 夜雨聆风
夜雨聆风找到问题只是开始,能自动修复才是终局。
上一篇我讲了如何用 OpenClaw 做日志根因分析,把翻日志时间从 2 小时压缩到 5 分钟。
很多人在问:"既然能定位问题,能不能直接修复?"
答案是:能,但不是无脑自动修复。
今天这篇文章,我只讲一件事:
如何用 OpenClaw 把"定位问题"和"修复问题"串成一个完整闭环。
我会讲清楚:
这不是理论,是我在生产环境跑了 3 个月的实战经验。
一、为什么自动修复这么难
先说结论:自动修复的难度不在技术,在风险控制。
定位问题 vs 修复问题
定位问题:
修复问题:
举个例子:
你的数据库连接池满了,AI 判断出根因是"慢查询导致连接堆积"。
如果 AI 建议你:
你选哪个?
所以自动修复的核心问题不是"能不能修",而是:
1. 在什么条件下修?2. 用什么策略修?3. 修完怎么验证?4. 修错了怎么回退?
二、我的设计原则
在做自动修复之前,我给自己定了 5 条铁律:
原则1: 人机协同,不是完全自动
AI 提建议,人做决策,高可信场景才自动执行。
三个级别:
示例:
原则2: 白名单机制,永不越权
只修复预定义的、经过验证的场景,不做任何即兴发挥。
维护一个"可自动修复场景白名单":
allowed_fixes:- type: pod_restartconditions:- status: CrashLoopBackOff- restart_count: < 5- namespace: !~ production-criticalapproval: auto- type: disk_cleanupconditions:- disk_usage: > 90%- path: /tmpapproval: auto- type: connection_pool_resetconditions:- pool_usage: 100%- service: checkout-apiapproval: manual # 需要人工确认
不在白名单里的,一律走人工审批。
原则3: 可观测、可回退、可审计
每一步操作都有日志,每一次修复都能回退,每一个决策都有审计。
必须记录:
必须支持回退:
原则4: 验证闭环,修完必须验证
修复不是目的,恢复服务才是。
验证机制:
如果验证失败,立即回退。
原则5: 从小范围试点开始
不要一上来就在生产环境全量自动修复。
灰度策略:
三、OpenClaw 如何串联整个闭环
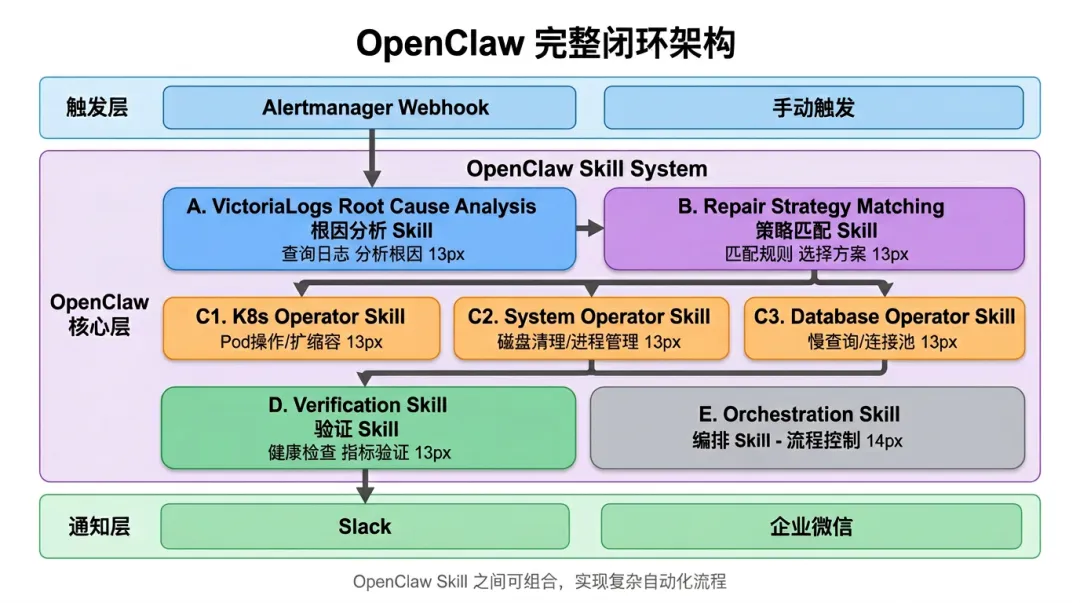
核心思路:OpenClaw 既是"大脑"也是"双手"。
OpenClaw 的 Skill 系统天然支持:
所以不需要额外工具,OpenClaw 自己就能完成从诊断到修复的完整闭环:
【OpenClaw完整闭环】触发(AlertmanagerWebhook)↓诊断(VictoriaLogs根因分析Skill)↓决策(修复策略匹配Skill)↓执行(Kubernetes/Ansible/ScriptSkill)↓验证(健康检查Skill)↓通知(Slack/企业微信)
OpenClaw Skill 的执行能力:
# OpenClaw 可以直接调用的工具- kubectl (Kubernetes操作)- ansible-playbook (配置管理)- curl/http (API 调用)- shell script (自定义脚本)- python script (复杂逻辑)- cloud CLI (AWS/GCP/阿里云/腾讯云)
关键设计:
四、7 天搭建完整闭环
Day 1-2: 创建 Kubernetes 操作 Skill (6小时)
目标: 让 OpenClaw 能执行 Kubernetes 基础操作。
步骤1: 创建 K8s 操作 Skill
# skills/k8s-operator/SKILL.md## Kubernetes 操作 Skill### 功能执行Kubernetes基础运维操作(重启Pod、扩缩容、查看状态)### 操作白名单- restart_pod:重启指定Pod- scale_deployment:调整副本数- get_pod_status:查看Pod状态- get_pod_logs:获取Pod日志### 安全限制-仅允许操作 staging/production 命名空间-禁止操作 production-critical 命名空间-Pod重启次数<5次才允许自动重启-所有操作都有详细审计日志
请使用 k8s-operator skill 重启 staging 命名空间的 checkout-api Pod
步骤2: 实现 Pod 重启功能
