 夜雨聆风
夜雨聆风AI项目的“信任断层”:如何跨越从试点到规模的鸿沟
当企业争相部署人工智能时,一个令人不安的真相逐渐浮出水面:绝大多数AI项目止步于试点,无法实现规模化价值。这不是技术能力的失败,而是信任机制的缺失。本文基于实证研究,提出“信任=可解释性×透明指数×可追溯性”的治理公式,并给出系统性的解决方案——管理本体论的四层架构。
文 / 刘凯
引言:效率的胜利,信任的溃败
一家大型商业银行投入近千万元打造智能信贷审批系统。上线后,审批时效从2天骤降至2秒,效率提升堪称惊艳。然而三个月后,该系统被紧急下线。原因令人深思:客户投诉率飙升、客户经理集体抵制、合规部门无法满足监管追溯要求。
效率赢了,信任输了。
这并非个例。Gartner调查显示,超过60%的企业AI项目未能实现预期价值,其中“缺乏信任”与“解释性不足”被列为前三大障碍。

RAND Corporation的研究更指出,AI项目的失败率高达80%,是传统IT项目失败率的两倍。
Forrester的数据表明,仅有10-15%的AI项目能进入长期生产使用。麦肯锡则发现,95%的生成式AI试点未能带来可衡量的P&L影响。
这些数字揭示了一个深刻的悖论:人工智能越是被赋予决策权力,人类对其的信任就越发脆弱。当算法从辅助工具变为决策主体,管理者面临的真正挑战不是技术能力,而是信任的可编程性。
本文将从信任的本质出发,提出一个可量化的信任公式,并引入管理本体论的四层架构,为管理者提供一套将“信任”从抽象概念转化为可执行、可度量、可进化的数字逻辑的系统性方法论。
【知识点】什么是“可解释性AI(XAI)”?
可解释性AI(Explainable AI)是指AI系统的决策过程和输出结果能够被人类理解的能力。它不追求让AI更聪明,而是让AI更“透明”。欧盟《通用数据保护条例》(GDPR)第22条赋予用户“获得解释的权利”——算法决策必须提供有意义的解释。中国《个人信息保护法》也要求自动化决策的透明性和结果公平。
一、信任的本质:从人际信任到算法信任
1.1 传统信任的基础
管理学将信任定义为“对他人未来行为符合预期的信心”(Mayer, Davis & Schoorman, 1995)。这种信任建立在可观察的重复互动之上。你信任一位资深会计,因为你知道他过去二十年如何做账,你能预判他的判断逻辑。你信任一位老中医,因为你知道他见过各种疑难杂症,你相信他的诊断逻辑。
信任的核心是确定性——我知道你会怎么做,我知道你为什么这么做,我知道下次你还会这么做。
“信任的本质不是喜欢对方,而是相信对方会遵守承诺。”——彼得·德鲁克(Peter Drucker),《管理的实践》(The Practice of Management, 1954)
1.2 算法信任的根本位移
然而,当决策主体从人变为算法,信任的基础发生了根本性位移。算法没有履历,没有声誉,没有情感。你无法通过“相处”来建立信任。唯一的途径,是让算法将其“思考过程”完全暴露在可审查的层面。
这正是诺贝尔经济学奖得主Herbert Simon在《管理行为》中预言的延伸:
“决策的理性受限于信息、时间和认知能力。AI可以扩展人的有限理性,但前提是决策过程必须可理解。”——赫伯特·西蒙(Herbert Simon),《管理行为》(Administrative Behavior, 1947)
换言之,算法信任的核心不是“相信它不会犯错”,而是“相信它的错误可以被理解、被追溯、被纠正”。
1.3 信任的可量化公式
基于上述分析,我们提出一个可量化的信任公式:
信任 = 可解释性 × 透明指数 × 可追溯性
可解释性:每个决策是否有可读的、结构化的理由。这是信任的“原材料”。
透明指数:决策逻辑对相关方开放的程度。这是信任的“流通渠道”。
可追溯性:每个决策能否回溯到规则ID、数据源与版本号。这是信任的“审计凭证”。
三者相乘,意味着任何一个因子为零,整体信任即为零。
【表格】信任的三种维度对比
二、管理本体论:信任的工程化框架
如何将上述公式转化为可执行的系统设计?答案是管理本体论。
管理本体论(Management Ontology)并非一套软件,而是一种将企业业务语义、管理规则、决策逻辑与治理机制进行数字化建模的方法论。它把现实世界的业务实体(客户、订单、产品、员工)映射为“对象”,把它们的属性和关系变成可计算的数据结构,并在此基础上构建四层治理架构。
2.1 为什么需要本体论?
