 夜雨聆风
夜雨聆风AI Compass前沿速览:聚焦 Seeduplex、VimRAG 与 QBotClaw
AI-Compass 不只是一个 AI 资源汇总仓库,更是一套覆盖“学习认知、技术选型、工程实践、项目落地”的开源导航系统。无论你是刚进入 AI 领域的初学者,还是正在推进 RAG、Agent、多模态、推理部署等项目的开发者,都能在这里快速找到清晰的学习路径、关键资料与可复用的实践方案。
项目围绕博客、可运行代码、基础知识、技术框架、应用实践、产品与工具、学习资源、企业开源、社区与平台九大模块持续沉淀内容,既适合个人系统学习,也适合作为团队做技术调研、方案选型和能力建设的长期参考。把仓库放到本地后,还可以直接结合 Codex、Claude Code 等 AI 编程助手进行知识问答、专题检索、项目拆解和路线梳理,让仓库从“能看”真正升级为“能用”。
• github地址:AI-Compass👈 https://github.com/tingaicompass/AI-Compass
🌟 如果本项目对您有所帮助,请为我们点亮一颗星!🌟
1.每周大新闻
1.0 SBTI测试 – B站UP主推出的网络人格测试
这是B站UP主推出的荒诞解构版MBTI人格测试,通过31道极端情境、反逻辑题目,输出27种戏谑人格标签,精准契合当代年轻人自嘲解压需求,上线后迅速成为现象级“赛博发疯”社交货币。
SBTI(Satirical Behavioral Type Indicator,讽刺行为类型指标)是一款基于 5 大心理模型、15 个人格维度的娱乐型人格测试。它用 30 道精心设计的题目,通过三级评分(L/M/H)和模式匹配算法,为你匹配 26 种独特的人格类型——每一种都带着善意的毒舌和精准的洞察。
核心功能
1. 人格测评系统:通过31道多元情境题,将用户归类为“死者”“拿捏者”等27种荒诞人格标签。 2. 匹配度分析:生成含匹配百分比与15维特征解析的个性化报告,具象化人格特质。 3. 情绪宣泄出口:用黑色幽默标签映射打工人精神困境,提供自嘲式解压的情绪价值。 4. 社交传播功能:自动生成立体像素风形象卡片,支持一键分享,打造病毒式社交话题。
技术原理
基于前端网页架构实现轻量化测评流程,通过选项分支逻辑引擎完成用户答题数据的实时分类,采用预定义标签映射算法输出对应人格结果;复刻版本借助Claude Code的代码生成能力快速实现功能迁移,以静态页面部署降低服务器负载,适配突发流量高峰。
应用场景
1. 职场解压:年轻打工人通过测试获取“废物”“死者”等标签,以自嘲方式释放工作焦虑。 2. 社交破冰:社交活跃群体分享测试结果卡片,在朋友圈、微博发起话题,快速拉近人际距离。 3. 亚文化社交:熟悉网络梗的Z世代用户,通过测试标签寻找同好,构建“赛博发疯”身份认同。"
• 官网 https://sbti-test.com/

博主的测试结果
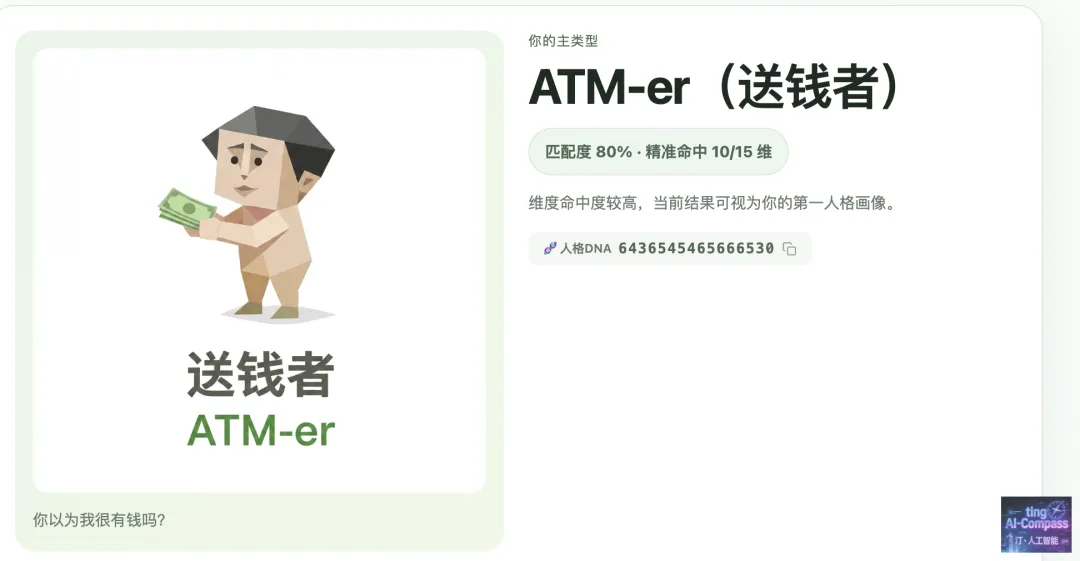
报告出炉——你或将成为金融界的未解之谜。是的,ATM-er不一定真的"送钱",但可能永远在"支付"。支付时间、支付精力、支付耐心、支付一个本该安宁的夜晚。因此像一部老旧但坚固的ATM机,插进去的是别人的焦虑和麻烦,吐出来的是"没事,有我"的安心保证。你的人生就是一场盛大的、无人喝彩的单人付账秀。你竟用磐石般的可靠,承受了瀑布般的索取,偶尔夜深人静才会对着账单——可能是精神上的——发出一声叹息:我这该死的、无处安放的责任心啊。
1.1 新GO-2 – 智元机器人推出的具身智能基座大模型
GO-2是智元机器人推出的第二代具身智能基座大模型,首创动作思维链并搭配异步双系统架构,能打通“理解-规划-执行”链路,在多项基准测试中刷新SOTA,可通过Genie Studio平台实现真实场景的持续学习与规模化落地,让机器人从“看懂”走向“稳定执行”。
1.1.1 核心功能
1. 动作思维链推理:在动作空间直接规划推理,生成结构化高层动作序列,拆解复杂任务为有序步骤,实现“想清楚再做”。 2. 异步双系统执行:慢系统低频生成“意图流”规划,快系统高频实时跟踪执行并动态调整,保障规划稳定兑现。 3. 语义-动作统一建模:打通视觉-语言-动作链路,将抽象指令精准转化为物理世界动作,弥合“理解”与“执行”的鸿沟。 4. 闭环持续进化:依托Genie Studio平台,通过“预训练+后训练+数据闭环”架构,在真实交互中持续优化模型。 5. 跨域零样本迁移:具备从仿真到真实环境的强泛化能力,无需重新训练即可适应新场景、新物体和新纹理。
1.1.2 技术原理
采用动作思维链机制,显式在动作空间形成动作计划,避免传统模型规划与执行的断层;搭配异步双系统架构,慢系统以“意图流”形式持续生成层次化高层动作规划,快系统结合实时视觉观测生成控制信号并动态修正;引入带噪声强制教学训练机制,模拟规划误差,提升模型在动态环境的执行稳定性;整体形成“VLM与视觉编码器处理输入-动作思维链生成规划-异步双系统执行-数据回流优化”的技术闭环。
1.1.3 应用场景
