 夜雨聆风
夜雨聆风2026 年 AI 工程最火概念:Harness Engineering 到底在革谁的命?
导语: 2026 年 2 月,AI 工程圈出现了一个高频词——Harness Engineering。Mitchell Hashimoto 在博客里首次用了这个词(他原话:"我自己管这叫 harness engineering"),OpenAI 紧接着发了一篇百万行代码的实验报告,Martin Fowler 网站跟进了一篇深度分析,Anthropic 三月又放出了全新的多智能体架构设计。几周之内,Harness 成了讨论 AI Agent 开发绕不开的概念。但说来说去,它到底在说什么?为什么说它"革命"?这篇文章给你一次讲透。
一、一个问题开场
先问一个很多开发者都踩过的坑:
你花了每个月几百块订阅了最强的模型,建了一个 Agent,跑了三天——重复犯错、做到一半放弃、越跑越蠢。换了个更贵的模型,效果也没好到哪去。
问题出在哪?不是模型不行。
有一个实验直接戳破了这件事:同一个模型,只换了文件编辑接口的调用方式,编码基准分数从 6.7% 直接跳到 68.3%。模型没换,变的全是外围那套系统。
这个"外围系统",就是 Harness Engineering 要研究的东西。
二、Harness Engineering 到底是什么
2.1 一句话定义
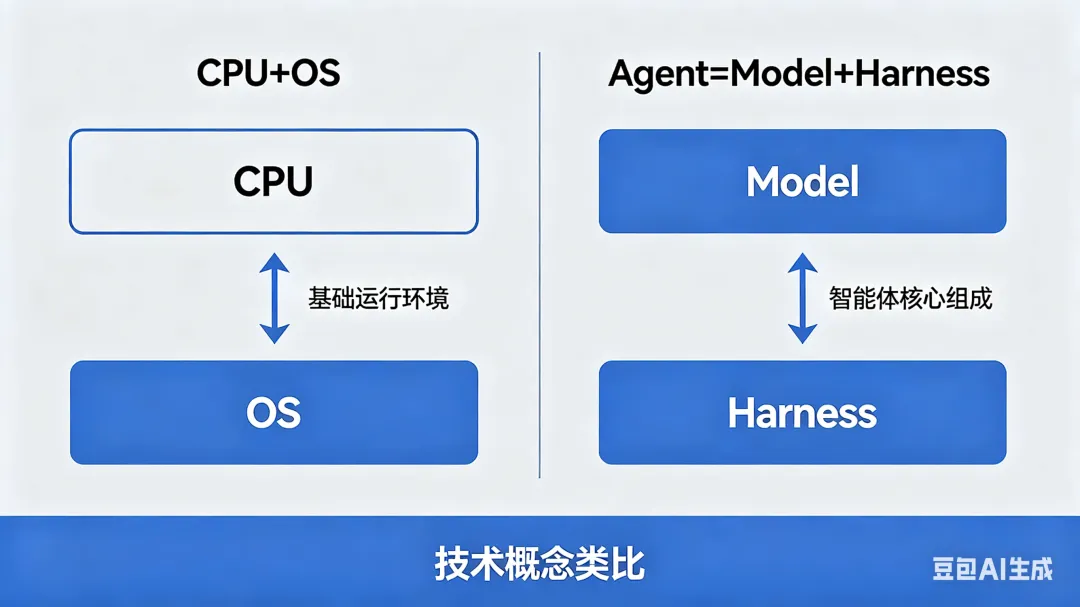
Agent = Model + Harness。你不是模型,那你就是 Harness。
听起来有点绝对?但它确实抓住了核心。
Harness 就是模型之外的一切——系统提示词、工具调用、文件系统、沙盒环境、编排逻辑、钩子中间件、反馈回路、约束机制。模型本身只是能力的来源,只有通过 Harness 把状态、工具、反馈和约束串起来,它才真正变成一个 Agent。
打个比方:模型是 CPU,Harness 是操作系统。CPU 再强,OS 拉胯也白搭。你买了最新款 M5 芯片,装了个崩溃不断的系统,体验还不如老芯片配稳定的 OS。
2.2 和 Prompt Engineering、Context Engineering 的区别
很多人容易把这三个概念混为一谈,实际上它们是嵌套关系,每一层解决的是完全不同的问题:
简单任务里,提示词最重要;依赖外部知识的任务里,上下文很关键;但在长链路、可执行、低容错的真实商业场景里,Harness 才是决定成败的东西。
2.3 模型做不到的,就是 Harness 要补的
不管大模型看起来多能干,本质就是一个文本进、文本出的函数。模型做不到的事情,就是 Harness 要补的:
三、为什么瓶颈不在模型,而在 Harness
这是 Harness Engineering 最反直觉、也最重要的结论。
OpenAI、Anthropic、Stripe、LangChain、Birgitta Böckeler 的实验数据全部指向同一个结论:基础设施才是瓶颈,而非智能水平。
Can.ac 实验:同一个模型,只把工具调用格式从一种换成另一种,分数从 6.7% 跳到 68.3%。模型完全没变。