企业AI项目失败的一个核心原因是语义割裂。销售部说的“客户”、财务部说的“客户”、客服部说的“客户”,可能是三个不同的定义。当AI需要跨部门协同决策时,这种语义不一致会直接导致输出混乱。
本体论的第一使命,就是建立统一的“企业词典”。在这个词典里,每个概念都有明确的定义、属性和关系。所有智能体、所有部门、所有系统都基于同一套语义工作。
【图】本体论四层架构总览
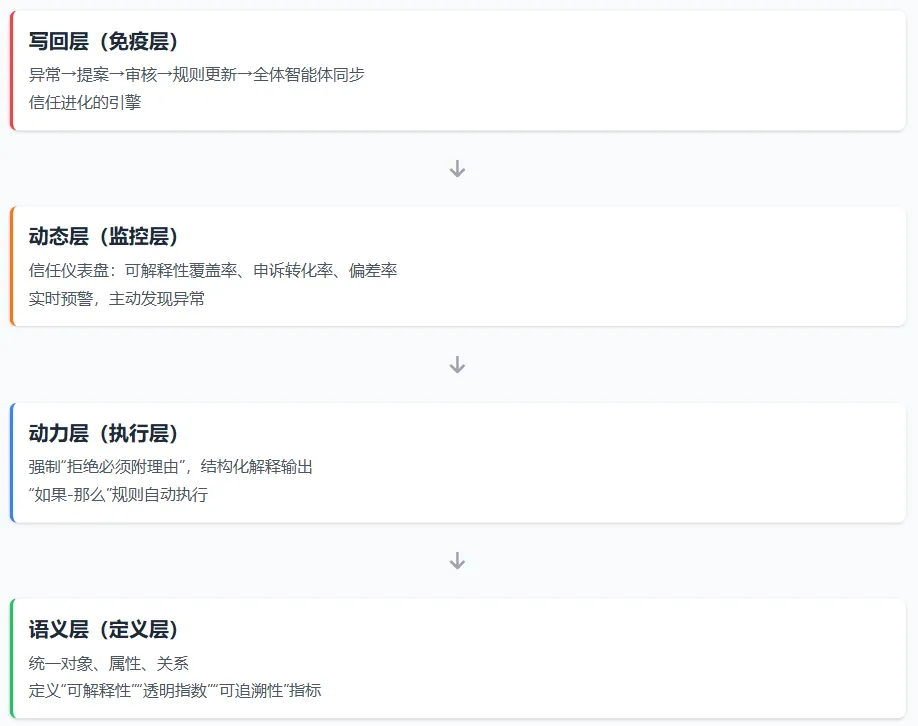
2.2 本体论的四层架构
我们将信任的构建分解为四个层次,每一层对应一个管理动作:定义 → 执行 → 监控 → 进化。
| 语义层 | |||
| 动力层 | |||
| 动态层 | |||
| 写回层 |
三、语义层:定义“信任”的可计算属性
语义层的任务是回答“世界有什么”。管理者首先需要将模糊的“信任”转化为可采集、可计算的数据结构。
在本体论中,我们定义“信任度”对象,其属性包括:
可解释性评分:每个决策是否附带结构化理由(目标100%)
透明指数:规则库对不同角色的开放程度(1-10分)
可追溯率:决策可追溯到规则ID、数据源与版本号的比例(目标100%)
这些定义不是挂在墙上的标语,而是写入系统的元数据。从此,全公司使用统一的信任度量衡。
什么是“元数据”?
