 夜雨聆风
夜雨聆风
AI Agent 是怎么管好自己的"记忆"的?
OpenClaw 上下文工程:从消息路由到 Token 压缩的完整拆解
技术深度 · 约 4500 字 · 阅读约需 18 分钟
Agent 架构上下文工程Session 管理Token 压缩Prompt Cache
如果你用过 AI 助手处理跨平台消息——Telegram 群聊、Discord 线程、微信,再加上各种私聊——你大概遇到过这种情况:Agent 突然忘了五分钟前的内容,或者把两个不相关的对话上下文混在一起回复。
这不是模型能力的问题,而是上下文工程(Context Engineering)没做好的问题。OpenClaw 在这件事上花了很多心思,这篇文章从架构设计到源码细节,把它拆开来看一看。
先把问题说清楚
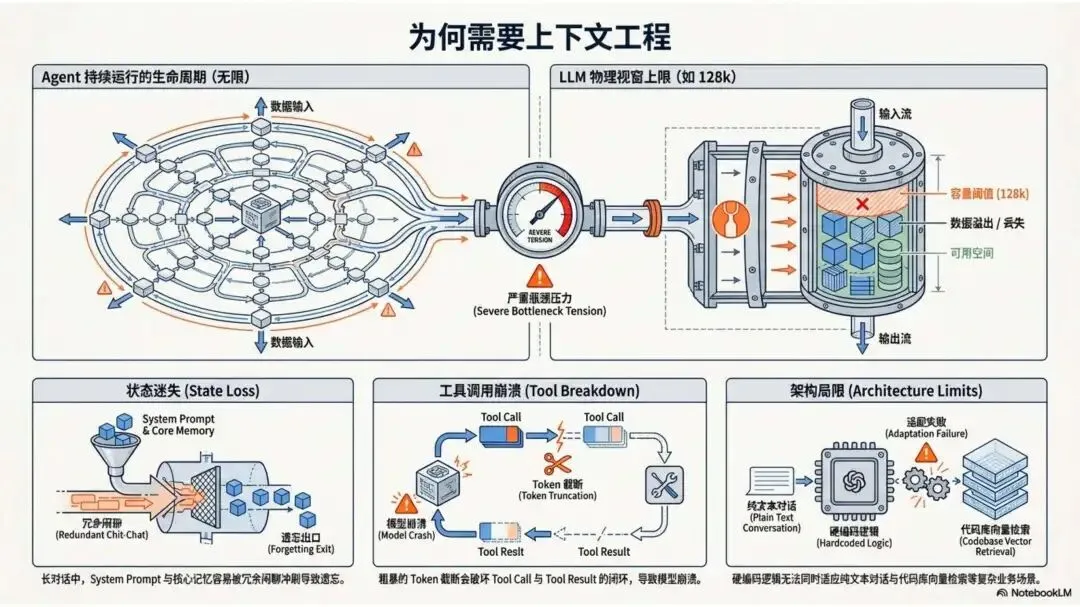
▲ 为何需要上下文工程:Agent 生命周期无限,LLM 上下文窗口有限,中间的张力是所有问题的根源
表面上看,上下文工程要解决的是 Token 不够用的问题。但 OpenClaw 面对的实际上是两个层次的挑战,而且两者需要完全不同的解法。
第一层:路由混乱。在多平台、多账号、多群组的环境里,消息来自四面八方。Telegram 的 group ID 是数字,Matrix 的 room ID 是字符串,Discord 还有服务器、频道、线程三级嵌套。Agent 必须准确判断:这条消息该谁处理?属于哪个对话线程?
