合现实”。
(二)具身推理
具身推理是智能体和物理世界交互时需要的推理能力,和机器人、自动驾驶、人类等具体载体绑定,核心有四个要求,论文重点研究前三个:
- 处理复杂感知输入
:从视频这类原始、模糊、不完整的感官数据里提取有效信息。 - 预测动作效果
:知道做一个动作会产生什么物理后果,比如机器人抓物体要预估重量,避免抓坏或掉落。 - 遵守物理约束
:动作必须符合惯性、摩擦力、材质等现实规则,保证安全、稳定执行。 - 从交互中学习
:根据环境反馈调整行为,论文把这部分作为未来工作。
论文把具身推理的能力和智能体类型做成二维框架,覆盖人类、机械臂、人形机器人、自动驾驶汽车等,确保模型能适配不同物理载体。
三、Cosmos-Reason1模型架构设计
论文提出两个规格的模型:Cosmos-Reason1-7B和Cosmos-Reason1-56B,采用解码器-only多模态架构,整体结构如图3所示,核心分为三部分:视觉编码器、投影层、大语言模型主干。
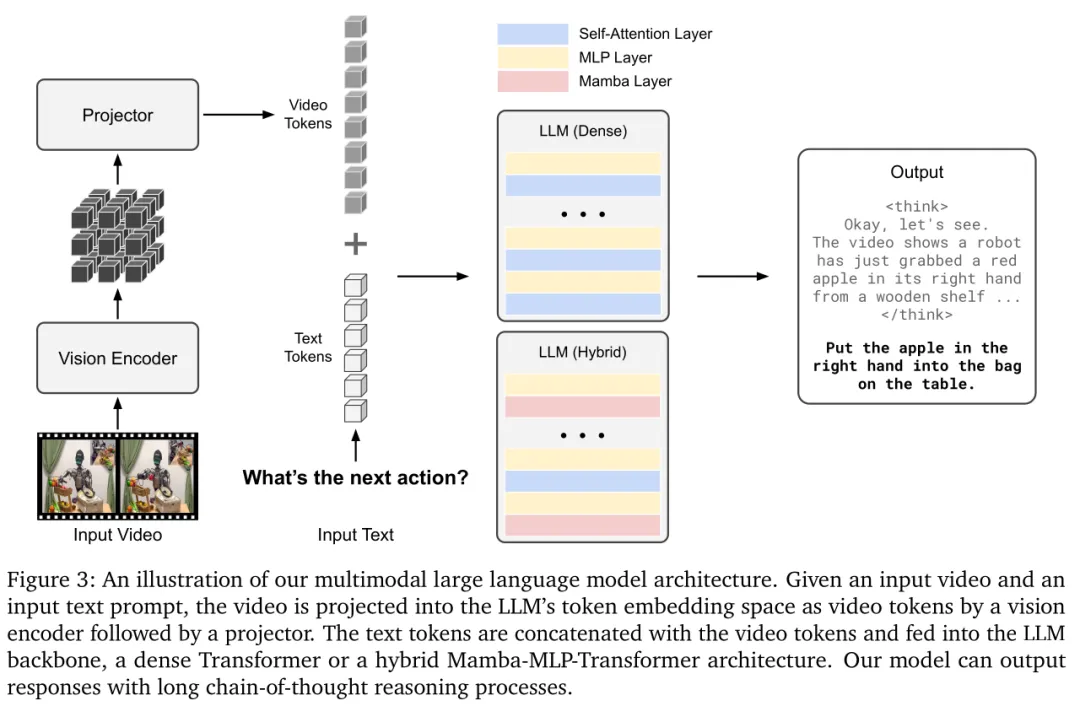
(一)整体架构逻辑
模型的输入是视频+文本指令,输出是长链推理过程+自然语言决策。处理流程是:
视频帧先进入视觉编码器,提取视觉特征; 投影层把视觉特征转换成和文本token对齐的向量,让大模型能“看懂”视频; 对齐后的视觉token和文本token拼接,输入大语言模型主干; 大模型先进行长链思考推理,再输出最终的答案或动作决策。
这种架构和LLaVA、NVLM-D一致,优势是结构简单,能统一处理图像、视频、文本所有模态,适配推理任务。
(二)各模块细节
- 视觉编码器
7B版本用ViT-676M,56B版本用InternViT-300M-V2.5; 视频处理:均匀采样最多32帧,每帧缩放到448×448,用14×14的patch提取特征,再通过PixelShuffle做2×2下采样,减少视觉token数量,提升效率。
- 投影层
两层MLP结构,负责视觉特征的下采样和维度对齐,把视觉特征映射到文本大模型的嵌入空间; 7B和56B版本的下采样倍率、维度参数不同,匹配各自的大模型主干。
- 大语言模型主干