元数据(Metadata)是“描述数据的数据”。例如,一张发票有金额、日期、供应商(这些是数据);而“金额的单位是元”“日期格式是YYYY-MM-DD”“供应商字段不可为空”——这些就是元数据。在本体论中,信任指标的定义本身也是元数据,它让“信任”成为可编程的对象。
四、动力层:强制“拒绝必须附理由”
动力层的任务是回答“当事件发生时做什么”。它将管理规则编码为“如果-那么”逻辑,由AI毫秒级执行。
最关键的信任规则是:
如果AI做出拒绝决策,则必须输出包含以下字段的结构化解释:触发规则ID、触发条件的具体数值、客户的对比基准(如行业平均分)、建议的补救措施。
这条规则生效后,任何AI拒绝都会自动生成如下解释:
“您的申请被拒绝。规则R-089触发:您的信用评分为62分,低于60分红线。该红线基于历史数据:评分低于60的客户逾期率35%。您可补充纳税记录或银行流水发起申诉。”
这不再是模糊的“信用不足”,而是可验证、可行动、可申诉的透明依据。
【表格】有/无“强制附理由”的客户体验对比
五、动态层:实时监控“可解释性”健康度
动态层的任务是“在复杂情况下做出判断”。它设立信任仪表盘,实时追踪关键指标:
可解释性覆盖率 = 附带完整理由的决策数 / 总决策数(目标100%)
平均解释长度(字符数)——过低可能表示解释敷衍
申诉转化率 = 收到解释后仍发起申诉的比例
偏差率 = 不同群体被拒绝的比例差异
当仪表盘显示“可解释性覆盖率”从100%降至92%,系统自动预警。管理者可追溯至具体模型或规则,快速修复。
六、写回层:让信任持续进化
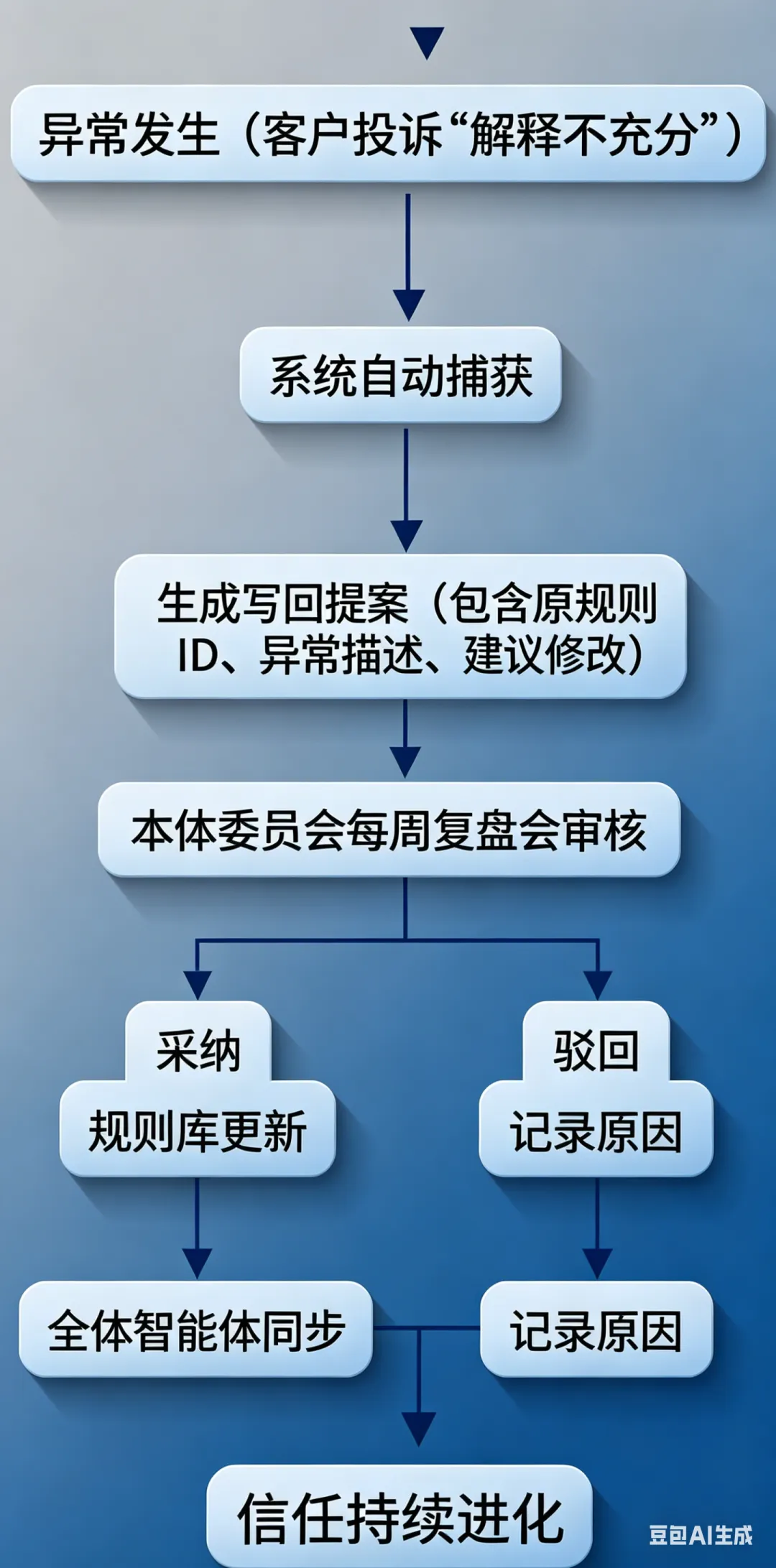
写回层是本体系中最具革命性的设计。它的核心是每一次例外都是规则进化的机会。
当客户投诉“AI说我的信用分低,但我在其他银行从未逾期”,系统自动捕获异常,生成一份结构化的“写回提案”:
“建议新增规则:当客户提供跨行征信证明时,自动触发二次复核,并将跨行数据纳入评分模型。”
管理者审核通过后,新规则写回动力层。从此,所有类似客户获得更公平的对待。
“信任像空气——它在的时候你感觉不到,一旦没了,你什么都做不了。” ——沃伦·巴菲特(Warren Buffett),《巴菲特致股东的信》