第二层:上下文窗口有限。即便路由对了,长期运行的 Agent 积累的对话历史会远超 LLM 的物理上下文上限(如 128k tokens)。如何压缩、压缩什么、压缩时不破坏工具调用的完整性——这些都是工程难题。
核心思路:OpenClaw 把这两层问题分给了两套完全独立的机制——底层的 SessionKey 路由系统,和上层的 Context Engine。两层各司其职,互不干扰。
上下文生命周期的完整编排
在深入各个模块之前,先看整体流程。OpenClaw 的上下文处理由 attempt.ts 统一编排,每次 Agent 运行都会经历这样一条流水线:
用户输入 / 触发器
↓
环境感知:确定 Workspace / Channel / Tool / 当前时间
↓
引导组装:读取 AGENTS.md、soul.md、Skills 列表等
↓
Bootstrap 预算检查:预计算引导文件 Token 消耗,超标则截断并发警告
↓
上下文组装:生成结构化的 System Prompt(含稳定化处理)
↓
对话历史注入
↓
Token 预估 ──── 合规 ────→ 调用模型
↑ |
└── 超出 ← Compaction(自动摘要 / 截断 / 修复)这条流水线有几个值得注意的特点:Compaction 是一个循环——压缩后重新估算 Token,如果还超就继续压,直到合规为止。稳定化处理夹在组装和历史注入之间,专门为 Prompt Cache 服务。Bootstrap 预算检查不是静默截断,而是带警告的显式告知。这三个细节后面会分别展开。
底层:SessionKey 与渠道归一化
OpenClaw 引入的最关键抽象是 SessionKey——一把"对话定位钥匙",编码了这条对话的完整上下文信息:在哪个平台、哪个账号、哪个群组、哪个线程里发生的。
私聊: agent:<agentId>:main群组: agent:<agentId>:telegram:group:<groupId>线程: agent:<agentId>:discord:group:<serverId>:thread:<threadId>Topic: agent:<agentId>:telegram:group:<groupId>:topic:<topicId>同一个群组的不同线程,永远拥有不同的 SessionKey,历史记录物理隔离,不会相互污染。
八级路由优先级
路由解析遵循"合取匹配"原则:配置里写的所有字段必须同时匹配,而不是任意一个匹配。优先级从具体到通用共分八级——从"精确匹配到单个用户",一路降到"任何消息都兜底"的默认 Agent。