7B版本:纯Transformer架构,基于Qwen2.5-VL; 56B版本:混合Mamba-MLP-Transformer架构,这是核心创新点之一。 原理:Transformer的自注意力处理长序列是二次复杂度,速度慢;Mamba是线性时间复杂度,处理长序列效率高,但细节捕捉能力不足。所以56B模型把Mamba层、MLP层、Transformer层交替组合,用少量Transformer层补足长上下文建模能力,兼顾效率和效果,如图4所示。
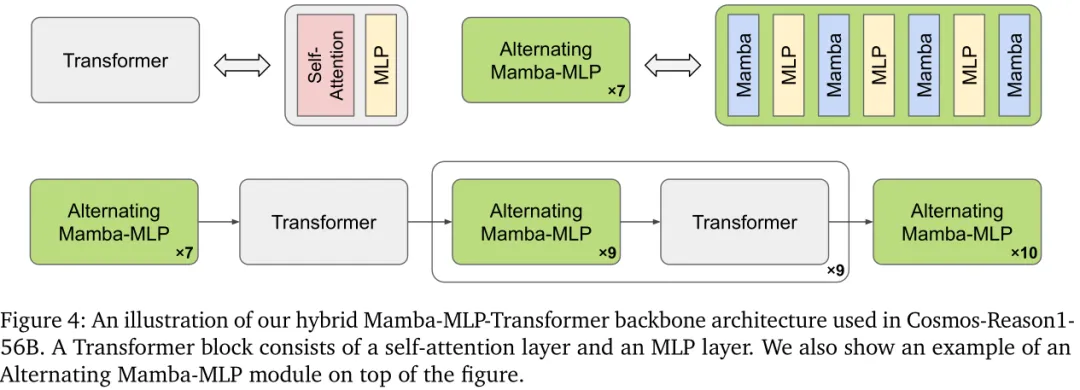
(三)并行训练配置
7B模型:张量并行TP=4; 56B模型:张量并行TP=8+流水线并行PP=2,适配超大参数量的训练。
四、两阶段训练方法:物理AI有监督微调+强化学习
模型训练分两个阶段,先通过有监督微调打下物理常识和具身推理的基础,再用强化学习进一步提升推理准确性,这是模型效果提升的核心方法。
(一)第一阶段:物理AI有监督微调(SFT)
核心目标:让模型学会物理常识和具身推理的基本逻辑,数据是模型效果的基础,团队精心构建了约400万条视频-文本对标注数据。
1. 数据构建逻辑
数据分为三大类,严格对应前面定义的本体论:
- 物理常识数据
:基于人工筛选的高质量视频,做详细字幕标注,再生成自由问答和选择题,包括理解类(直接看视频就能答)和推理类(需要结合物理知识),再用DeepSeek-R1生成长链推理轨迹。 - 具身推理数据
:覆盖机械臂、人形机器人、自动驾驶、人类第一视角视频,聚焦三个核心任务:任务完成验证、动作可行性判断、下一步动作预测,同样生成推理轨迹。 - 直觉物理数据
:专门补全基础物理能力,包括空间拼图(打乱视频patch让模型还原)、时间箭头(判断视频正放/倒放)、物体永存性(判断物体被遮挡后是否消失),这部分数据是自监督生成,成本低、规模大。
2. 数据处理流程
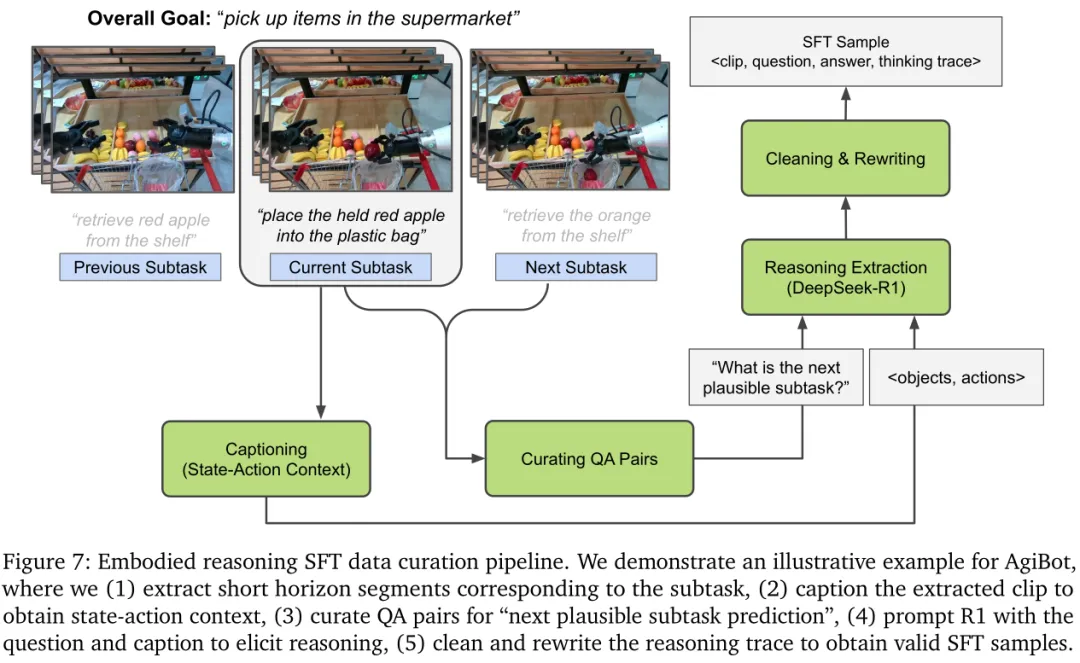
以具身推理数据为例,如图7所示:
把长视频拆成短片段,聚焦短期动作; 用视觉-语言模型做状态-动作字幕标注; 生成推理问答对; 用DeepSeek-R1生成推理轨迹; 规则清洗,去掉无关描述,得到有效训练样本。
3. 训练参数