LangChain 的真实案例:他们优化了 Agent 的运行环境(文档组织方式、验证回路、追踪系统),在 Terminal Bench 2.0 上从全球第 30 名升到第 5 名,得分从 52.8% 提升到 66.5%。模型没换,Harness 换了。
还有一个重要发现——LangChain 提出的 Model-Harness Coupling 问题:当前的 Agent 产品(如 Claude Code、Codex)是模型和 Harness 一起训练的,这导致一种过拟合——换了工具逻辑后模型表现会变差。在 Terminal Bench 2.0 排行榜上,Opus 在 Claude Code 自带的 Harness 下的得分,远低于它在其他 Harness 中的得分。结论是:"the best harness for your task is not necessarily the one a model was post-trained with"——为你的任务选 Harness 时,不要被模型的默认 Harness 束缚。
四、一个成熟的 Harness 长什么样:六层架构
从系统设计角度看,一个成熟的 Harness 有清晰的六层结构:
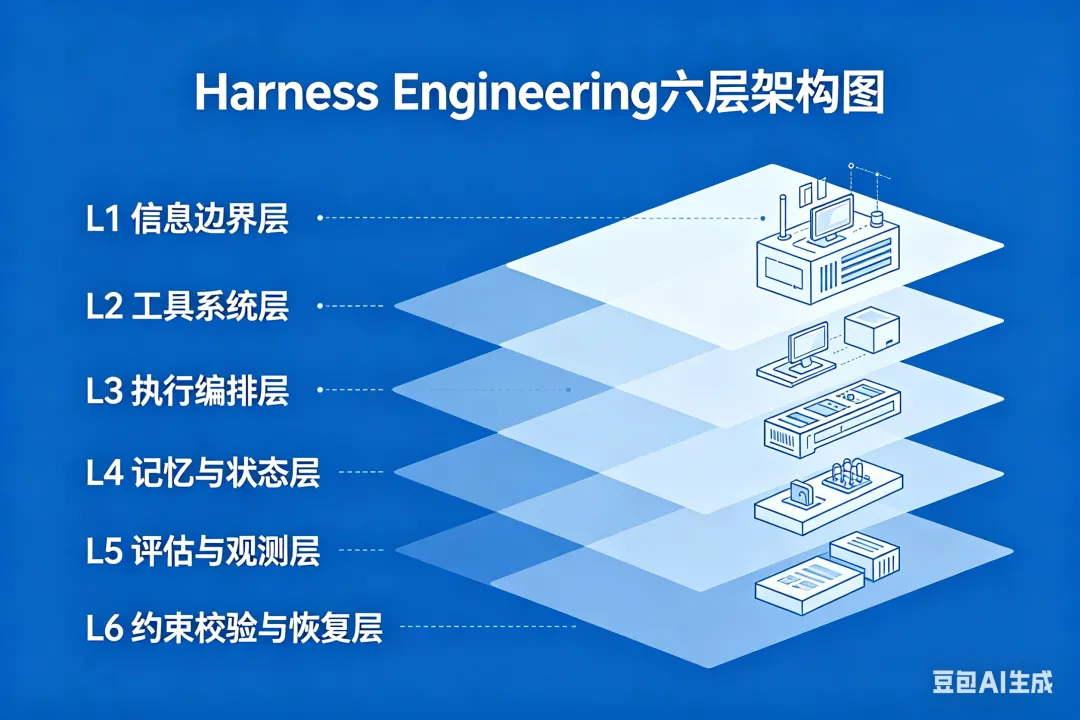
可以类比成给一个新手员工搭建的完整工作环境:L1 是岗位说明书,L2 是办公工具,L3 是标准操作流程,L4 是项目管理系统,L5 是质检流程,L6 是红线规则和应急预案。
六层架构最大的价值:不是功能堆叠,而是从"定义边界"到"兜底恢复"的完整闭环。
注意:不要试图一开始就搭齐六层。从 L1(信息边界)和 L6(约束与恢复)入手,这两层投入产出比最高。 L1 决定 Agent 知道该干什么,L6 决定它搞砸了能不能拉回来。中间的层次随着项目复杂度增长逐步补齐。
五、为什么上下文越多,Agent 反而越蠢
Dex Horthy 观察到一个现象:168K token 的上下文窗口,用到大约 40% 的时候,Agent 的输出质量就开始明显下降。
Anthropic 在自己的实践中也碰到了类似问题,他们叫**"上下文焦虑"**:Sonnet 4.5 在上下文快填满时会变得犹豫,倾向于提前收工——哪怕任务还没做完。光靠压缩不够,最终的做法是直接清空上下文窗口,但通过结构化的交接文档把关键状态留下来。
你的目标不是给 Agent 塞更多信息,而是让它在任何时候都运行在干净、相关的上下文里。
工程建议:生产环境中监控上下文利用率是第一优先级。建议设置 40% 阈值告警——当上下文占用超过这个比例时,就应该触发上下文压缩或任务交接。等到 Agent 已经变蠢了再处理就晚了。
六、一线团队实战案例
6.1 OpenAI:三个人、五个月、一百万行、零手写代码
先看数据:
比数字更有意思的是他们总结的五大方法论:
① 给 Agent 一张地图,而不是一本千页手册。 OpenAI 的 AGENTS.md 只有约 100 行,作用是目录,指向 docs/ 目录下更深层的设计文档。就像到新城市,给你一张简明地图告诉你"详细资料翻到第 X 页",而不是塞给你一本旅游指南。