# skills/k8s-operator/actions/restart_pod.pyimport subprocessimport jsonimport timefrom datetime import datetimedef restart_pod(namespace: str, pod_name: str):"""重启 Kubernetes PodArgs:namespace: 命名空间pod_name: Pod 名称Returns:操作结果"""# 0. 审计日志log_audit("restart_pod", {"namespace": namespace,"pod_name": pod_name,"timestamp": datetime.now().isoformat()})# 1. 安全检查: 验证命名空间白名单if namespace in ['production-critical', 'kube-system']:return {'success': False,'error': f'Namespace {namespace} is not allowed'}# 2. 安全检查: 验证 Pod 重启次数restart_count = get_pod_restart_count(namespace, pod_name)if restart_count >= 5:return {'success': False,'error': f'Pod restart count ({restart_count}) exceeds limit (5)'}# 3. 记录操作前状态before_state = get_pod_state(namespace, pod_name)# 4. 执行重启 (删除 Pod,让 Deployment 自动重建)cmd = ['kubectl', 'delete', 'pod', pod_name, '-n', namespace]result = subprocess.run(cmd, capture_output=True, text=True)if result.returncode != 0:return {'success': False,'error': result.stderr}# 5. 等待 Pod 重建并 Readysuccess = wait_for_pod_ready(namespace, pod_name, timeout=120)if not success:return {'success': False,'error': 'Pod failed to become ready after restart'}# 6. 记录操作后状态after_state = get_pod_state(namespace, pod_name)# 7. 返回结果return {'success': True,'before': before_state,'after': after_state,'message': f'Pod {pod_name} restarted successfully'}def get_pod_restart_count(namespace: str, pod_name: str) -> int:"""获取 Pod 重启次数"""cmd = ['kubectl', 'get', 'pod', pod_name, '-n', namespace,'-o', 'jsonpath={.status.containerStatuses[0].restartCount}']result = subprocess.run(cmd, capture_output=True, text=True)return int(result.stdout) if result.stdout else 0def get_pod_state(namespace: str, pod_name: str) -> dict:"""获取 Pod 当前状态"""cmd = ['kubectl', 'get', 'pod', pod_name, '-n', namespace,'-o', 'json']result = subprocess.run(cmd, capture_output=True, text=True)if result.returncode != 0:return {'error': result.stderr}pod = json.loads(result.stdout)return {'status': pod['status']['phase'],'ready': pod['status'].get('conditions', [{}])[-1].get('status'),'restart_count': pod['status']['containerStatuses'][0]['restartCount'],'image': pod['spec']['containers'][0]['image']}def wait_for_pod_ready(namespace: str, pod_name: str, timeout: int = 120) -> bool:"""等待 Pod 变为 Ready"""start_time = time.time()# 先获取 Pod 的 Label,因为删除后 Pod 名会变label = get_pod_label(namespace, pod_name)while time.time() - start_time < timeout:# 通过 Label 查找新 Podpods = get_pods_by_label(namespace, label)for pod in pods:if pod['status'] == 'Running' and pod['ready'] == 'True':return Truetime.sleep(5)return Falsedef log_audit(action: str, params: dict):"""记录审计日志"""with open('/var/log/openclaw/audit.log', 'a') as f:f.write(json.dumps({'action': action,'params': params,'timestamp': datetime.now().isoformat()}) + '\n')
步骤3: 测试 K8s 操作
