 夜雨聆风
夜雨聆风
2026年4月,AI编程领域连续出现了几个值得认真对待的进展:智谱GLM-5.1开源编程能力追到了Claude Opus 4.6的94.6%;腾讯云QClaw V2多Agent协同编程正式上线;Claude Code单日提交据说已占全球GitHub公开代码的4%。整个行业在继续讨论一个老问题:AI会不会取代程序员?
但这个问题本身就跑偏了。
真正值得关心的,是一件听起来更乏味的事:不是AI能不能写代码,而是谁来判断AI写的代码对不对。
未来企业付钱买的不是代码行数,而是一个"由AI生成、有人验收、有人负责"的完整系统。能驾驭AI写代码只是基础门槛,能定义清楚问题并验收AI输出,才是新的核心竞争力。
这场变革被理解反了
在程序员群体里,一个流行的误判是:赶紧学会用Cursor、Claude Code、CodeBuddy这些工具,就能保住自己的位置。
这个逻辑在2024年或许成立。在2026年,它已经不够了。
当一项技能变成行业标配,它就不再是竞争优势,而是入场券。你花了两个月学会用Cursor,你隔壁那个程序员也花了两个月。你们之间谁更值钱,不取决于你们都会用Cursor,而取决于谁能更好地定义问题、谁能判断AI的输出是否正确、谁能在线索断裂的时候站出来接手。
天平倾斜的方向就是这个。
几个具体场景
场景一:API价格差了七倍,企业会怎么选?
GLM-5.1的编程能力据说追到了Claude Opus 4.6的九成以上,而API价格只有后者的七分之一。这不是两组数据对比,这是商业决策。当两套系统的编程能力站在同一档位,成本更低的那一个会更快地被部署到更多业务线上去。
但这里真正有意思的不是企业选择了哪个模型,而是企业里谁负责"判断这个模型能不能用"。是程序员自己。他要定义测试场景,要判断输出质量,要在模型跑偏的时候发现并纠正。这个判断力,模型本身给不了他。
场景二:AI能跑36小时,谁来负责盯着?
Cursor Agent的单次任务运行时间已经可以拉长到36小时,Claude Code的代码贡献量据说已经占到了全球GitHub公开代码的4%。这些数字加在一起说明一件事:AI编程已经从Demo进入了真实的生产流程。
但有一个数字没有被统计:这些跑起来的任务,有多少是真正按预期完成的,有多少在中途偏离了目标仍然被合入了代码库?
AI生成代码的速度已经不是瓶颈。谁来定义问题,谁来验收结果,谁来在AI跑偏的时候踩刹车——这些事情正在变成真正的稀缺能力。
场景三:三个Agent并行,谁来当协调者?
腾讯云QClaw V2的多Agent协同编程支持最多三个Agent并行,各有自己的专业背景和"性格"设置,能够在任务中途互相交接。这个场景听起来像是编程的未来,但它的前提是有人懂得在什么时候启动哪个Agent,什么时候推翻AI的结论,什么时候把任务收回来自己处理。
这种判断力不是工具手册教出来的,也不是某次培训能解决的。它来自对系统设计的深层理解,和对业务问题的准确拆解。

一个反常识的结论
一个直觉上的矛盾:AI编程能力越强,应该越不需要人类程序员。但现实恰恰相反——AI编程能力越强,它生成的代码量越大、速度越快,如果没有人来定义问题和验收结果,AI的错误会以同样的速度被放大。
一个AI在36小时内生成了一万行代码,其中有两百行存在隐蔽的安全漏洞。如果没有验收机制,这两百行代码会直接进入生产环境,然后成为某个深夜的事故报告。
AI编程能力触顶不是威胁,是条件。它让"验收能力"从一项可以忽略的软技能,变成了硬刚需。

边界在哪里
这个判断有一个重要的边界:复杂系统设计和架构决策仍然依赖人类积累的经验和判断,AI生成的代码在安全性和可靠性上确实还存在隐患,监管要求也可能强制保留人类审查环节。
这些反对方恰恰证明了同一个逻辑:越是强调这些风险,就越需要人来承担最终责任。这个角色不会消失,只会更值钱。
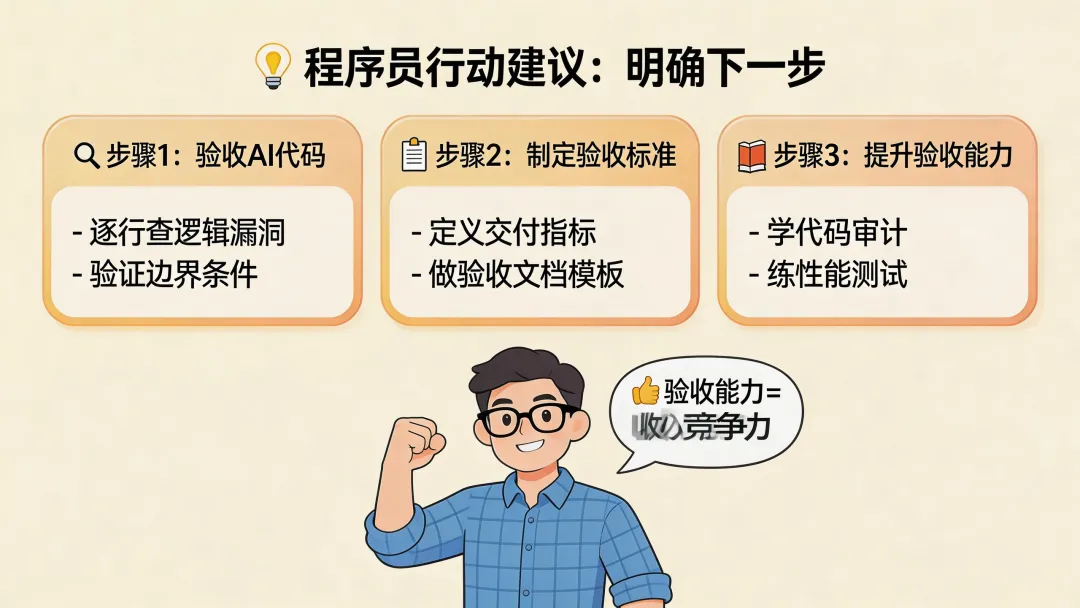
下一步做什么
如果你在这个行业里,有一件事值得现在就开始:把"AI工具使用"和"验收能力"分开训练。
学会用AI编程工具是必要的,但不足以构成壁垒。你真正需要建立的是:把模糊的产品需求拆解成精确的技术规格的能力,对AI生成代码进行质量判断的经验积累,以及在AI持续跑偏时主动介入并接管问题的判断力。
这些能力没有快捷键,但有一个笨办法:主动接手那些AI辅助开发项目,在真实场景里锻炼"什么时候信AI、什么时候否掉AI"的判断直觉。
这个转变不会在明天完成。但它已经开始。
这篇文章反对一个流行的幻觉:以为学会AI工具就安全了。它想提醒的是:AI编程能力触顶,恰好是另一项能力价值上升的起点。那项能力目前还没有被充分定价。