之所以称之为“写回层”或“免疫层”,是因为它模拟了生物免疫系统的机制:系统能够自动发现异常、生成抗体(新规则)、自我修复、持续进化。
七、治理机制:本体委员会与四条红线
7.1 本体委员会
本体委员会是跨部门的常设治理机构,由业务、技术、合规、员工代表组成。其职责包括:
评审写回提案,决定是否采纳
统一核心术语的定义,维护语义层
调整确定性等级和决策边界
每季度审视信任指标,发起范式升级
“坦诚不是残忍,而是把真相放在可理解的位置上。”——埃德·卡特穆尔(Ed Catmull),《创新公司》(Creativity, Inc., 2014)
7.2 四条管理红线
在AI治理中,四条原则不可妥协:
一、透明可审计:每个AI决策必须可追溯、可解释
信任不是喊出来的,是每一个可解释的决策堆出来的。当AI做出一个拒绝决策,如果它只说“信用不足”,客户愤怒,员工无奈,合规抓狂。如果它说“您的信用评分为62分,低于60分红线(规则R-089),该红线基于历史数据:评分低于60的客户逾期率35%。您可补充纳税记录或银行流水发起申诉”,情况就完全不同。前者是黑箱,后者是透明。
在算法时代,“承诺”就是编码在动力层的规则,“遵守承诺”就是规则被执行且可验证。透明可审计,正是让承诺变得可见、可查、可问责。
【表格】透明可审计的有无对比
二、最终责任在人:重大决策必须由人签字
AI可以建议,可以推荐,可以预警,但最终的责任必须由人承担。因为税务机关、审计师、法院不会接受“AI让我这么做的”作为理由。这是管理的底线,也是伦理的底线。
“权力与责任必须对等。把决策权交给机器,却把责任留给人类,这是不道德的。” ——赫伯特·西蒙(Herbert Simon),《管理行为》
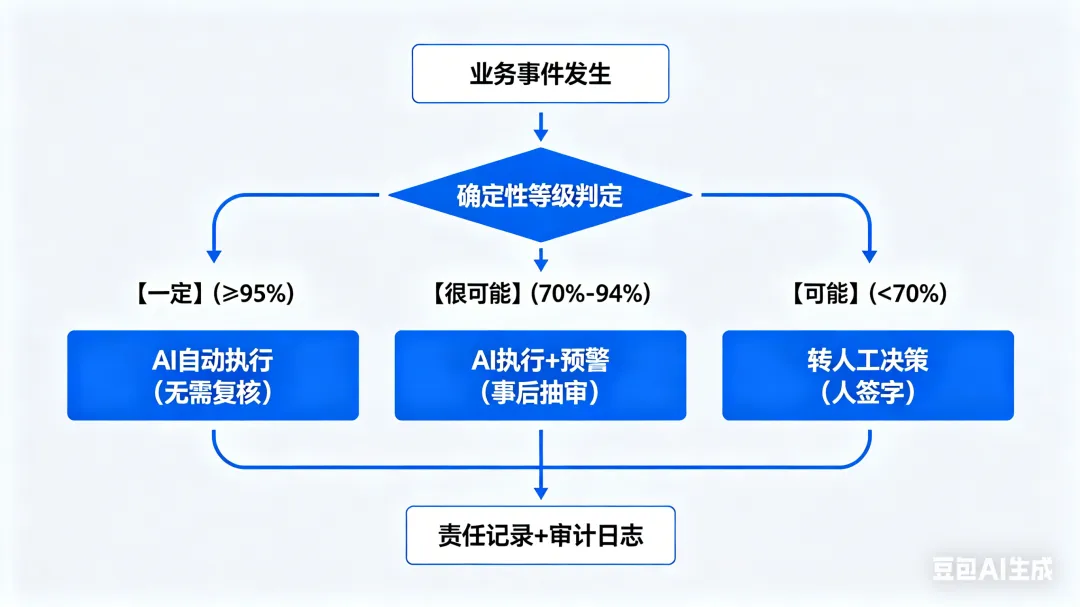
在本体论中,这一原则通过“确定性等级”和“权限控制”来实现。确定性等级分为“一定”“很可能”“可能”三类。“一定”级规则AI自动执行,“很可能”级执行后推送预警,“可能”级必须转人工决策。同时,高风险行动(如删除生产数据库、批准大额授信)的触发必须要求人类授权签名,系统不提供绕过机制。