为什么不允许模糊匹配?因为在多 Bot 账号并存的服务器里,模糊匹配会让同一条消息在不同时刻被不同 Agent 处理——这就是"路由彩票"现象,生产环境的噩梦。
上下文增强:告诉模型"谁在说话"
历史消息注入采用"Pending-only"逻辑:只注入自上次回复后尚未处理的消息,既节省 Token,又防止重复处理。群聊中 LLM 天然不知道每条消息是谁发的,系统通过 [from: Sender Name] 标签显式标注,弥补这个认知缺口。
一个容易被忽视的细节:在多 Agent 广播模式下,如果 Bot A 的回复进入消息流,Bot B 必须识别出这不是人类的消息。OpenClaw 对 WhatsApp Web 专门实现了批处理字符串比对算法——没有这个机制,多 Bot 群组会陷入"机器人互聊"的死循环。
上层:Context Engine 的四阶段生命周期
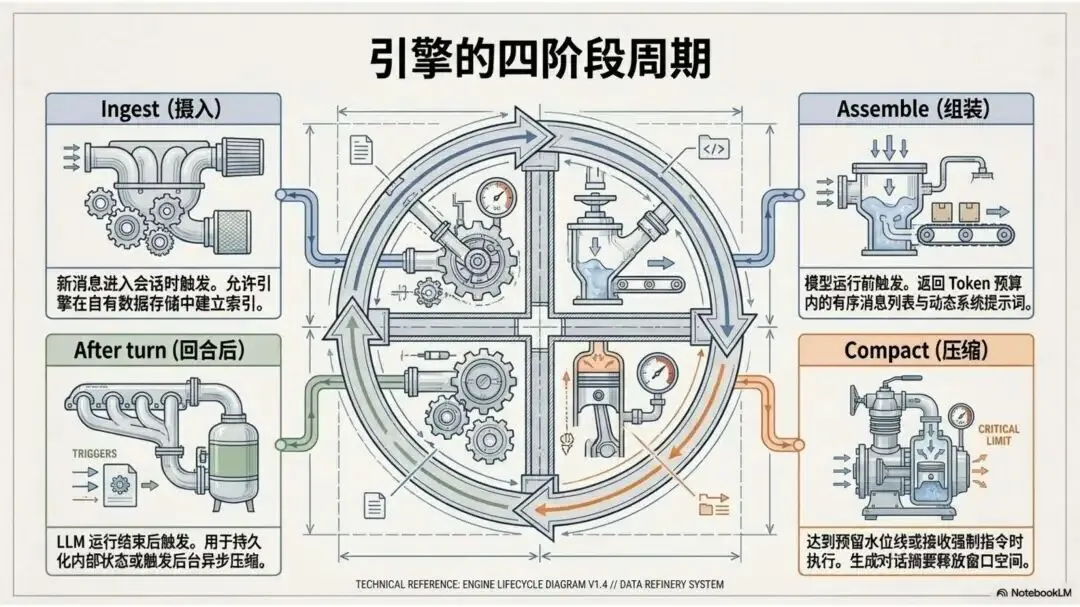
▲ Context Engine 四阶段周期:Ingest → Assemble → Compact → After Turn
Context Engine 决定的是:在模型每次运行时,它的"视野"里有什么。整个引擎围绕四个严格分离的阶段运转。
Ingest(摄入)
新消息到达时触发,负责把消息落盘到 Session JSONL 文件,同时允许外部插件建立索引。这一阶段不组装 Prompt,只管存储——存算分离使得后续可以随时更换组装策略,而不影响历史数据。
Assemble(组装)
模型运行前触发,把历史记录、工具定义、系统提示词、Workspace 文件等碎片拼成一个完整的 Prompt 快照。返回值里必须包含 estimatedTokens——这是系统判断是否触发压缩的唯一水位计。
Compact(压缩)
当估算 Token 量逼近 contextWindow - reserveTokens 水位线时触发。这是工程复杂度最高的部分——下面单独展开。
After Turn(回合后)
LLM 推理结束后触发,用于持久化状态或同步后台任务。Memory 插件在这里完成异步写入,与推理逻辑完全解耦。
System Prompt 的动态组装
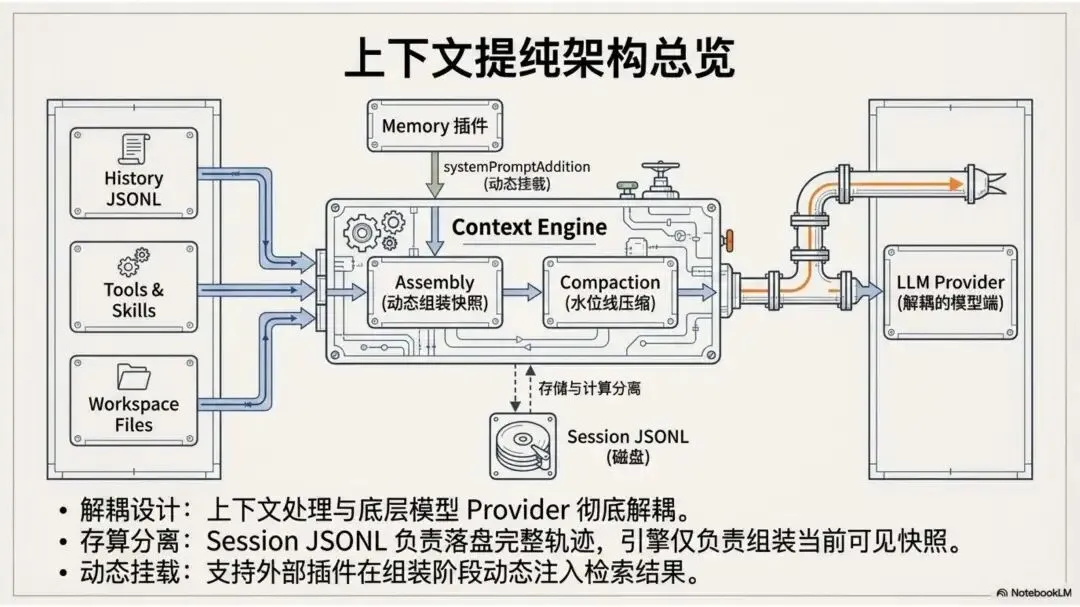
▲ 整体架构:History、Tools、Workspace 文件流入 Context Engine,组装后送往 LLM Provider