# 手动测试python skills/k8s-operator/actions/restart_pod.py \--namespace staging \--pod-name checkout-api-7d8f9c5b6-abcde# OpenClaw 测试openclaw run "请使用 k8s-operator skill 重启 staging 的 checkout-api Pod"
Day 3-4: 创建更多修复操作 Skill (8小时)
目标: 扩展修复能力,覆盖常见故障场景。
场景1: 磁盘清理
# skills/system-operator/actions/cleanup_disk.pyimport subprocessimport osdef cleanup_disk(path: str, max_age_days:int=7):"""清理指定路径的旧文件Args:path:路径(/tmp, /var/log/old 等)max_age_days:保留天数"""# 安全检查: 只允许清理特定路径allowed_paths =['/tmp','/var/log/old','/var/cache']if path notin allowed_paths:return{'success':False,'error': f'Path {path} is not in allowed list'}# 获取清理前磁盘使用率before_usage = get_disk_usage(path)# 执行清理 (删除 N 天前的文件)cmd =['find', path,'-type','f','-mtime', f'+{max_age_days}','-delete']result = subprocess.run(cmd, capture_output=True, text=True)# 获取清理后磁盘使用率after_usage = get_disk_usage(path)return{'success': result.returncode ==0,'before_usage': before_usage,'after_usage': after_usage,'freed_space': before_usage - after_usage}def get_disk_usage(path: str)->float:"""获取磁盘使用率"""stat = os.statvfs(path)total = stat.f_blocks * stat.f_frsizeused =(stat.f_blocks - stat.f_bfree)* stat.f_frsizereturn(used / total)*100
场景2: Kill 慢查询
# skills/database-operator/actions/kill_slow_query.pyimport pymysqldef kill_slow_queries(host: str, database: str, min_query_time:int=300):"""Kill慢查询Args:host:数据库地址database:数据库名min_query_time:最小执行时间(秒)"""# 连接数据库conn = pymysql.connect(host=host, user='admin', password='xxx', database=database)cursor = conn.cursor()# 查找慢查询cursor.execute(f"""SELECT ID, TIME, INFOFROM information_schema.PROCESSLISTWHERE COMMAND ='Query'AND TIME >{min_query_time}AND USER !='system'""")slow_queries = cursor.fetchall()killed =[]# Kill 慢查询for query_id, query_time, query_info in slow_queries:cursor.execute(f"KILL {query_id}")killed.append({'id': query_id,'time': query_time,'query': query_info[:100]# 只记录前 100 个字符})conn.close()return{'success':True,'killed_count': len(killed),'killed_queries': killed}
场景3: 缓存刷新