三、高情绪场景不得自动化:裁员、绩效面谈等场景AI只提供信息
员工需要的不是一份“算法给出的评级”,而是“被认真对待的感觉”。裁员谈话、绩效面谈、薪酬纠纷——这些场景涉及人的尊严、情感和未来。AI可以提前整理数据、提供话术建议、记录谈话要点,但面对面沟通、共情表达、责任担当,必须由人完成。
“管理的本质是激发人的善意和潜能。冰冷的算法永远无法替代温暖的对话。”——陈春花,《管理的常识》
在本体论中,这一原则通过“场景分类”和“操作权限控制”来实现。将决策场景分为“高情绪”“低情绪”两类。高情绪场景的AI权限仅限于“只读”和“建议”,不得触发“执行”动作。
【表格】高情绪场景 vs 低情绪场景
四、人才成长不可跳过:新人必须先手动训练才能使用AI
如果新人一入职就让AI帮他做所有事,他永远学不会业务底层逻辑。他不知道发票为什么会被退回,不知道三单匹配的差异原因,不知道客户为什么会逾期。当AI遇到从未见过的异常时,他束手无策。更严重的是,他无法判断AI的输出是否正确,因为他没有亲手做过。
“师傅带徒弟,不仅是传手艺,更是传心法。没有亲手经历过,永远无法真正理解。”
在本体论中,这一原则通过“分阶段权限”和“能力考核”来实现。新员工必须先手动完成一定数量的完整案例,才能逐步获得AI辅助权限乃至自动执行权限。
八、行业案例:信任重构的实践
某股份制银行上线智能信贷系统后遭遇信任危机。他们引入本体论重构:
语义层:统一“信用风险”“逾期”“优质客户”等定义
动力层:强制“拒绝必须附理由”,输出规则ID、触发条件、对比基准
动态层:搭建信任仪表盘,监控可解释性覆盖率和偏差率
写回层:客户申诉自动生成写回提案,每两周更新规则库
结果:审批时间2秒,自动化率78%;95%的拒绝附带可理解的理由,客户投诉率下降60%;不同职业群体通过率差异从15个百分点缩小到3个百分点。
九、建立AI智能体信任的三把钥匙
在构建可信任的AI决策系统时,有三条核心规则必须被编码进管理本体论的不同层次,它们共同构成信任的工程化底座。
【附带理由:让客户可理解、员工可解释】