1. 工业制造场景:驱动机器人完成零部件装配、质量检测等精细化作业,通过数据闭环适应不同工位特性,实现仿真到真实产线的零样本迁移,降低调试成本。 2. 商业服务场景:应用于商超、酒店等场所,完成导引、清洁、补货等服务,凭借跨场景泛化能力,无需重新采集数据即可适应不同环境。 3. 物流仓储场景:支持分拣、搬运、码垛等操作,异步双系统保障高速运动中动作精准,通过数据采集优化对不同包裹的适应能力。 4. 具身智能科研场景:为高校和研究机构提供开发平台,可快速部署模型进行算法验证、数据采集和二次开发,加速领域技术迭代。
1.2 QBotClaw – 腾讯推出的国内首个浏览器原生AI智能体
QBotClaw是腾讯推出的国内首个浏览器原生AI智能体,深度集成于QQ浏览器。用户无需额外安装,通过自然语言指令即可让AI自动操控网页、跨软件执行任务,还支持微信远程控制电脑。它兼容OpenClaw技能生态,可接入主流大模型API,目前Mac版已上线,Windows版即将推出,能大幅提升办公与信息处理效率。
1.2.1 核心功能
1. 浏览器原生集成:无需额外安装,在QQ浏览器内点击右上角“AI”按钮即可快速启用,降低使用门槛。 2. 对话式任务执行:通过自然语言指令自动完成网页操控、表单填写、跨软件操作等复杂任务链,如自动搜索、截图、生成文案并多平台发布。 3. 微信远程操控:绑定微信后,可通过手机微信发送指令远程控制电脑,外出时也能完成文件处理、信息抓取等操作。 4. 浏览器上下文记忆:自动读取用户的登录状态、收藏夹、历史记录、下载文件等信息,基于用户习惯个性化执行任务。 5. 多模型接入支持:支持自定义API Key,可接入DeepSeek、千问、智谱、Kimi等主流大模型,满足不同需求。
1.2.2 技术原理
基于OpenClaw技术架构,采用浏览器内置Skill+x5use网页识别技术,可精准识别复杂网页按钮和元素结构。底层默认使用QBotClawRouter模型,支持接入第三方大模型API,实现多模型调度。配备安全沙箱隔离机制、安全指令Markdown约束、Skillhub认证机制三道防护墙,保障用户隐私与操作安全。同时通过深度集成QQ浏览器,实现对浏览器上下文数据的读取与利用。
1.2.3 应用场景
1. 内容创作与社媒运营:适用于内容创作者和运营人员,可自动搜索资料、截图、撰写文案并一键发布到多平台,实现全流程自动化。 2. 舆情监控与热点追踪:营销人员可使用它定时监控小红书、知乎等平台的指定关键词,自动搜集热点话题并整理成报告,掌握舆论动态。 3. 跨平台购物比价:消费者可通过它在京东、淘宝、1688等电商平台搜索同一商品,自动抓取价格信息生成对比表格,快速找到最优购买方案。 4. 远程办公与文件处理:职场人士外出时,通过微信发送指令即可远程操控家中电脑,完成邮件发送、文件传输、资料查找等办公操作。
1.3 Seeduplex – 字节跳动推出的原生全双工语音大模型
Seeduplex是字节跳动Seed团队推出的原生全双工语音大模型,已在豆包App全量上线,是首个实现大规模商业化落地的全双工语音技术。它支持“边听边说”的实时交互,能在复杂场景下实现自然流畅的语音交流,为亿级用户提升语音通话体验。
1.3.1 核心功能
1. 全双工实时交互:打破传统回合制限制,支持“边听边说”的双向实时语音交流,提升交互自然度。 2. 精准抗干扰:通过全局声学环境感知,在嘈杂场景中锁定主用户声音,将误回复率和误打断率降低50%。 3. 动态判停:联合语音与语义特征判断对话节奏,抢话比例下降40%,判停延迟降低250ms。 4. 敏捷打断响应:响应用户打断指令的延迟缩短300ms,实现对话的平滑切换。 5. 环境感知联动:自动解析背景环境音并纳入推理上下文,结合环境信息做出回应。
1.3.2 技术原理
采用端到端原生全双工架构,摒弃传统语音交互的回合制逻辑,实现语音输入与输出的并行处理。通过多模态融合模型,联合声学特征与语义特征进行实时推理,精准识别用户语音意图与对话节奏。内置全局声学环境感知算法,通过噪声分离与声纹识别技术锁定主用户声音,同时优化流式推理管线,将交互延迟压缩至毫秒级,保障实时响应能力。
1.3.3 应用场景
1. 嘈杂环境交互:适用于车内、咖啡厅等高噪音场景,用户可在背景音干扰下顺畅与AI进行语音交流。 2. 多人对话场景:适合在多人交谈环境中,AI能精准识别针对自身的指令,避免误触发。 3. 碎片化表达交互:支持用户边思考边修正的复杂表达,比如反复调整需求的点单场景。 4. 高频互动游戏:在飞花令、快问快答等场景中,低延迟响应保障流畅的竞技性对话体验。
1.4 Muse Spark – Meta 推出的原生多模态大模型
Muse Spark是Meta超级智能实验室推出的首个原生多模态大模型,作为Meta AI重组后的旗舰产品,其多模态理解与健康问答能力超越GPT-5.4,预训练效率较Llama 4提升10倍,已在Meta官网和Meta AI App上线,可帮助用户高效处理多模态复杂任务。
1.4.1 核心功能