# skills/cache-operator/actions/flush_cache.pyimport redisdef flush_redis_cache(host: str, port:int=6379, pattern: str =None):"""刷新Redis缓存Args:host:Redis地址port:Redis端口pattern:Key匹配模式(例如"user:*")"""client = redis.Redis(host=host, port=port)if pattern:# 删除匹配的 Keykeys = client.keys(pattern)if keys:client.delete(*keys)deleted_count = len(keys)else:# 清空整个库 (谨慎使用)client.flushdb()deleted_count ="all"return{'success':True,'deleted_count': deleted_count,'pattern': pattern or'all'}
Day 5: 设计修复决策流程 (6小时)
目标: 让 OpenClaw 自动选择修复策略。
修复决策树
# skills/auto-remediation/decision_tree.pyREMEDIATION_RULES = [{'name': 'Pod CrashLoopBackOff','conditions': {'pod_status': 'CrashLoopBackOff','restart_count': {'$lt': 5},'namespace': {'$nin': ['production-critical']}},'actions': [{'type': 'restart_pod','approval': 'auto', # L3'params': {'namespace': '${namespace}','pod_name': '${pod_name}'}}],'verification': {'type': 'pod_status','expected': 'Running','timeout': 120}},{'name': 'Disk Full','conditions': {'disk_usage': {'$gt': 90},'mount_point': {'$in': ['/tmp', '/var/log']}},'actions': [{'type': 'cleanup_disk','approval': 'auto','params': {'path': '${mount_point}','max_age_days': 7}}],'verification': {'type': 'disk_usage','expected': {'$lt': 80},'timeout': 60}},{'name': 'Database Connection Pool Exhausted','conditions': {'error_pattern': 'connection.*pool.*timeout','service': 'checkout-api'},'actions': [{'type': 'kill_slow_query','approval': 'manual', # L2 需要确认'params': {'database': 'checkout_db','min_query_time': 300}},{'type': 'restart_pod','approval': 'manual','params': {'namespace': 'production','pod_name': '${pod_name}'}}],'verification': {'type': 'error_rate','expected': {'$lt': 1}, # 错误率 < 1%'timeout': 300}}]def find_matching_rule(context: dict) -> dict:"""根据故障上下文匹配修复规则Args:context: 故障上下文(来自根因分析)Returns:匹配的规则,如果没有返回 None"""for rule in REMEDIATION_RULES:if match_conditions(rule['conditions'], context):return rulereturn Nonedef match_conditions(conditions: dict, context: dict) -> bool:"""检查条件是否匹配"""for key, expected in conditions.items():actual = context.get(key)if isinstance(expected, dict):# 复杂条件 (例如 $gt, $lt, $in)if '$gt' in expected and actual <= expected['$gt']:return Falseif '$lt' in expected and actual >= expected['$lt']:return Falseif '$in' in expected and actual not in expected['$in']:return Falseif '$nin' in expected and actual in expected['$nin']:return Falseelse:# 简单相等if actual != expected:return Falsereturn True
Day 6: 串联完整闭环 (8小时)
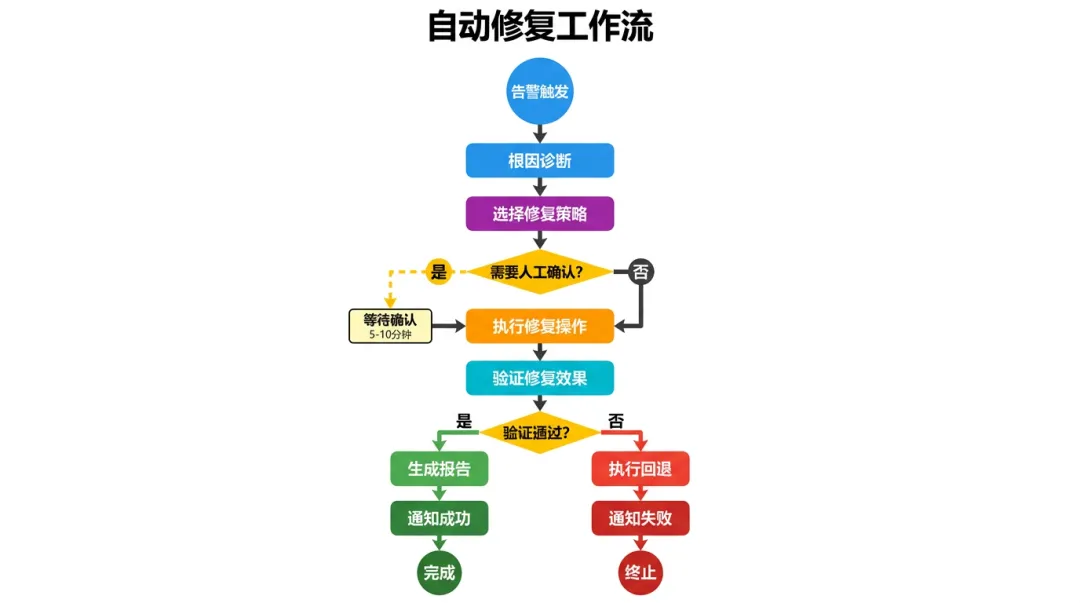
目标: 从告警 → 诊断 → 修复 → 验证 → 通知,OpenClaw 一条龙处理。