System Prompt 并不是一段静态文字,而是四层内容在运行时叠加的结果(源码入口:system-prompt.ts 的 buildEmbeddedSystemPrompt):
第一层(最底):OpenClaw 核心接管层,覆盖供应商默认 Prompt,注入基础交互规范。
第二层:基础元数据——工具列表、调用说明、宿主信息与系统时间戳。
第三层:动态系统提示词(systemPromptAddition),支持 Memory 插件在此阶段追加召回结果。
第四层(最顶):Workspace 引导文件,包括 identity.md、soul.md(定义角色性格)、AGENTS.md、TOOLS.md 等 Agent 个性化配置。
Skills 懒加载:把指令当资源
这是整个系统里最有意思的一个设计。相比把所有领域指令直接塞进 System Prompt,OpenClaw 引入了一套 Skills 懒加载机制:System Prompt 里只告诉模型"你有哪些可用技能",模型在需要时才通过 read 工具去读取具体的 SKILL.md 文件。
这个设计的收益是双重的:一方面极大节省了基础上下文(几十个技能的完整指令可能有数万 Token,而懒加载只需要几百 Token 的目录);另一方面也符合"按需加载"的工程直觉——不用的指令不应该占据有限的视窗空间。
设计哲学一:Instruction-as-Resource——将复杂的领域指令视为可检索的资源,而非静态嵌入的文本。这与数据库索引的思路如出一辙:你不会把整张表放进内存,你只会在需要时查询。
⚠️ 使用者需要警惕的边界:Bootstrap 预算管理(bootstrap-budget.ts)会预检这些引导文件的 Token 消耗。如果放入的文档过大,系统会自动截断并向模型发出显式警告(bootstrapPromptWarning),告知哪些文件因为预算问题没能完整装载。注意:这里是带警告的显式截断,而不是静默失忆——这与 MEMORY.md 超限时的行为不同。
Compaction:在遗忘边界上的工程细节
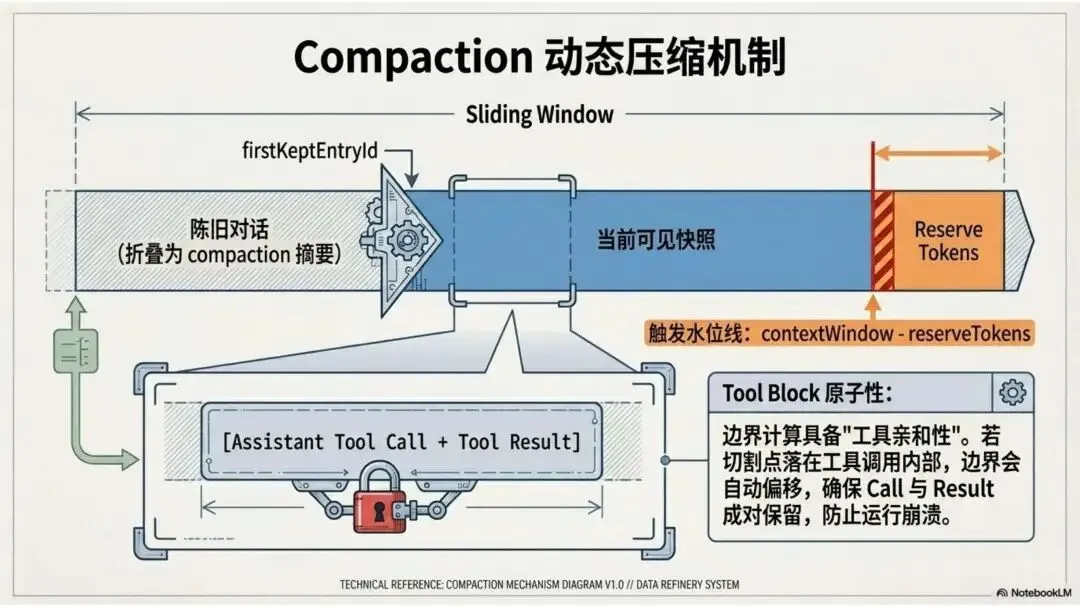
▲ Compaction 滑动窗口:firstKeptEntryId 左侧折叠为摘要,右侧保留 Reserve Tokens 缓冲区
Compaction 的核心(源码:compaction.ts)是一个滑动窗口:firstKeptEntryId 标记当前可见快照的起点,窗口左侧的陈旧对话被折叠为压缩摘要。