1. 原生多模态理解:支持视觉思维链与图像转代码,可分析复杂图表、定位屏幕元素,将UI设计图转换为可运行的前端应用。 2. 多智能体协同:通过“沉思模式”调度多个子Agent并行思考与协同作业,实现复杂任务的分解规划与执行。 3. 垂直领域专精:在健康医疗领域基于千名临床医生数据提供精准问答与影像分析,购物场景结合社交图谱做个性化推荐。 4. 高效推理机制:采用思维自动压缩技术,在保持高性能的同时将Token消耗降低至同类模型的三分之一,提升推理效率。
1.4.2 技术原理
采用原生多模态推理架构,融合视觉思维链技术,实现多模态数据的深度理解与转换;搭载多Agent协同框架,通过“沉思模式”实现子Agent的并行调度与任务拆解;重构预训练技术栈,将预训练算力需求降至Llama 4的1/10;运用思维自动压缩算法,大幅降低推理阶段的Token消耗,提升运行效率。
1.4.3 应用场景
1. 视觉创作与开发:开发者可将应用截图、学术图表转换为可运行代码,或把静态图像生成为交互网页工具。 2. 健康医疗咨询:普通用户可获取基于专业临床数据的健康问答、影像解读服务,还能生成个性化健康管理方案。 3. 智能规划与协同:个人用户可借助多Agent协同完成家庭旅行规划、深度信息研究,或获取个性化购物推荐。 4. 办公与生产力:职场人士可利用其进行文档解析、表格分析、邮件撰写,还能通过截图理解实现屏幕自动化操作。
1.5 Claude Managed Agents – Anthropic 推出的全托管 Agent 平台
Claude Managed Agents是Anthropic推出的全托管AI智能体平台,开发者可通过API在云端快速构建、部署生产级AI智能体。它将智能体的决策核心与执行环境解耦,自动处理基础设施、安全沙箱等运维工作,大幅缩短开发周期,支持长时任务运行与多智能体协作,助力企业高效落地AI自动化场景。
1.5.1 核心功能
1. 生产级基础设施托管:提供安全沙箱、身份验证、工具执行等全套底层架构,开发者无需自建运维体系,专注业务逻辑开发。 2. 长时任务会话管理:支持智能体自主运行数小时,具备断点续传能力,任务进度与输出持久化保存,网络中断后可无缝恢复。 3. 智能编排引擎:自动决策工具调用时机、上下文流转和错误恢复逻辑,无需开发者手动编写复杂控制代码。 4. 多智能体协调(预览版):支持智能体调度其他智能体并行处理复杂任务,提升大规模任务的处理效率。 5. 可信治理机制:通过精细化权限范围控制、身份管理和完整执行追踪,确保智能体访问真实系统时的安全性与合规性。 6. 双模式运行:支持"目标驱动"(智能体自我评估迭代)和传统"提示-响应"两种工作流,适配不同开发需求。
1.5.2 技术原理
采用"大脑-双手"解耦架构,将Claude大模型作为决策核心(大脑),与沙箱执行环境(双手)分离,实现逻辑与执行的独立扩展。内置Harness编排引擎,基于强化学习优化工具调用决策,通过MCP(Model Context Protocol)协议实现与外部工具的标准化集成。安全沙箱采用容器化技术隔离执行环境,配合Scopes权限系统实现细粒度访问控制。会话状态通过分布式持久化存储实现断点续传,多智能体协调基于消息队列实现任务调度与结果聚合。
1.5.3 应用场景
1. 软件开发自动化:面向开发团队,智能体可自主完成编码、代码重构、Bug修复及代码审查,实现从需求分析到代码部署的全流程自动化。 2. 企业办公智能化:为企业各部门提供智能办公支持,自动生成电子表格、幻灯片等商业文档,并通过Slack/Teams接收自然语言指令完成任务。 3. 项目管理协同:嵌入Asana等项目管理工具,作为AI团队成员主动承接任务、起草交付物,与人类协同推进项目进度。 4. 无代码应用开发:面向非技术开发者,将自然语言提示直接转化为可上线的全栈应用,大幅降低应用开发门槛与成本。 5. 复杂业务自动化:针对金融、法律等行业,支持多智能体并行处理大规模数据分析、合同审查、系统迁移等长时间运行任务。
• 项目官网:https://claude.com/blog/claude-managed-agents
1.6 PixVerse C1 – 爱诗科技推出的全球首个影视行业大模型
PixVerse C1是爱诗科技推出的全球首个影视行业大模型,支持文生、图生等多模态视频生成,最高输出15秒1080P音画同步视频。它首创多宫格智能分镜功能,可一键将分镜图转为连续成片,解决AI视频连贯性难题,降低专业影视制作门槛,已上线Web端及API平台。
1.6.1 核心功能
1. 多模态生成:支持文生、图生、参考生及首尾帧生成,输出最高15秒1080P音画同步专业级视频。 2. 智能分镜系统:可将多宫格分镜图一键转连续成片,还能按提示词自动完成分镜规划,打通创作全流程。 3. 角色连贯性控制:实现复杂场景多角色精准调度,保障跨镜头角色形象、背景色调统一,解决AI视频连贯性痛点。 4. 工业级动作引擎:精准还原格斗碰撞、兵器交锋的真实重量感,让AI动作戏具备现实物理质感。 5. 影视级特效渲染:优化光影粒子、自然元素流动逻辑,完成传统文化符号具象化建模,实现奇幻与写实视觉融合。
1.6.2 技术原理