核心:创建"自动修复编排" Skill
# skills/auto-remediation-workflow/SKILL.md## 自动修复编排 Skill### 功能接收告警,自动完成:诊断→决策→执行→验证→通知的完整闭环### 工作流程1.接收AlertmanagerWebhook2.调用根因分析Skill3.匹配修复规则4.调用具体修复Skill(k8s-operator/system-operator/database-operator)5.验证修复效果6.通知结果### 使用方法由AlertmanagerWebhook自动触发,或手动触发:
请使用 auto-remediation-workflow skill 处理 checkout-api 服务的 CrashLoopBackOff 告警
实现完整工作流
# skills/auto-remediation-workflow/orchestrator.pydef auto_remediation_workflow(alert: dict):"""OpenClaw 自动修复完整流程Args:alert: 告警信息 (来自 Alertmanager)Returns:修复结果"""workflow_id = generate_workflow_id()log_workflow_start(workflow_id, alert)try:# ========== 第一步: 根因诊断 (调用上一篇的 Skill) ==========print(f"[{workflow_id}] 步骤1: 诊断根因...")diagnosis = call_openclaw_skill(skill="victorialogs-rootcause",params={"service": alert['service'],"time_range": "10m"})log_diagnosis(workflow_id, diagnosis)if not diagnosis['success']:notify_failure(workflow_id, "诊断失败", diagnosis['error'])return# ========== 第二步: 选择修复策略 ==========print(f"[{workflow_id}] 步骤2: 选择修复策略...")remediation_rule = find_matching_rule(diagnosis['root_cause'])if not remediation_rule:# 没有匹配的规则,通知人工介入notify_manual_intervention(workflow_id, diagnosis)returnlog_remediation_plan(workflow_id, remediation_rule)# ========== 第三步: 执行修复 (调用具体操作 Skill) ==========print(f"[{workflow_id}] 步骤3: 执行修复...")# 检查是否需要人工确认if remediation_rule['approval'] == 'manual':approved = request_approval_via_slack(workflow_id,remediation_rule,timeout=300 # 5分钟超时)if not approved:notify_approval_timeout(workflow_id, remediation_rule)return# 调用具体修复 Skillfix_result = call_openclaw_skill(skill=remediation_rule['skill'],params=remediation_rule['params'])log_execution(workflow_id, fix_result)if not fix_result['success']:notify_execution_failure(workflow_id, fix_result)return# ========== 第四步: 验证修复效果 ==========print(f"[{workflow_id}] 步骤4: 验证修复效果...")verification = verify_remediation(verification_config=remediation_rule['verification'],timeout=remediation_rule['verification']['timeout'])log_verification(workflow_id, verification)if not verification['success']:# 验证失败,尝试回退print(f"[{workflow_id}] 验证失败,尝试回退...")rollback_result = rollback_fix(workflow_id, remediation_rule)notify_rollback(workflow_id, verification, rollback_result)return# ========== 第五步: 生成报告并通知 ==========print(f"[{workflow_id}] 步骤5: 生成报告...")report = generate_report(workflow_id, {'alert': alert,'diagnosis': diagnosis,'remediation': remediation_rule,'execution': fix_result,'verification': verification})notify_success(workflow_id, report)log_workflow_complete(workflow_id)except Exception as e:log_workflow_error(workflow_id, e)notify_failure(workflow_id, "工作流异常", str(e))def call_openclaw_skill(skill: str, params: dict) -> dict:"""调用 OpenClaw Skill在 OpenClaw 内部,Skill 之间可以相互调用"""# 构造 Skill 调用指令prompt = f"请使用 {skill} skill 执行操作,参数: {json.dumps(params)}"# OpenClaw 内部调用result = openclaw.run_skill(skill, params)return resultdef find_matching_rule(root_cause: str) -> dict:"""根据根因匹配修复规则这些规则是预定义的,经过验证的修复策略"""# 修复规则库 (后面详细讲)for rule in REMEDIATION_RULES:if match_root_cause(rule['pattern'], root_cause):return rulereturn Nonedef verify_remediation(verification_config: dict, timeout: int) -> dict:"""验证修复效果OpenClaw 调用验证 Skill 检查系统状态"""start_time = time.time()while time.time() - start_time < timeout:if verification_config['type'] == 'pod_status':# 调用 k8s-operator skill 检查 Pod 状态result = call_openclaw_skill(skill="k8s-operator",params={"action": "get_pod_status", **verification_config['params']})if result['status'] == verification_config['expected']:return {'success': True, 'message': 'Pod 已恢复'}elif verification_config['type'] == 'error_rate':# 查询 VictoriaMetrics 检查错误率error_rate = query_victoria_metrics('rate(http_requests_errors_total[5m])')if error_rate < verification_config['threshold']:return {'success': True, 'message': f'错误率已降至 {error_rate:.2f}%'}elif verification_config['type'] == 'disk_usage':# 调用 system-operator skill 检查磁盘result = call_openclaw_skill(skill="system-operator",params={"action": "get_disk_usage", **verification_config['params']})if result['usage'] < verification_config['threshold']:return {'success': True, 'message': f'磁盘使用率已降至 {result["usage"]}%'}time.sleep(10)return {'success': False, 'message': '验证超时'}def request_approval_via_slack(workflow_id: str, rule: dict, timeout: int) -> bool:"""通过 Slack 请求人工审批发送交互式消息,等待用户点击"批准"或"拒绝""""message = {"text": f"🚨 需要您的审批 - 工作流 {workflow_id}","blocks": [{"type": "section","text": {"type": "mrkdwn","text": f"*修复操作:* {rule['description']}\n*影响范围:* {rule['impact']}\n*风险等级:* {rule['risk_level']}"}},{"type": "actions","elements": [{"type": "button","text": {"type": "plain_text", "text": "✅ 