级联块处理:当历史太长时
摘要生成不是一次完成的。如果历史记录太长,会先分段摘要,再把分段摘要汇总——这就是级联块处理(Cascading Chunks)。好处是单次摘要任务的输入始终在模型能力范围内,不会因为历史过长导致摘要本身的质量下降。
关键信息保护
摘要指令里强制要求模型保留两类信息:第一是标识符——UUID、文件 Hash、路径名等不透明 ID 严禁缩短或改写;第二是活跃任务状态——当前正在进行的决策记录和未完成的操作必须完整保留。
这防止的是一类非常具体的能力退化:模型在压缩后"记得"某个任务在进行,却"忘了"那个任务对应的文件路径或操作 ID,导致后续工具调用传入幻造的参数。
Tool Call 原子性修复
repairToolUseResultPairing如果压缩边界恰好落在一个工具调用内部([Tool Call] 保留了,但对应的 [Tool Result] 被截断),系统会自动修复成对关系——要么同时保留,要么同时移除。原因很具体:Claude 等模型在看到孤立的 Tool Call 而没有对应 Result 时会直接报错,认为 API 调用顺序违规。这不是优雅降级,是硬崩溃。所以修复是强制的,不是可选的。
设计哲学二:State-Preserving Summarization——摘要不是内容缩写,而是状态机的迁移。侧重点不是"历史发生了什么",而是"还有什么事没做完"。这两者之间的差异,决定了 Agent 在压缩后是否还能继续正确运行。
Prompt Cache 稳定化:字节级一致性工程
OpenClaw 在 prompt-cache-stability.ts 里做了一件很少被提及但代价极高的事:为了让 Claude / Gemini 的 Prompt Cache 尽可能命中,它对所有动态生成的内容做了确定性处理。
排序规范化:所有工具定义、文件列表、能力标识符,统一按字母顺序排序。这样,即使 Agent 在两次运行之间注册了一个新工具,已有工具部分的字节流仍然保持不变,缓存不会因为"插入"一条记录而整体失效。
Cache Boundary 设计:系统在 System Prompt 中设置了明确的稳定边界:不常变动的内容(工具定义、技能列表、角色配置)放在前面;经常变动的内容(当前时间、动态注入的 systemPromptAddition)放在后面。这样每次请求,缓存命中的部分是最长的前缀,而不是零散的片段。