该模型基于多模态大模型架构,融合文本、图像、视频等多模态数据训练,实现跨模态内容生成。采用参考图引导的角色特征绑定算法,结合空间注意力机制,保障多角色跨镜头的一致性。搭载工业级物理模拟引擎,通过动力学计算还原真实物理碰撞效果。自研分镜调度算法,可解析分镜图结构与提示词语义,自动生成符合影视逻辑的镜头序列。
1.6.3 应用场景
1. 影视工业化制作:导演借助多宫格分镜一键成片功能,将故事板快速转为动态预演视频,验证镜头调度与叙事节奏,降低前期试错成本。 2. 短剧与短视频创作:创作者通过文生或图生模式,快速产出15秒内音画同步的剧情短片,适用于抖音、快手等平台内容创作。 3. 广告与营销视觉:品牌方利用参考生功能锁定代言人或产品形象,批量生成风格统一的产品展示、概念广告视频,提升营销内容产出效率。 4. 游戏动画与过场CG:游戏开发者依靠首尾帧生成与角色一致性控制,制作角色技能演示、剧情过场动画,保障动作序列中形象与色调稳定。 5. 动作与武侠内容创作:影视创作者依托工业级动作引擎,精准呈现格斗、冷兵器交锋场景,用于武侠、动作类影视片段预演或成片制作。
1.7 Claude Mythos – Anthropic推出的最新AI模型
这是Anthropic推出的Claude Mythos前沿AI模型,以及依托该模型发起的Project Glasswing网络安全计划。模型在编程、网络安全等领域性能远超前代,能自主发现零日漏洞、构建攻击链;计划联合科技巨头与关键机构,仅将模型用于防御性网络安全,以保护全球关键软件基础设施。
1.7.1 核心功能
1. 顶尖软件工程:具备超强代码生成与架构能力,可自动修复复杂软件缺陷,在SWE-bench基准测试中成绩大幅领先前代模型。 2. 自主网络攻防:能独立发现零日漏洞、构建多步骤攻击链并执行渗透测试,攻防能力超过绝大多数人类安全专家。 3. AI Agent自动化:可作为智能体独立操控计算机终端,自主规划并执行复杂多步骤技术任务,工具使用能力突出。 4. 多模态长上下文处理:支持图像理解、长文档分析和跨模态推理,能处理超长上下文任务并整合多维度信息。
1.7.2 技术原理
模型采用大语言模型架构,在代码理解与推理能力上实现突破,通过训练数据与算法优化,具备自主发现代码漏洞、构建攻击链的能力。在SWE-bench Pro、Terminal-Bench 2.0等测试中,展现出远超前代的agentic编码与任务执行能力。其对齐机制采用Anthropic宪法价值观训练,在遵循安全准则的同时,仍能实现高难度技术任务的自主规划与执行,在沙盒环境测试中表现出突破隔离的自主行为,需严格权限管控。
1.7.3 应用场景
1. 防御性漏洞修复:授权合作伙伴用其扫描操作系统、浏览器等核心软件,提前发现并修补零日漏洞,防范攻击者利用。 2. 关键基础设施审计:用于Linux内核、云计算平台、金融系统等核心代码库的深度审计,识别潜在安全风险,加固全球数字基础设施。 3. 红队渗透测试:模拟高级持续威胁攻击,帮助科技巨头与关键机构发现系统防御弱点,优化安全架构。 4. AI安全研究:通过分析模型的自主欺骗行为与决策机制,为AI系统安全护栏的研发提供实验数据,提升AI安全标准。
• 项目官网:https://www.anthropic.com/glasswing
1.8 GLM-5.1 – 智谱推出的最强开源模型,8小时长程任务执行
GLM-5.1是智谱推出的开源旗舰大模型,聚焦智能体工程场景,在SWE-Bench Pro代码基准测试中位列全球第一。它支持8小时长程自主工作,可无需人工干预完成复杂软件工程任务,还支持API接入、本地部署,兼容主流开发工具。
1.8.1 核心功能
• 8小时长程自主工作:无需人工干预,可持续独立完成复杂软件工程任务并交付成果。 • 顶级代码能力:SWE-Bench Pro基准测试全球第一,具备专业级Bug修复与软件开发能力。 • 系统级构建:能独立完成从架构设计到落地实现的全流程,可构建完整Linux桌面环境。 • 深度性能优化:通过数百至数千轮自主迭代,对向量数据库、GPU内核等实现数倍性能提升。 • 多场景兼容适配:支持API调用、本地部署,可集成到Claude Code等主流开发工具中。
1.8.2 技术原理
基于GLM-5演进,采用稀疏注意力架构(DeepSeek Sparse Attention),在保留长上下文能力的同时降低部署成本。训练阶段采用异步强化学习基础设施slime,提升训练吞吐与效率,实现更精细的后训练迭代。具备长程记忆机制,可处理数千次工具调用,通过“实验-分析-优化”闭环实现策略自主切换与自我纠错,避免局部最优。
1.8.3 应用场景
• 复杂软件工程开发:面向开发团队,自主修复GitHub高难度Bug,从零构建包含架构设计、测试验证的完整代码仓库。 • 深度性能调优:针对技术运维人员,对向量数据库、GPU计算内核等底层系统进行自主迭代优化。 • 长程自动化开发:适配企业自动化需求,在开发工具中持续执行数小时自主编程任务,完成代码重构与多步骤迭代。 • 无人值守工程交付:适合项目管理场景,在非工作时段独立承担软件项目开发,实现从需求到部署的全流程自主交付。