② 架构约束不能写在文档里,必须靠工具强制执行。 自定义 Linter 加结构测试,违反就报错,报错消息里直接告诉你怎么改。OpenAI 原话:"If it cannot be enforced mechanically, agents will deviate."——文档记录约束是不够的,如果不能机械化地强制执行,Agent 就会偏离。
③ 可观测性也是给 Agent 看的,不只是给人看的。 接入 Chrome DevTools Protocol,Agent 能自己抓 DOM 快照、截图,自己验证"启动时间降到 800ms 以下"这个目标。
④ 熵不会自己消失,必须主动对抗。 每周花 20% 时间手动清理低质量代码,后来这事被自动化了——后台 Agent 定期扫描并自动提交清理 PR。清理的速度跟上生成的速度,才能可持续。
⑤ 写在 Slack 里的知识,对 Agent 来说等于不存在。 所有团队知识都放在版本控制的仓库里,而非 Slack 或 Google Docs。
6.2 Anthropic:从上下文焦虑到 GAN 式三智能体架构
Anthropic 在这个方向上有两个值得细看的实践:
16 个 Agent 写 C 编译器项目:Nicholas Carlini 用约两周跑了 16 个并行 Claude Opus 实例,产出了一个 GCC torture test 通过率 99% 的 C 编译器,可编译 PostgreSQL、Redis、FFmpeg、CPython、Linux 6.9 Kernel 等 150+ 项目,API 成本约 2 万美元。几个 Harness 设计决策很有意思:日志全部写进文件用 grep 友好的单行格式(主动控制上下文污染);测试子采样(每个 Agent 只跑随机 1-10% 但对单个 Agent 是确定性的,跨 VM 是随机的)。
三智能体架构(借鉴 GAN 思路):Anthropic Labs 2026 年 3 月发布的架构:
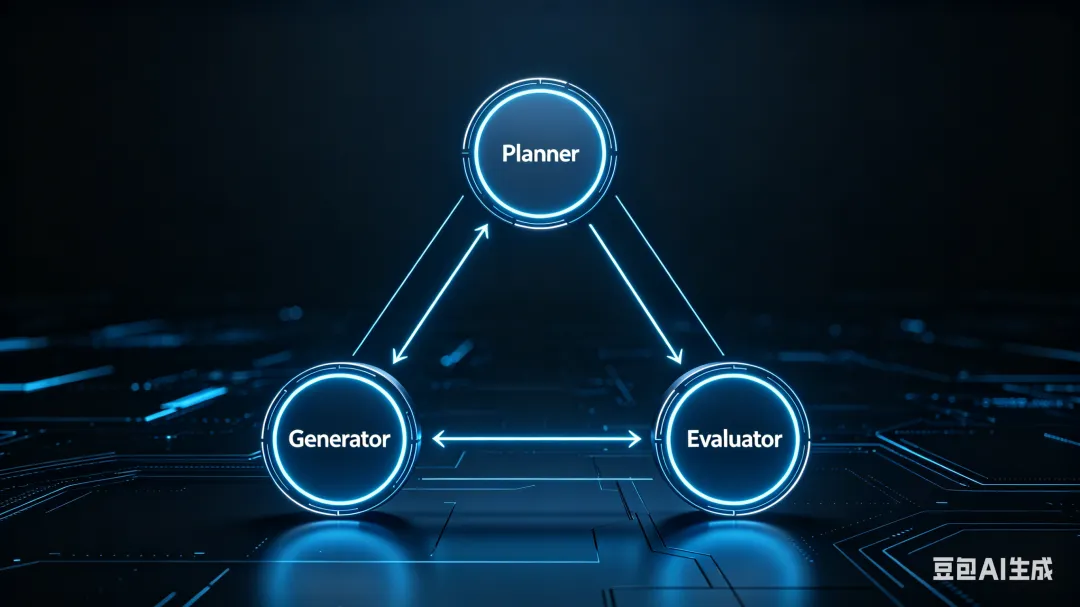
• Planner(规划者):把产品描述扩展成完整规格,要求"在范围上要大胆" • Generator(执行者):按功能一个个做 Sprint,每个 Sprint 有明确完成标准 • Evaluator(评估者):用 Playwright MCP 实际点击运行中的应用,按产品设计、功能性、视觉、代码质量打分
这个架构要解决两个核心问题:上下文焦虑(Sonnet 4.5 快到上限时草草收尾 → 解法:context resets + 结构化交接)和自我评价偏差(Agent 自信满满夸自己做得好,实际质量一般 → 解法:生成和评估交给两个独立 Agent)。
遇到上下文焦虑,不是压缩而是重启。 当 Agent 上下文接近饱和时,先把当前任务状态结构化提取出来,启动一个全新的"干净"Agent,把交接文档交给它。这就像程序遇到内存泄漏——不是手动释放每一个内存块,而是直接重启进程从检查点恢复。虽然粗暴,但在长任务场景里效果远好于继续往里塞。