7B模型:训练12500次迭代,学习率从1e-5余弦退火到1e-6; 56B模型:先30000次迭代用1e-5,再20000次迭代用1e-6; 优化器:融合Adam,权重衰减0.1,平衡采样数据避免单一领域过拟合。
(二)第二阶段:物理AI强化学习(RL)
核心目标:在SFT基础上,用可验证的规则化奖励,进一步提升推理的准确性和逻辑性,解决开放回答难以打分的问题。
1. 强化学习算法:GRPO
选用GRPO算法,优势是不需要单独训练评论家模型,流程简单、计算效率高。原理:对同一个prompt生成一组回答,计算每个回答的奖励,用组内奖励的均值和标准差做归一化,得到优势函数,再优化模型策略,公式用语言解释就是:每个回答的优势 = (该回答奖励 - 组内奖励均值)/ 组内奖励标准差,让模型优先输出高优势的回答。
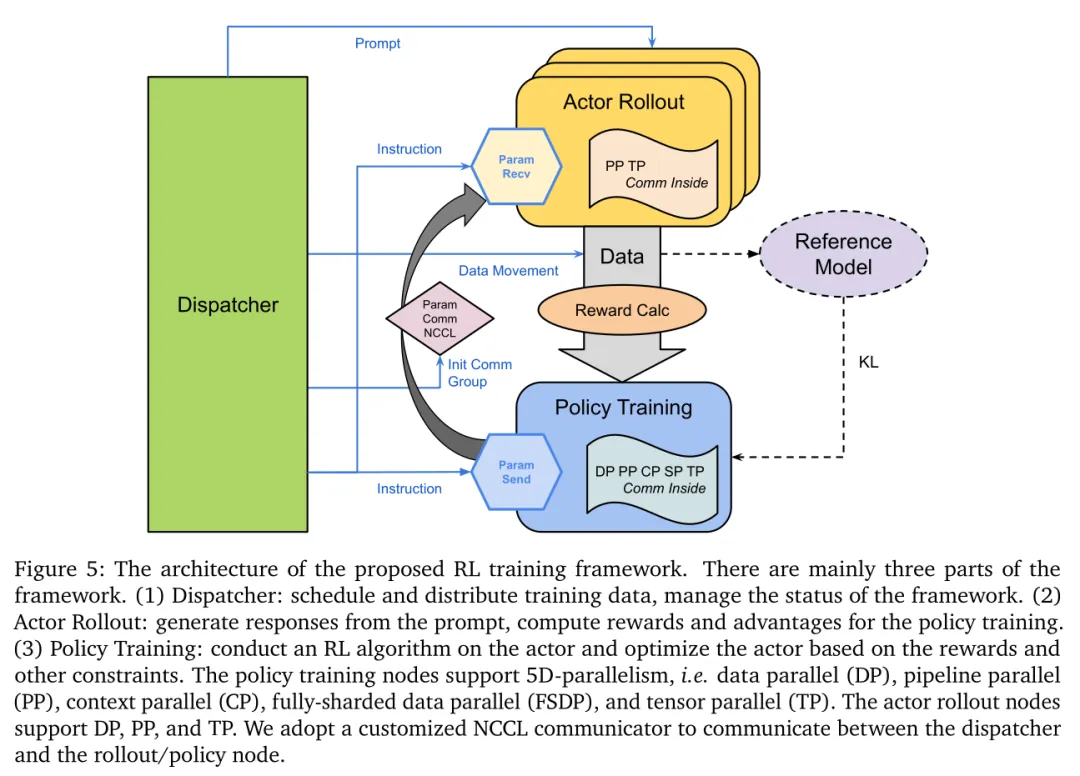
2. 创新训练框架:全异步高鲁棒性框架
如图5所示,框架分为调度器、智能体 rollout、策略训练三部分:
异构部署:策略训练和智能体生成解耦,避免同步开销,训练效率提升约160%; 容错机制:节点故障时能快速重配置,不中断训练; 调度器冗余:提升框架稳定性,支持动态扩缩容。
3. 奖励设计(核心创新)
物理推理的回答是开放的,很难直接打分,团队把所有训练样本转换成单选题,用两种规则化、可验证的奖励:
- 准确率奖励
:判断模型输出的答案是否和标准答案匹配,字符串匹配即可,简单可靠; - 格式奖励
:鼓励模型用标签包裹推理过程,标签包裹最终答案,用正则表达式匹配,保证推理结构规范。
4. 强化学习训练细节
批量大小:128个问题,每个问题采样9个输出,最大长度6144token; 学习率:4e-6,KL惩罚系数0.005,训练500次迭代; 数据处理:动态打乱单选题选项,提升模型泛化能力。
五、评测基准构建
团队没有用现成评测集,而是根据自己定义的本体论,构建了物理常识评测集和具身推理评测集,保证评测针对性。
(一)物理常识评测集
426个视频,604道题,分为空间、时间、基础物理三类; 题型:二选一问题+多选题,覆盖16个细分子类。
(二)具身推理评测集