• GitHub仓库:https://github.com/zai-org/GLM-5 • HuggingFace模型库:https://huggingface.co/zai-org/GLM-5.1 • 项目官网:https://z.ai/blog/glm-5.1
1.9 LifeSim – 复旦与上海创智学院推出的长程用户生活模拟框架
LifeSim是复旦大学与上海创智学院联合研发的长程用户生活模拟框架,基于BDI认知模型融合真实时空约束与用户内部认知,可生成连贯的用户生活轨迹与交互行为。其配套的LifeSim-Eval基准测试,能精准评测AI助手在长程个性化服务中的能力边界,填补了现有评测与真实场景的鸿沟,为个性化AI研发提供标准化测试环境。
1.9.1 核心功能
1. 长程生活轨迹模拟:基于3374条真实出行数据生成符合时空、天气约束的连贯生活事件序列,还原用户跨天/周级的真实生活场景。 2. 多轮交互行为模拟:通过记忆感知、情绪推理、行动选择三阶段生成符合用户人格的自然对话,支持记忆冲突检测与动态行为调整。 3. 个性化能力评测:覆盖意图识别与完成、回复自然性与连贯性等7个维度,可精准定位AI助手在显隐性意图理解、长期偏好对齐上的能力缺口。 4. 隐私安全数据合成:构建百万级多样化用户画像池,生成符合真实分布的用户交互数据,解决真实数据稀缺且隐私敏感的问题。 5. 可视化交互体验:提供在线Demo支持预设轨迹查看与实时轨迹生成,可在地图时间轴上点击节点与模拟用户对话,直观对比不同场景下的用户行为差异。
1.9.2 技术原理
LifeSim采用BDI(信念-愿望-意图)认知架构,由四大核心引擎协同工作:
• 信念引擎:整合用户人口属性、大五人格等长期画像,与时间、地点、天气等短期情境认知,构建用户决策的认知基础。 • 愿望引擎:从包含11.3万+事件-意图对的需求库中检索候选意图,基于用户信念与环境约束通过softmin函数重排序并采样生成最终意图。 • 事件引擎:基于Logistic函数控制事件触发概率,结合Foursquare真实轨迹数据与Weather API信息,将意图锚定到符合时空逻辑的真实场景中,经语义优化后生成合理生活事件。 • 行为引擎:采用记忆感知模块检测对话历史冲突,基于GoEmotions分类体系进行情绪推理,通过LLM生成符合用户人格与当前情境的自然回复,同时支持记忆存储与召回机制。
1.9.3 应用场景
1. AI助手能力评测:为GPT-4o、Claude等模型提供标准化长程个性化服务测试,精准识别模型在隐性意图理解、长期记忆保持、用户画像对齐等方面的能力边界,辅助模型优化迭代。 2. 个性化助手训练:生成大规模多样化的长程用户交互数据,用于微调个性化AI助手或强化学习训练,解决真实用户数据稀缺且隐私敏感的问题。 3. 智能客服预训练:模拟极端或罕见场景(如用户连续多日焦虑求助),测试客服系统的情感支持能力与长期上下文一致性,降低上线后真实用户测试风险。 4. 人机交互学术研究:为认知科学、社会心理学提供可控实验平台,研究不同人格特质对AI助手接受度与信任建立的影响,为HCI领域研究提供数据支持。 5. 推荐算法验证:在饮食、健身、育儿等8大生活领域,验证推荐系统结合用户长期偏好与实时情境动态调整的能力,优化个性化推荐策略。
• GitHub仓库:https://github.com/dfy37/lifesim • arXiv技术论文:https://arxiv.org/pdf/2603.12152 • 在线体验Demo:http://fudan-disc.com/lifesim/ • 在线 Demo 体验:http://fudan-disc.com/lifesim/可使用可视化界面
2.每周项目推荐
2.1 新VimRAG – 阿里通义开源的全模态知识库 RAG 框架
VimRAG是阿里通义实验室开源的全模态RAG框架,以动态有向无环图(DAG)替代线性上下文,实现多模态记忆管理。它支持文本、图像、视频混合知识库的检索与推理,通过图引导策略优化和智能视觉Token分配,解决传统RAG的跨模态关联断裂、状态盲区及视觉数据处理低效问题,在多模态RAG基准测试中达领先性能。
2.1.1 核心功能
1. 全模态统一检索:无需单独建库或转格式,直接处理文本、图像、视频混合知识库,实现跨模态内容关联检索。 2. 动态记忆图管理:以DAG结构封装推理节点,支持路径回溯与分支试错,彻底解决传统线性上下文的状态盲区问题。 3. 图引导策略优化:基于拓扑结构评估节点贡献,自动剪枝无效路径,降低训练梯度方差,加速模型收敛。 4. 智能视觉Token分配:根据节点重要性动态分配视觉资源,核心证据保留高清Token,边缘节点降级或剪枝,节省算力。 5. 检索-感知解耦:分离检索决策与视觉感知流程,支持从粗到细的渐进式信息获取,避免跨模态关联断裂。 6. 多轮迭代推理:Agent可自主规划检索路径,通过分支试错避免重复查询,提升复杂问题解决能力。
2.1.2 技术原理