所有AI做出的拒绝或否定性决策,必须附带结构化的解释理由。这个理由不能是“信用不足”这样的模糊结论,而应包含四个要素:触发决策的规则ID、导致该规则生效的具体数值(如信用评分62分)、与行业或历史数据的对比基准(如行业平均分68分),以及建议的补救措施(如补充纳税记录)。这样设计,客户能够真正理解自己被拒绝的原因,员工也能有据可依地向客户解释,从而在每一次交互中积累信任。
【开放查询:让透明可追溯、让信任可审计】
整个规则库必须对相关角色开放查询。客户经理、客服人员、合规审计等岗位,应能够按规则ID、时间、用户等维度检索任意决策的依据。这意味着信任不再是黑箱中的猜测,而是可以被任何人随时验证的透明事实。当员工可以自己查到“为什么这个客户被拒绝”,他们就不再是背锅侠,而是有数据支撑的沟通者。
【一键申诉通道:让系统持续进化,让信任不断增强】
系统必须为用户提供一键申诉的通道,且每一次申诉都会自动进入写回队列,触发规则优化流程。当客户或员工发现AI的判断存在偏差,他们不是被挡在门外,而是被邀请参与系统的进化。申诉经过审核后,如果确实揭示了规则缺陷,新的规则将被写回动力层,所有智能体同步学习。信任由此不再是静态的合规清单,而是随着每一次互动持续升级的活系统。
这三条规则一旦编码生效,您将不再需要反复强调“我们要建立信任”。信任已被嵌入系统的每一次执行、每一次监控、每一次进化。
结语:信任不是态度,是工程
Herbert Simon(司马贺)在七十年前的洞见至今闪耀:“管理就是决策。”而在AI时代,决策的主体不再限于人。我们如何信任一个算法?
答案不是更快的芯片,不是更大的数据,而是更透明的逻辑。
“管理者的最大盲点,是看不到自己身处其中的反馈回路。” ——杰伊·福瑞斯特(Jay Forrester),系统动力学创始人
管理本体论提供了一套将“信任”从玄学转化为工程的完整方法论。它把可解释性定义成指标,把附理由编码成规则,把申诉设计成写回回路。当这些设计被执行、被监控、被进化,信任就不再是喊出来的口号,而是长出来的系统能力。
有本体论与无本体论的信任机制
| 决策输出 | ||
| 用户知情权 | ||
| 沟通能力 | ||
| 合规审计 | ||
| 投诉处理 | ||
| 信任积累 |
管理者们,不要再问“为什么员工不信任AI”了。先问自己:在开展AI智能体设计时,你给AI设计“解释”的能力了吗?