600个视频,610道题,覆盖BridgeData V2、RoboVQA、AgiBot、HoloAssist、自动驾驶、RoboFail六个场景; 核心评测三个能力:任务完成验证、动作可行性、下一步动作预测,全部用单选题,方便自动评测。
(三)直觉物理评测集
针对时间箭头、空间拼图、物体永存性三个任务,各100个视频,确保无训练数据泄露。
六、实验结果与核心结论
(一)核心效果提升
- 物理常识
:Cosmos-Reason1-56B超过OpenAI o1,7B版本比基线Qwen2.5-VL-7B提升6.9%; - 具身推理
:7B和56B版本比基线模型提升超10%,远超GPT-4o、Gemini 2.0 Flash; - 直觉物理
:现有模型在时间箭头、物体永存性上接近随机猜测,Cosmos-Reason1-7B平均提升32.4%,RL后再提升7%; - 整体
:SFT让模型性能提升超10%,RL再提升超5%。
(二)关键现象
RL后模型学会拒绝不合理选项:面对模糊问题,能判断所有选项都不对,而不是强行选择; RL优化推理逻辑:时间推理上能识别反物理运动,空间推理不再混淆时序和空间,物体永存性推理更简洁准确。
(三)局限性
RoboFail评测集效果提升有限,原因是该场景物理约束复杂、训练数据不足,是未来需要优化的方向。
七、论文贡献总结
定义物理AI的核心能力框架,提出物理常识和具身推理两大本体论; 提出Cosmos-Reason1系列多模态大模型,7B纯Transformer+56B混合Mamba架构,适配物理推理; 构建两阶段训练方案,结合物理AI有监督微调和规则化奖励的强化学习; 构建专属评测基准,验证模型在物理常识、具身推理、直觉物理上的显著提升; 开源代码和模型,推动物理AI领域发展。
NVIDIA 官方尚未发布专门针对 Cosmos-Reason2 的单一独立学术论文,但该模型的技术框架和核心理念主要包含在 Cosmos World Foundation Model (WFM) 平台的系列论文和技术文档中。