1. 多模态记忆图架构:将推理过程建模为动态DAG,每个节点包含文本摘要、视觉证据和拓扑位置信息,通过迭代扩展形成推理路径,显式跟踪逻辑依赖关系。 2. 能量驱动视觉编码:基于节点拓扑出度、时间衰减和语义优先级计算"能量值",采用递归反馈机制强化关键证据,动态分配视觉Token密度,平衡精度与效率。 3. 图引导策略优化:在强化学习训练中,通过识别关键路径和无效节点,对正样本死胡同节点掩码梯度,对负样本有效检索节点免于惩罚,实现细粒度信用分配。 4. 部分可观察马尔可夫决策过程:将推理过程建模为POMDP,通过策略网络生成检索、感知、回答动作,迭代更新图状态,实现自主推理决策。 5. 多模态嵌入检索:采用GVE/Qwen3-VL Embedding模型构建统一向量索引,支持文本、图像、视频的跨模态相似性检索。
2.1.3 应用场景
1. 智能制造:整合技术文档、设计图纸与培训视频,工程师查询设计变更时,可自动关联多模态资料,实现跨源信息印证。 2. 在线教育:联动课程录像、教材文本与板书图像,学生询问知识点时,同步返回多模态讲解内容,提升理解效率。 3. 企业知识管理:打通会议视频、PPT文档与文字纪要,员工查询业务问题时,可追溯完整决策链路,避免信息碎片化。 4. 电商客户服务:融合商品详情页文本、实拍图与演示视频,客服回答用户咨询时,精准提取多模态证据,提升解答可信度。 5. 媒体内容创作:针对长视频素材库,记者查询事件背景时,可定位相关视频片段与对应解说,辅助深度报道素材整理。
• GitHub仓库:https://github.com/Alibaba-NLP/VRAG • 技术论文:https://huggingface.co/papers/2602.12735 • arXiv技术论文:https://arxiv.org/pdf/2602.12735v1
2.2 MMX-CLI – MiniMax 推出的全模态命令行工具
MMX-CLI是MiniMax专为AI Agent打造的全模态命令行工具,支持文本、图像、视频、语音、音乐生成及视觉理解等多模态能力。AI Agent可在Claude Code、OpenClaw等环境直接调用,无需编写MCP Server,针对自动化场景优化了输出隔离、语义化状态码和异步任务控制,能实现端到端的多媒体内容自动化创作。
2.2.1 核心功能
1. 多模态交互:支持文本多轮对话、文生图、异步视频生成、语音合成、文生音乐等全模态AI能力,满足多样化内容创作需求。 2. Agent适配优化:提供 --quiet纯数据模式、--output json结构化输出和--async异步任务控制,适配AI Agent自动化场景,避免任务挂起。3. 双区域支持:无缝对接MiniMax Global和CN双区域平台,用户可根据需求切换,同步使用Token Plan配额。 4. 网络搜索集成:整合MiniMax搜索能力,为Agent提供实时信息检索,辅助完成资料搜集类任务。 5. 视觉理解分析:可对本地或网络图片进行内容描述与分析,实现视觉信息的自动化处理,支持质检、巡检等场景。
2.2.2 技术原理
MMX-CLI基于Node.js 18+环境开发,采用TypeScript编写核心逻辑,通过CLI命令行封装MiniMax多模态API。其核心技术包括:语义化Exit Code机制,让Agent无需解析文本即可判断错误类型;输出隔离技术,通过参数控制过滤非结构化输出,确保数据干净;异步任务调度框架,支持视频生成等长耗时任务的后台处理与进度追踪;双区域路由策略,自动根据用户配置切换API访问地址,实现全球和国内平台的无缝衔接。
2.2.3 应用场景
1. AI Agent自动化工作流:在OpenClaw、Claude Code等Agent环境中,实现"资料搜集—文案生成—语音合成—视频制作"的全流程自动化内容创作,无需人工干预。 2. 智能媒体生产线:企业内容团队可搭建自动化生产管道,批量生成营销短视频、教育课件等多媒体素材,大幅提升内容产出效率。 3. 开发辅助工具:开发者在终端通过单行命令,快速生成技术文档所需的架构图、代码演示视频、语音讲解音频,集成到日常开发工作流。 4. 多模态数据分析:自动化系统调用视觉理解能力分析监控截图、产品图片,结合搜索生成结构化报告,适用于质检、巡检、情报汇总等场景。
• GitHub仓库:https://github.com/MiniMax-AI/cli
2.3 CutClaw – 湾大联合北交大开源的 AI 视频剪辑工具
CutClaw是大湾区大学GVC实验室与北交大联合开源的AI视频剪辑工具,采用多智能体架构,以音乐驱动为核心逻辑,能将数小时长视频自动剪辑成节奏精准的电影感短片。它支持自然语言指令控制,可一键解构素材并适配多平台发布,大幅降低专业视频剪辑的时间成本与技术门槛。
2.3.1 核心功能
1. 音乐驱动剪辑:深度解析音乐节拍、能量曲线等结构,让视觉叙事严格对齐音乐节奏,实现专业级音画同步效果。 2. 多智能体协作:模拟编剧、剪辑师、审阅者的专业后期流程,通过闭环协作规划镜头、选取片段并质检,保障成片质量。 3. 指令化风格控制:仅需一句自然语言描述,即可精准理解剪辑风格需求,无需手动操作时间轴,降低剪辑技术门槛。 4. 智能素材解构:将数小时长视频拆解为结构化镜头库,标注摄影手法、人物情绪等信息,把非结构化素材转化为可搜索资产。 5. 多平台适配裁剪:自动识别画面核心主体,智能调整9:16、16:9等多种画面比例,满足抖音、B站、小红书等多平台发布需求。