为什么这件事值得单独说?假设每次请求有 50k tokens 的 System Prompt,如果缓存命中,Provider 端对这 50k tokens 不计费或打折计费(Claude 的 Prompt Cache 折扣约为 90%)。如果因为排序不稳定导致缓存每次都未命中,成本差距在高频调用场景下可能是量级级别的。
设计哲学三:Cache-First Engineering——所有的动态拼接都在字节级别考虑了缓存一致性。这不是锦上添花,而是在规模化部署下控制成本的基本盘。
上下文限额自发现:不硬编码模型上限
OpenClaw 并没有在代码里写死"GPT-4 是 128k,Claude 是 200k"这类配置,而是在 context.ts 里实现了一套多级查询机制:
查询优先级(由高到低):1. 用户在 openclaw.json 中显式配置的 contextWindow2. 运行时通过 Provider API 的 meta 信息动态发现3. 内置的 MODEL_CONTEXT_TOKEN_CACHE 注册表兜底这个设计的好处是:当新模型发布时,只要 Provider 的 meta 接口返回了正确的 contextWindow,系统就能自动适配,不需要人工更新代码。对于用户来说,也可以通过配置显式覆盖,应对那些 Provider API 返回值不准确的边缘情况。
演进路径:三种形态的 Context Engine
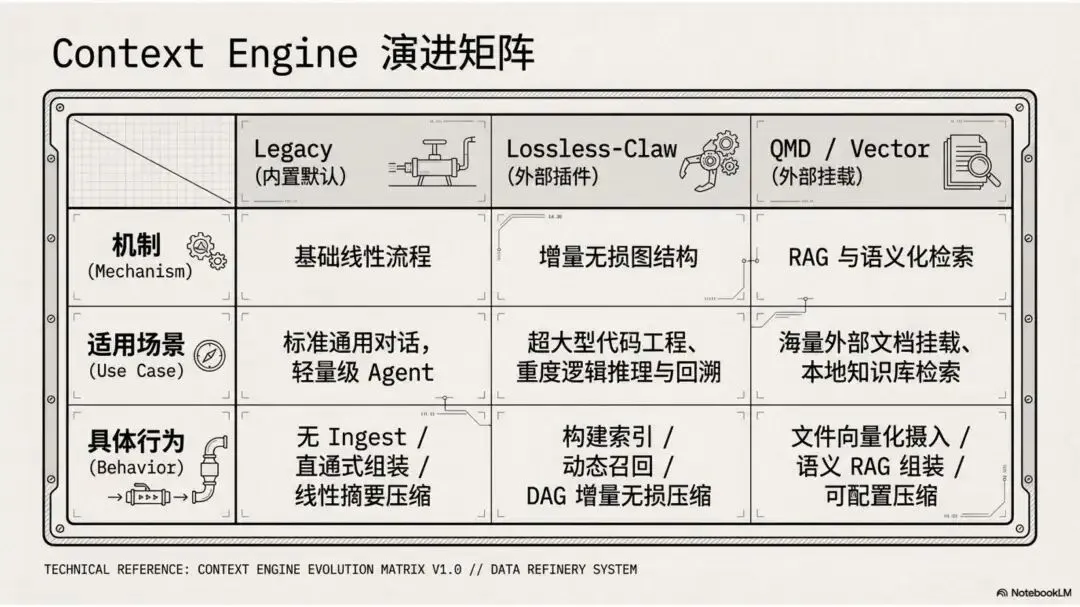
▲ Context Engine 演进矩阵:Legacy → Lossless-Claw → QMD/Vector,三种模式对应不同使用场景
Legacy 模式(内置默认):适合标准对话和轻量 Agent,基础线性流程,不含动态召回环节。开箱即用,零配置。
Lossless-Claw 模式(外部插件):专为超大型代码工程和重度逻辑推理设计。通过增量无损图结构与 DAG 动态召回,实现真正的无损上下文压缩——压缩后的历史不是摘要,而是完整的结构化索引,随时可以精确召回。
QMD/Vector 模式(外部挂载):面向海量外部文档载入和本地知识库检索场景,通过文档向量化摄入和语义 RAG 组装实现可配置压缩。
三种模式的切换完全通过 plugins.slots.contextEngine 插件槽实现,对上层业务逻辑无感。
诚实的边界
OpenClaw 的文档对已知局限相当坦诚,这里也同样说清楚:
Token 估算漂移:本地的 contextTokens 估算与 Provider 实际计算之间存在系统性偏差,必须留足 Reserve Tokens 缓冲,代价是有效上下文窗口略小于标称值。
Prompt Cache 的脆弱性:如果频繁通过 Hook 在 Prompt Cache 边界之上动态追加内容,会不断破坏 Provider 端的静默缓存,导致 API 成本意外飙升。这是使用 systemPromptAddition 时需要警惕的反模式。
MEMORY.md 静默截断:超大 MEMORY.md 超出单文件上限时,Agent 不会报错,只会静默截断。注意这与 Bootstrap 文件的显式警告机制不同——目前对 MEMORY.md 没有同等的告知机制,这是一个已知的不一致性。
平台私有 API 脆弱性:macOS 26 (Tahoe) 破坏了 BlueBubbles 的消息编辑功能,这类平台 API 的频繁变动目前缺乏基于功能检测(Feature Detection)的动态降级逻辑。
总结:三条设计哲学
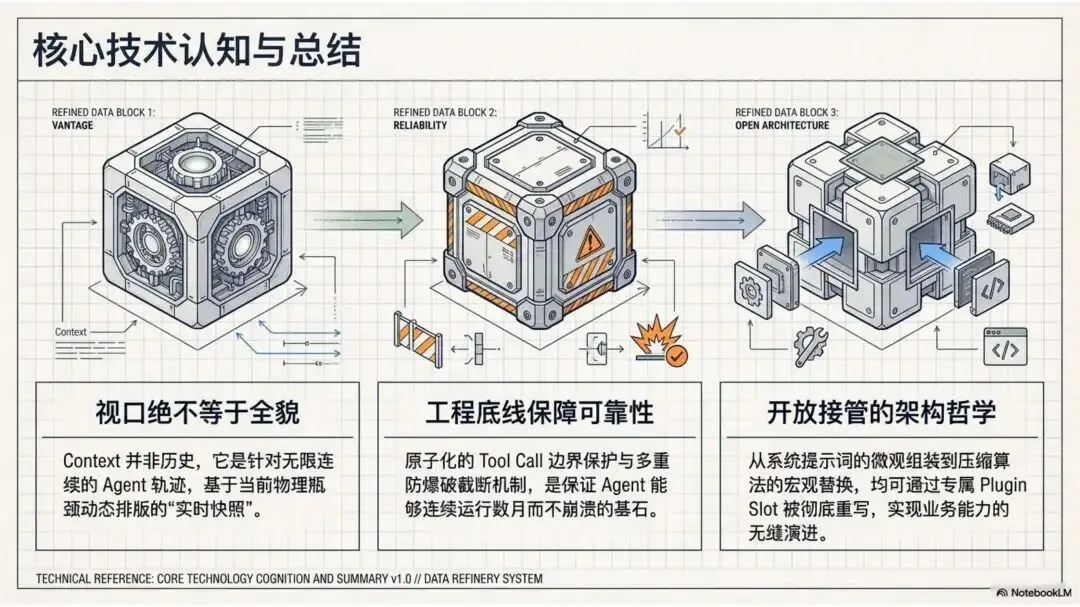
▲ 三条核心结论:视口绝不等于全貌 / 工程底线保障可靠性 / 开放接管的架构哲学
从源码到架构,OpenClaw 的上下文工程围绕三条设计哲学展开:
Instruction-as-Resource:把复杂的领域指令(Skills)视为可检索的资源,而非静态嵌入的文本。按需加载,而不是全量预加载。这让基础上下文保持精简,同时保留了扩展能力的空间。
State-Preserving Summarization:摘要不是内容缩写,而是状态机的迁移。压缩的目标不是"记住发生了什么",而是"保护还没做完的事"。标识符透传和 Tool Call 原子性修复都是这条哲学的具体体现。
Cache-First Engineering:所有动态拼接都在字节级别考虑了 Prompt Cache 的命中率——排序规范化、Cache Boundary 设计、避免在稳定前缀之前插入动态内容。这不是优化,而是规模化部署下的成本控制基本盘。
这三条哲学有一个共同的底层逻辑:在有限的资源约束下(Token 窗口、API 成本、存储空间),做出让系统长期可运行的工程决策,而不是让系统在 Demo 里好看的设计决策。
本文基于 NotebookLM 生成报告与幻灯片、OpenClaw 源码分析与官方文档整理
Incept the prompt, kick out of hallucination.
植令,坠醒。
The Kick · 创刊号