批准"},"style": "primary","value": f"approve_{workflow_id}"},{"type": "button","text": {"type": "plain_text", "text": "❌ 拒绝"},"style": "danger","value": f"reject_{workflow_id}"}]}]}# 发送到 Slacksend_slack_message(channel="#ops-alerts", message=message)# 等待用户响应 (轮询或 Webhook)start_time = time.time()while time.time() - start_time < timeout:approval_status = check_approval_status(workflow_id)if approval_status == 'approved':return Trueelif approval_status == 'rejected':return Falsetime.sleep(5)# 超时return False
Day 7: 测试和上线 (6小时)
测试场景
场景1: Pod CrashLoopBackOff (L3 自动修复)
# 模拟故障kubectl run test-crash --image=nginx --restart=Always-- sh -c "exit 1"# 触发告警(Prometheus)# 等待自动修复# 验证 Pod 已重启并恢复
场景2: 磁盘满 (L3 自动修复)
# 模拟磁盘满dd if=/dev/zero of=/tmp/bigfile bs=1M count=10000# 触发告警# 等待自动清理# 验证磁盘使用率下降
场景3: 数据库连接池满 (L2 人工确认)
# 模拟慢查询# 触发告警# OpenClaw 诊断 → 发现慢查询# 发送修复建议到 Slack# 人工点击"确认"按钮# Hermes 执行 kill 慢查询# 验证连接池恢复
灰度发布
第1周: 测试环境
第2-3周: 生产环境试点
第4周: 扩大范围
五、三个月后的数据
故障修复效率
平均修复时间: 从 45 分钟降到 8 分钟
•人工修复平均: 45 分钟(定位 + 修复 + 验证)•自动修复平均: 8 分钟(触发 + 执行 + 验证)•效率提升: 82%
自动化覆盖率
L3 自动修复覆盖: 40%
•Pod CrashLoopBackOff: 25%•磁盘满: 10%•缓存清理: 5%•L2 建议修复覆盖: 30%•慢查询 kill: 15%•服务重启: 10%•配置回滚: 5%•仍需人工处理: 30%
修复成功率
一次修复成功率: 85%
•L3 自动修复成功率: 92%(操作简单,风险低)•L2 建议修复成功率: 78%(需要人判断,可能选错)
误操作和回退
误操作次数: 3 次 / 3 个月
•误删 Pod: 2 次(已自动重建,影响 < 1分钟)•误杀查询: 1 次(业务已重试,无实际影响)•回退成功率: 100%
成本
总成本: $150/月
•OpenClaw API 调用: $80/月•Hermes Agent 服务器: $50/月(1台 2C4G)•监控和日志存储: $20/月
ROI
节省时间: 60 小时/月
•故障次数: 40 次/月•平均节省: 1.5 小时/次•按时薪 $50 算: $3000/月•投资回报率: 20 倍
六、三个血泪教训
教训1: 不要低估回退的重要性
反面案例:
第 2 周时,我们自动重启了一个 Pod,但忘了这个 Pod 是有状态的,里面缓存了用户会话。
重启后,100+ 用户被强制登出。
虽然业务影响不大(重新登录即可),但用户体验很差。
改进:
教训2: 验证一定要充分
反面案例:
我们的验证逻辑只检查"Pod 状态是 Running",但没检查"服务是否真的可用"。
结果有一次 Pod 起来了,但应用启动失败,我们却认为"修复成功"。
改进:
教训3: 人工确认要有超时机制
反面案例:
L2 修复需要人工确认,我们发了消息到 Slack,然后就一直等。
结果那天正好是周末,值班同学没看到,系统等了 2 小时还在等。
改进:
七、适合你的场景吗?
适合的团队
✅ 有基础监控体系(Prometheus, ELK, VictoriaLogs 等)
✅ 故障类型相对固定(常见的几种问题反复出现)
✅ 有明确的修复 SOP(知道怎么修,只是嫌慢)
✅ 团队接受 AI 辅助(不排斥自动化)
✅ 有一定开发能力(能写 Python 脚本)
不适合的场景
❌ 监控数据不全(连日志都没有,AI 无法分析)
❌ 故障千奇百怪(每次都是新问题,无法沉淀规则)
❌ 修复操作极其复杂(需要多个系统配合,无法自动化)
❌ 团队强烈抵触(担心 AI 搞坏系统)
❌ 没有回退机制(修复后无法撤销,风险太高)
八、下一步可以做什么
短期优化
长期规划
最后
这套方案的核心不是"AI 多聪明"。
而是把确定性的、重复性的修复操作自动化,把人从救火中解放出来。
AI 不会替代 SRE,但会用 AI 的 SRE 会替代不会用的。
从定位到修复,闭环才是王道。
💬 说说你的想法
如果你也在做自动化修复相关的工作,评论区聊聊:
如果这篇文章对你有帮助,点个"在看",让更多 SRE 看到。
📚 相关资源
🚀 下期预告
下一篇我会写OpenClaw 成本优化实战,如何用 AI 把云资源成本降低 30%。
关注我,不错过 AI 运维实战系列。