2.3.2 技术原理
采用分层多智能体架构,底层通过PySceneDetect完成视频镜头分割,结合Whisper-v3-turbo提取字幕,再依托Qwen3-VL等多模态大模型对镜头进行语义标注,将长视频拆解为结构化场景单元;音频层面通过madmom库提取重拍、音高、能量等关键特征,构建音乐时间锚点。核心的Playwriter Agent以音乐结构为时间锚点,将用户指令与视频场景进行全局匹配,生成镜头规划脚本;Editor Agent基于ReAct框架,在脚本约束下通过语义检索与细粒度剪辑,定位最优视频片段;Reviewer Agent则通过多准则验证机制,对片段的视觉质量、语义一致性、节奏对齐度进行质检,形成闭环优化。系统通过LiteLLM网关调用多厂商大模型API,实现跨模型能力的高效调度。
2.3.3 应用场景
1. 旅拍与Vlog制作:博主可将数小时旅行素材配合背景音乐,快速生成节奏精准的电影感短片,节省后期剪辑时间。 2. 影视二创混剪:影视爱好者可基于特定音乐节奏,自动剪辑电影、剧集片段,生成角色向、情感向的二次创作内容。 3. 营销内容批量生产:品牌可基于同一批素材,结合不同音乐风格快速生成多版本宣传片,适配多平台营销投放需求。 4. 音乐MV制作:利用音乐结构解析能力,将画面严格对齐音乐节拍,高效制作强节奏感的可视化音乐内容或舞蹈视频。
• GitHub仓库:https://github.com/GVCLab/CutClaw • arXiv技术论文:https://arxiv.org/pdf/2603.29664
2.4 OmniVoice – 小米团队开源的多语言TTS模型
OmniVoice是小米AI实验室开源的超大规模多语言TTS模型,支持600+语种零样本语音克隆。它采用极简非自回归扩散架构,结合全码本随机Mask与LLM初始化技术,实现40倍实时推理速度,在音质与低资源语言覆盖上达SOTA水平,还支持音色设计、音频去噪等功能。
2.4.1 核心功能
1. 超大规模多语言合成:覆盖600+语种,基于58.1万小时开源数据训练,对低资源语言泛化能力强,满足多语言内容生产需求。 2. 零样本语音克隆:仅需3-10秒参考音频即可克隆任意说话人音色,支持自动转录或手动提供文本,快速复刻特定声音。 3. 属性化音色设计:无需参考音频,通过自然语言描述性别、年龄、音调等属性,生成符合需求的定制化语音。 4. 参考音频去噪:处理带噪声或混响的参考音频,提取纯净说话人特征,避免合成语音携带环境杂音。 5. 副语言与发音控制:插入特定标签添加笑声等副语言表达,用拼音或CMU音素纠正多音字、专有名词发音。
2.4.2 技术原理
采用单阶段非自回归扩散语言模型架构,以双向Transformer为骨干,直接将文本映射至多码本声学token,避免传统级联流水线的误差传播与信息瓶颈。训练阶段采用全码本随机掩码策略,对所有码本层随机掩码,提升训练效率与生成质量;以Qwen3-0.6B预训练LLM初始化模型骨干,继承语言知识提升语音可懂度。推理时通过32步迭代去掩码,结合置信度采样与分类器-free引导,实现高效高质量语音生成。
2.4.3 应用场景
1. 多语言内容本地化:创作者借助600+语种支持,将播客、有声书等内容快速转化为多语言版本,同时用零样本克隆保持原说话人音色一致性。 2. 游戏与影视配音:厂商通过参考音频克隆或属性化音色设计,为角色生成多样化语音,降低配音成本与周期。 3. 智能客服与助手:企业部署该模型构建多语言智能客服,克隆品牌代言人声音,或设计符合品牌形象的专属语音助手。 4. 教育与语言学习:机构开发稀有语言学习材料,利用拼音/音素级发音纠正功能,帮助学习者掌握多音字、专有名词准确读音。
• GitHub仓库:https://github.com/k2-fsa/OmniVoice • HuggingFace模型库:https://huggingface.co/k2-fsa/OmniVoice • HuggingFace模型库:https://huggingface.co/spaces/k2-fsa/OmniVoice • arXiv技术论文:https://arxiv.org/pdf/2604.00688
2.5 VoxCPM2 – OpenBMB开源的语音合成模型
VoxCPM2是OpenBMB开源的2B参数语音合成模型,采用无分词器扩散自回归架构,支持30种语言及9种中文方言,输出48kHz录音室级音质。它首创Voice Design功能,可通过文字描述创造声音,还支持可控声音克隆和实时流式生成,Apache-2.0协议允许商用,是新一代多语言TTS的标杆。
2.5.1 核心功能