6.3 Stripe:每周 1300+ 个 PR,全程无人值守
Stripe 的 Minions 系统代表了另一个极端——高度自动化的无人值守模式。开发者发一条 Slack 消息,Agent 从写代码到跑 CI 到提 PR 全部搞定,人只在最后审查。每周超过 1300 个完全由 Minions 生产的 PR 被合并。
核心架构:Devbox(AWS EC2 预装源码的"牲口"池,启动约 10 秒)→ 编排状态机(确定性节点 lint/push 和 Agent 节点交替)→ Toolshed MCP(近 500 个工具的集中式服务)→ 反馈回路(pre-push hook 秒级修 lint,推送后最多 2 轮 CI)。核心理念:"What's good for humans is good for agents."——为人类工程师投资的 Devbox、工具链和开发者体验,在 Agent 上也直接产生了回报。
6.4 Mitchell Hashimoto:一个人 vs Harness 工程学
Hashimoto(Vagrant、Terraform、Ghostty 终端模拟器作者)的路线和 Stripe 完全相反——他坚持一次只跑一个 Agent,保持深度参与,明确说"不想跑多 Agent"。
他的六步进阶路线:① 放弃聊天模式,在能读文件、跑程序、发 HTTP 请求的环境里直接干活 → ② 复现自己的工作,每件事做两次:一次自己做,一次让 Agent 做 → ③ 下班前启动 Agent,每天最后 30 分钟给 Agent 布置深度调研任务 → ④ 外包确定性任务,挑出 Agent 几乎一定能做好的事后台跑 → ⑤ 工程化 Harness,每当 Agent 犯错,就工程化一个解决方案让它永远不再犯 → ⑥ 始终有 Agent 在跑,目标是 10-20% 工作时间有后台 Agent 运行。
Ghostty 项目里的 AGENTS.md,每一行都对应一个过去的 Agent 失败案例。这不是静态文档,而是一个持续积累的防错系统——Agent 犯了一个新类型的错误,就加一行规则。
七、从零搭 Harness 的行动清单
综合一线团队的实践经验,按优先级梳理了行动路线。先做 P0,效果立竿见影。
P0:立即可以做
常见误区:很多团队把 AGENTS.md 当成"超级 System Prompt",把所有规则塞进一个文件。 结果上下文窗口被撑爆,Agent 反而更蠢。正确做法是 AGENTS.md 只当目录用(约 100 行),详细规则放在子文档中按需加载。
P1:P0 做完之后
P2:有余力再考虑
八、你的 Harness 到哪个阶段了?
九、结语
Harness Engineering 做的事情一句话概括:承认模型有边界,然后把边界之外的需求一个个工程化地补上。
有一句话值得记下来:模型决定了系统的上限,Harness 决定了系统的底线。
在简单任务中提示词最重要,在依赖外部知识的任务中上下文很关键,但在长链路、可执行、低容错的真实商业场景中,Harness 才是 AI 稳定落地的前提条件。
与其纠结选哪个模型,不如先把 Harness 搭好。