NVIDIA 推出的 Cosmos-Reason2 是其专为“物理 AI(Physical AI)”设计的推理型视觉语言模型(VLM)的最新一代。相比于第一代 Cosmos-Reason1,osmos-Reason2 的核心进步在于它将 “看懂物理世界” 提升到了 “精确测量并规划物理行为” 的高度。它更轻、更快,且具备极强的空间坐标处理能力,是专为下一代机器人和自动化系统打造的“物理逻辑引擎”。
1. 核心技术规格对比
特性 | Cosmos-Reason1 | Cosmos-Reason2 |
上下文窗口 | 16K tokens | 256K tokens (大幅提升) |
模型尺寸 | 7B, 56B | 2B, 8B (更轻量,适合边缘部署) |
空间感知能力 | 基础视觉理解 | 2D/3D 点定位、边界框(Bounding Box)坐标 |
时间精度 | 标准视频理解 | 增强的时间戳精度(更精准的动作捕捉) |
输出功能 | 自然语言推理 | 推理说明 + 轨迹坐标输出 |
2. 关键性能提升
- 超长上下文 (256K):
Reason2 的上下文窗口从 16K 扩展到了 256K。这意味着它可以一次性“阅读”更长时间的视频序列或更复杂的环境数据,从而在长时段的任务规划中保持连贯性。 - 物理常识与时空推理:
Reason2 强化了对物体如何在时空中移动的理解。它不仅能看到物体,还能预测其运动轨迹,并以 2D/3D 坐标的形式精确输出。这对于机器人避障、路径规划等任务至关重要。 - 部署灵活性:
Reason1 提供的是较大的 7B 和 56B 模型,而 Reason2 推出了 2B 和 8B 版本。这使得 Reason2 能够更容易地部署在如机器人、自动驾驶汽车等边缘计算设备上,而不必完全依赖云端。
3. 应用场景的演进
- 从“观察”到“规划”:
Reason1 主要侧重于理解物理世界并生成逻辑描述;而 Reason2 更像是一个“行动大脑”,它能够直接为物理代理(Physical Agents)规划下一步动作,支持更复杂的具身智能(Embodied AI)决策。 - 典型案例:
- 自动驾驶 (Uber):
Reason2 被用于自动生成视频标注,将视频内容转化为可搜索的、带推理逻辑的文本数据,极大提升了数据标注的效率。 - 工业安全:
能够精确识别工业环境中的违规行为,并提供精确的时间戳和空间定位信息。