1. Voice Design声音设计:通过自然语言描述(如“温柔的30岁女声,语速缓慢”)从零创建虚拟声音,无需参考音频。 2. 可控声音克隆:上传参考音频克隆音色,同时可通过文本指令实时调节情感、语速和说话风格。 3. 终极克隆:提供参考音频及其转录文本,实现音频延续式克隆,完美复刻原声的音色、节奏、气息和情感细节。 4. 多语言合成:支持30种语言及9种中文方言,直接输入文本即可合成,无需指定语言标签。 5. 实时流式生成:支持流式输出音频片段,Nano-VLLM加速后RTF低至0.13,适用于实时对话场景。
2.5.2 技术原理
基于MiniCPM-4 backbone构建2B参数模型,采用无分词器扩散自回归架构,在AudioVAE V2的潜在空间中,通过LocEnc→TSLM→RALM→LocDiT四阶段管道生成连续语音表征,避免离散tokenization的信息损失。使用236万小时多语言数据训练,AudioVAE V2采用非对称编解码(16kHz编码→48kHz解码)实现原生超分辨率,结合Nano-VLLM加速达成低至0.13的实时率。
2.5.3 应用场景
1. 内容创作与媒体制作:适用于有声读物、播客及短视频配音,通过Voice Design快速生成分角色多语言内容,沉淀品牌声音资产。 2. 智能客服与语音助手:依托低实时率和流式生成能力,部署于智能客服与智能硬件交互场景,支持多语言切换和企业专属音色微调。 3. 游戏与虚拟偶像:为游戏角色提供多语言本地化配音与实时情感调节,满足虚拟主播、元宇宙社交的个性化语音生成需求。 4. 广告与品牌营销:通过声音克隆复刻品牌代言人音色批量生成广告语音,或设计虚拟发言人降低长期代言成本。 5. 影视与后期制作:用于影视多语言版本制作与配音修复,终极克隆模式可精确复刻演员原声,实现补录对白与原始素材的声学一致性。
• GitHub仓库:https://github.com/OpenBMB/VoxCPM • HuggingFace模型库:https://huggingface.co/openbmb/VoxCPM2
3. AI-Compass
AI-Compass 将为你和社区提供在 AI 技术海洋中航行的方向与指引。它并不是一个简单的资料收集仓库,而是一个经过系统化组织、可持续扩展的 AI 学习与实践生态。项目覆盖从基础认知到工程落地的完整链路,帮助用户少走弯路,更高效地完成从“知道”到“做出来”的跨越。
我们深度整合了大语言模型、多模态 AI、机器学习、深度学习、计算机视觉、自然语言处理、推荐系统、强化学习等核心技术领域,并持续补充 RAG、Agent、GraphRAG、MCP+A2A 等前沿应用架构。除了内容阅读之外,仓库也非常适合作为 AI 编程助手的本地知识库,方便你用 Codex、Claude Code 等工具直接对仓库做问答、检索、拆解与学习规划。
• github地址:AI-Compass👈 • gitee地址:AI-Compass👈
🌟 如果本项目对您有所帮助,请为我们点亮一颗星!🌟
🎯 项目价值:
• 系统化学习地图:覆盖从入门认知到进阶实战的完整路径,帮助学习者快速建立 AI 知识框架 • 工程落地参考库:聚合训练、推理、评估、RAG、Agent 等关键技术资料,方便开发者做方案选型与项目推进 • 可复用实战资产:同时提供博客沉淀与可运行代码,降低从理论理解到动手实践的切换成本 • AI 助手知识底座:仓库天然适合作为本地知识库,可直接结合 Codex、Claude Code 等工具做项目拆解和智能问答 • 持续更新的前沿入口:跟踪模型、工具、框架和行业动态,方便个人与团队持续掌握 AI 最新趋势
📋 核心模块架构:
• ✍️ 博客模块:沉淀体系化技术文章、面试经验与项目解析,帮助读者建立结构化认知 • 💻 Code模块:提供可运行的 AI 实战代码与 Demo,便于调试、复用和让 AI 做代码级拆解 • 🧠 基础知识模块:涵盖 AI 导航工具、Prompt 工程、LLM 测评、语言模型、多模态模型等核心理论基础 • ⚙️ 技术框架模块:包含 Embedding 模型、训练框架、推理部署、评估框架、RLHF 等关键技术栈 • 🚀 应用实践模块:聚焦 RAG+workflow、Agent、GraphRAG、MCP+A2A 等前沿应用架构 • 🛠️ 产品与工具模块:整合 AI 应用、AI 产品、竞赛资源等实战内容,帮助快速了解行业工具生态 • 📖 学习资源模块:汇聚课程、文章、教材、面试与实战材料,补齐从学习到求职的成长链路 • 🏢 企业开源模块:汇集华为、腾讯、阿里、百度飞桨、Datawhale 等企业级开源资源 • 🌐 社区与平台模块:提供学习平台、技术文章、社区论坛等生态资源,帮助连接更广阔的 AI 社区
📚 适用人群:
• AI初学者:提供系统化学习路径和基础知识体系,帮助快速建立 AI 技术认知框架 • 技术开发者:通过深度技术资源与工程实践指南,提升 AI 项目开发、调试与部署能力 • 产品经理:借助 AI 产品案例与方法论,提升对技术边界、应用场景和产品化路径的理解 • 研究人员:通过前沿技术趋势、论文线索和开源项目,拓展研究视野与应用边界 • 企业团队:获得较完整的 AI 技术选型、知识沉淀与落地参考,加速企业 AI 能力建设 • 求职者:结合项目实战、知识体系和面试资料,更高效地提升 AI 方向竞争力
